Python深入理解collections模块:常见数据结构及应用场景分析
- 介绍
- collections模块的常见数据结构
- 代码演示
- defaultdict
- Counter
- OrderedDict
介绍
在Python编程中,经常需要使用一些内置的数据结构,如列表、字典等。然而,在某些特定的场景下,这些内置数据结构可能无法满足需求。这时,可以考虑使用collections模块提供的特殊数据结构。本文将深入探讨collections模块中的常见数据结构,如defaultdict、Counter、OrderedDict等,以及它们的应用场景和性能特点。
collections模块的常见数据结构
| 模块 | 类 | 应用场景 | 性能特点 |
|---|---|---|---|
| collections | defaultdict | 当需要为字典中的键指定一个默认值,或者在遍历字典时需要处理键不存在的情况时,可以使用defaultdict。 | 相比于内置的字典,defaultdict在创建键时会多一层判断,因此性能略逊一筹。但是,它提供了便利性,可以减少代码的复杂性。 |
| collections | Counter | 当需要统计一个列表、字符串等可迭代对象中每个元素的出现次数时,可以使用Counter。 | Counter在统计元素出现次数时,性能与内置的dict相当。但是,Counter提供了额外的方法,如most_common(),可以方便地获取出现次数最多的元素。 |
| collections | OrderedDict | 当需要按照元素插入的顺序访问字典中的键值对时,可以使用OrderedDict。 | OrderedDict在维护元素顺序方面会消耗一定的性能,因此相比于普通字典,它的性能稍逊一筹。但是,它提供了有序的字典功能,可以提高代码的可读性。 |
代码演示
defaultdict
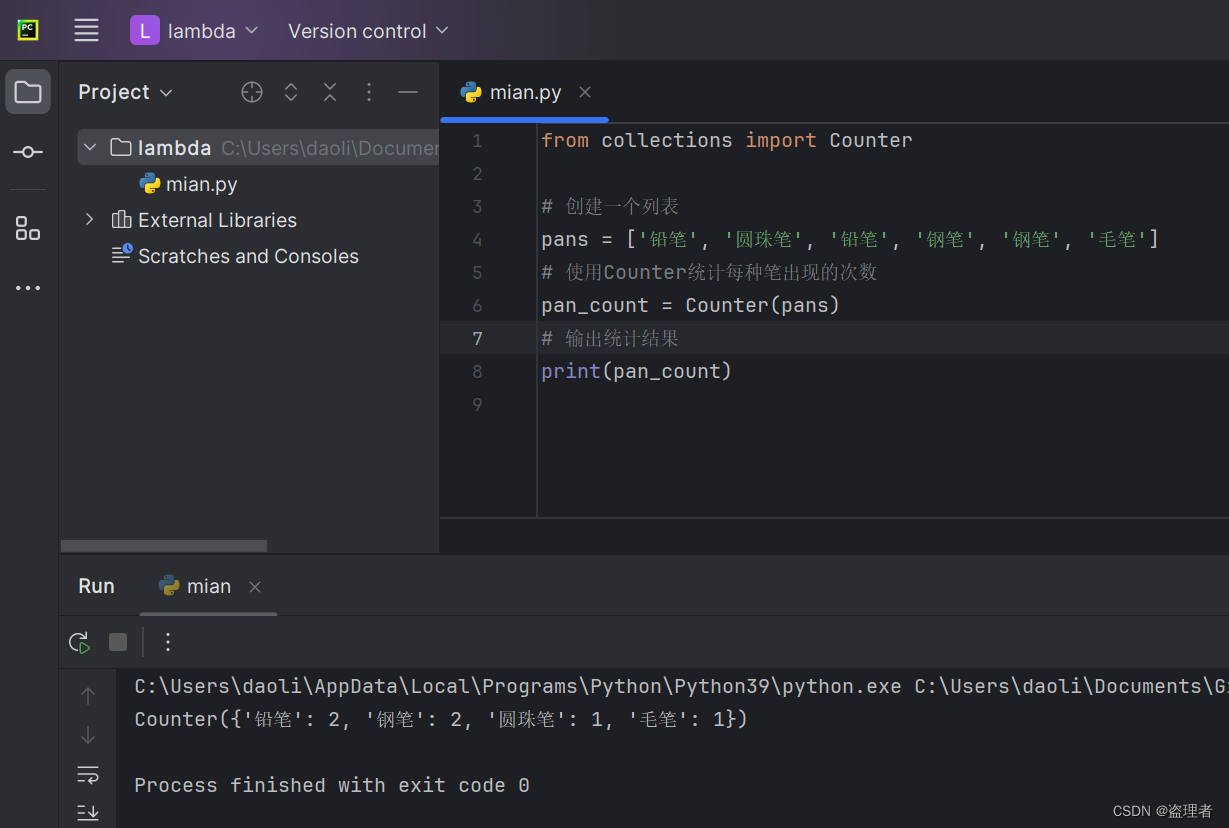
from collections import defaultdict
# 创建一个数字列表
numbers = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
# 使用 defaultdict 来创建一个计数器
counts = defaultdict(int)
# 计数每个数字出现的次数
for number in numbers:
counts[number] += 1
# 打印计数结果
for number, count in counts.items():
print(f'数字 {number} 出现了 {count} 次。')
运行上述代码,输出结果为:
数字 1 出现了 1 次。
数字 2 出现了 2 次。
数字 3 出现了 3 次。
数字 4 出现了 4 次。
Counter
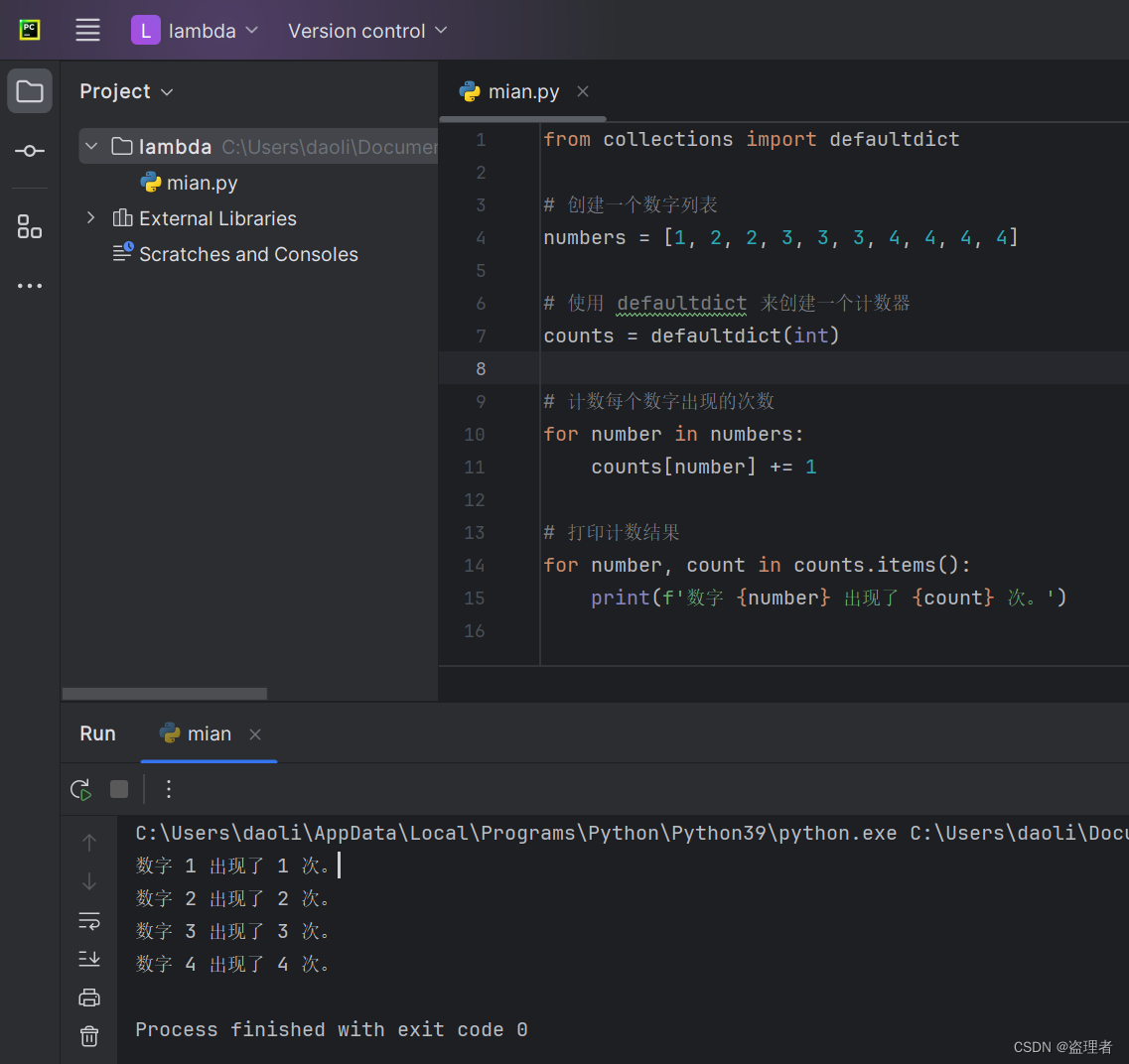
以下是一个使用Counter进行统计分析的简单代码:
from collections import Counter
# 创建一个列表
pans = ['铅笔', '圆珠笔', '铅笔', '钢笔', '钢笔', '毛笔']
# 使用Counter统计每种笔出现的次数
pan_count = Counter(pans)
# 输出统计结果
print(pan_count)
运行上述代码,输出结果为:
Counter({'铅笔': 2, '钢笔': 2, '圆珠笔': 1, '毛笔': 1})
OrderedDict
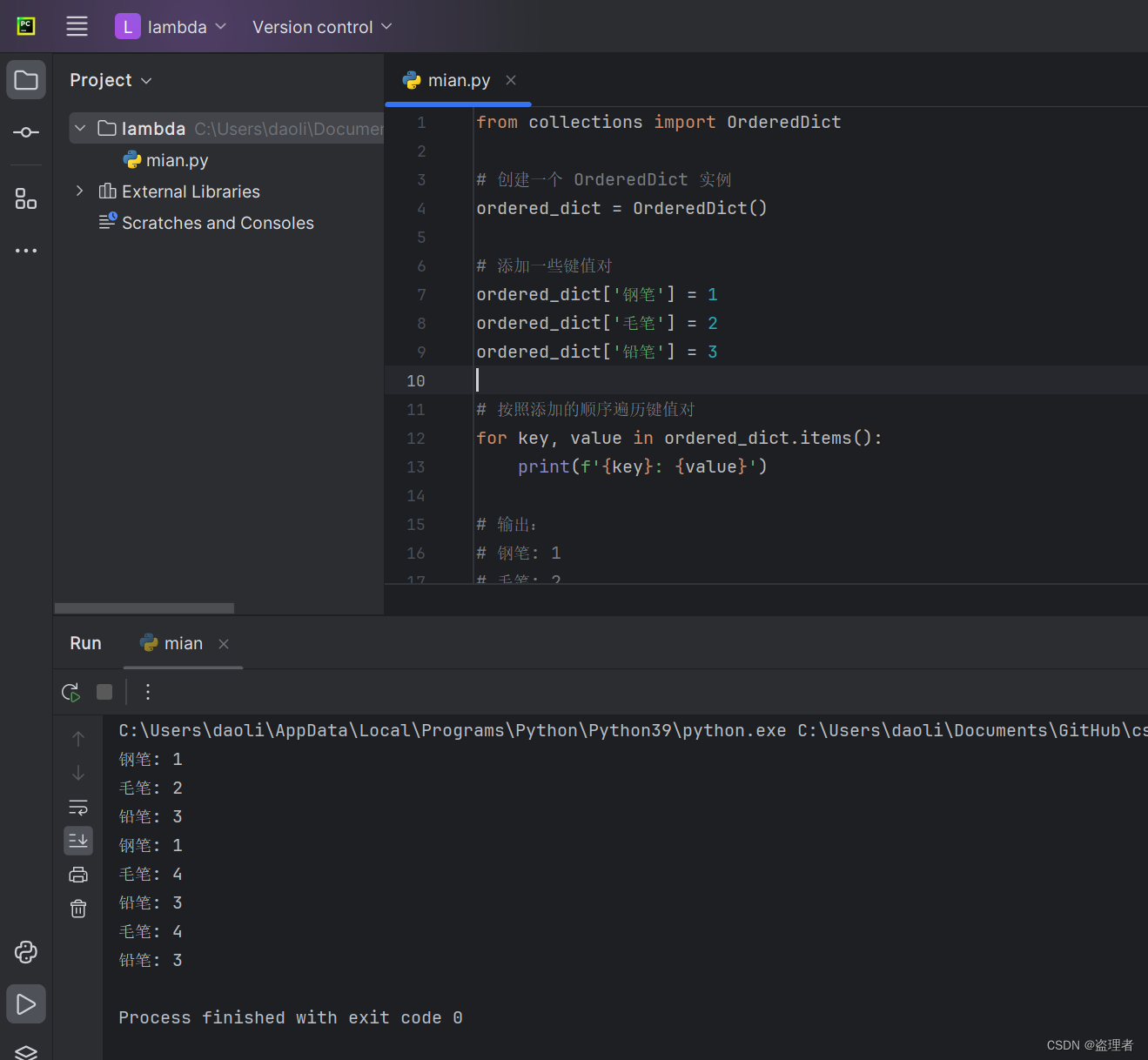
from collections import OrderedDict
# 创建一个 OrderedDict 实例
ordered_dict = OrderedDict()
# 添加一些键值对
ordered_dict['钢笔'] = 1
ordered_dict['毛笔'] = 2
ordered_dict['铅笔'] = 3
# 按照添加的顺序遍历键值对
for key, value in ordered_dict.items():
print(f'{key}: {value}')
# 输出:
# 钢笔: 1
# 毛笔: 2
# 铅笔: 3
# 更新一个键值对
ordered_dict['毛笔'] = 4
# 再次遍历,可以看到更新后的键值对
for key, value in ordered_dict.items():
print(f'{key}: {value}')
# 输出:
# 钢笔: 1
# 毛笔: 4
# 铅笔: 3
# 删除一个键值对
del ordered_dict['钢笔']
# 再次遍历
for key, value in ordered_dict.items():
print(f'{key}: {value}')
# 输出:
# 毛笔: 4
# 铅笔: 3
运行的结果
钢笔: 1
毛笔: 2
铅笔: 3
钢笔: 1
毛笔: 4
铅笔: 3
毛笔: 4
铅笔: 3




![java---查找算法(二分查找,插值查找,斐波那契[黄金分割查找] )-----详解 (ᕑᗢᓫ∗)˒](https://img-blog.csdnimg.cn/direct/1e03076b431342ce958728c48bab2257.webp)