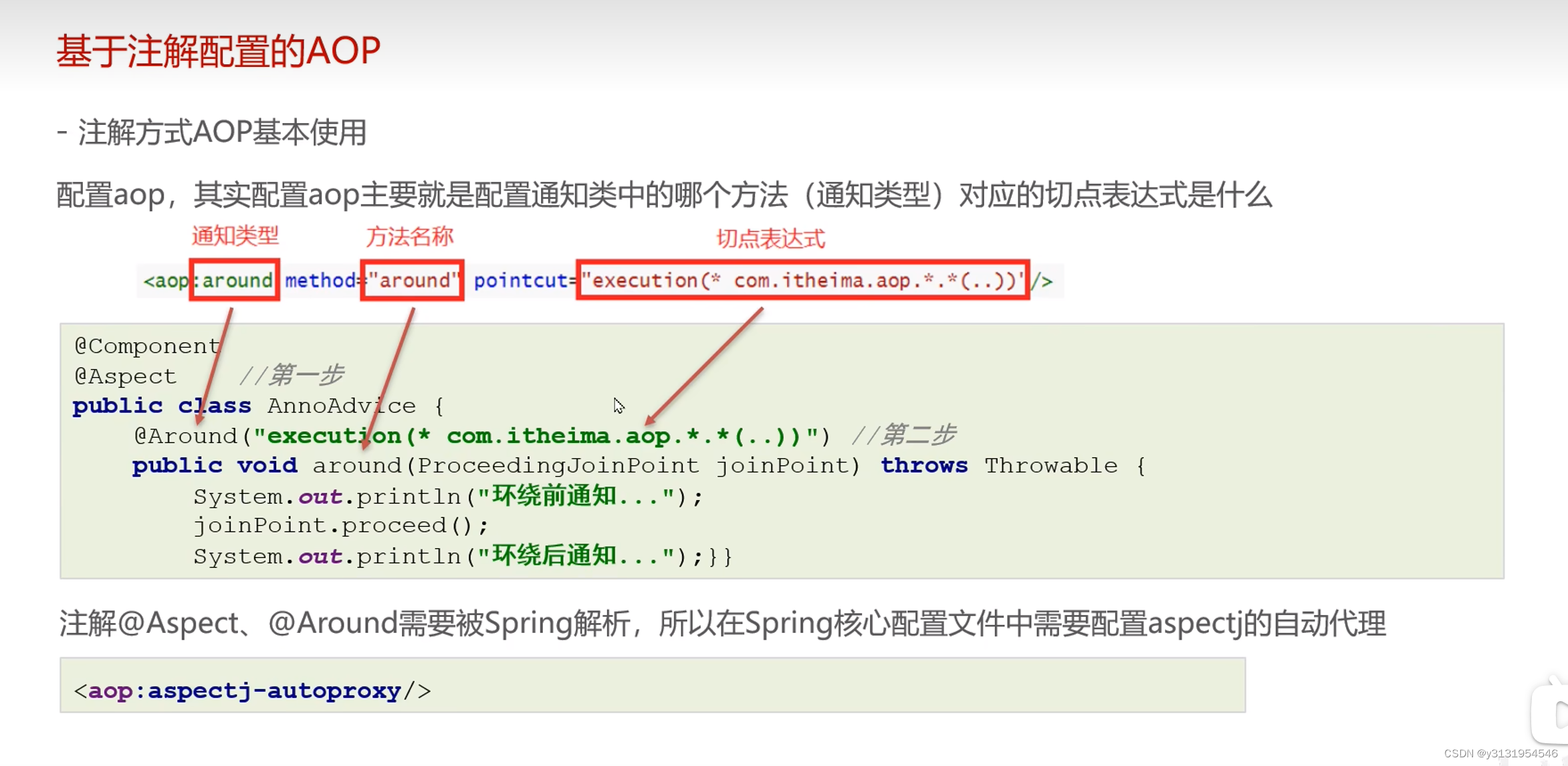
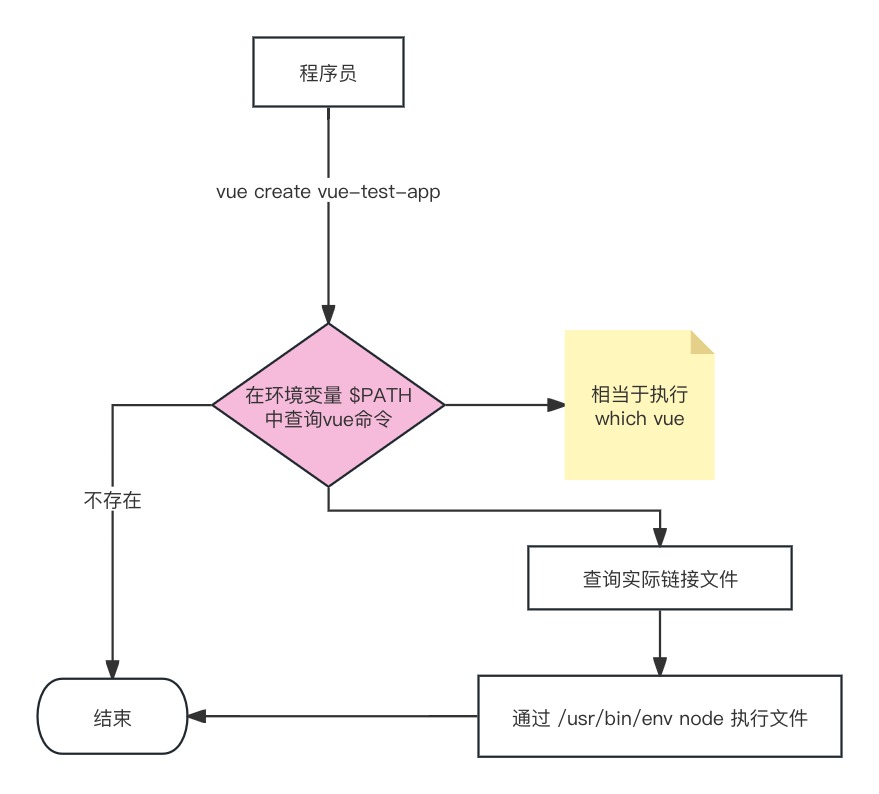
并发编程
我们主流的并发编程思路一般有:多进程、多线程
但这两种方式都需要操作系统介入,进入内核态,是十分大的时间开销
由此而来,一个解决该需求的技术出现了:用户级线程,也叫做 绿程、轻量级线程、协程
python - asyncio、java - netty22111111111111115
由于 go 语言是 web2.0 时代发展起来的语言,go语言没有多线程和多进程的写法,其只有协程的写法 golang - goroutine
func Print() {
fmt.Println("打印印")
}
func main() {
go Print()
}
我们可以使用这种方式来进行并发编程,但这个程序里要注意,我们主程序在确定完异步之后结束,会立即让程序退出,这就导致我们并发的子线程没来得及执行就退出了。
我们可以增加一个Sleep来让主线程让出资源,等待子线程执行完毕再进行操作
func Print() {
for {
time.Sleep(time.Second)
fmt.Println("打印印")
}
}
func main() {
go Print()
for {
time.Sleep(time.Second)
fmt.Println("主线程")
}
}
另外的,Go 语言协程的一个巨大优势是 可以打开成百上千个协程,协助程序效率的提升
要注意一个问题:
多进程的切换十分浪费时间,且及其浪费系统资源
多线程的切换也很浪费时间,但其解决了浪费系统资源的问题
协程既解决了切换浪费时间的问题,也解决了浪费系统资源的问题
Go语言仅支持协程
Go语言中,协程的调度(gmp机制):

用户新建的协程(Goroutine)会被加入到同一调度器中等待运行,若调度器满,则会将调度器中一半的 G 加入到全局队列中,其他 P 若没有 G 则会从其他 P 中偷取一半的 G ,若所有的都满,则会新建 M 进行处理
P 的数量是固定的
注意 M 和 P 不是永远绑定的,当一个 P 现在绑定的 M 进入了阻塞等情况,P 会自动去寻找空闲的 M 或创建新的 M 来绑定
子 goroutine 如何通知到主 goroutine 其运行状态?也就是我们主协程要知道子协程运行完毕之后再进行进一步操作,也就是 (wait)
func main() {
// 定义 sync.Group 类型的变量用于控制goroutine的状态
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
go func(i int) {
wg.Add(1) // 每次启动一个协程都要开启一个计数器
defer wg.Done() // 每次结束之前都要让计数器 -1
fmt.Println("这次打印了:" + strconv.Itoa(i))
}(i)
}
wg.Wait()
fmt.Println("结束..................................")
}
锁
Go语言中的锁
互斥锁
我们看下面这个程序:
var total int
var wg sync.WaitGroup
func add() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
total += 1
}
}
func sub() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
total -= 1
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total)
/*
-100001
100001
68595
...
*/
}
我们发现这个程序的结果不可预知,这是因为 a 的操作分为三步:
取得 a 的值、执行 a 的计算操作、写入 a 的值,这三步不是原子性的,如果发生了交叉,则一个数准备写入时发生协程切换,这时后面再做再多的操作,也会被这次切换屏蔽掉,最终写入这一个数的结果,由此可知,这种非原子性操作共享数据的模式是不可预知结果的。
那么,我们就需要加锁,像下面这样
var total int
var wg sync.WaitGroup
var lock sync.Mutex
var lockc = &lock
func add() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
lock.Lock() // 加锁,直至见到自己这把锁的 Unlock() 方法之前,令这中间的方法都为原子性的
total += 1
lock.Unlock() // 解锁,配合 Lock() 方法使用
}
}
func sub() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
lockc.Lock()
total -= 1
lockc.Unlock()
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total)
fmt.Printf("%p\n", &lock)
fmt.Printf("%p\n", &(*lockc))
}
注意,上面这个程序不仅演示了加锁,还演示了,浅拷贝不影响加锁的情况
另外,我们也可以使用 automic 对简单的数值计算进行加锁
var total int32
var wg sync.WaitGroup
var lock sync.Mutex
var lockc = &lock
func add() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
atomic.AddInt32(&total, 1)
}
}
func sub() {
defer wg.Done()
for i := 0; i <= 100000; i++ {
atomic.AddInt32(&total, -1)
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total)
}
读写锁
读写锁就是:允许同时读,不允许同时写,不允许同时读写
func main() {
var num int
var rwlock sync.RWMutex // 定义一个读写锁
var wg sync.WaitGroup // 定义等待处理器
wg.Add(2)
go func() {
defer wg.Done()
rwlock.Lock() // 写锁
defer rwlock.Unlock()
num = 12
}()
// 同步处理器,这里是简便处理
time.Sleep(1)
go func() {
defer wg.Done()
rwlock.RLock()
defer rwlock.RUnlock()
fmt.Println(num)
}()
wg.Wait()
}
一个简单的测试
func main() {
var rwlock sync.RWMutex // 定义一个读写锁
var wg sync.WaitGroup // 定义等待处理器
wg.Add(6)
go func() {
time.Sleep(time.Second)
defer fmt.Println("释放写锁,可以进行读操作")
defer wg.Done()
rwlock.Lock() // 写锁
defer rwlock.Unlock()
fmt.Println("得到写锁,停止读操作")
time.Sleep(time.Second * 5)
}()
for i := 0; i < 5; i++ {
go func() {
defer wg.Done()
for {
rwlock.RLock()
fmt.Println("得到读锁,进行读操作")
time.Sleep(time.Millisecond * 500)
rwlock.RUnlock()
}
}()
}
wg.Wait()
/**
得到读锁,进行读操作
得到写锁,停止读操作
释放写锁,可以进行读操作
得到读锁,进行读操作
得到读锁,进行读操作
得到读锁,进行读操作
*/
}
通信
Go 语言中对于并发场景下的通信,秉持以下理念:
不要通过共享内存来通信,要通过通信实现共享内存
其他语言都是用一个共享的变量来实现通信,或者消息队列,Go语言就希望实现队列的机制
var msg chan string //定义一个用于传递 string 的 channel
// 创建一个缓冲区大小为 1 的 channel
// 只有 有缓冲区的 channel 才可以暂存数据
msg = make(chan string, 1)
msg <- "data"
data := <-msg
fmt.Println(data)
只有 goroutine 中才可以使用缓冲区大小为 0 的channel
func main() {
var msg chan string //定义一个用于传递 string 的 channel
// 创建一个缓冲区大小为 1 的 channel
// 只有 有缓冲区的 channel 才可以暂存数据
msg = make(chan string, 0)
go func(msg chan string) {
data := <-msg
fmt.Println(data)
}(msg)
msg <- "data"
time.Sleep(time.Second * 3)
}
这时由于 go 语言 channel 中的 happen-before 机制,该机制保证了 就算先 receiver 也会被 goroutine 挂起,等待 sender 完成之后再进行 receiver 的具体执行
go 语言中,channel 的应用场景十分广泛,包括:
- 信息传递、消息过滤
- 信号广播
- 事件订阅与广播
- 任务分发
- 结果汇总
- 并发控制
- 同步异步
Go 语言的消息接收问题
func main() {
var msg chan string //定义一个用于传递 string 的 channel
// 创建一个缓冲区大小为 1 的 channel
// 只有 有缓冲区的 channel 才可以暂存数据
msg = make(chan string, 0)
go func(msg chan string) {
// 注意这里,每一个接收消息的变量只能接收到一个消息,若有多条消息同时发送,则无法接收
data := <-msg
fmt.Println(data)
math := <-msg
fmt.Println(math)
}(msg)
msg <- "data"
msg <- "math"
time.Sleep(time.Second * 3)
}
如果我们不知道消息会发送来多少,可以使用 for-range 进行监听:
func main() {
var msg chan string //定义一个用于传递 string 的 channel
// 创建一个缓冲区大小为 1 的 channel
// 只有 有缓冲区的 channel 才可以暂存数据
msg = make(chan string, 2)
go func(msg chan string) {
// 若我们不确定有多少消息会过来,我们可以使用 for-range 进行循环验证
for data := range msg {
fmt.Println(data)
}
}(msg)
msg <- "data"
msg <- "math"
time.Sleep(time.Second * 3)
}
close(msg) // 关闭队列,监听队列的 goroutine 会立刻退出
关闭了的 channel 不能再存储数据,但可以进行数据的取出操作
上面我们所接触的 channel 都是双向的 channel 即这个channel 对应的goroutine 既可以从里面读数据,也可以向里面写数据,这种不符合我们程序,一个程序只做它对应的一个功能,这一程序设计思路
创建单向 channel:
var ch1 chan int // 这是一个双向 channel
var ch2 chan<- float64 // 这是一个只能写入 float64 类型数据的单向 channel
var ch3 <-chan int // 这是一个只能从 存储int型 channel中读取数据的单向channel
c := make(chan int, 3) // 创建一个双向 channel
var send chan<- int = c // 将 c channel 的写入能力赋予给 send,使其成为一个单向发送的 channel (生产者)
var receive <-chan int = c // 将c channel 的读取能力赋予给receive,使其成为一个单向接收的 channel (消费者)
经典例子:
/**
经典:
使用两个 goroutine 交替打印:12AB34CD56EF78GH910IJ1112.....YZ2728
*/
var number, letter = make(chan bool), make(chan bool)
func printNum() {
// 这里是等待接收消息,若消息接收不到,则该协程会始终阻塞在这个位置
i := 1
for {
<-number
fmt.Printf("%d%d", i, i+1)
i += 2
letter <- true
}
}
func printLetter() {
i := 0
str := "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for {
<-letter
fmt.Print(str[i : i+2])
number <- true
if i <= 23 {
i += 2
} else {
return
}
}
}
func main() {
go printNum()
go printLetter()
number <- true
time.Sleep(time.Second * 20)
}
使用 select 对 goroutine 进行监控
// 使用 struct{} 作为传入的信息,由于这个 struct{} 占用内存空间较小,这是一种常见的传递方式
func g1(ch chan struct{}) {
time.Sleep(time.Second * 3)
ch <- struct{}{}
}
func g2(ch chan struct{}) {
time.Sleep(time.Second * 3)
ch <- struct{}{}
}
func main() {
g1Channel := make(chan struct{})
g2Channel := make(chan struct{})
go g1(g1Channel)
go g2(g2Channel)
// 注意这里只要有一个能取到值则 select 结果则结束
select {
// 若 g1Channel 中能取到值
case <-g1Channel:
fmt.Println("g1 done")
// 若 g1Channel 中能取到值
case <-g2Channel:
fmt.Println("g2 done")
}
}
这里若所有的 goroutine 都就绪了,则 select 执行哪个是随机的,为的是防止某个 goroutine 一直被优先执行导致的另一个 goroutine 饥饿
超时机制:
// 使用 struct{} 作为传入的信息,由于这个 struct{} 占用内存空间较小,这是一种常见的传递方式
func g1(ch chan struct{}) {
time.Sleep(time.Second * 3)
ch <- struct{}{}
}
func g2(ch chan struct{}) {
time.Sleep(time.Second * 3)
ch <- struct{}{}
}
func main() {
g1Channel := make(chan struct{})
g2Channel := make(chan struct{})
go g1(g1Channel)
go g2(g2Channel)
timeChannel := time.NewTimer(5 * time.Second)
for {
// 注意这里只要有一个能取到值则 select 结果则结束
select {
// 若 g1Channel 中能取到值
case <-g1Channel:
fmt.Println("g1 done")
// 若 g1Channel 中能取到值
case <-g2Channel:
fmt.Println("g2 done")
case <-timeChannel.C: // timeChannel.C 是获取我们创建的 channel 的方法
fmt.Println("time out")
return
}
}
}
context
使用 WithCancel() 引入手动终止进程的功能
func cpuIInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done(): // 本质还是一个 channel
fmt.Println("程序退出执行...........")
return
default:
time.Sleep(1 * time.Second)
fmt.Println("CPUUUUUUUUUUUUUU")
}
}
}
func main() {
/**
这里有一个问题,我们可以将以 context.Background() 为参数的 context 是作为最上层的父 context
所有以其他 context 为参数的 context 都是他的子 context
只要父 context 调用了 cancel() 则其所有的子 context 都会停止
*/
ctxParent, cancel := context.WithCancel(context.Background())
ctxChild, _ := context.WithCancel(ctxParent)
wg.Add(1)
go cpuIInfo(ctxChild)
time.Sleep(5 * time.Second)
cancel() // 这个方法会直接向context channel 中传入一个对象,令channel停止
wg.Wait()
}
使用 WthTimeout() 来自动引入超时退出机制
var wg sync.WaitGroup
func cpuIInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done(): // 本质还是一个 channel
fmt.Println("程序退出执行...........")
return
default:
time.Sleep(1 * time.Second)
fmt.Println("CPUUUUUUUUUUUUUU")
}
}
}
func main() {
/**
这里有一个问题,我们可以将以 context.Background() 为参数的 context 是作为最上层的父 context
所有以其他 context 为参数的 context 都是他的子 context
只要父 context 调用了 cancel() 则其所有的子 context 都会停止
*/
ctxParent, _ := context.WithTimeout(context.Background(), 6*time.Second)
ctxChild, _ := context.WithCancel(ctxParent)
wg.Add(1)
go cpuIInfo(ctxChild)
wg.Wait()
}
WithDeadline() 是指定某个时间点,在某个时间点的时候进行执行
WithValue() 则会向 context 中传递一个数据,我们可以在子 goroutine 中调用这个数据
var wg sync.WaitGroup
func cpuIInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done(): // 本质还是一个 channel
fmt.Println("程序退出执行...........")
return
default:
time.Sleep(1 * time.Second)
fmt.Printf("%s", ctx.Value("LeaderID"))
fmt.Println("CPUUUUUUUUUUUUUU")
}
}
}
func main() {
/**
这里有一个问题,我们可以将以 context.Background() 为参数的 context 是作为最上层的父 context
所有以其他 context 为参数的 context 都是他的子 context
只要父 context 调用了 cancel() 则其所有的子 context 都会停止
*/
ctxParent, _ := context.WithTimeout(context.Background(), 6*time.Second)
ctxChild := context.WithValue(ctxParent, "LeaderID", "00001") // 注意 WithValue 方法只有一个返回值
wg.Add(1)
go cpuIInfo(ctxChild)
wg.Wait()
}