从传统数据库到大数据的转变,首当其冲的是各种术语的理解。
所以我与chatgpt发生了一系列对话,以便于我能快速理解这些术语。
我先把汇总的结果放在前边,后边会一步步地来说明我是如何获取这些信息的。前边我也发过一些关于chatgpt提示词相关的文章,能更好地帮助我们与chatgpt进行沟通。
提示词工程技术
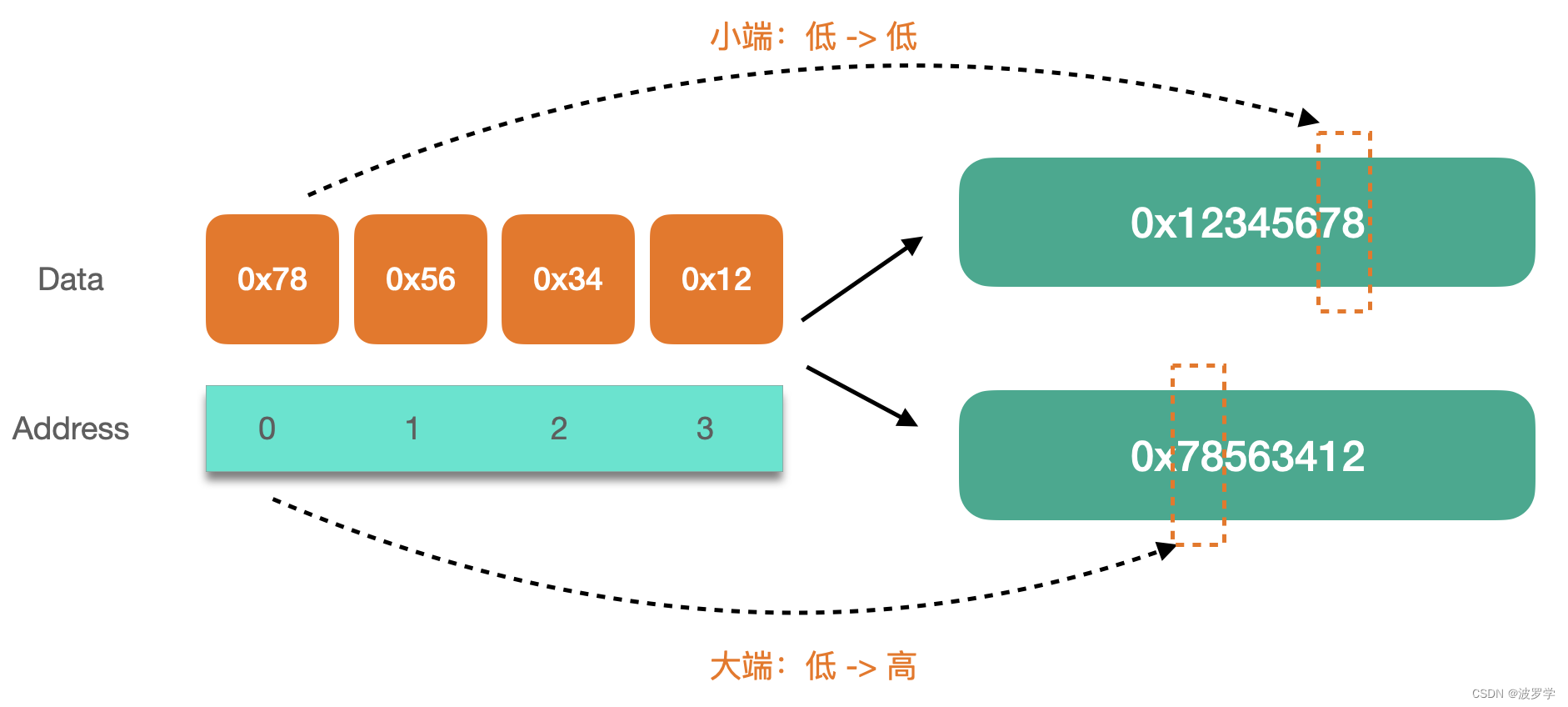
Copy on Write (COW)和Merge on Read (MOR)两种模式的主要特点和区别:
| 特性/模式 | Copy on Write (COW) | Merge on Read (MOR) |
|---|---|---|
| 数据更新 | 通过复制并重写整个文件来更新 | 将更改作为增量日志保存 |
| 读取性能 | 高;因为总是直接读取最新的完整快照 | 较低;需要在读取时合并基础文件与日志 |
| 写入性能 | 较低;每次变更都需重写整个文件 | 高;仅追加变化至增量日志 |
| 存储效率 | 较低;每次更新均产生新的全量数据副本 | 较高;只需额外存储变化部分 |
| 实时查询支持 | 不适用于需要极端实时反馈的场景 | 支持近乎实时地查询最新数据 |
| 适用场景 | 主要针对读操作多、数据变动较少的应用 | 主要针对写操作频繁、需要即时视图更新的应用 |
问题1: 零样本提示(Zero-Shot Prompting)
你能跟我通俗易懂地解释一下hudi表cow类型和mor类型的区别吗

问题2:自洽性可能(Self-Consistency)
你可以结合实际例子再做一个解释说明吗?
 问题3:定向刺激提示(Directional Stimulus Prompting)
问题3:定向刺激提示(Directional Stimulus Prompting)
我感觉我还不是很懂,你再解释得更通俗易懂一些
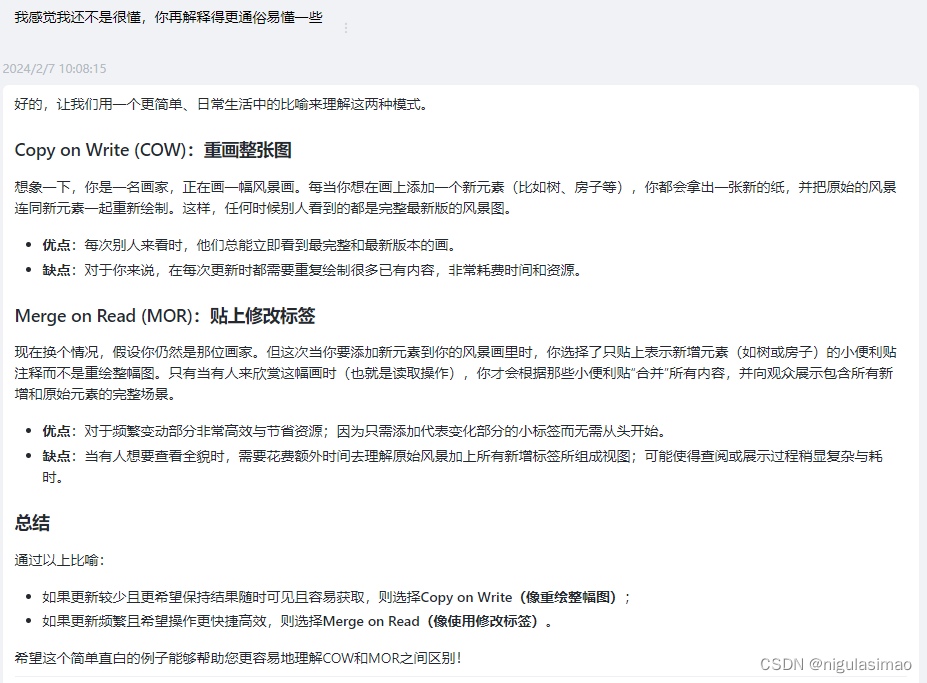
问题4:定向刺激提示(Directional Stimulus Prompting)
你能把上边COW和MOR的特点做一个表格吗,让我非常清楚地能看出两者的区别

问题4:零样本提示(Zero-Shot Prompting)和自洽性可能(Self-Consistency)
使用MOR模式的时候,为何要多删除带_ro和_rt的表?