6.4 指针修改机制
LS0和LS1都包含指针修改机制。当使用间接或索引寻址模式时,指针的修改可以与地址生成并行执行。在间接寻址模式中,指针包含地址,而在变址寻址模式下,指针包含偏移量(有关这些寻址模式的更多详细信息,请参阅第6.3.1节“间接寻址模式”和第6.3.2节“索引寻址模式”)。因为指针是在地址生成后修改的,所以这种修改被称为后期修改。
以下选项可用于指针后期修改:
- 后期增量:指针按指令中指定的访问宽度递增。访问宽度根据存储器访问操作确定,可以是一个、两个或四个。
- 步骤修改:将其中一个步骤寄存器添加到指针。可以用作步进寄存器的GRF寄存器子集列在pm(修改后)伪操作数的汇编语法部分,如CEVA-BX2体系结构规范第II卷所述。
步骤寄存器包含一个有符号的值,该值表示字节数。与前一选项相比,步骤修改不会根据访问宽度进行缩放。
该选项在指令中通过使用加号(+)来指定,该加号的步骤寄存器名称跟在地址规范后面。
- 偏移量修改:将宽度高达32位的有符号立即数添加到指针。立即数包含许多字节。与步长修改类似,偏移修改不根据访问宽度缩放。
该选项在指令中使用符号+#imm指定,其中#imm
表示有符号的立即数。
实施例6-7.间接寻址模式下的后增量
|
mov #0x100,r5.ui ; r5 is initialized with the value 0x100 nop nop ld (r5.ui).us+r20, r2.ui ld指令应用间接寻址模式,并使用指针r5。访问宽度为两个字节,在r2中进行零扩展。 使用后增量选项,它由符号+r20指定。生成的内存地址为0x100,ld指令后的指针值更新为r20的值。 |
实施例6-8. 步骤修改
|
mov #0x10004,r20.i ; Step register initialization. mov #0x200,r3.ui ; Offset initialization. nop nop ld (r0.ui+r3.i).ui+r20, r2.ui 使用步进寄存器r20对偏移量r3进行后修改。ld后r3的值指令为0x10204。 r20不根据访问宽度缩放,并且r0的内容不改变。 |
实施例6-9. 偏移量修改
|
mov #0x100,r5.ui ; r5 is initialized with the value 0x100. nop nop ld (r5.ui).us2+#10,r0.ui,r1.ui 指针r5按立即数#10递增。ld后r5的值指令为0x10A。 |
6.4.1 修改(modr)说明书
modr指令在不访问数据存储器的情况下修改指针。它指定要添加到其中的指针和值,可以由LS0和LS1执行。
该值可以是四个步骤寄存器之一,也可以是有符号立即数。立即数的宽度高达32位。
例6-10. modr指令
|
mov #0x50,r4.ui nop nop modr (r4.ui).ui+#256 指针r4使用立即数进行后期修改。后面的r4的值, 修改(modr)指令为0x150。 |
6.4.2 模缓冲区支持
由于地址指针在访问后进行后修改,ld和st指令的子集将地址指针限制在循环模缓冲区中。这些指令使用额外的操作数来指定模缓冲区的大小。此操作数在地址操作数之前指定,并以字节为单位保存缓冲区的大小,其中最大缓冲区大小为64K-1个字节。此操作数从GRF的子集(r22、r23、r28、r29)中选择,并应使用首选缓冲区大小M的值进行初始化。
模数运算意味着间接rN+pm_value上的后修改值保持在数据缓冲区限制内(其中pm_value.表示缩放或阶跃寄存器后修改)。当修改后的值(即rN+pm_value)超出缓冲区的边界时,可能出现以下情况:
- 如果pm_value>0,则新值为rN+pm_value–M。
- 如果pm_value<0,则新值为rN+pm_value+M。使用模数模式时,必须遵守以下规则:
- M必须大于或等于步长的绝对值(pm_value)。
- 指针应指向缓冲区内的地址。
- 访问指针加上访问宽度不应超过缓冲区边界。
例如,如果缓冲区结束于地址0x30C,并且指针值为0x30A,则不允许发出4字节访问。
缓冲区的起始地址必须在其k个LSB中包含零,其中k是满足2k大于或等于M的最小正整数。上界是起始地址+M-1。这意味着数据空间自动划分为多个循环缓冲区,以便每个缓冲区的下边界满足前面的条件。起始地址必须仅指向模缓冲区内的位置。
注:使用步进寄存器指定pm_value时,仅使用其低16位。后修改的符号根据步进寄存器的位号16确定。
例6-11. 模数-多个环绕缓冲区
|
mov #0x6,r0.ui ; Loop counter initialization mov #0x0c,r22.ui ; Initialize the modulo register with a buffer size of 12 bytes mov #0x4,r20.i ; Initialize step register with a step of 4 that is ≤ 12 mov #0x308,r4.ui ; Initialize read pointer mov #0x500,r6.ui ; Initialize write pointer nop LP_START: brrcmplp {ge, calc3, ds2} r0.i,#-1,#1,#LP_START ld r22.ui,(r4.ui).i+r20.i,r2.i st r2.i,(r6.ui)+#4 在此示例中,读取指针用值0x308初始化,并位于起始地址为0x300的缓冲区中(四个LSB为零)。结束地址为0x30B(缓冲区大小为12)。 由于缓冲区大小为12,因此每次读取指针被0x4(r20)后修改时,如果生成的指针大于0x30B,则读取指针将被环绕到缓冲区的起始地址。 六次迭代期间r4的值为0x308、0x300、0x304、0x308、0x300和0x304。 |
6.4.3 加载和存储指令谓词
LSU支持断言(predicate)机制,该机制支持所有加载和存储指令的条件执行。整数、short和char的加载和存储使用单个断言(prX.b)进行谓词,而加载和存储双短类型(s2)则使用双谓词(prX.b2)进行谓语
设置断言时,加载和存储指令根据指令访问内存。清除标量断言时,不会发生加载或存储操作。即使断言被清除,也可以在加载操作中访问内部存储器;然而,由于该指令,没有写入目标寄存器,并且没有断言访问保护评估。清除标量断言时,不会访问外部内存。
6.5 内存访问
LS0和LS1单元都支持对数据存储器的各种类型的存储器访问。以下部分描述了描述每个访问的参数。
6.5.1 未对齐的内存访问
硬件完全支持未对齐的数据内存访问,没有任何核心暂停周期。支持对齐和未对齐访问而不受惩罚的能力可以具有指令较少的优势,这导致提高核心性能和减少代码大小。
6.5.2 Access参数
每个访问都具有以下参数:
- 访问类型:基本类型为8位字符(C)、16位短整型(S)和32位整型(S)。访问也可以是基本类型的倍数(例如,两个字符(C2))。
- 内存访问宽度:从一个字符(8位)到四个短整数/两个整数(64位),最多四个整数。
- 数据类型:这是有符号操作数或无符号操作数,在指令的语法中描述。默认情况下,内存操作数是符号扩展的。如果在指令中指定[,u]参数,则内存操作数将被视为无符号操作数,并进行零扩展。
6.5.3 LSU操作
LSU可以操作加载和存储的数据类型。在加载操作中,LSU可以从内存中读取一个数据元素,更改元素类型,然后将其写入处理器寄存器。在存储操作中,LSU可以从处理器寄存器读取数据元素,更改元素类型,然后将其存储到内存中。
6.5.4 标量加载和存储操作
标量加载和存储操作用于加载和存储GRF、ARF和SRF寄存器。LS0支持标量加载操作,它可以从内存中读取多达128位。LS1支持标量存储操作,它最多可以将128位写入内存。
例6-12. 标量加载操作
|
将立即数移动到用作基地址的地址指针: mov #0x1000,r7 使用索引寻址模式的标量调用: ld(#65+r7.ui).us2,r10.ui,r5.ui 假设位置0x1040处的存储器内容是从存储器加载的两个8未整数,零扩展,并写入寄存器r10和r5:
执行后: r10 = 0x00001234 r5 = 0x00001BCD |
6.6 写入序列后读取
写入缓冲区增加写入事务的延迟;然而,它必须对核心读取事务透明。地址匹配机制允许暂停尚未写入内存的核心读取数据。
访问存储器的每个读取事务都会生成额外的访问,以检查所需的数据是否在写入缓冲区中。一组比较器检查所请求的地址或其一部分是在地址延迟线中,还是在等待写入存储器的写入缓冲器中。然后,读取匹配机制为读取事务的每个字节生成暂停。
6.7 GetBits机制
GetBits是一种可选的硬件可配置机制,它允许从存储器阵列读取数据,并从中提取不同长度的连续位字段。单个指令最多可以读取32位。
6.7.1 支持寄存器
以下寄存器支持GetBits机制,如表 6-4中所述:
- StreamBuff:从中提取位字段的64位缓冲区。缓冲区由两个32位寄存器组成:StreamBuff1(MSP)和StreamBuff 0(LSP)。
- 一种临时32位缓冲区(TstreamBuff),用于存储从内存加载的数据。
- 一种模式和状态寄存器(GBCTL),其中存储当前字段指针和空状态。
表6-4.GetBits寄存器
| 寄存器名称 | 大小[位] | 描述 |
| StreamBuff0 | 32 | 流缓冲区的下部 |
| StreamBuff1 | 32 | 流缓冲区的上部 |
| TstreamBuff | 32 | 从内存加载的传入数据的临时缓冲区 |
| GBCTL | 6 | 专用GetBits模式和状态寄存器: Bit[31]=诱人 设置何时可以将数据加载到TstreamBuff,即Tstream Buff为空。 位[4:0]=流式处理器 保存指向StreamBuff1中的位的指针,从中可以读取下一个字段 |
6.7.2 getbits指令
执行GetBits指令时,GetBits机制被激活。支持的格式为:
getbits{[show][,big]}(rN.ui).ui+#4,rA.ui,rZ.ui getbits{[显示][,大]}
其中:
- rA或immB6指定要提取的字段的宽度,以位为单位。
- rZ指定存储提取字段的目标寄存器。
- rN指定在需要时将位流的延续从中加载到流缓冲区的内存指针。
- {big}确定如何处理数据:
- 如果指定,则数据被视为Big Endian。
- 如果不是,则将数据视为Little Endian。
- {show}在不更新缓冲区和streampter字段的情况下提取数据
GBCTL寄存器,如第6.7.4节“显示比特流”中所述。
在使用getbits提取位之前,应按照第6.7.5节“流初始化”中的描述初始化缓冲区。
有关getbits指令的结构和操作的更多详细信息,请参阅CEVA-BX2体系结构规范第二卷。
6.7.3 作业流程图
getbits指令指定要从缓冲区提取的位数,以及该字段将更新的目标字段。StreamBuff1寄存器中要从中提取字段的指针在GBCTL寄存器的streampter字段中指定。指针以StreamBuff的MSB开始(在StreamBuff1中),字段向右扩展,朝向StreamBuffef的LSB。该字段最长可达32位,并且可以从StreamBuff1寄存器扩展到StreamBuffe0寄存器。
当执行getbits指令时,提取位字段,并将流指针与要在streampter字段中更新的提取字段的长度相加。如果添加后指针超过32位,则会发生以下情况:
- 实际写入streampter的值环绕(即,从中减去32),以便streamptor始终指向StreamBuff1内部。
- StreamBuff0复制到StreamBuff 1。
- TstreamBuff被复制到StreamBuff0。
- 设置了GBCTL寄存器中的temply字段,表示TstreamBuff不包含有效数据。
如果在执行getbits指令时设置了试探指示,则对由getbits指针操作数的值指向的TstreamBuff执行32位内存加载。指针更新为4。
图 6-2 显示了getbits指令期间的功能数据流。
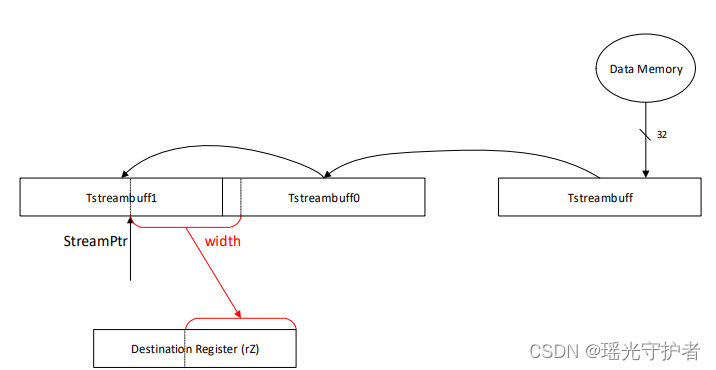
图6-2. getbits指令的高级数据流
流中的位以Little Endian或Big Endian顺序从内存中读取(根据getbits指令中的{Big}开关),使内核能够以正确的方式读取流。
例6-13.使用getbits指令读取比特流
|
获取位(r0.ui).ui+#4,#0xa,r3;从streamBuff寄存器读取10位。 此指令从streamBuff寄存器读取10位。r3被零扩展到32位。 假设:
如果设置了试探指示,则从存储器中r0指向的地址加载32位,并且r0更新4。 |
6.7.4 显示位流
当在getbits指令中设置{show}开关时,位仅直接从streamBuff寄存器读取到目标操作数,并且GBCTL寄存器中的streamPtr字段不会更改。
此指令仅用于显示streamBuff的内容,而不修改它。指令读取的位数由另一个寄存器或指令中的立即数指定。并对此进行演示。
例6-14.使用getbits指令显示比特流
|
getbits (r0.ui).ui+#4, #0xa, r3 ; Read 10 bits from the streamBuff register. This instruction reads 10 bits from the streamBuff register. r3 is zero-extended to 32 bits. Assuming: • streamBuff = 0xd4c2_981a_77ef_01ba • streamPtr = 25 Then after execution: • r3 = 0x0000_00d3 • streamPtr = 3 If the tempty indication is set, 32 bits are loaded from the address pointed at by r0 in the memory, and r0 is updated by 4. |
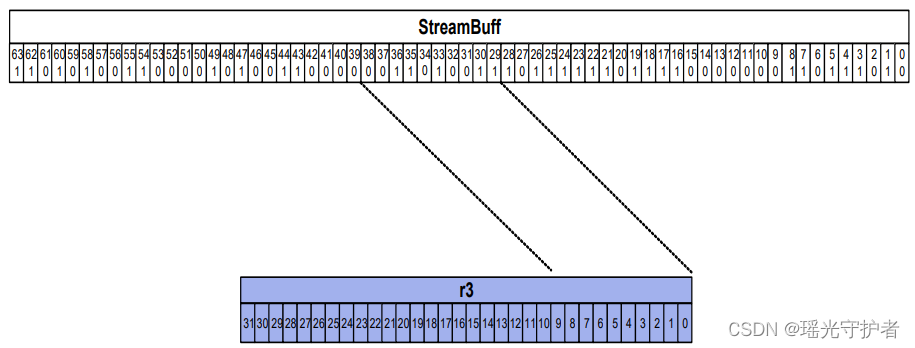
图6-3.使用getbits指令显示比特流
6.7.5 流初始化
要初始化位流读取机制,请执行以下操作:
- 将流的前64位加载到streamBuff1和StreamBuff0中
- 寄存器(每个寄存器通过单独的指令)。
- 清除GBCTL寄存器中的streamPtr字段,以指示streamBuff已满。
- 将temply字段设置为1,以指示TstreamBuff寄存器为空。
例6-15.GetBits流初始化
|
r0 is assumed to point to the start of the bit stream in memory. ld (r0.ui).ui+#4, r5.ui mov r5.ui, streamBuff1.ui ; initializing streamBuff high part. ld (r0.ui).ui+#4, r5.ui mov r5.ui, streamBuff0.ui ; initializing streamBuff low part. mov #0x80000000, r5.ui mov r5.ui, gbctl ; Clear streamptr, ;Set the TstreamBuff empty indication |