文章目录
- RNN结构
- RNN实战
- RNN小结
RNN结构
NPLM 在处理长序列时会面临一些挑战。首先,由于它仍然是基于词的模型,因此在处理稀有词汇或者词汇表外的词汇时效果不佳。其次,NPLM不能很好地处理长距离依赖关系。而上面这两个局限,恰恰就是RNN的优势。
RNN的核心思想是利用“循环”的机制,将网络的输出反馈到输入,这使得它能够在处理数据时保留前面的信息,从而捕获序列中的长距离依赖关系,在处理序列数据,如文本、语音和时间序列时具有明显的优势。
RNN可以看作一个具有“记忆”的神经网络。RNN的基本原理是通过循环来传递隐藏状态信息,从而实现对序列数据的建模。一个简单的RNN包括输入层、隐藏层和输出层。在每个时间步(可理解为每次循环的过程),RNN会读取当前输入,并结合前一个时间步的隐藏状态来更新当前的隐藏状态。然后,这个隐藏状态会被用于生成输出和更新下一个时间步的隐藏状态。通过这种方式,RNN可以推获序列中的依赖关系。最后,输出层根据隐藏层的信息产生预测。
通过在每个时间步共享权重(即在处理各个token时使用相同的RNN),RNN
能够处理不同长度的输入序列。这种权重共享机制使得RNN 具有很大的灵活性,因为它可以适应各种长度的序列,在处理自然语言和其他可变长度序列数据时更具优势,而不像NPLM 那样受到窗口大小固定的限制。
RNN的基本架构图:
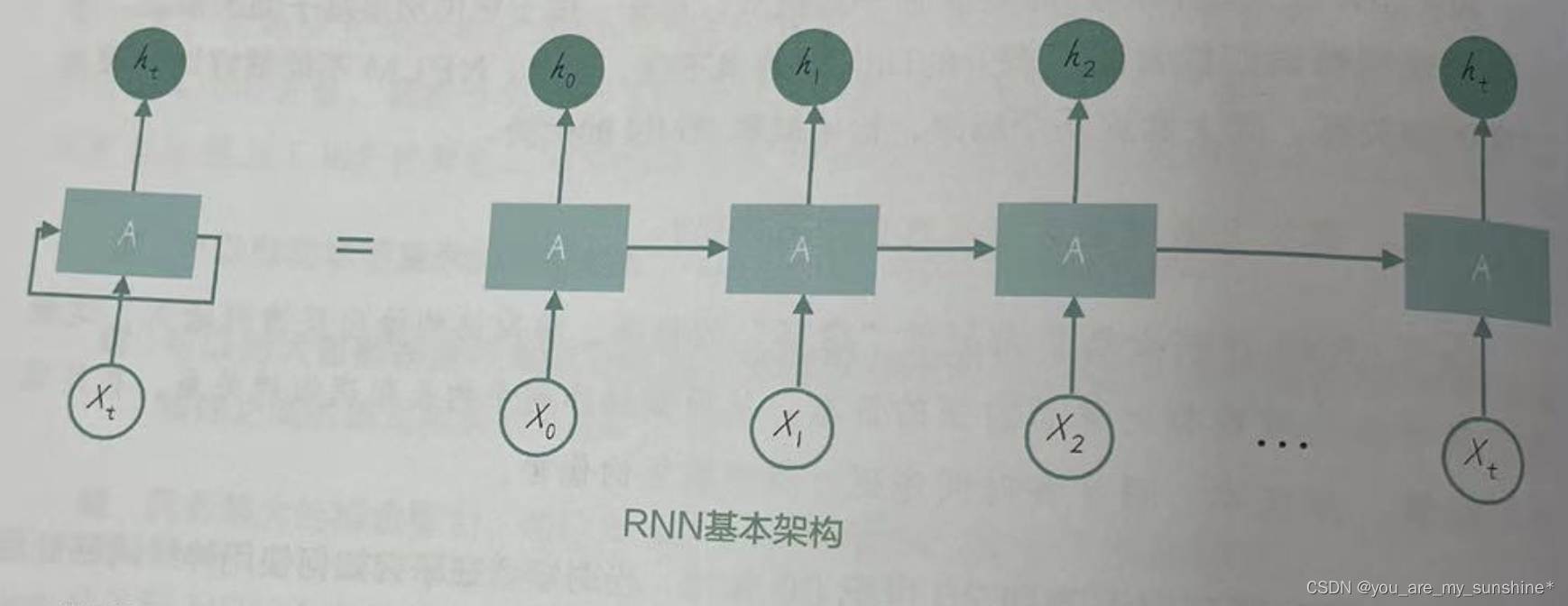
例如一段文本。我们可以将这段文本分成单词或字符,并将其作为 RNN 的输入。对于每一个时间步,RNN会执行以下操作。
(1)接收前时间步的输入x_t(即上图中的xt)。
(2)结合前一时间步的隐藏层状态h_(t-1),计算当前时间步的隐藏层状态 h_t(即上图中的ht)。这通常通过一个激活函数(如tanh函数)实现。计算公式如下(其中, W_hh 是隐藏层到隐藏层的权重矩阵,W_xh是输入到隐藏层的权重矩阵):
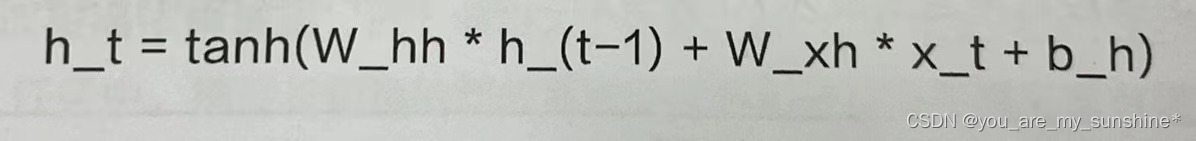
(3)基于当前时间步的隐藏层状态h_t,计算输出层y_t(RNN在时间步t的输出)。
这通常通过一个线性变换和激活函数(如softmax函数)实现。计算公式如下:

通过上述操作,RNN可以处理整个序列数据,并在每个时间步生成一个输出。需要注意的是,RNN具有参数共享的特性。这意味着在不同时间步,RNN 使用相同的权重矩阵(W_hh,W_xh和W_hy)和偏置(b_h和b_y)进行计算。
RNN虽然在某些方面具有优势,但它的局限性也不容忽视。在训练过程中,RNN可能会遇到梯度消失和梯度爆炸的问题,这会导致网络很难学习长距离依赖关系。为了解决这些问题,研究人员提出了LSTM 和 GRU等改进型RNN结构。LSTM、GRU广义上属于 RNN,不过这些结构引入了门控机制,使得模型能够更好地捕捉到序列中的长距离依赖关系,从而在许多NLP 任务中表现更优。
RNN实战
我们使用了一个LSTM层替换了NPLM原有的线性层。之后,定义了一个基于RNN的语言模型,它包含一个嵌入层、一个LSTM层和一个线性层。该模型将输入的词序列转换为嵌入向量,将嵌入向量输入LSTM层中,并将LSTM层的输出传递到线性层中,以生成最终的输出。其中LSTM层的输入是词嵌入,输出是在每个时间步的隐藏状态。我们只选择最后一个时间步的隐藏状态作为全连接层的输入,以生成预测结果。
在 RNN 模型中,网络结构主要取决于以下几个参数。
(1)词嵌入大小embedding_size:决定了词嵌入层的输出维度。
(2)隐藏层大小n_hidden:决定了LSTM(或其他RNN变体)层的隐藏状态大小。
这意味着,在RNN模型中,我们可以灵活地处理不同长度的输入序列,而不需要改变网络结构。这是RNN模型与NPLM的一个重要区别。这使得RNN模型在处理自然语言任务时更具优势,因为它可以很好地处理不同长度的文本序列。
循环神经网络中的种种细节,比如隐藏层状态的计算 h_t = tanh(W_hh * h_(t-1) + W_xh *x_t + b_h),又比如基于当前时间步的隐藏层状态 h_t,计算输出层 y_t的线性变换和激活,为什么在代码中都没有体现?
其实,这是因为RNN实现的细节已经被封装在PyTorch的LSTM层了。这里的代码1stm_out._=self.1stm(X)虽然很简洁,但实际上它涵盖了LSTM处理输入序列的复杂计算过程。对于输入序列 X,LSTM会逐时间步处理,每个时间步的输入不仅包括当前时间步的数据,还会接收上一时间步的隐藏层状态。这样,信息就在时间步之间传递,形成一种循环。在每个时间步,通过LSTM内部的门控机制,网络计算并更新当前的状态,并生成对应的输出。
在处理输入序列时,LSTM内部会进行以下操作。
对于每个时间步t,LSTM会接收当前时间步的输入x_t及上一个时间步的隐藏状态h_(t-1) 和细胞状态c_(t-1)。
接着,LSTM会计算输入门、遗忘门和输出门的激活值。这些门控机制使得 LSTM 能够有选择地保留或遗忘之前的信息,从而更好地捕捉长距离依赖关系。
这些门的计算公式如下。

其中,w_ii是从当前输入x_t到输入门的权重矩阵,而W_hi是从前一时间步的隐藏状态h_(t-1)到输入门的权重矩阵。W_if是从当前输入x_t到遗忘门的权重矩阵,W_hf是从前一时间步的隐藏状态h_(t-1)到遗忘门的权重矩阵。W_io是从当前输入x_t到输出门的权重矩阵,W_ho是从前一时间步的隐藏状态h_(t-1)到输出门的权重矩阵。偏置项b_ii、b_hi、b_if、b_hf、b_io 和 b_ho,即各自门控或单元的偏置。以上所有的权重矩阵和偏置项都是在模型的训练过程中通过反向传播和优化算法学习得到的。
LSTM更新细胞状态c_t。这是通过结合输入门、遗忘门和当前输入的信息来实现的。计算公式如下。
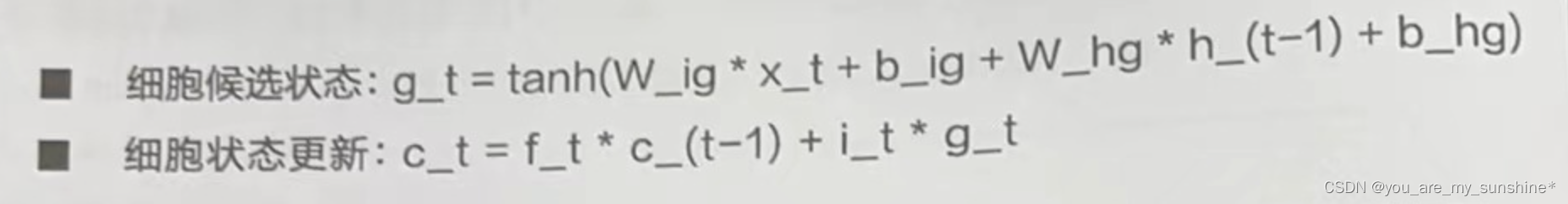
最后,LSTM 会计算当前时间步的隐藏状态h_t,这通常作为输出。计算公式如下。

在整个循环过程中,LSTM会逐时间步处理输入序列,并产生对应的输出。这使得LSTM 能够捕捉到输入序列中的长距离依赖关系,并在各种NLP任务中表现出优越的性能。
不过,你要注意到,在我们的循环神经网络中,n_step这个参数将不再出现。理解这个差异有助于你了解原始的NPLM 和 RNN 模型的本质区别。
-
在NPLM 中,n_step作为一个重要参数,直接影响模型的结构。具体来说,n_step决定了模型中第一个线性层的输入大小(n_step * m)。这是因
为NPLM 会将词嵌入层的输出展平,然后将其输入第一个线性层。因此,n_step 的值将直接影响线性层的输入大小,从而影响整个模型的结构。 -
在RNN模型中,因为RNN模型是专门为处理任意长度的序列数据设计的,我们会将词嵌入层的输出直接输入LSTM(或其他RNN变体)层,而不需要将其展平。因此,输入序列的长度不会影响网络结构。
RNN模型在处理序列数据时具有优势,因为它们可以捕捉序列中的长距离依赖关系。在本例中,我们构建了一个基于LSTM 的 RNN模型,能够更好地捕捉长距离依赖。虽然在这个简单的示例中,模型的改进可能不会显著提高效率,但在处理更复杂的自然语言任务时,LSTM的性能通常会比简单的线性模型更好。
RNN并不是NLP任务的完美解决方案,它的局限性主要包括以下几点。
- 顺序计算:这些网络在处理序列时,需要按照时间步的顺序进行计算。这意味着在某个时间步的计算完成之前,无法进行下一个时间步的计算。这种顺序计算限制了这些网络的并行计算能力,从而降低了计算效率和速度。
- 长距离依赖问题:尽管LSTM 和GRU等RNN变体拥有了更好的记忆功能,但在处理非常长的序列时,这些网络仍然可能无法完全捕捉到序列中的长距离依赖关系。
- 有限的可扩展性:RNN及其变体在面对更大规模的数据集和更复杂的任务时,可能会遇到扩展性问题。随着序列长度的增加,它们的计算复杂性也会增加,这可能导致训练时间过长和资源需求过高。
在RNN时代,NLP应用落地整体表现不佳的原因有以下几点。
- 模型表达能力不足:尽管RNN及其变体在某些任务中取得了不错的成果,但它们的表达能力可能不足以处理复杂的NLP任务。这是因为自然语言中的依赖关系和语义结构可能非常复杂,而这些网络可能无法捕捉到全部信息。
- 缺乏大规模数据:在RNN时代,大规模的预训练数据集和计算资源相对较少。这使得模型难以从大量的无监督文本数据中学习到丰富的语言知识,从而影响了它们在实际应用中的表现。
- 优化算法发展不足:在RNN时代,优化算法仍处在相对初级的阶段,可能无法充分利用可用的数据和计算资源。这可能导致模型训练过程中的梯度消失、梯度爆炸等问题,从而影响模型的性能和稳定性。
# 构建一个非常简单的数据集
sentences = ["我 喜欢 玩具", "我 爱 爸爸", "我 讨厌 挨打"]
# 将所有句子连接在一起,用空格分隔成多个词,再将重复的词去除,构建词汇表
word_list = list(set(" ".join(sentences).split()))
# 创建一个字典,将每个词映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print(' 词汇表:', word_to_idx) # 打印词汇到索引的映射字典
print(' 词汇表大小:', voc_size) # 打印词汇表大小

# 构建批处理数据
import torch # 导入 PyTorch 库
import random # 导入 random 库
batch_size = 2 # 每批数据的大小
def make_batch():
input_batch = [] # 定义输入批处理列表
target_batch = [] # 定义目标批处理列表
selected_sentences = random.sample(sentences, batch_size) # 随机选择句子
for sen in selected_sentences: # 遍历每个句子
word = sen.split() # 用空格将句子分隔成多个词
# 将除最后一个词以外的所有词的索引作为输入
input = [word_to_idx[n] for n in word[:-1]] # 创建输入数据
# 将最后一个词的索引作为目标
target = word_to_idx[word[-1]] # 创建目标数据
input_batch.append(input) # 将输入添加到输入批处理列表
target_batch.append(target) # 将目标添加到目标批处理列表
input_batch = torch.LongTensor(input_batch) # 将输入数据转换为张量
target_batch = torch.LongTensor(target_batch) # 将目标数据转换为张量
return input_batch, target_batch # 返回输入批处理和目标批处理数据
input_batch, target_batch = make_batch() # 生成批处理数据
print(" 输入批处理数据:",input_batch) # 打印输入批处理数据
# 将输入批处理数据中的每个索引值转换为对应的原始词
input_words = []
for input_idx in input_batch:
input_words.append([idx_to_word[idx.item()] for idx in input_idx])
print(" 输入批处理数据对应的原始词:",input_words)
print(" 目标批处理数据:",target_batch) # 打印目标批处理数据
# 将目标批处理数据中的每个索引值转换为对应的原始词
target_words = [idx_to_word[idx.item()] for idx in target_batch]
print(" 目标批处理数据对应的原始词:",target_words)

import torch.nn as nn # 导入神经网络模块
# 定义循环神经网络(RNN)
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__() # 调用父类的构造函数
self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层
# 用 LSTM 层替代第一个线性层,其输入大小为 embedding_size,隐藏层大小为 n_hidden
self.lstm = nn.LSTM(embedding_size, n_hidden, batch_first=True)
# 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小
self.linear = nn.Linear(n_hidden, voc_size)
def forward(self, X): # 定义前向传播过程
# 输入数据 X 张量的形状为 [batch_size, n_step]
X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]
# 通过 LSTM 层
lstm_out, _ = self.lstm(X) # lstm_out 形状变为 [batch_size, n_step, n_hidden]
# 只选择最后一个时间步的输出作为全连接层的输入,通过第二个线性层得到输出
output = self.linear(lstm_out[:, -1, :]) # output 的形状为 [batch_size, voc_size]
return output # 返回输出结果
n_step = 2 # 时间步数,表示每个输入序列的长度,也就是上下文长度
n_hidden = 2 # 隐藏层大小
embedding_size = 2 # 词嵌入大小
model = RNN() # 创建循环神经网络模型实例
print(' RNN 模型结构:', model) # 打印模型的结构

import torch.optim as optim # 导入优化器模块
criterion = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.1) # 定义优化器为 Adam,学习率为 0.1
# 训练模型
for epoch in range(5000): # 设置训练迭代次数
optimizer.zero_grad() # 清除优化器的梯度
input_batch, target_batch = make_batch() # 创建输入和目标批处理数据
output = model(input_batch) # 将输入数据传入模型,得到输出结果
loss = criterion(output, target_batch) # 计算损失值
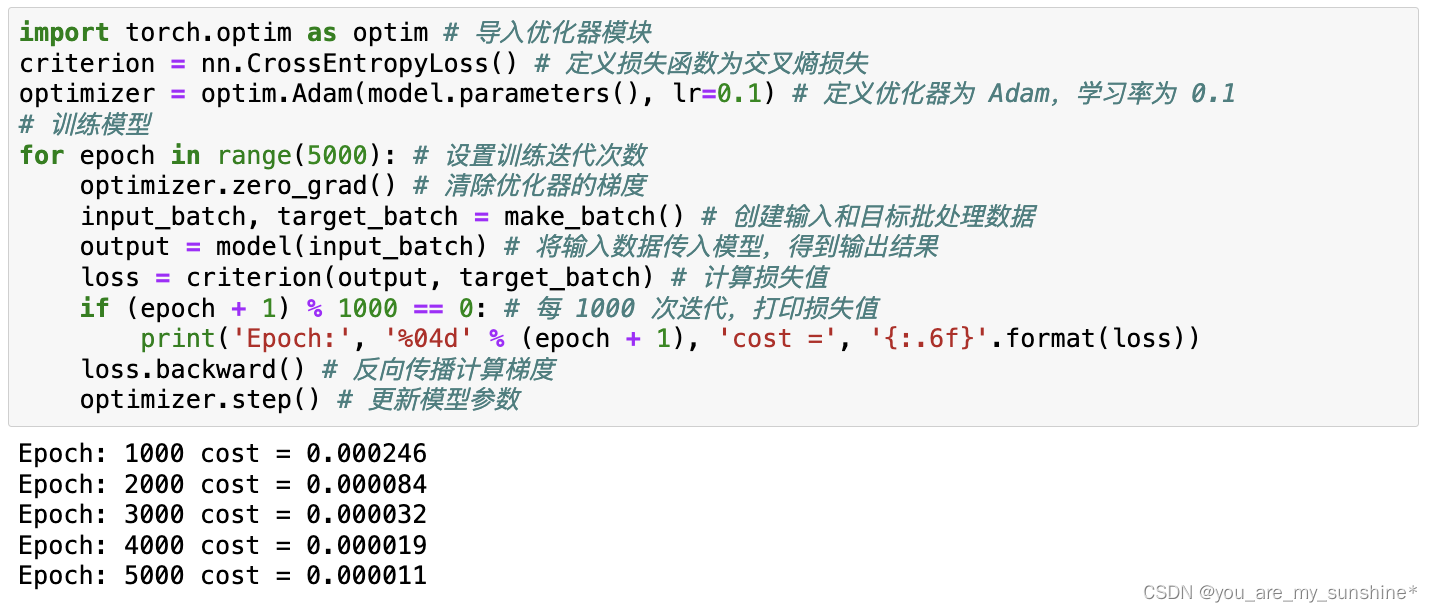
if (epoch + 1) % 1000 == 0: # 每 1000 次迭代,打印损失值
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
# 进行预测
input_strs = [['我', '讨厌'], ['我', '喜欢']] # 需要预测的输入序列
# 将输入序列转换为对应的索引
input_indices = [[word_to_idx[word] for word in seq] for seq in input_strs]
# 将输入序列的索引转换为张量
input_batch = torch.LongTensor(input_indices)
# 对输入序列进行预测,取输出中概率最大的类别
predict = model(input_batch).data.max(1)[1]
# 将预测结果的索引转换为对应的词
predict_strs = [idx_to_word[n.item()] for n in predict.squeeze()]
for input_seq, pred in zip(input_strs, predict_strs):
print(input_seq, '->', pred) # 打印输入序列和预测结果

RNN小结
RNN
优势:
核心思想是利用“循环”的机制,将网络的输出反馈到输入,这使得它能够在处理数据时保留前面的信息,从而捕获序列中的长距离依赖关系,在处理序列数据,如文本、语音和时间序列时具有明显的优势。
劣势:
并行计算(降低了计算效率和速度)、
长距离依赖问题(但在处理非常长的序列时,这些网络仍然可能无法完全捕捉到序列中的长距离依赖关系)、
有限的可扩展性(随着序列长度的增加,它们的计算复杂性也会增加,这可能导致训练时间过长和资源需求过高)
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…