目录
激活函数分类
区别与优缺点
饱和激活函数
非饱和激活函数
综合考虑
Sigmoid激活函数
Tanh激活函数
ReLU激活函数
Leaky Relu激活函数
Swish激活函数
激活函数分类
激活函数可以分为两大类 :
- 饱和激活函数:sigmoid、tanh
- 非饱和激活函数: ReLU、Leaky Relu、ELU【指数线性单元】、PReLU【参数化的ReLU 】、RReLU【随机ReLU】
区别与优缺点
饱和激活函数
-
Sigmoid:
- 优点:
- 平滑,输出值在0到1之间,适合用于输出概率。
- 易于理解和实现。
- 缺点:
- 梯度消失问题:当输入值过大或过小时,梯度接近0,使得网络难以学习。
- 输出不是零中心的:使得优化过程更加复杂。
- 应用场景: 主要用于二分类问题,如逻辑回归中。
- 优点:
-
Tanh:
- 优点:
- 输出值在-1到1之间,是零中心的,有利于数据的表示。
- 比Sigmoid更加有效,因为其梯度更强。
- 缺点:
- 同样存在梯度消失问题。
- 应用场景: 适合处理需要考虑正负数的场景,如音频处理。
- 优点:
非饱和激活函数
-
ReLU(Rectified Linear Unit):
- 优点:
- 计算简单,加速了网络的训练。
- 缓解了梯度消失问题,特别是在网络较深时。
- 缺点:
- “死亡ReLU”问题:部分神经元可能永远不会被激活,导致信息丢失。
- 应用场景: 目前在大多数深度学习网络中被广泛使用,特别是在卷积神经网络中。
- 优点:
-
Leaky ReLU, PReLU, ELU 等变体:
- 优点:
- 尝试解决死亡ReLU问题。
- 在某些情况下,可以提供比标准ReLU更好的性能。
- 缺点:
- 可能会导致训练过程更复杂。
- 应用场景: 在需要缓解死亡ReLU问题的场景下,如GANs或更深的网络结构。
- 优点:
综合考虑
- 在选择激活函数时,应根据具体问题和网络结构来决定。
- 对于一般的深度学习问题,ReLU及其变体通常是首选,因为它们提供了良好的性能和快速的训练。
- 对于需要输出概率或者处理更复杂的非线性问题的场景,可能会考虑使用Sigmoid或Tanh。
Sigmoid激活函数
sigmoid函数也叫Logistic函数,用于隐藏层的输出,输出在(0,1)之间,它可以将一个实数映射到(0,1)的范围内,可以用来做二分类。常用于:在特征相差比较复杂或是相差不是特别大的时候效果比较好。该函数将大的负数转换成0,将大的正数转换为1。公式描述如下:

实现代码:
import numpy as np
import matplotlib.pyplot as plt
# 定义sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 生成一系列点
x = np.linspace(-10, 10, 100)
y = sigmoid(x)
# 绘制图像
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("Sigmoid(x)")
plt.title("Sigmoid Function")
plt.grid(True)
plt.show()
如图所示:

Tanh激活函数
Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。
公式如下:

实现代码:
import matplotlib.pyplot as plt
import math
def tanh(x):
return (math.exp(x) - math.exp(-x)) / (math.exp(x) + math.exp(-x))
# 生成一系列点
x_values = [x * 0.1 for x in range(-100, 101)]
y_values = [tanh(x) for x in x_values]
# 绘制图像
plt.plot(x_values, y_values)
plt.xlabel("x")
plt.ylabel("tanh(x)")
plt.title("Tanh Activation Function")
plt.grid(True)
plt.show()
如图所示:

与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。
优点:它解决了Sigmoid函数的不是zero-centered输出问题。
缺点:梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
ReLU激活函数
Relu激活函数的解析式:
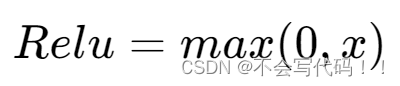
实现代码:
import numpy as np
import matplotlib.pyplot as plt
# 定义ReLU函数
def relu(x):
return np.maximum(0, x)
# 生成一系列点
x = np.linspace(-10, 10, 100)
y = relu(x)
# 绘制图像
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("ReLU(x)")
plt.title("ReLU Activation Function")
plt.grid(True)
plt.show()
如图所示:

当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。该激活函数使网络更快速地收敛。它不会饱和,即它可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。
Relu激活函数缺点:
- 不以零为中心:和 Sigmoid 激活函数类似,ReLU 函数的输出不以零为中心。
- 前向传导(forward pass)过程中,如果 x < 0,则神经元保持非激活状态,且在后向传导(backward pass)中「杀死」梯度。这样权重无法得到更新,网络无法学习。当 x = 0 时,该点的梯度未定义,但是这个问题在实现中得到了解决,通过采用左侧或右侧的梯度的方式。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
Leaky Relu激活函数
Leaky Relu激活函数的解析式:

实现代码:
import numpy as np
import matplotlib.pyplot as plt
# 定义Leaky ReLU函数
def leaky_relu(x, alpha=0.01):
return np.where(x >= 0, x, alpha * x)
# 生成一系列点
x = np.linspace(-10, 10, 100)
y = leaky_relu(x)
# 绘制图像
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("Leaky ReLU(x)")
plt.title("Leaky ReLU Activation Function")
plt.grid(True)
plt.show()
如图所示:

Leaky ReLU 的概念是:当 x < 0 时,它得到 0.01 的正梯度。
优点:
该函数一定程度上缓解了 dead ReLU 问题。
缺点:
使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。该扩展就是 Parametric ReLU。
Swish激活函数
Swish激活函数是一个较新的激活函数,公式如下:

实现代码:
import numpy as np
import matplotlib.pyplot as plt
# 定义Swish函数
def swish(x, beta=1):
return x * (1 / (1 + np.exp(-beta * x)))
# 生成一系列点
x = np.linspace(-10, 10, 100)
y = swish(x)
# 绘制图像
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("Swish(x)")
plt.title("Swish Activation Function")
plt.grid(True)
plt.show()
如图所示:

根据上图,从图像上来看,Swish函数跟ReLu差不多,唯一区别较大的是接近于0的负半轴区域,因此,Swish 激活函数的输出可能下降,即使在输入值增大的情况下。大多数激活函数是单调的,即输入值增大的情况下,输出值不可能下降。而 Swish 函数为 0 时具备单侧有界(one-sided boundedness)的特性,它是平滑、非单调的。
缺点: - 只有实验证明,没有理论支持。 - 在浅层网络上,性能与relu差别不大。