Netty体系如何使得ByteBuf根据实际IO收发数据场景进行自适应扩容缩容的?
IO收发数据的过程:
read 读取("I"):网卡硬件通过网络传输介质读取对端传输过来的数据,网卡硬件再把数据写到recv-socket缓冲区,应用程序编写逻辑把recv-socket缓冲区的数据读取到ByteBuf。
write 写出("O"): 应用程序写到ByteBuf,ByteBuf的数据再flush刷新到send-socket缓冲区,send-socket再把数据写到网卡硬件,网卡硬件通过网络传输介质传输给对端。
像之前我们使用Netty进行开发时,最寻常的方式是如何申请一个ByteBuf空间?
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer();
但是这样申请ByteBuf空间具有一个弊端:ByteBuf是固定空间大小的,导致收发socket缓冲区的数据时,ByteBuf可能过大或过小,如果Netty体系可以封装一种方法逻辑去使得ByteBuf自适应的扩容缩容,那么可以最大程度的利用ByteBuf 并且最大利用的提升IO收发数据的性能。
Netty是怎么做的?
是由如下AbstractNioByteChannel类中核心逻辑链路read方法:

- 开始分析
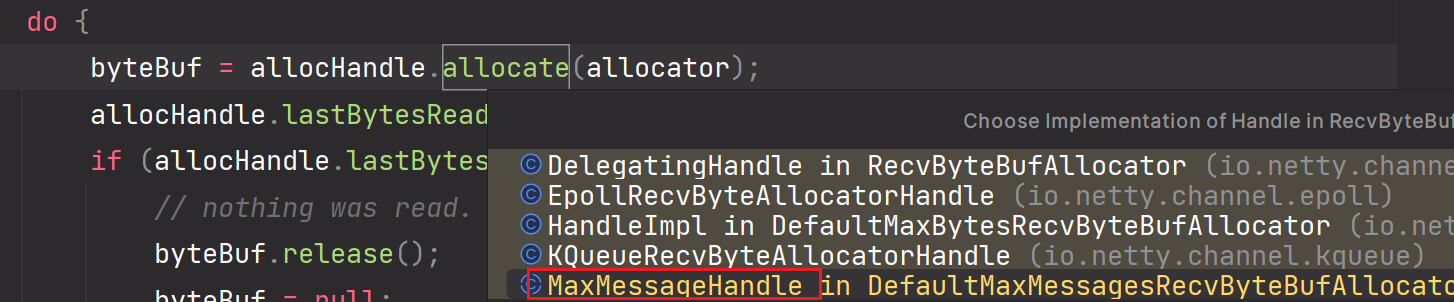
1.Netty封装了一个自适应实际场景变化大小的ByteBuf,比原生直接通过ByteBufAllocator.allocate()创建ByteBuf要灵活的多。原生创建ByteBuf的方式导致ByteBuf的大小固定不可变。

2.

为什么IO基本上都是使用直接内存?
因为对于IO这种强阻塞,高数据量的传输操作,其实使用直接内存的目的就是为了减少数据的拷贝,实现零拷贝。IO收发数据量过大,使用直接内存可以极大的减少数据的拷贝次数。
如何申请直接内存?通过Unsafe。
Unsafe:跳过JVM虚拟机,直接操控操作系统所管理的内存资源。
原来:java--->JVM--->OS--->计算机内存
引入Unsafe后:java(Unsafe)--->OS--->计算机内存
直接内存的创建,其实底层就是使用Unsafe这个类去直接向操作系统申请了一块内存。
非直接内存其实就是堆内存,也就是向JVM申请的堆内存。JVM通过自身的C++程序再向OS操作系统去申请真正的内存空间。这样性能就差了很多。
JUC的CAS很多类底层都是Unsafe做的,所以性能高。比如说:AtomicInteger
3.

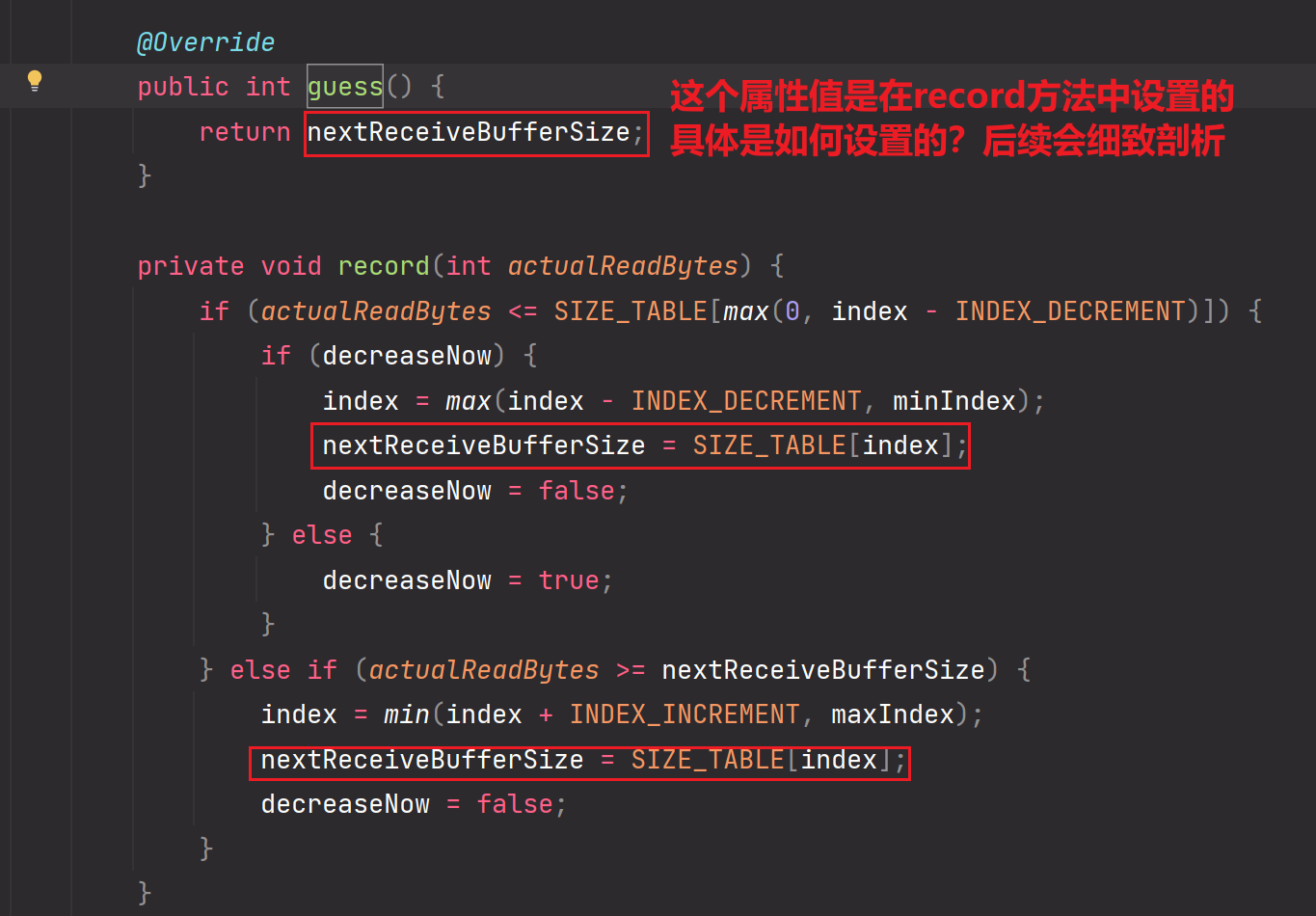
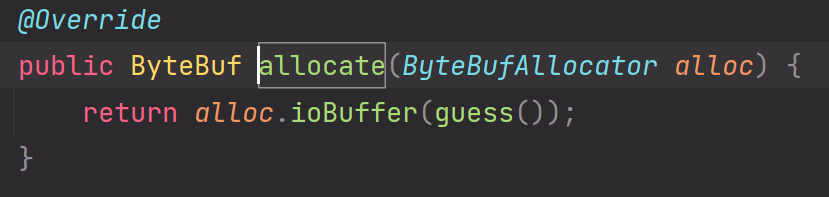
4.guess()方法,返回nextReceiveBufferSize。该属性值代表当前我们应该把ByteBuf缓冲区的大小设置成nextReceiveBufferSize大小。该值的大小是通过上一次ByteBuf的读取情况进行动态变化的,具体是如何进行自适应变化得出的?后续慢慢分析。
5.
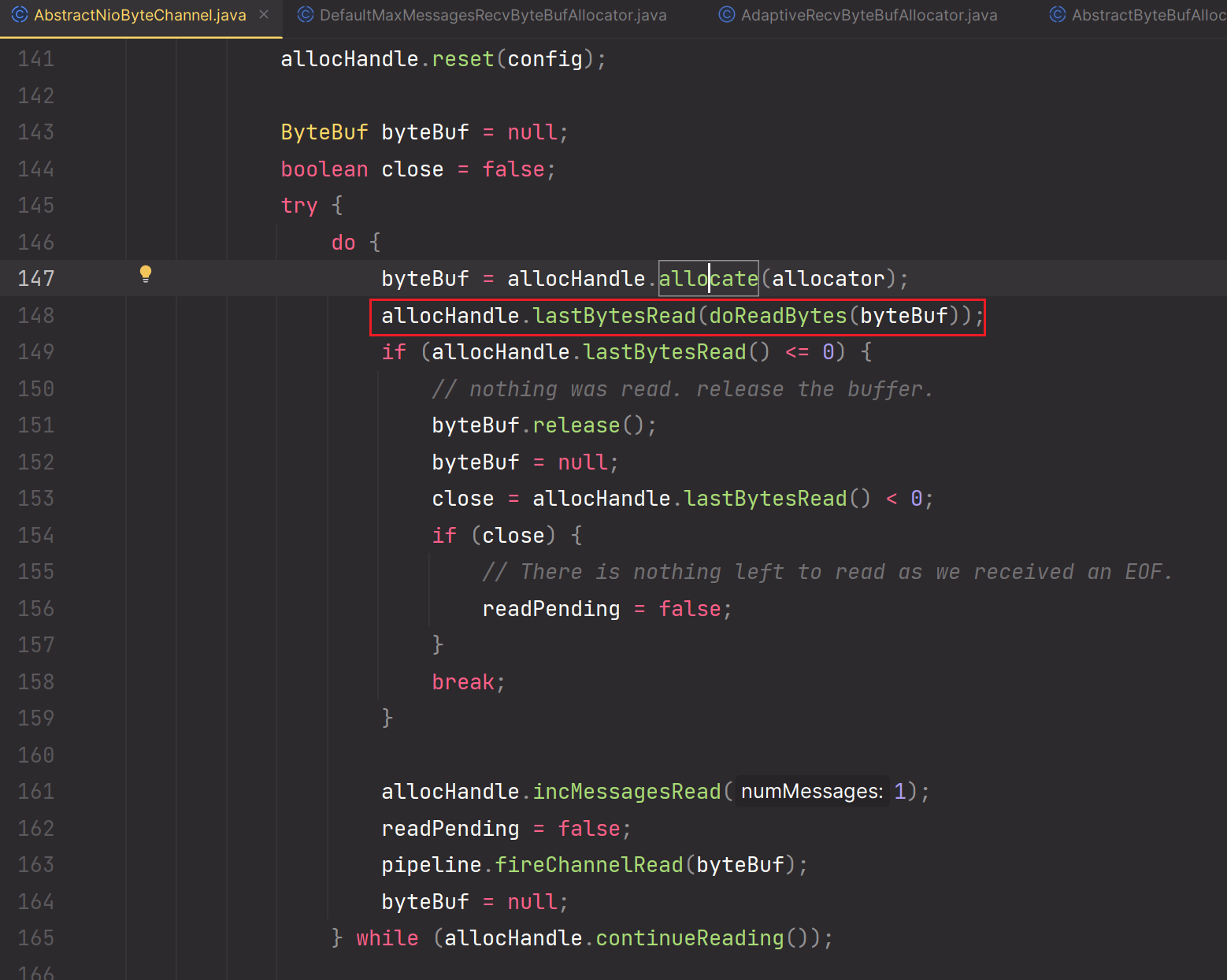
6.doReadBytes方法


recvBufAllocatorHandle()
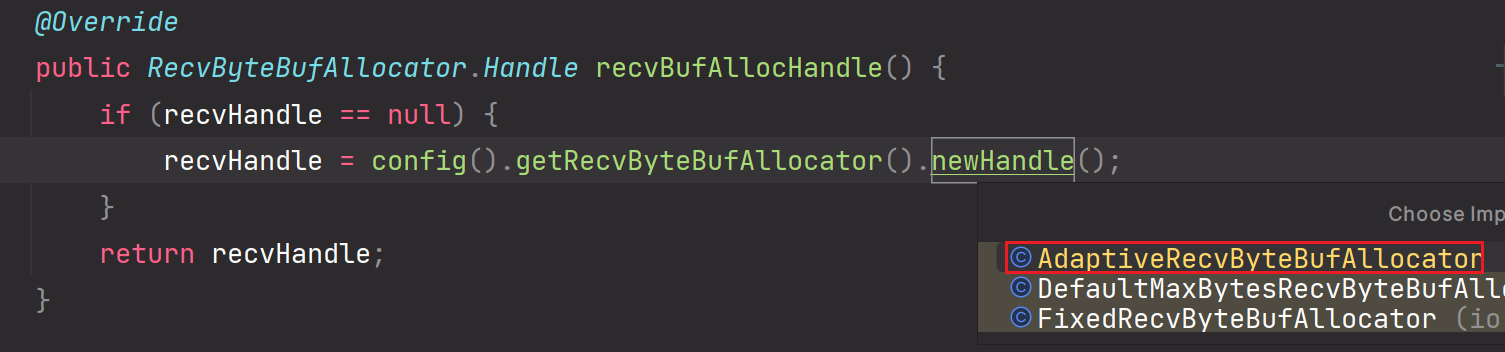

7.


8.static静态代码块中的代码会执行加载一次

分析static静态代码块的代码逻辑:
ByteBuf自适应扩容池sizeTable中有许多ByteBuf可选的值大小,但是sizeTable中的数据值是具有一定规律的,规律如下:
1.当可选值大小小于512时,从16开始递增,每次递增16,把每一个可选值加入到sizeTable中。在第一个for循环结束后,sizeTable这一自适应扩容池中有可选值:16,32,48,64,80,96,112,.........,512
2.当可选值达到512,且不超过int整型最大值【不包含int整型最大值】的范围之间,可选值按照2倍的大小进行递增。所以在第二个for循环结束后,sizeTable这一自适应扩容池中有可选值:16,..........,512,1024,2048,.........,Integer.MAX_VALUE / 2
当sizeTable集合初始化完成后,创建SIZE_TABLE数组,把集合中的所有元素都放入到SIZE_TABLE数组中。
9.传入一个size,在扩容池SIZE_TABLE中找到一个与size最相近的可选值,并且返回该可选值所对应的索引下标。查找利用的是二分查找法。

10.

11.前面的准备工作,属性初始化工作都做完后,这里展开分析record自适应扩缩容ByteBuf的核心逻辑:
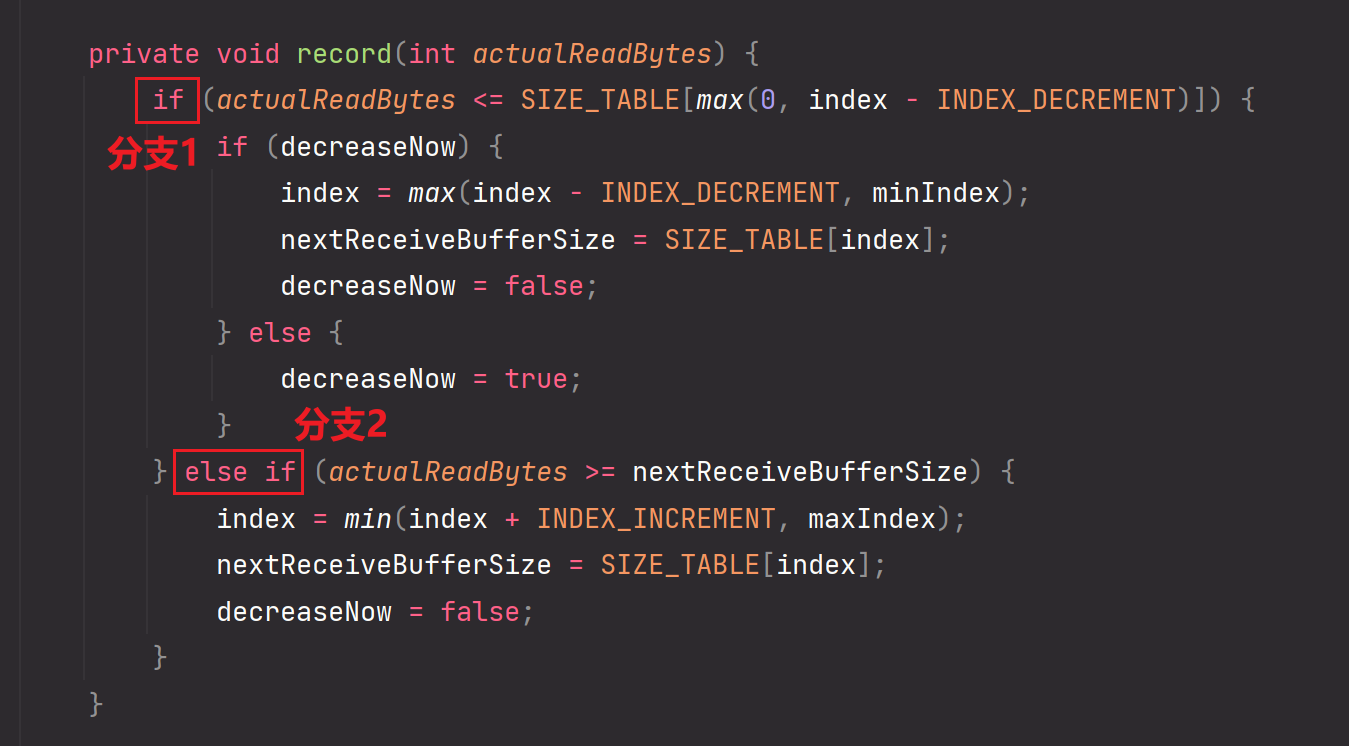
分支1:INDEX_DECREMENT=1,为递减频率。
max(0,index-INDEX_DECREMENT):二者找到一个最大值。意思就是最小递减到0
SIZE_TABLE[max(0,index-INDEX_DECREMENT)]:表示最低递减到可选值为16的ByteBuf,也就是索引值为0所对应的元素值
如果actualReadBytes(实际要从socket缓冲区读取到ByteBuf的数据大小) 小于等于 SIZE_TABLE[max(0,index-INDEX_DECREMENT)],说明可以自适应缩容。你思考一下,你都往前找一个可选值了,结果实际读取的ByteBuf数据大小还是小于等于该已经假设递减过的数据值了,那么说明当前ByteBuf在往前缩小一个后还是使用不完全,那么你是不是可以把ByteBuf缩小到该假设递减到的大小。
但是Netty这里又做了一层逻辑,兜底,第一次判断为true后,由于decreaseNow=false,不会真正的缩容。但是当第二次读取又一次进入该record方法时,还是判断出if为true,那么又一次说明真的用不完,那么因为此时decrease=true,所以可以进入内层if分支,那么可以真正的执行缩容逻辑,并且把decreaseNow置为false。eg:把32执行一次这个缩容逻辑,最终变为16
分支2:INDEX_INCREMENT=4
如果actualReadBytes(实际要从socket缓冲区读取到ByteBuf的数据大小) 大于或等于当前ByteBuf的大小时,我们需要进行扩容操作。扩容时是按照频率INDEX_INCREMENT=4进行扩容,也就是每次向后跳四个可选值的频率进行递增。但是ByteBuf最大值不可以超过Integer.MAX_VALUE/2。同理会做很多处理逻辑。eg:把16执行一遍这个扩容逻辑,最终变为80
并且把decreaseNow置为false。
12.
所以:
这一轮我们通过record方法可能设置出的nextReceiveBufferSize的变量值大小,最终下一次do while再循环到调用allocate方法时,其中调用ioBuffer方法申请大小时,参数使用的guess()方法就会使用到上一次设置的nextReceiveBufferSize的值大小。
13.至此,Netty构建的ByteBuf的扩容缩容机制也就分析结束了。







![力扣精选算法100道——和为 K 的子数组[前缀和专题]](https://img-blog.csdnimg.cn/direct/173b9e1be6ed43e9afc25073148b7af1.png)


![【蓝桥杯冲冲冲】[NOIP2017 提高组] 宝藏](https://img-blog.csdnimg.cn/img_convert/0133354571d6164ee90cda7abb9e9549.png)