☘️博主介绍☘️:
✨又是一天没白过,我是奈斯,DBA一名✨
✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️
❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣️❣️❣️

哈喽各位小伙伴,时光荏苒,岁月如梭,转眼间我们又将迎来新的一年。在此,我祝愿大家新年快乐!在岁末之际,我想与大家分享一项关于Oracle数据库的实用技术——LogMiner日志挖掘技术,作为年前的最后一篇文章。
Oracle LogMiner是Oracle公司从产品8i以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得Oracle在线/归档日志文件中的具体内容,特别是该工具可以分析出所有对于数据库操作的DML和DDL语句。该工具特别适用于调试、审计或者回退某个特定的事务。
在Oracle 8i之前,Oracle没有提供任何协助数据库管理员来读取和解释重作日志文件内容的工具。系统出现问题,对于一个普通的数据管理员来讲,唯一可以作的工作就是将所有的lo文件打包,然后发给Oracle公司的技术支持,然后静静地等待Oracle公司技术支持给我们最后的答案。然而从8i以后,Oracle提供了这样一个强有力的工具LogMiner。
LogMiner工具即可以用来分析在线重做日志文件,也可以用来分析离线重做日志文件(归档),即可以分析本身自己数据库的重作日志文件,也可以用来分析其他数据库的重作日志文件。重做日志文件中存放着所有进行数据库恢复的数据,记录了数据的所有变化,包括DML、DDL、或对数据所作的结构性操作更改等。那个数据块block、那个数据行row做了什么dml、value操作。
LogMiner分析工具实际上是由一组PL/SQL包和一些动态视图(Oracle8i内置包的一部分)组成,它作为Oracle数据库的一部分来发布是8i产品提供的一个完全免费的工具。
在12c版本中之后提供了图形用户界面Oracle LogMiner Viewer来管理,Oracle LogMiner Viewer是Oracle Enterprise Manager的一部分。
愿你在新的一年里,像数据库里的查询一样,总能快速找到想要的答案,而不是总是“查询超时”!
目录
官方文档对logminer的介绍:
LogMiner的配置要求:
logminer用途:
LogMiner不支持挖掘的数据类型和表存储属性(除以下类型外,基本上都是支持的):
安装logminer:11g需要安装,12c之后默认安装了logminer
相关视图:
补充日志的作用(Supplemental Logging):
案例:cdb环境logminer日志挖掘恢复误删除和误更新的操作

官方文档对logminer的介绍:
Using LogMiner to Analyze Redo Log Files

LogMiner的配置要求:
源和挖掘数据库:
1)源数据库和挖掘数据库必须运行在同一硬件平台上。
2)挖掘数据库可以与源数据库相同,也可以完全独立于源数据库。
3)挖掘数据库必须运行与源数据库相同版本或更高版本的Oracle数据库软件。
4)挖掘数据库必须使用与源数据库相同的字符集(或字符集的超集)。
LogMiner词典:
1)该字典必须由生成LogMiner将分析的重做日志文件的同一源数据库生成。
所有重做日志文件:
1)必须由相同的源数据库生成。
2)必须与同一数据库相关联RESETLOGS SCN.
3)Oracle数据库必须是8.0或更高版本。然而,在9.0.1版本中引入的一些LogMiner特性只适用于在Oracle9i或更高版本数据库上生成的重做日志文件。请参阅“支持的数据库和重做日志文件版本”。
注意:在生成将由LogMiner分析的日志文件之前,必须启用补充日志记录。默认情况下,Oracle数据库不提供任何补充日志记录,这意味着默认情况下LogMiner不可用。因此在生成将由LogMiner分析的日志文件之前,必须至少启用最低限度的补充日志记录。也就是说如果误操作数据之前没有启用补充日志那么就不能使用logminer工具恢复误操作的数据。
logminer用途:
1)跟踪数据库的变化:可以离线的跟踪数据库的变化,而不会影响在线系统的性能。
2)回退数据库的变化:回退特定的变化数据,减少point-in-time recovery的执行。
3)优化和扩容计划:可通过分析日志文件中的数据以分析数据增长模式。
LogMiner不支持挖掘的数据类型和表存储属性(除以下类型外,基本上都是支持的):
1)BFILE
2)嵌套表格
3)带有嵌套表格的对象
4)带有标识列的表
5)时间有效性列
6)PKREF列
7)PKOID列
8)嵌套表属性和独立嵌套表列
安装logminer:11g需要安装,12c之后默认安装了logminer
在使用LogMiner之前需要确认Oracle是否带有进行LogMiner分析包,一般来说Windows操作系统10g以上都默认包含。如果不能确认,可以DBA身份登录系统,查看系统中是否存在运行LogMiner 所需要的dbms_logmnr、dbms_logmnr_d包,如果没有需要安装LogMiner工具,必须首先要运行下面三个脚本(LogMiner分析工具实际上是由一组PL/SQL包和一些动态视图组成,11g需要安装,12c之后默认安装了logminer)
@$ORACLE_HOME/rdbms/admin/dbmslm.sql ---创建DBMS_LOGMNR包,用于分析重做日志文件。
@$ORACLE_HOME/rdbms/admin/dbmslmd.sql ---创建DBMS_LOGMNR_D包,用于创建数据字典文件。
执行完成sql脚本将生成以下过程和视图:
类型
过程名
用途
过程
dbms_logmnr_d.build
创建一个数据字典文件。
过程
dbms_logmnr.add_logfile
在类表中增加日志文件以供分析。
过程
dbms_logmnr.start_logmnr
使用一个可选的字典文件和前面确定要分析日志
文件来启动LogMiner。
过程
dbms_logmnr.end_logmnr
停止LogMiner分析。
视图
v$logmnr_dictionary
显示有关LogMiner字典文件的信息,该文件是使用STORE_IN_FLAT_FILE选项创建到DBMS_LOGMNR.START_LOGMNR的。显示的信息包括关于创建LogMiner字典的数据库的信息。
视图
v$logmnr_parameters
显示有关可选LogMiner参数的信息,包括开始和结束系统更改编号(scn),以及开始和结束logminer的时间。
视图
v$logmnr_logs
在LogMiner启动时显示分析的日志列表。
视图
v$logmnr_contents
LogMiner启动后,可以使用该视图在SQL提示符下输入SQL语句来查询重做日志的内容。
相关视图:
1)v$logmnr_dictionary:显示有关LogMiner字典文件的信息,该文件是使用STORE_IN_FLAT_FILE选项创建到DBMS_LOGMNR.START_LOGMNR的。显示的信息包括关于创建LogMiner字典的数据库的信息。
2)v$logmnr_parameters:显示有关可选LogMiner参数的信息,包括开始和结束系统更改编号(scn),以及开始和结束logminer的时间。只有启动分析dbms_logmnr.add_logfile添加日志的时间范围和scn范围时才能看到相关开始的时间scn。相关结束的时间scn记录到这个表中,启动分析dbms_logmnr.add_logfile添加的所有日志是不会记录到这个表。
START_DATE:开始搜索的日期
REQUIRED_START_DATE:如果启用了DDL跟踪,则需要开始搜索的日期
END_DATE:结束搜索的日期
START_SCN:开始搜索的系统更改号
REQUIRED_START_SCN:如果启用了DDL跟踪,则开始搜索所需的系统更改号
END_SCN:系统更改编号以结束搜索
3)v$logmnr_logs:在LogMiner启动时显示分析的日志列表。
FILENAME:重做日志文件的名称
LOW_TIME:重做日志文件中任何记录的最早日期
HIGH_TIME:重做日志文件中任何记录的最近日期
LOW_SCN:重做日志切换到时分配的SCN
NEXT_SCN:重做日志后的SCN。下一个日志的低SCN。
4)v$logmnr_contents:LogMiner启动后,可以使用该视图在SQL提示符下输入SQL语句来查询重做日志的内容。
SCN:特定数据变化的系统更改号
TIMESTAM:数据改变发生的时间
COMMIT_TIMESTAMP:数据改变提交的时间
SEG_OWNER:数据发生改变的段名称
SEG_NAME:段的所有者名称
SEG_TYPE:数据发生改变的段类型
SEG_TYPE_NAME:数据发生改变的段类型名称
TABLE_SPACE:变化段的表空间
ROW_ID:特定数据变化行的 ID
SESSION_INFO:数据发生变化时用户进程信息
OPERATION :重做记录中记录的操作(如 INSERT)
SQL_REDO:可以为重做记录重做指定行变化的SQL语句(正向操作)。既实际执行的sql。
SQL_UNDO:可以为重做记录回退或恢复指定行变化的 SQL语句(反向操作)。sql反转,如果是insert,就对应delete;如果是delete,对应insert;如果是update,就将set和where调换。
注意:视图v$logmnr_contents里分析的结果仅在运行dbms_logmrn.start_logmnr过程中的这个会话的生命期中存在。这是因为所有的LogMiner存储都在PGA内存中,所有其他的进程是看不到它的,同时随着进程的结束,分析结果也随之消失。最后使用DBMS_LOGMNR.END_LOGMNR过程终止日志分析事务,此时PGA内存区域被清除,分析结果也随之不再存在。
补充日志的作用(Supplemental Logging):
重做日志文件通常用于实例恢复和介质恢复。这些操作所需的数据会自动记录在重做日志文件中。但是基于重做的应用程序可能需要在重做日志文件中记录额外的列。记录这些附加列的过程称为补充日志记录。
默认情况下,Oracle数据库不提供任何补充日志记录,这意味着默认情况下LogMiner不可用。因此在生成将由LogMiner分析的日志文件之前,必须至少启用最低限度的补充日志记录。也就是说如果误操作数据之前没有启用补充日志那么就不能使用logminer工具恢复误操作的数据。
正常情况下,redo log只记录的进行恢复所必需的信息,但是这些信息对于我们使用redo log进行一些其他应用时是不够的。例如在redo log中使用rowid唯一标识一行而不是通过 Primary key,如果我们在另外的数据库分析这些日志并想重新执行某些dml时就可能会有问题,因为不同的数据库其rowid代表的内容是不同的。在这时候就需要一些额外的信息(columns)加入redo log,这就是supplemental logging。
supplemental logging分为两个级别database_level and table_level,默认不开启,建议开启数据库级别。默认情况下,Oracle数据库没有提供任何补充日志,从而导致默认情况下logMiner无法支持以下特征:
1)索引簇、链行和迁移行;
2)直接路径插入;
3)摘取LogMiner字典到重做日志;
4)跟踪DDL;
5)生成键列的SQL_REDO和SQL_UNDO信息;
6)LONG和LOB数据类型。
因此为了充分利用LogMiner提供的特征,必须激活补充日志。激活不用重启数据库,数据库联机即可。打开补充日志(打开最小附加日志模式,日志的记录按照最小颗粒记录)
SQL> alter database add supplemental log data; ---打开附加日志模式。删除 supplemental log的语句alter database drop supplemental log data;
SQL> select SUPPLEMENTAL_LOG_DATA_MIN from v$database;

案例:cdb环境logminer日志挖掘恢复误删除和误更新的操作
一、安装logminer和打开补充日志
(1)安装logminer(LogMiner分析工具实际上是由一组PL/SQL包和一些动态视图组成,11g需要安装,12c之后默认安装了logminer)
SQL> @$ORACLE_HOME/rdbms/admin/dbmslm.sql ---创建DBMS_LOGMNR包,用于分析重做日志文件。 SQL> @$ORACLE_HOME/rdbms/admin/dbmslmd.sql ---创建DBMS_LOGMNR_D包,用于创建数据字典文件。(2)打开补充日志(打开最小附加日志模式,日志的记录按照最小颗粒记录。使用logminer必须启用补充日志,如果误操作数据之前没有启用补充日志那么就不能使用logminer工具恢复误操作的数据)
SQL> select SUPPLEMENTAL_LOG_DATA_MIN from v$database; SQL> alter database add supplemental log data; ---打开附加日志模式。删除 supplemental log的语句alter database drop supplemental log data; SQL> select SUPPLEMENTAL_LOG_DATA_MIN from v$database;
二、连接到pdb实例模拟误删除和误更新
(1)连接到pdb实例orcl_pdb1,插入测试数据
[oracle@12c ~]$ sqlplus test/123456@orcl_pdb1 SQL> show con_name; SQL> create table table1 ( id number(10) not null, name varchar(16) not null, sex varchar(16) not null, age number(10) not null ); insert into table1(id,name,sex,age) values (1,'name1','w',21); insert into table1(id,name,sex,age) values (2,'name2','m',22); insert into table1(id,name,sex,age) values (3,'name3','w',23); insert into table1(id,name,sex,age) values (4,'name4','m',24); insert into table1(id,name,sex,age) values (5,'name5','w',25); commit;(2)误删表数据和更新数据
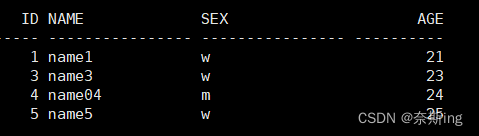
SQL> delete from table1 where id=2; SQL> commit; SQL> update table1 set name='name04' where id=4; SQL> commit; SQL> select * from table1;
三、通过logminer工具将归档进行分析
(1)需要在cdb的sys用户下执行日志切换(pdb切换日志没有权限:ORA-65040: operation not allowed from within a pluggable database)
SQL> archive log list; SQL> alter system switch logfile; ---将日志进行归档,因为delete的操作在当前日志里,所以需要进行日志切换归档。下面会用到logminer工具对这个归档进行分析 SQL> select name from v$archived_log;
(2)建立日志分析列表(logminer分析的日志会输出到v$logmnr_contents视图里)
SQL> begin dbms_logmnr.add_logfile(logfilename=>'/oracle/app/oracle/arch/1_280_1135074264.dbf',options=>dbms_logmnr.new); end; / SQL> begin dbms_logmnr.add_logfile(logfilename=>'/oracle/app/oracle/arch/1_281_1135074264.dbf',options=>dbms_logmnr.addfile); end; / SQL> begin dbms_logmnr.add_logfile(logfilename=>'/oracle/app/oracle/arch/1_282_1135074264.dbf',options=>dbms_logmnr.addfile); end; / SQL> begin dbms_logmnr.add_logfile(logfilename=>'/oracle/app/oracle/arch/1_283_1135074264.dbf',options=>dbms_logmnr.addfile); end; / ....... LogMiner可以分析在线和归档两种日志文件,加入分析日志文件使用dbms_logmnr.add_logfile过程,第一个文件使用dbms_logmnr.new参数,后面文件使用dbms_logmnr.addfile参数
(3)启动分析
启动分析dbms_logmnr.add_logfile添加的所有日志: SQL> begin dbms_logmnr.start_logmnr(Options => dbms_logmnr.dict_from_online_catalog); end; /
(4)查看日志分析结果(logminer分析的日志会输出到v$logmnr_contents视图里)
SQL> select FILENAME from v$logmnr_logs; ---在LogMiner启动时显示分析的日志列表。 SQL> select username,scn,timestamp,sql_redo,sql_undo from v$logmnr_contents WHERE table_name='TABLE1';总共输出8行,一行创建表的语句(create table);5行插入数据(insert);1行删除数据(delete);1行更新数据(update)
SQL_REDO:可以为重做记录重做指定行变化的SQL语句(正向操作)。既实际执行的sql。
SQL_UNDO:可以为重做记录回退或恢复指定行变化的 SQL语句(反向操作)。sql反转,如果是insert,就对应delete;如果是delete,对应insert;如果是update,就将set和where调换。
(5)结束分析
结束分析后v$logmnr_contents输出的内容消失,如果在看v$logmnr_contents视图就会报错:ORA-01306: 在从 v$logmnr_contents 中选择之前必须调用 dbms_logmnr.start_logmnr()
视图v$logmnr_contents里分析的结果仅在运行dbms_logmrn.start_logmnr过程中的这个会话的生命期中存在。这是因为所有的LogMiner存储都在PGA内存中,所有其他的进程是看不到它的,同时随着进程的结束,分析结果也随之消失。最后使用DBMS_LOGMNR.END_LOGMNR过程终止日志分析事务,此时PGA内存区域被清除,分析结果也随之不再存在。
SQL> begin dbms_logmnr.end_logmnr; end; /




四、连接到pdb实例恢复数据
(1)连接到pdb实例orcl_pdb1
[oracle@12c ~]$ sqlplus test/123456@orcl_pdb1 SQL> show con_name; SQL> select * from table1;
(2)将误删除和误更新数据写到文本里执行
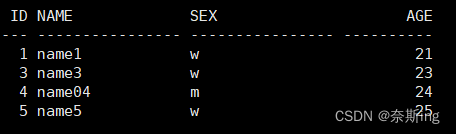
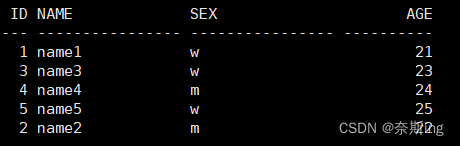
SQL> insert into "TEST"."TABLE1"("ID","NAME","SEX","AGE") values ('2','name2','m','22'); SQL> update "TEST"."TABLE1" set "NAME" = 'name4' where "NAME" = 'name04' and ROWID = 'AAARnWAAEAAABe3AAD'; SQL> commit; SQL> select * from table1;
好啦!今天的内容全部结束了,希望各位在这新的一年,愿你的代码永远没有bug,如果有,那也只是特性,不是bug!