前端文件下载的多种方式。
- 前言
- a标签下载
- a标签常用属性介绍- target,href,download。
- window.location.href下载
- window.open下载
- iframe 下载
- 动态生成a标签下载
- 文件url下载
- 文件流下载
- blob文件流转换常用类型
- 使用 streamSaver 看实时下载进度
前言
如果我们要下载一些浏览器读不懂的文件,我们可以使用 < a >标签在新窗口打开链接,也可以使用 windows.open(‘url’) 的方式打开新窗口进行下载。
但如果这个文件浏览器是读得懂的,比如 .txt 文件,那浏览器就不会执行下载,而是会直接在页面中把文件内容展示出来。
根据这个特性,我们可以根据需求自由选择如下方案进行下载
a标签下载
<a href="链接" download="链接名称"> //点击下载
a标签常用属性介绍- target,href,download。
- target属性
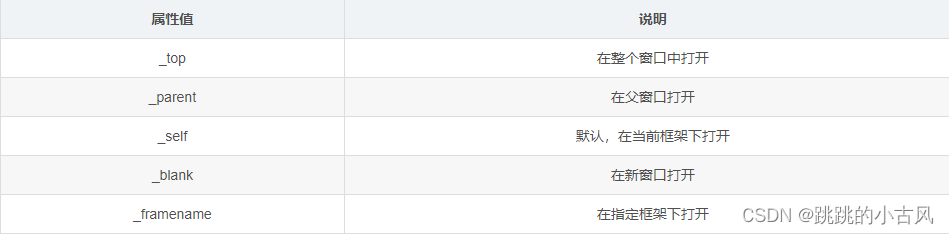
- href属性
如果 < a > 标签没有 href 属性,它只是一个超链接的占位符。
<a href="http://baidu.com">在当前窗口打开百度链接</a>
<a href="http://baidu.com" target="_blank">在新窗口打开百度链接</a>
<a href="#">网页返回顶部</a>
<a href="#miss">锚点跳转——本页面跳转</a>
- download 属性
download 规定当用户单击超链接时将下载目标(href 属性中规定的文件)。
download 的值为文件下载后的新名称。允许使用任何值,浏览器会自动检测正确的文件扩展名并将其添加到文件中(例如 .img、.pdf、.txt、.html 等)
网络图片download无效,点击为预览
<a href="图片链接" download="图片名称"> //点击下载图片
<a href="pdf链接" download="1.pdf" target="_blank">pdf下载</a> //下载pdf,浏览器不自动打开 记得让后台给.pdf加个content-type头:application/octet-strea
window.location.href下载
// 通用下载方法
export function download(url) {
window.location.href = url
}
直接访问可能会覆盖当前页面地址,影响用户体验。
只有.pdf和图片可以实现跳转另一个新窗口进行预览,其他格式是下载
window.open下载
export function download(url) {
window.open(url);
},
这个方法只能将指定路径的资源加载到浏览器里面,如果文件不能被浏览器浏览,那就会被浏览器下载到本地。反之,如果下载一个txt文本,用该方法会直接预览txt文件
iframe 下载
export function download(url) {
window.open("about:blank");
const iframe = document.createElement("iframe");
iframe.src = url;
iframe.style.width = "100%";
iframe.style.height = "100vh";
iframe.style.margin = "0";
iframe.style.padding = "0";
iframe.style.overflow = "hidden";
iframe.style.border = "none";
win.document.body.style.margin = "0";
win.document.body.appendChild(iframe);
}
动态生成a标签下载
文件url下载
export function download(url) {
const link = document.createElement('a');
link.style.display = 'none';
link.download ="文件名";
link.href = url;
link.click();
document.body.removeChild(link);
}
文件流下载
// 用fetch发送请求 对请求回来的二进制文件流进行处理 如果返回的就是文件流 则直接进行fetch后的步骤则可
export function download(url) {
fetch(url)
.then((response) => response.blob()) // 获取文件数据流
.then((blob) => {
const url = window.URL.createObjectURL(new Blob([blob], {
type: "根据文件类型写不同的type",
})); // 生成文件在浏览器中的链接
const a = document.createElement("a");
a.href = url;
a.download = "文件名"; // 文件名 如果是视频格式 需要加上后缀名 “.flv /.mp4”
a.style.display = "none";
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
window.URL.revokeObjectURL(url); // 清除文件链接
})
.catch(console.error);
}
如果遇到下载 txt、jpg 等文件时出现直接打开文件而不是下载文件的情况时,可以在下载地址即 url 后拼接 ‘?response-content-type=application/octet-stream’ 即可
blob文件流转换常用类型
| 后缀 | MIME Type |
|---|---|
| .doc | application/msword |
| .docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| .xls | application/vnd.ms-excel |
| .xlsx | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
| .ppt | application/vnd.ms-powerpoint |
| .pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation |
| .flv | flv-application/octet-stream |
| application/pdf | |
| .png | image/png |
| .gif | image/gif |
| .jpeg .jpg | image/jpeg |
| .mp3 | audio/mpeg |
| .mp4 | video/mpeg4 |
| .html | text/html |
| .css | text/css |
| .js | text/javascript |
| .json | application/json |
| .zip | application/zip |
使用 streamSaver 看实时下载进度
StreamSaver源码地址
npm i streamsaver
import streamSaver from "streamsaver"
使用 StreamSaver.js 下载文件的大概流程是这样的(为了方便理解,我用一些不专业的术语进行描述)
- 创建一个文件,该文件支持写入操作。streamSaver.createWriteStream(‘文件名.后缀’)。
- 使用 fetch 方法访问文件的url,将内容一点点的放到 StreamSaver 创建的文件里。
- 监听文件内容是否读取完整,读取完就执行“保存并关闭文件”的操作。
fetch(url).then((res) => {
const fileStream = streamSaver.createWriteStream(
"历史视频.flv",//文件名
{
size: res.headers.get("content-length"),
}
);
const readableStream = res.body;
if (window.WritableStream && readableStream.pipeTo) {
return readableStream.pipeTo(fileStream).then(() => {});
}
window.writer = fileStream.getWriter();
const reader = res.body.getReader();
const pump = () =>
reader
.read()
.then((res) =>
res.done ? window.writer.close() : window.writer.write(res.value).then(pump)
);
pump();
});




![java---查找算法(二分查找,插值查找,斐波那契[黄金分割查找] )-----详解 (ᕑᗢᓫ∗)˒](https://img-blog.csdnimg.cn/direct/1e03076b431342ce958728c48bab2257.webp)
