文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
- 解法三
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:验证二叉搜索树
出处:98. 验证二叉搜索树
难度
3 级
题目描述
要求
给定一个二叉树的根结点 root \texttt{root} root,判断其是否是一个有效的二叉搜索树。
有效二叉搜索树定义如下:
- 结点的左子树只包含小于当前结点的数。
- 结点的右子树只包含大于当前结点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例
示例 1:
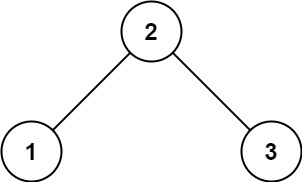
输入:
root
=
[2,1,3]
\texttt{root = [2,1,3]}
root = [2,1,3]
输出:
true
\texttt{true}
true
示例 2:
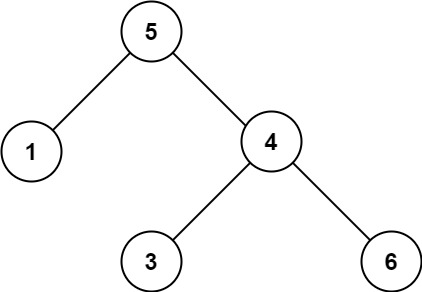
输入:
root
=
[5,1,4,null,null,3,6]
\texttt{root = [5,1,4,null,null,3,6]}
root = [5,1,4,null,null,3,6]
输出:
false
\texttt{false}
false
解释:根结点的值是
5
\texttt{5}
5,但是右子结点的值是
4
\texttt{4}
4。
数据范围
- 树中结点数目在范围 [1, 10 4 ] \texttt{[1, 10}^\texttt{4}\texttt{]} [1, 104] 内
- -2 31 ≤ Node.val ≤ 2 31 − 1 \texttt{-2}^\texttt{31} \le \texttt{Node.val} \le \texttt{2}^\texttt{31} - \texttt{1} -231≤Node.val≤231−1
解法一
思路和算法
对于二叉搜索树中的任意结点,其左子树中的结点值都小于当前结点值,其右子树中的结点值都大于当前结点值,因此二叉搜索树的每一个子树(包括原二叉搜索树本身)都有结点值的取值范围。对于原二叉搜索树,结点值的取值范围是 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞),如果根结点值为 r r r,则根结点的左子树和右子树的结点值取值范围分别是 ( − ∞ , r − 1 ] (-\infty, r - 1] (−∞,r−1] 和 [ r + 1 , + ∞ ) [r + 1, +\infty) [r+1,+∞)。
由于数据范围限制了二叉搜索树中的结点值的取值范围,因此上述取值范围可以用闭区间表示。对于二叉搜索树的每一个子树(包括原二叉搜索树本身),如果其结点值的取值范围是 [ lowerBound , upperBound ] [\textit{lowerBound}, \textit{upperBound}] [lowerBound,upperBound],子树的根结点值为 mid \textit{mid} mid,则该子树的左子树和右子树的结点值取值范围分别是 [ lowerBound , mid − 1 ] [\textit{lowerBound}, \textit{mid} - 1] [lowerBound,mid−1] 和 [ mid + 1 , upperBound ] [\textit{mid} + 1, \textit{upperBound}] [mid+1,upperBound]。
判断给定的二叉树是否是二叉搜索树,可以通过判断给定的二叉树的每一个子树是否是二叉搜索树,即每一个子树是否都满足结点值在特定取值范围内。从根结点开始遍历二叉树,对于每个结点,判断其子树的结点值是否在特定取值范围内。
上述过程是一个递归的过程。递归的终止条件有两种情况。
-
当前结点为空,空树是二叉搜索树。
-
当前结点不为空且当前结点值不在特定取值范围内,二叉树不是二叉搜索树。
对于其余情况,根据当前子树的取值范围和当前结点值确定左子树和右子树的取值范围,对左子树和右子树调用递归。
由于二叉树中的结点值取值范围是 [ − 2 31 , 2 31 − 1 ] [-2^{31}, 2^{31} - 1] [−231,231−1],为了避免溢出,取值范围的上界和下界应使用数据类型 long \texttt{long} long,用 [ − 2 63 , 2 63 − 1 ] [-2^{63}, 2^{63} - 1] [−263,263−1] 作为原二叉树的取值范围。
代码
class Solution {
public boolean isValidBST(TreeNode root) {
return isValidBST(root, Long.MIN_VALUE, Long.MAX_VALUE);
}
public boolean isValidBST(TreeNode node, long lowerBound, long upperBound) {
if (node == null) {
return true;
}
if (node.val < lowerBound || node.val > upperBound) {
return false;
}
return isValidBST(node.left, lowerBound, (long) node.val - 1) && isValidBST(node.right, (long) node.val + 1, upperBound);
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度主要是递归调用的栈空间,取决于二叉树的高度,最坏情况下二叉树的高度是 O ( n ) O(n) O(n)。
解法二
思路和算法
二叉树的中序遍历的方法为:依次遍历左子树、根结点和右子树,对于左子树和右子树使用同样的方法遍历。根据二叉搜索树的性质可知,对于值为 x x x 的结点,值小于 x x x 的结点一定在值等于 x x x 的结点之前被访问,值大于 x x x 的结点一定在值等于 x x x 的结点之后被访问,因此二叉搜索树的中序遍历序列一定是递增的。只要得到二叉树的中序遍历序列,即可根据中序遍历序列是否递增判断二叉树是否是二叉搜索树。
由于只是判断二叉树的中序遍历序列是否递增,因此不需要存储完整的中序遍历序列,而是只需要存储上一个遍历到的结点值。每次访问结点时,比较当前结点值和上一个结点值。如果存在一个结点值小于等于上一个结点值,则中序遍历序列不是递增的,二叉树不是二叉搜索树。如果每个结点值都大于上一个结点值,则中序遍历序列是递增的,二叉树是二叉搜索树。
由于二叉树中的结点值取值范围是 [ − 2 31 , 2 31 − 1 ] [-2^{31}, 2^{31} - 1] [−231,231−1],因此将上一个结点值初始化为 − 2 63 -2^{63} −263。每次访问结点之后,需要将上一个结点值更新为当前结点值。
代码
class Solution {
public boolean isValidBST(TreeNode root) {
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
long prev = Long.MIN_VALUE;
TreeNode node = root;
while (!stack.isEmpty() || node != null) {
while (node != null) {
stack.push(node);
node = node.left;
}
node = stack.pop();
if (node.val <= prev) {
return false;
}
prev = node.val;
node = node.right;
}
return true;
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度主要是栈空间,取决于二叉树的高度,最坏情况下二叉树的高度是 O ( n ) O(n) O(n)。
解法三
思路和算法
解法二虽然不需要存储中序遍历序列,但是仍需要使用栈空间。使用莫里斯遍历可以将空间复杂度降低到 O ( 1 ) O(1) O(1)。
遍历过程中维护上一个结点值。每次访问结点时,比较当前结点值和上一个结点值。如果存在一个结点值小于等于上一个结点值,则中序遍历序列不是递增的,二叉树不是二叉搜索树。如果每个结点值都大于上一个结点值,则中序遍历序列是递增的,二叉树是二叉搜索树。
代码
class Solution {
public boolean isValidBST(TreeNode root) {
long prev = Long.MIN_VALUE;
TreeNode node = root;
while (node != null) {
if (node.left == null) {
if (node.val <= prev) {
return false;
}
prev = node.val;
node = node.right;
} else {
TreeNode predecessor = node.left;
while (predecessor.right != null && predecessor.right != node) {
predecessor = predecessor.right;
}
if (predecessor.right == null) {
predecessor.right = node;
node = node.left;
} else {
predecessor.right = null;
if (node.val <= prev) {
return false;
}
prev = node.val;
node = node.right;
}
}
}
return true;
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。使用莫里斯遍历,每个结点最多被访问两次。
-
空间复杂度: O ( 1 ) O(1) O(1)。