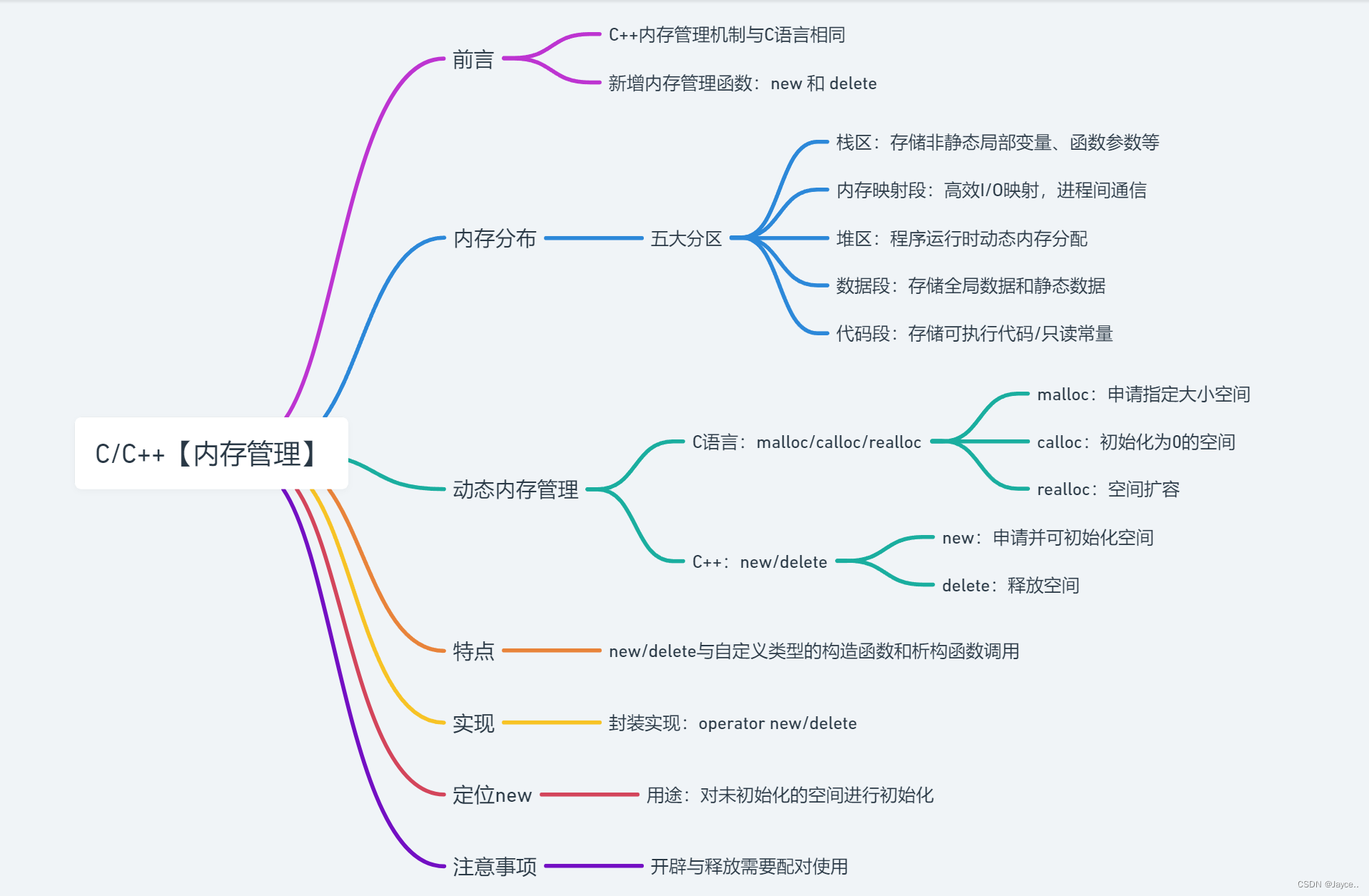
GPT是一种Transformer Decoder架构,Decoder通过自回归方式生成下一个词,所以擅长文本生成任务。
本文将图解GPT2,本系列还有图解Tokenization,Word2Vec,Transformer,Bert。
这篇文章主要来自下面这篇博客。
https://jalammar.github.io/illustrated-gpt2/
正文
今年,应该算得上是大模型年。OpenAI的GPT-2展现出了惊人的写作能力,其生成内容的连贯且富有感情,超出了我们对目前语言模型的预期。GPT-2其实并不是一种新型架构,他的结构类似于只有解码器的Transformer。GPT-2(Generative Pre-trained Transformer Version2)是一个基于Transformer的巨大的语言模型,并在庞大的数据集上进行了训练。在这篇文章中,我们将看一下是什么构造能让它具有如此性能;我们将深入解析它的自注意力层;最后我们会看一下语言模型之外的仅有解码器的Transformer的应用。
这篇文章也是想补充我之前的博客《图解Transformer》,在这我会用更多的图片来解释Transformers的内部原理,以及它们是如何从原始的Transformer演变过来的。随着Transformer衍生出来的新模型的内部构造不断发展,我希望这系列的图解文章能帮助大家更容易理解这些模型。
1 GPT-2和语言模型
什么是语言模型?
1.1 语言模型
在之前的图解Word2Vec中我们看了什么是语言模型,其实就是一个能根据一部分句子内容预测下一个单词的机器学习模型。最常见的的语言模型大概就是手机输入法,它能根据你当前输入的内容提示下一个字或者词。
从这个角度说,我们可以称GPT-2是一个类似于输入法的预测下一个单词的模型,但是它比输入法更大更智能。GPT-2是在一个叫WebText的40GB的巨大数据集上训练的,这个数据集是OpenAI的工作者从网上收集的。从存储空间来看,我们的输入法只需要几十MB的空间,但是GPT-2最小的模型就需要500MB来存储它的参数,而最大的GPT-2模型是它的13倍,需要6.5GB的存储空间来存储其参数。

你可以通过AllenAI GPT-2 Explorer体验一下GPT-2,它是使用GPT-2预测下一个词,会显示十种可能预测(以及它们的概率分数),你可以选择一个词,然后看它下一个预测列表。
1.2 Transformer的语言模型
在我们之前图解Transformer中已经看到,一个Transformer是一个encoder-decoder构架组成的,编码器和解码器都是由数个Transformer组件堆叠成的。这个结构是很合理的,因为编码器-解码器构架成功解决了机器翻译中的问题。
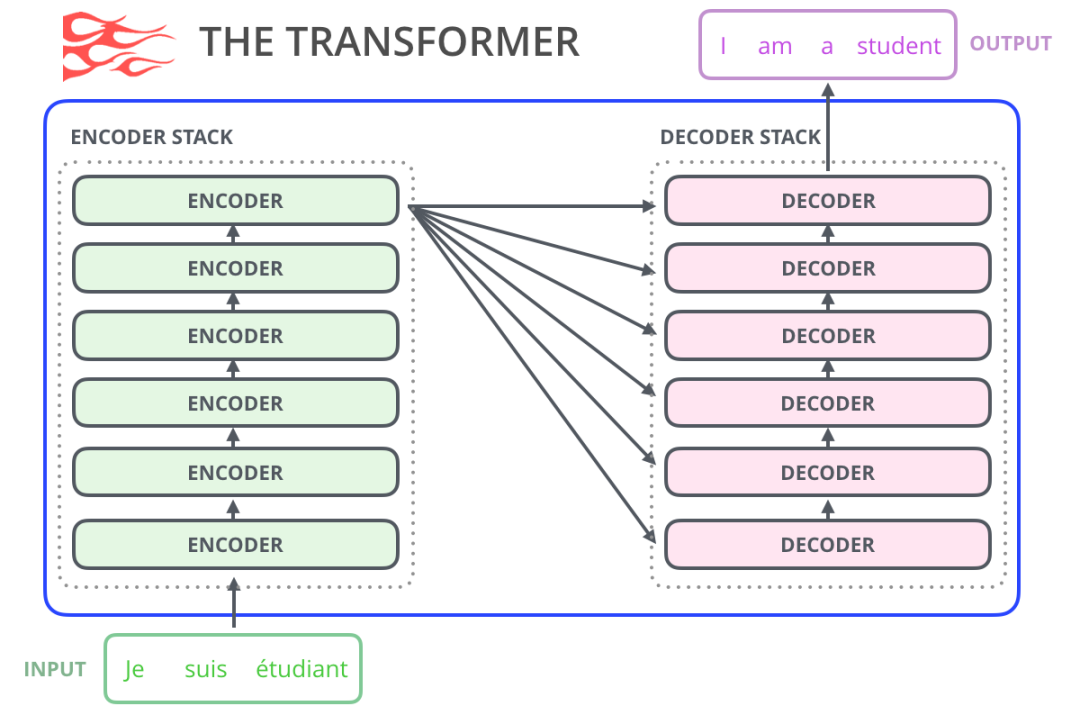
在随后的大量研究工作中,该体系结构抛弃了编码器或着解码器,只使用另一部分Transformer组件。将尽可能多的组件堆叠起来,投入大量计算机资源,用大量文本进行训练(比如一些语言模型需要小几十万美元,AlphaStar可能需要数百万美元)。
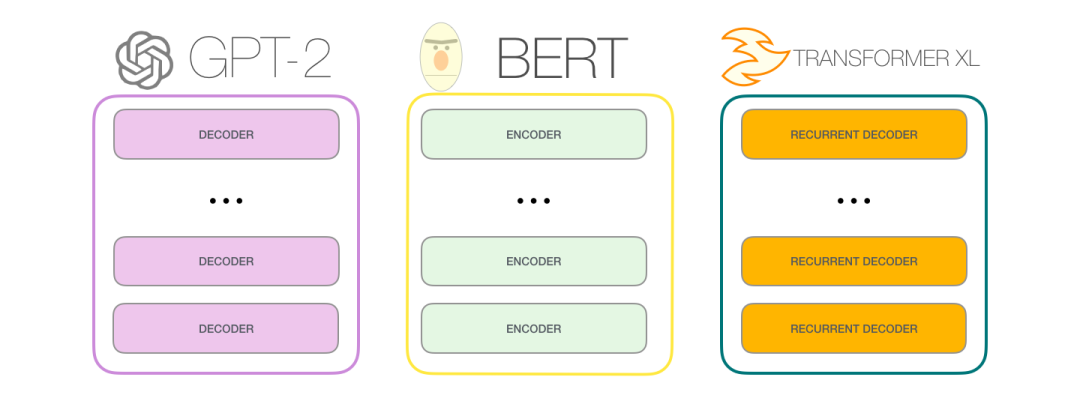
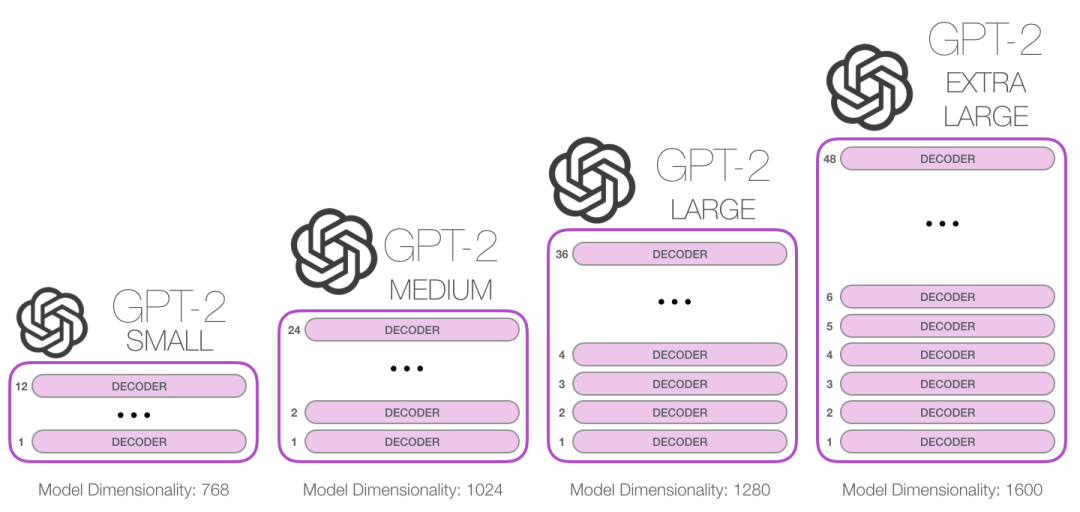
我们能把这些Transformer组件堆多高?GPT-2不同模型大小的区别就在于组件数目的不同:
1.3 和BERT的不同
GPT-2是用Transformer的decoder组件,BERT是用Transformer的encoder组件。我们将在<图解Bert>中继续探讨二者的差异。
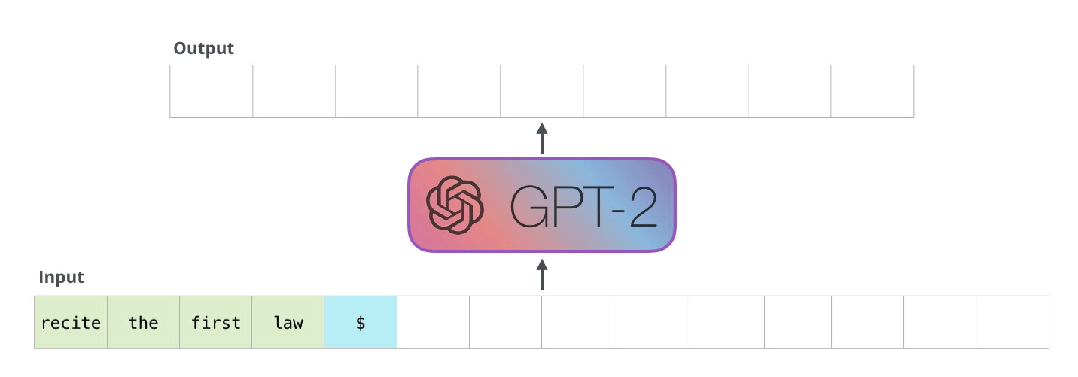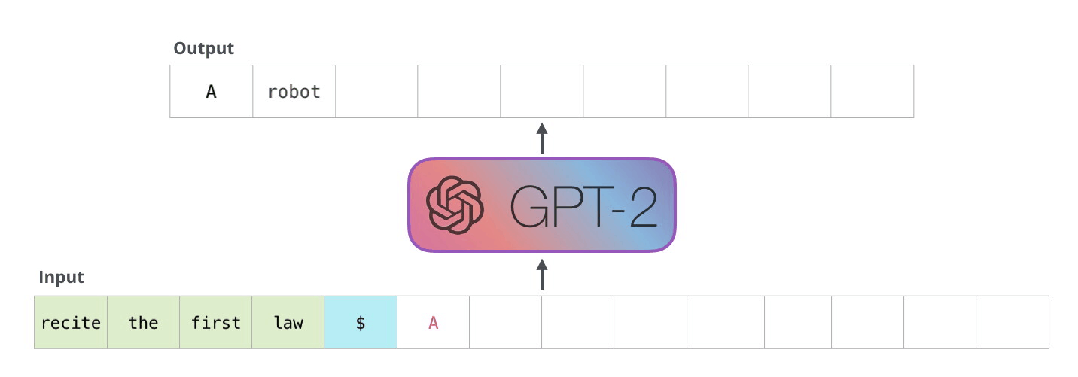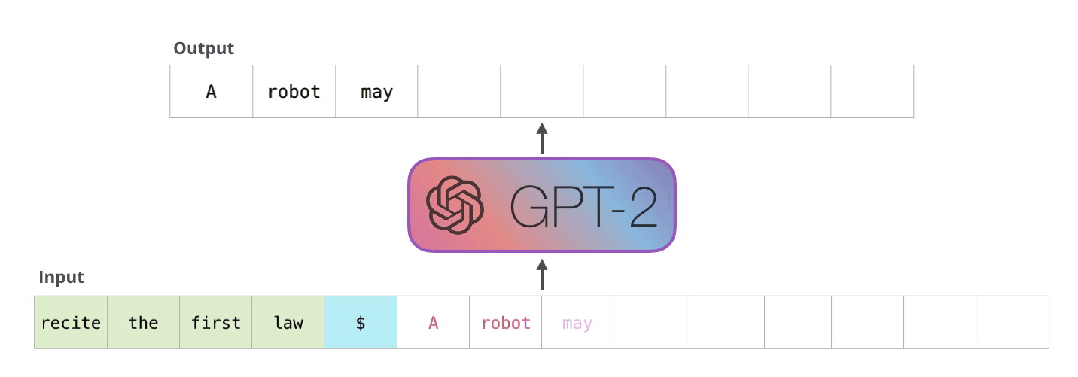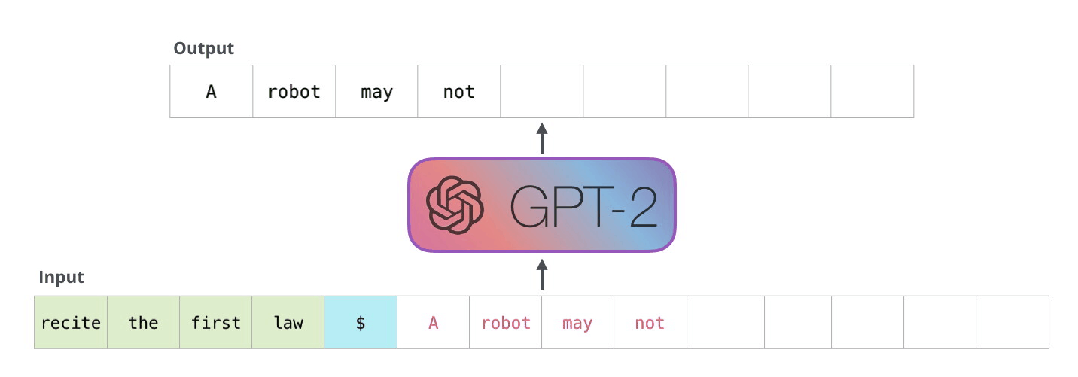
但是两个模型一个关键的区别在于,GPT-2和传统的语言模型一样,一次只输出一个token。例如我们让一个训练好的GPT-2输出机器人第一定律。
First Law of Robotics
A robot may not injure a human being or, through inaction, allow a human being to come to harm.
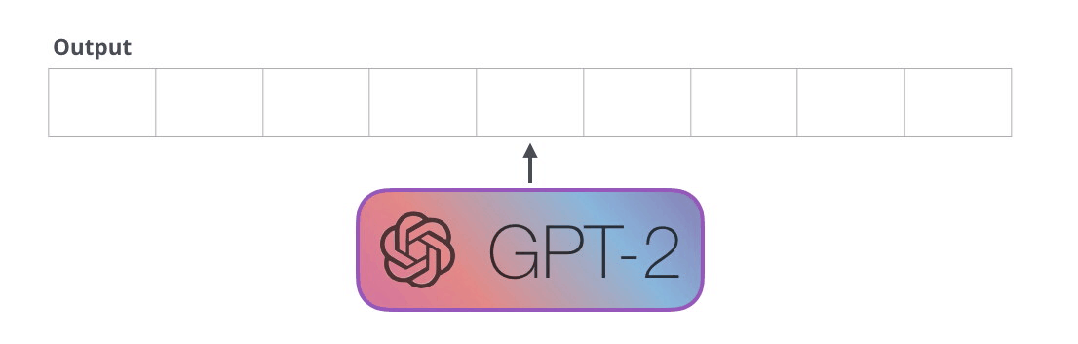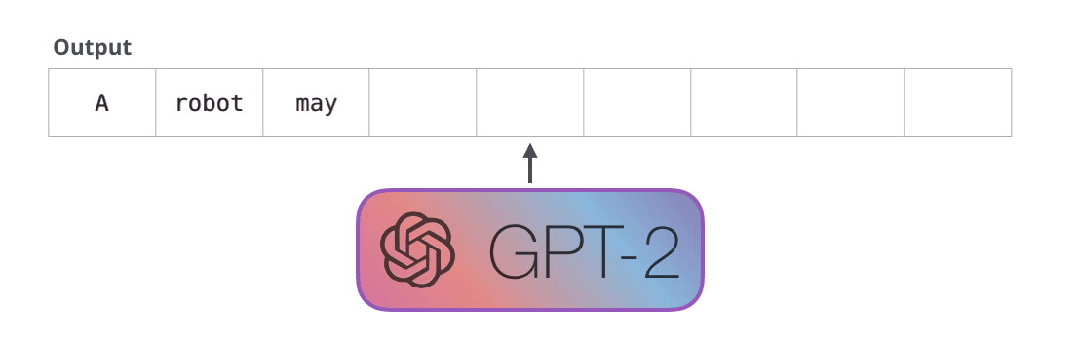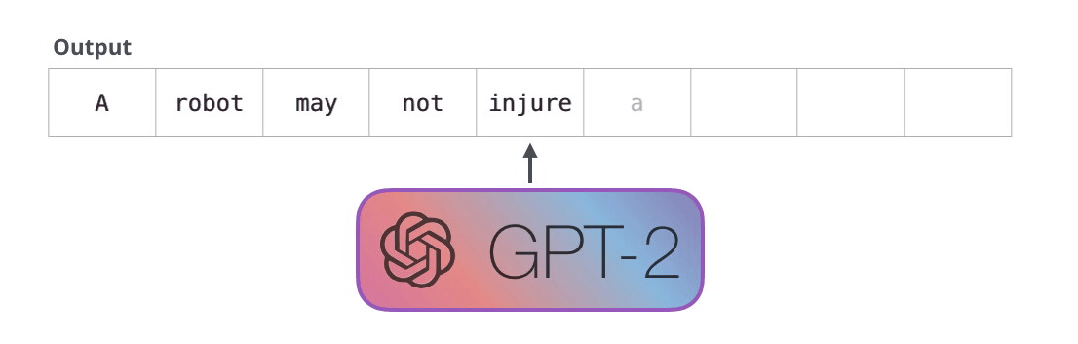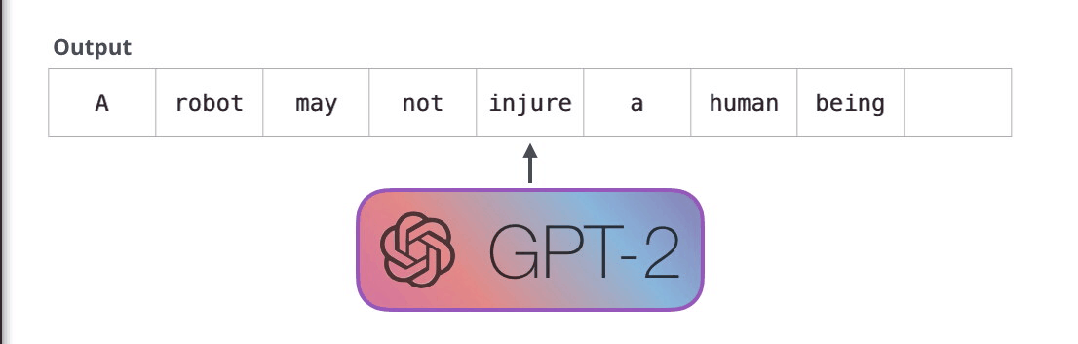
这些模型实际工作的方式:在生成每个token之后,这个token会被添加到输入序列中组成新序列,新序列作为模型下一步的输入。这方式被称为“自动回归”(auto-regression)。这就是RNNs模型的一个机制。
GPT2以及TransformerXL和XLNet等后来的模型本质上看都是自回归模型。当然BERT不是。这是一种权衡,虽然没有自回归能力,但是BERT获得了理解整合上下文的能力,从而获得了更好的结果。XLNet又回到了自回归,但是同时找到了另一种方法来整合双方的上下文。
1.4 Transformer 组件的演变
Transformer论文原文介绍了两种类型的transformer组件:
1.4.1 encoder组件
首先是编码器组件:
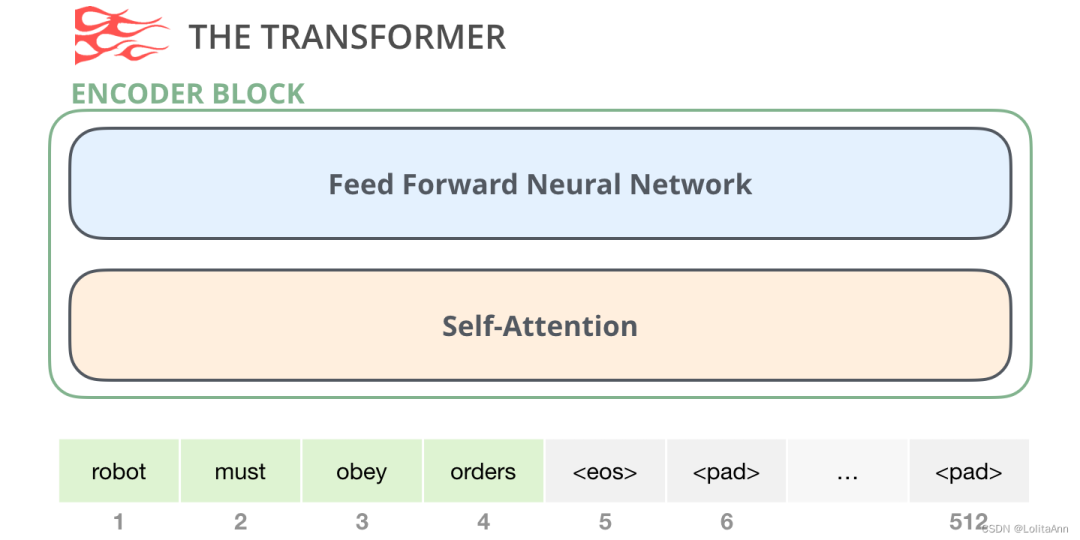
原文中的编码器块可以接收最大长度为512的序列作为输入。如果一个输入序列达不到512也没关系,我们可以把序列的其余部分填充起来。
1.4.2 decoder组件
然后是decoder组件,decoder组件和encoder组件稍微有点不一样,区别是它中间加了一层可以让它关注到encoder的内容。我们也称之为交叉注意力机制。
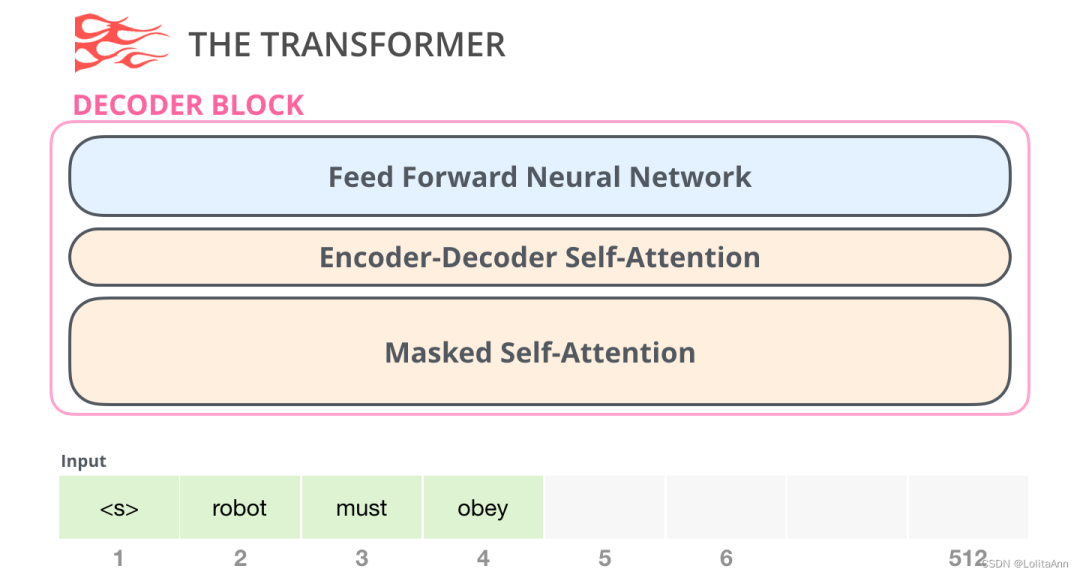
当然这里的自注意力层也有一个关键区别,就是他会把之后的内容mask掉。
不是和BERT那样把词替换为[mask],而是在自注意力计算过程中通过一些方法不让自注意力计算当前位置右侧的内容。
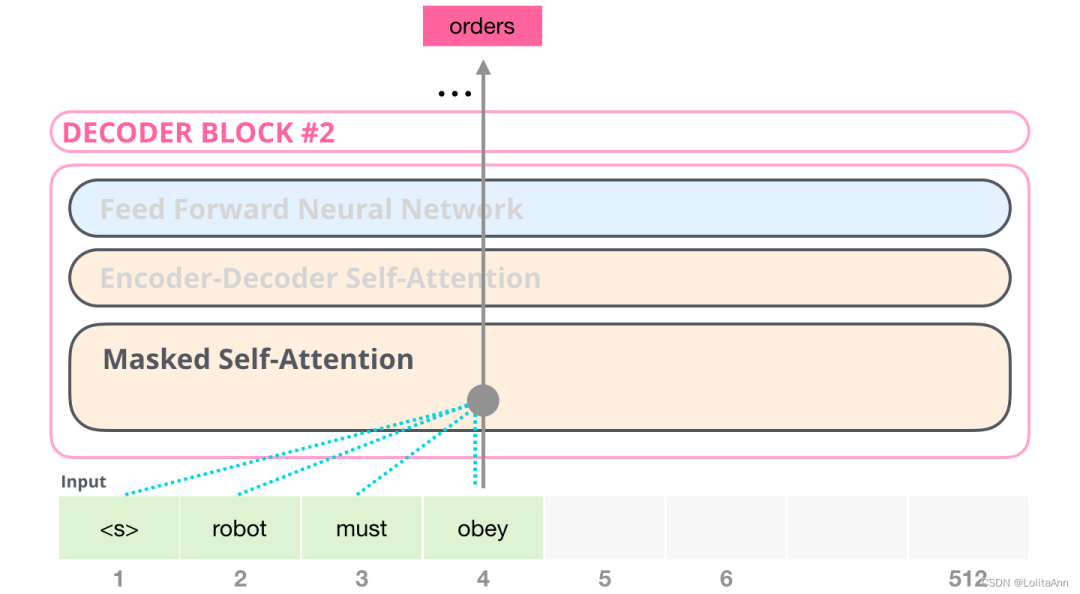
例如,如果我们现在计算第四个单词,他的注意力只能关注到前四个词。
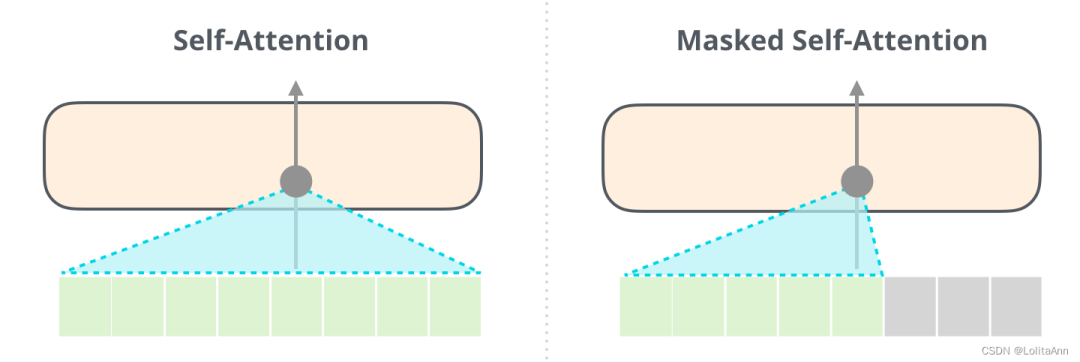
重申一下,BERT的自注意力和GPT-2的屏蔽式自注意力之间是有明显的区别的。一个正常的自注意计算在计算某位置的时候允许模型关注其右边的信息,屏蔽式自注意则不能关注到右侧信息:
1.4.3 只有decoder组件
在Transformer论文之后,Generating Wikipedia by Summarizing Long Sequences 提出了transformer组件的另一种打开方式,也能够进行语言建模。这个模型丢掉了Transformer的编码器,因此我们称之为“Transformer-解码器”。这个早期的基于transformer的语言模型由六个transformer的decoder组件组成:
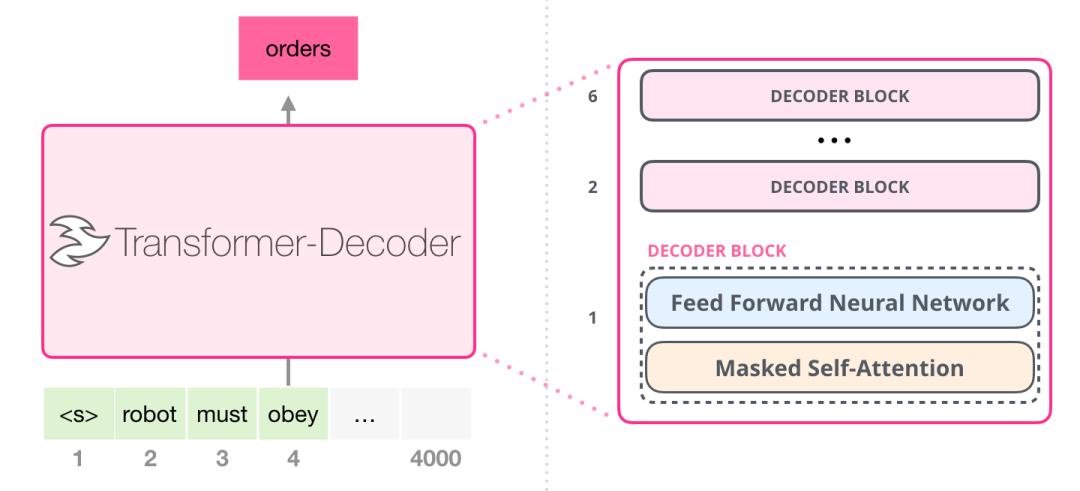
decoder组件都是相同的。我展开了第一个,所以你可以看到它的自注意力层是带mask的自注意。注意,该模型现在可以接受的输入序列长度为4000,这是对比原始transformer输入长度512的一个大规模升级。
这些decoder组件和原始的transformer的decoder组件非常相似,但是他们去掉了第二个自注意力层。Character-Level Language Modeling with Deeper Self-Attention这篇文章也研究了一个类似结构,创建一个语言模型每次预测一个字或词。
本文的主角GPT-2就是这种仅使用解码器组件的模型。
1.5 GPT-2内部构造
让我们把一个训练好的GPT-2丢到手术台上,拆解看一下它是如何运作的。
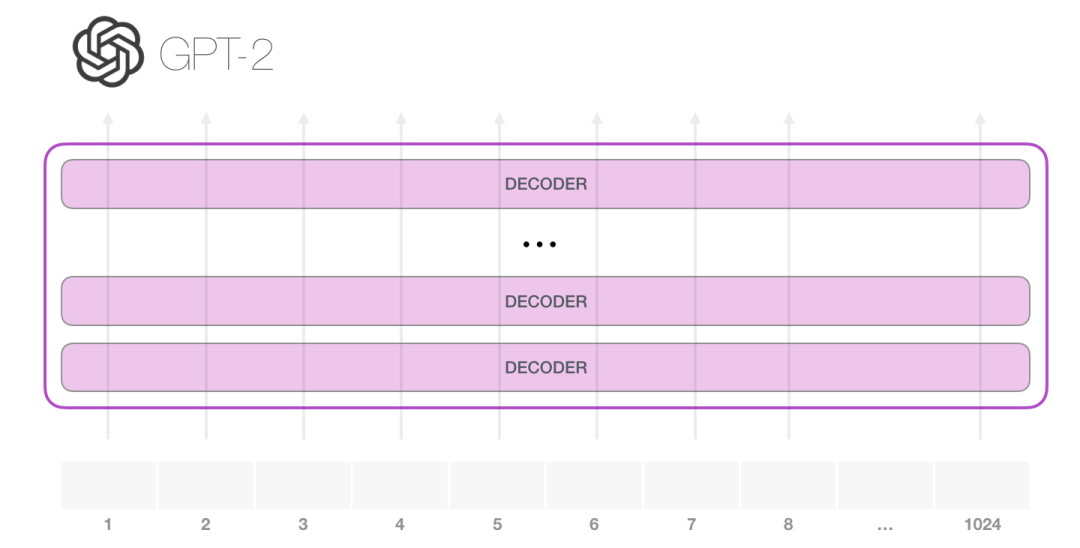
GPT-2可以处理1024长度的tokens,每个token沿着自己的路径流经所有decoder组件。
运行一个已经训练好的的GPT-2,最简单的方法是让它自己运行,或者称之为无条件生样本。我们也可以给它一个提示(prompt),让它围绕一个特定的主题生成,或称之为交互式条件样本生成。
在无限制的情况下,我们只需要给他一个开始标记,就可以让他开始生成词语(训练好的模型使用<|endoftext|>作为开始标记,之后我们用<s>来代替)。
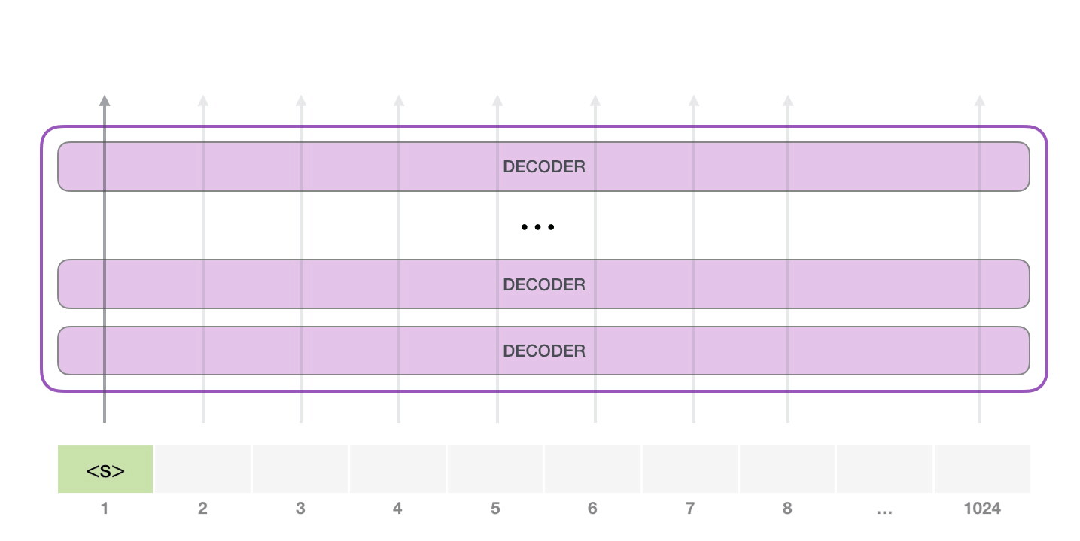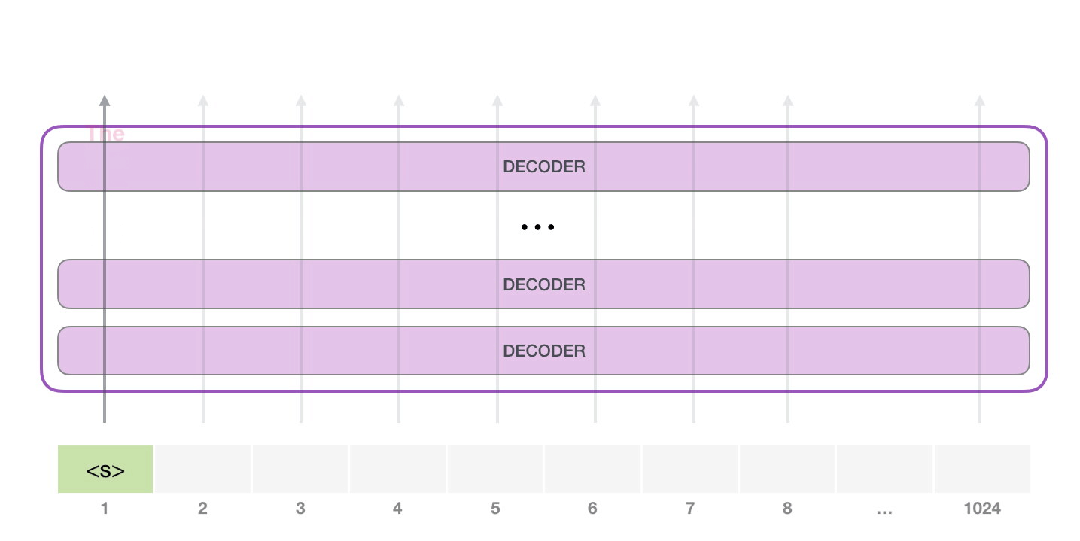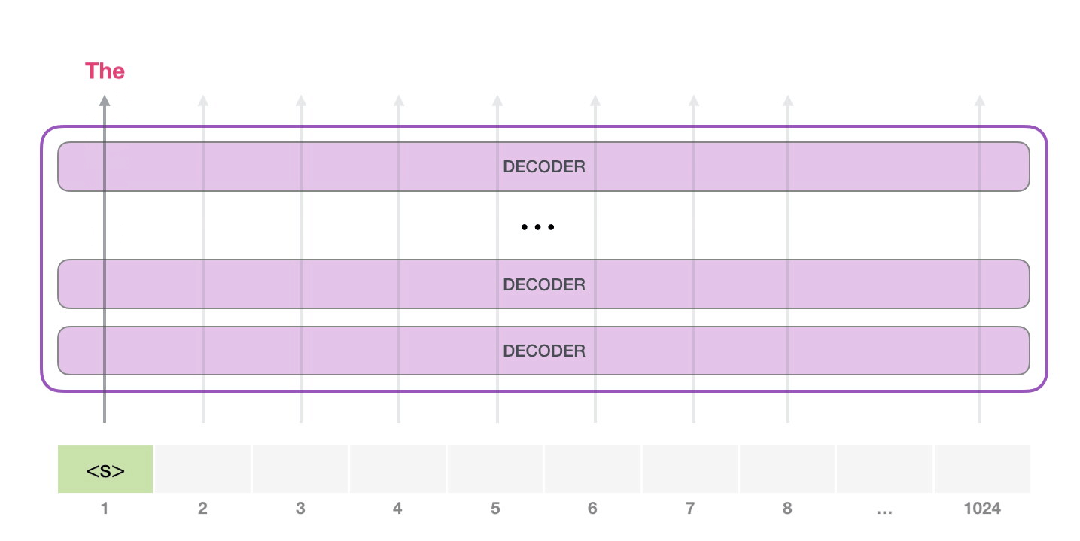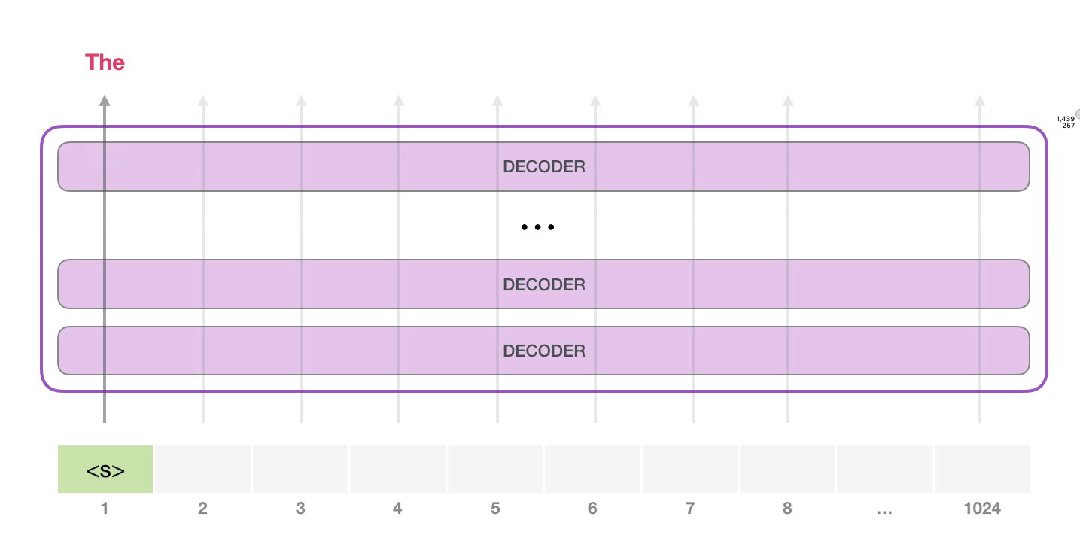
该模型只有一个输入标记,所以该路径将是唯一的活动路径。这个token在所有层中被连续处理,然后会产生一个向量。这个向量可以根据模型的词汇表进行评分,词汇表就是模型知道的所有单词,GPT-2的词汇表是5万词。在这个例子中,我们选择了概率最高的token:“the”。
我们也可以从中调节:你想一下,如果你在输入法里不断点击提示单词,它有时会陷入重复,就是一直都显示同样的文字,唯一的解决办法是你点击第二个或第三个建议的单词。同样的情况也会发生在GPT-2里。
GPT-2有一个叫做top-k的参数,我们可以借助它,让模型采样除了最高概率单词以外的单词(top-k=1时就是上边说的情况)。
在下一步,我们将第一步的输出添加到我们的输入序列中,并让模型进行下一次预测。
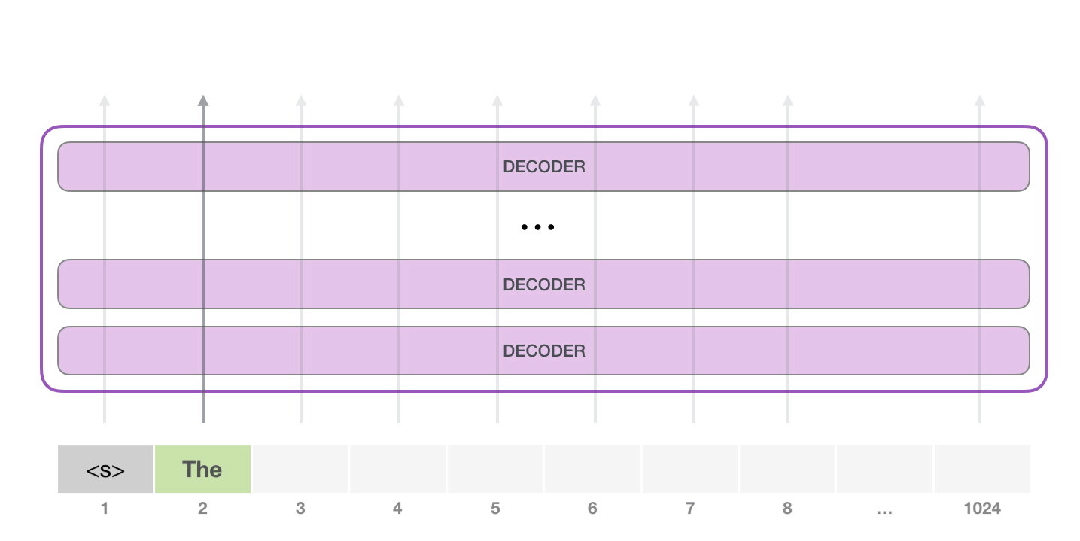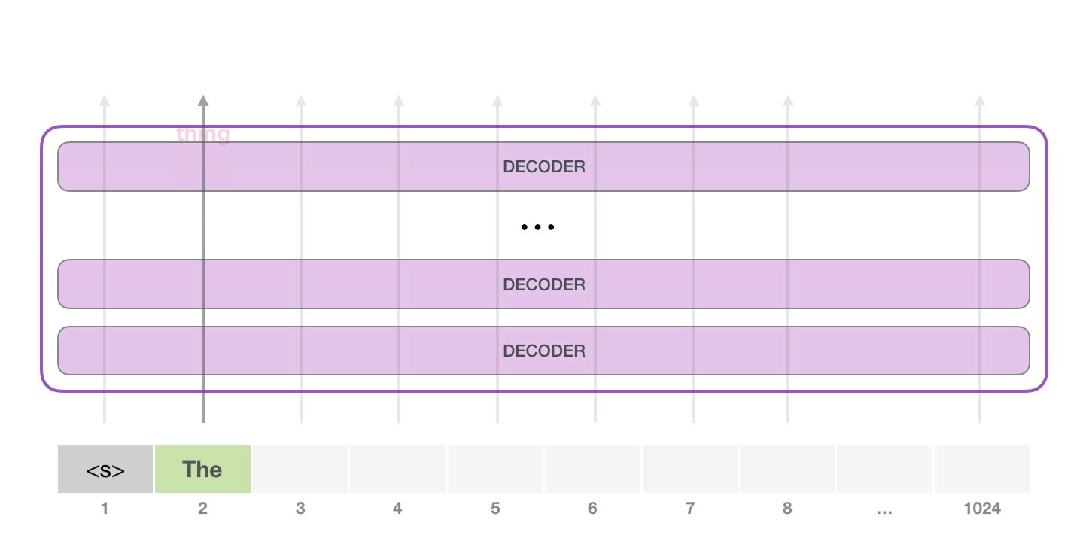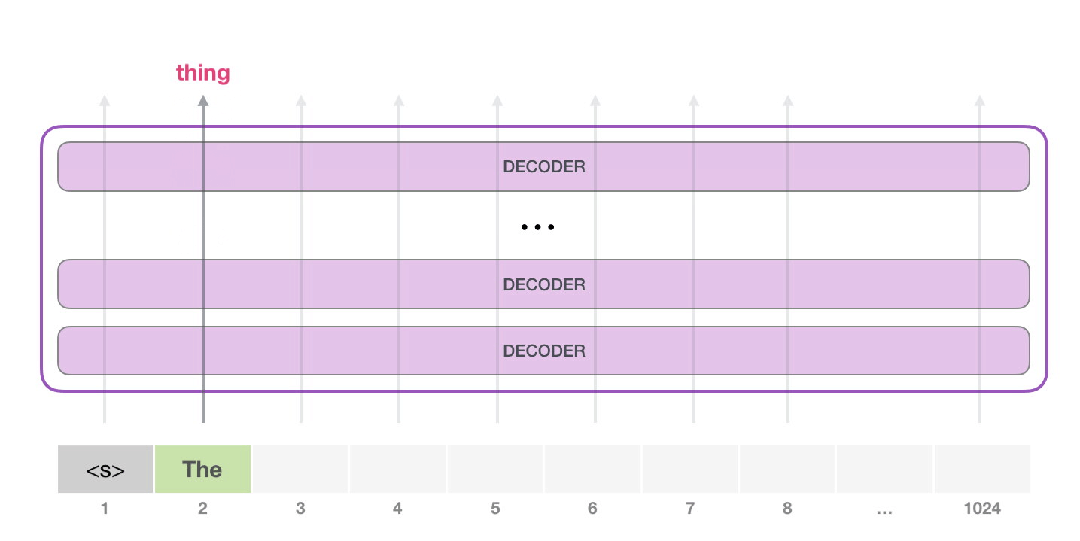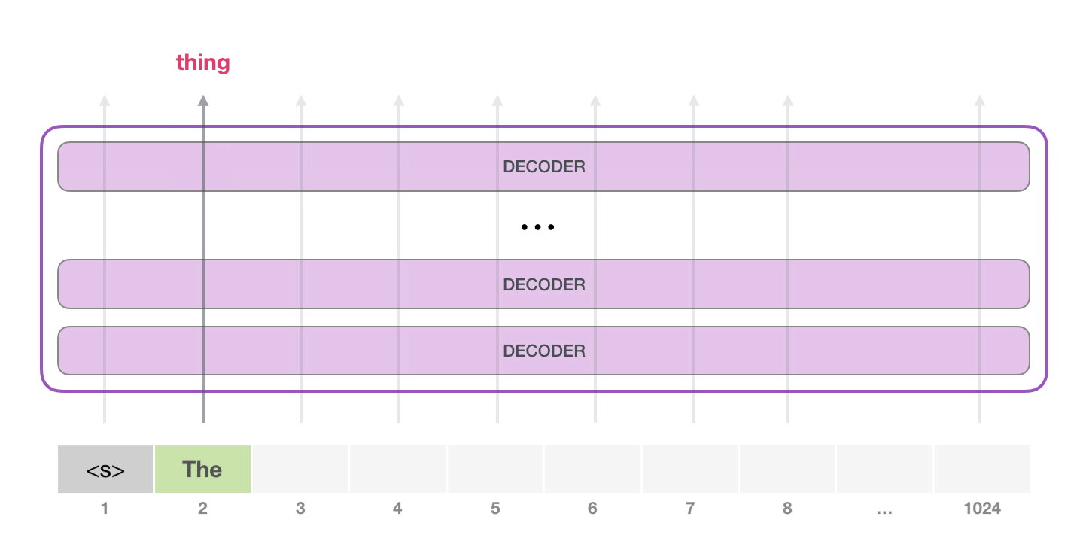
注意,现在第二条路径是计算中唯一活动的路径。GPT-2的每一层都保留了自己对第一个token的解释,并在处理第二个token时使用自己存储的解释(我们将在后边自注意部分对此进行详细介绍)。GPT-2不会根据第二个token内容对第一个token重新编码。
1.6 更深入了解内部构造
1.6.1 输入编码
看一下更多的细节加深对模型的理解。先从输入开始看。跟我们之前说到的其他模型一样,模型会先从embedding矩阵中查找输入单词的embedding向量,embedding矩阵可以看做是预训练模型的一部分。
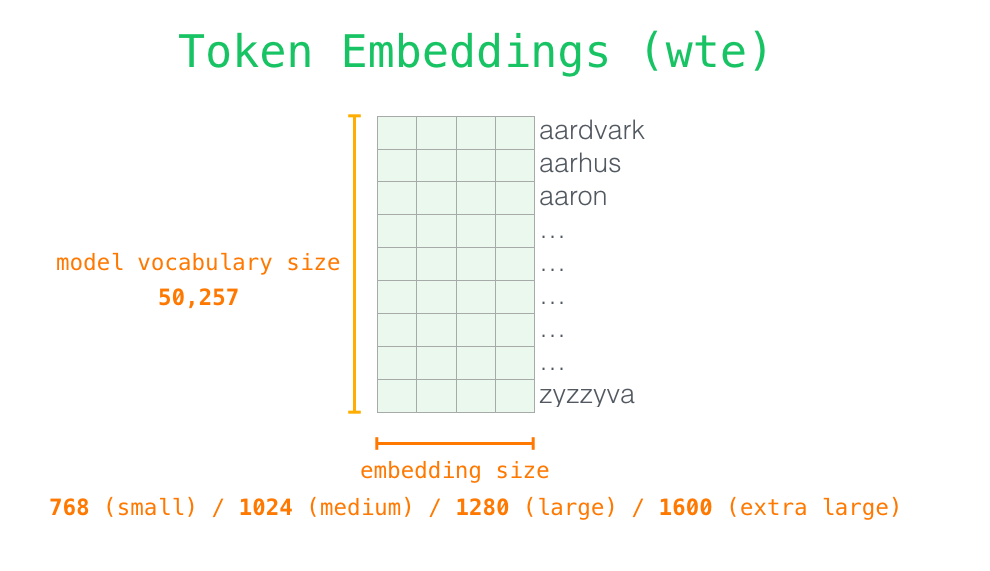
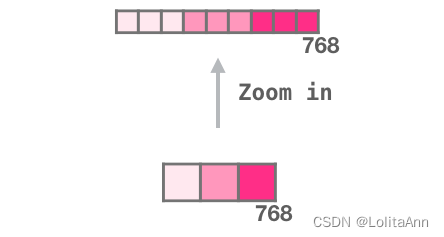
每一行都是一个单词的embedding向量:用一组数字表示一个词语,这组数字是捕获词语的一些含义信息。向量长度在不同大小的GPT-2中是不一样的。最小的GPT-2模型(GPT-2 small)中每个token的embedding向量长度为每768。
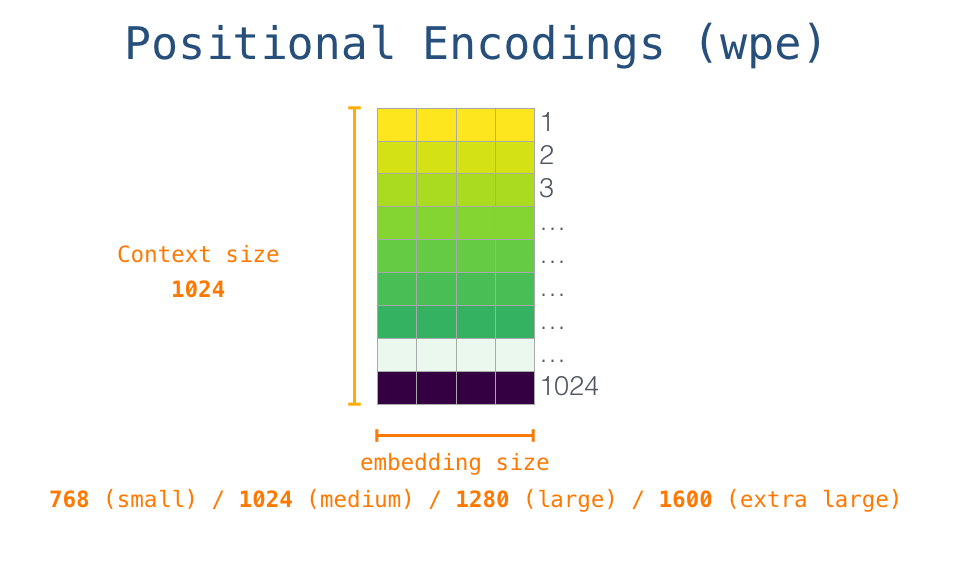
因此最开始我们需要到embedding矩阵中找到开始token <s> 。在把它丢给模型第一个块之前,我们需要给它加上位置编码,位置编码作用是给transformer组件指示该单词在输入序列中的位置。
位置编码矩阵也是GPT-2模型的一部分,它包含输入中1024个位置的每个位置编码向量。
至此,我们已经介绍了在将输入词交给第一个transformer组件之前如何处理这个单词。我们还知道训练好的GPT-2中的两个权重矩阵。

把一个单词丢进transformer组件之前要做的事:先找到该单词的embedding,再把它和对应的位置编码相结合。
1.6.2 堆栈之旅
先看最底下第一个decoder组件,要处理的token先经过自注意力层的处理,再经过神经网络层的处理,处理完之后把它结果丢给下一个decoder组件。每个组件的处理流程都是一样的,但是每个组件的自注意力层和神经网络层都有自己的权重。
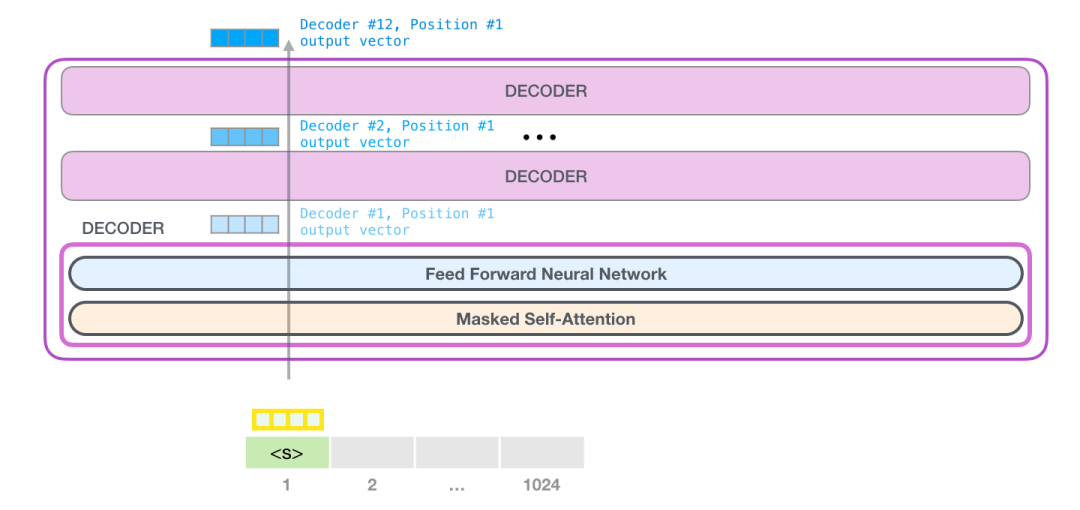
1.6.3 回顾自注意力
语言很大程度上依赖于语境。例如,看看机器人第二定律:
Second Law of Robotics
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
我在句子中标出了三个地方,这些地方的单词是指代其他单词的。如果不结合它们所指的上下文,就没有办法理解或处理这些单词。当一个模型处理这个句子时,它必须能够知道:
-
it 指的是 robot
-
such orders前半部分的 the orders given it by human beings
-
First Law 指的是机器人第一定律
这就是自注意力要做的。在处理某个单词之前,它会先让模型理解相关单词,这些相关单词可以解释某个单词的上下文。注意力要做的就是给每个词进行相关度打分,并将它们的向量表示相加来。
举个栗子,处理“it”的时候,注意力机制会关注到“a robot”,注意力会计算三个词“it”、“a”、“robot”的向量及其attention分数的加权和。
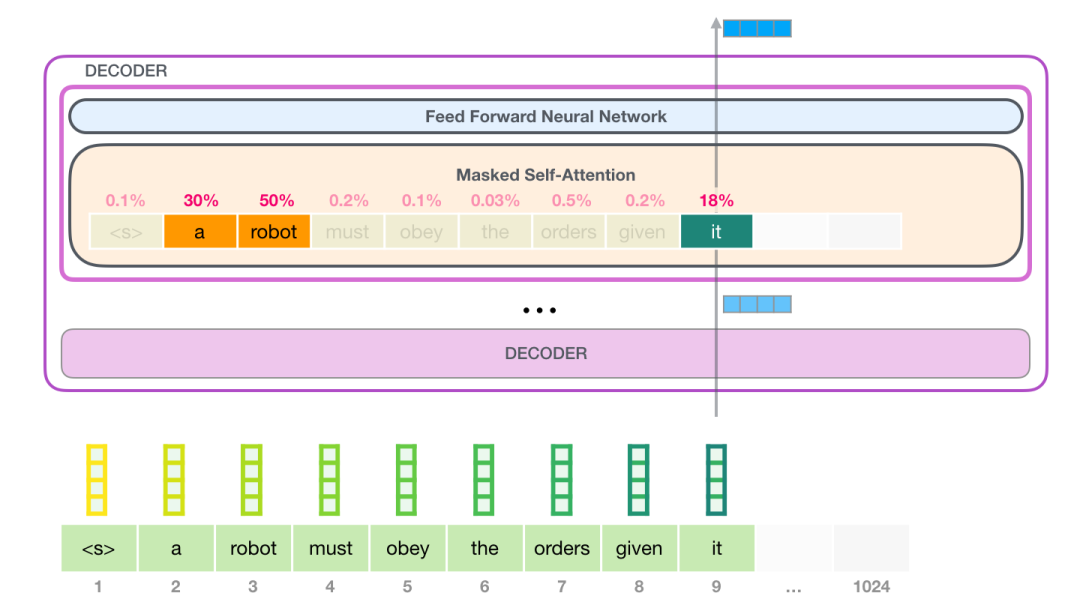
1.6.4 自注意力处理过程
自注意力处理过程是沿着序列的每个token的路径处理的, 主要组成部分是下边三个向量:
Query: query是当前单词的表示形式,用于对所有其他单词(key)进行评分,我们只需要关注当前正在处理的token的query。
Key: Key可以看做是序列中所有单词的标签,是在我们找相关单词时候的对照物。
Value: Value是单词的实际表示,一旦我们对每个单词的相关度打分之后,我们就要对value进行相加表示当前正在处理的单词的value。
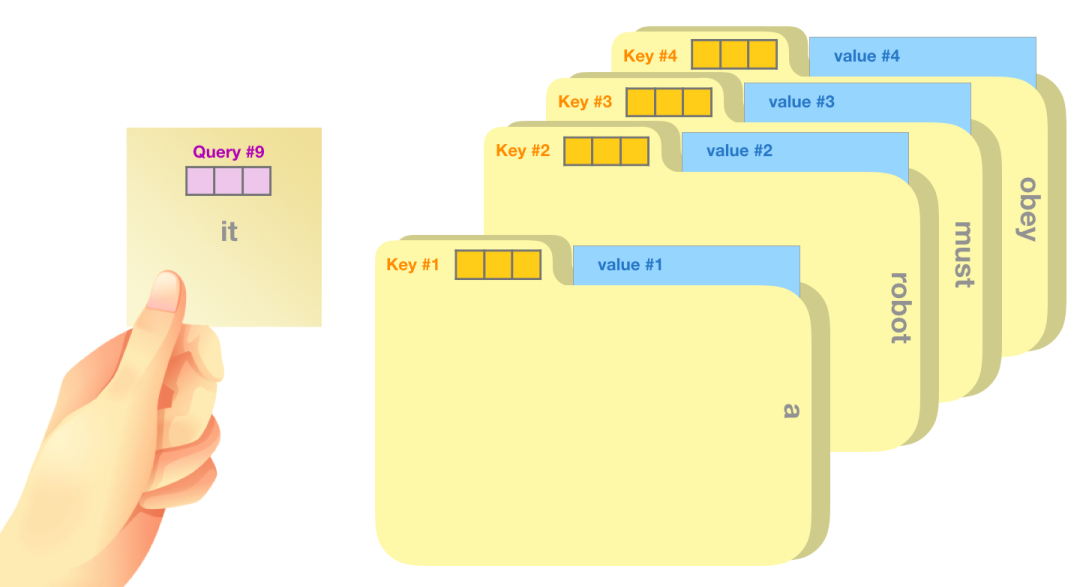
一个简单的比喻是,就像在文件柜里找文件一样。query就像一张你拿着一张便签,上面写着要找的主题。key就像柜子里文件夹的标签,当你找到与便利贴上相关的标签的时候,我们取出该文件夹,文件夹中的内容就是value向量。当然你要找的不是一个文件,是一组相关文件。
将query向量乘以key向量生成文件夹的相关度分数(实现上就是两个向量点积之后softmax)
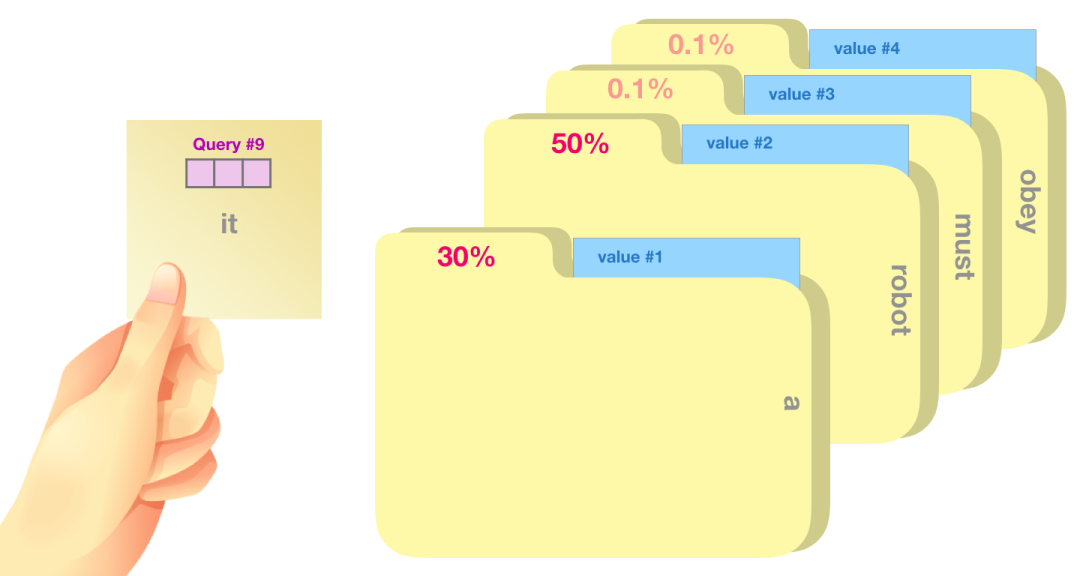
我们把每一个相关度分数乘以一组value,然后相加,这就产生了我们自注意力的结果。
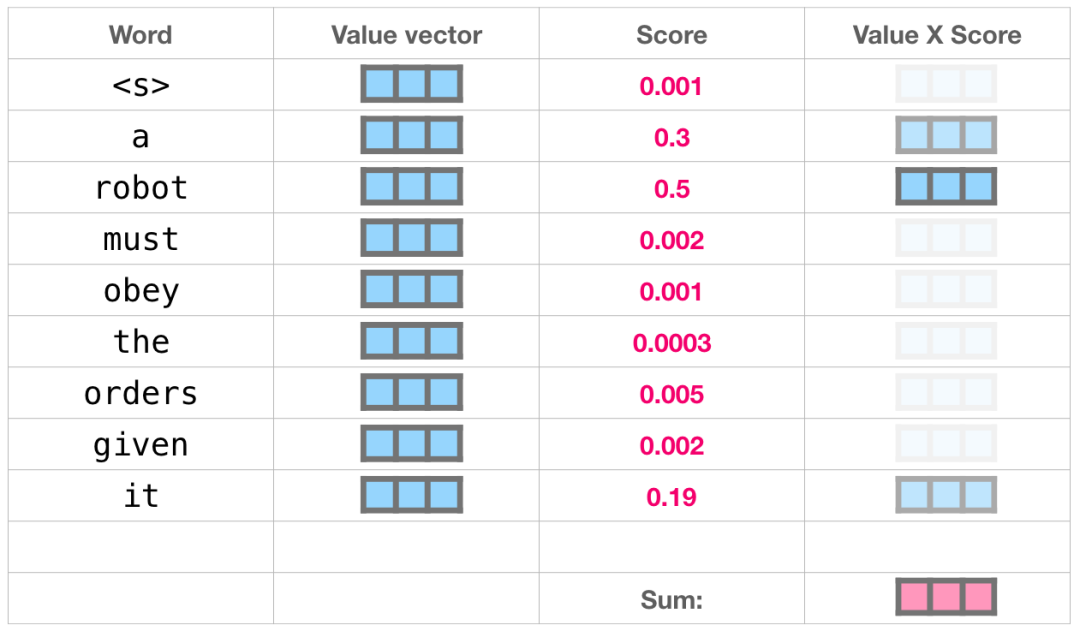
向量加权换和计算在上图的例子中就是将50%注意力放在“robot”这个词上,将30%注意力放在“a”这个词上,将19%的注意力放在“it”这个词上。如果你想详细了解,第二部分我们会更深入探讨自注意力机制,在这我们就简略说一下这一部分,继续往下看模型输出是怎样的。
1.6.5 模型输出
当模型最后一个decoder组件产生输出向量的时候,会把这个向量和embedding矩阵做乘法。
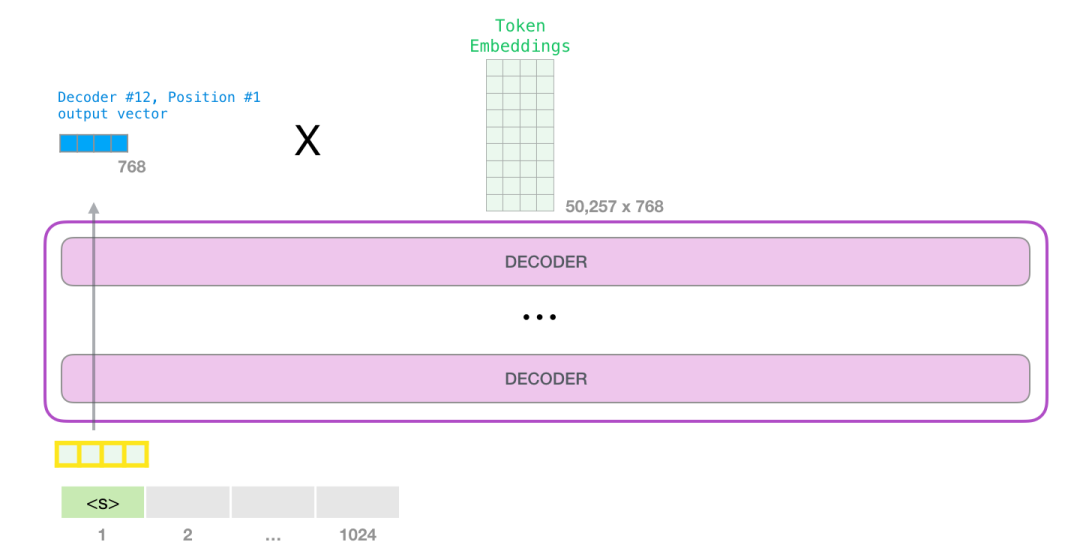
回想一下,embedding矩阵中的每一行对应词汇表中的一个单词。因此这个乘法的计算结果我们可以认为是当前单词结果对整个词汇表的打分。
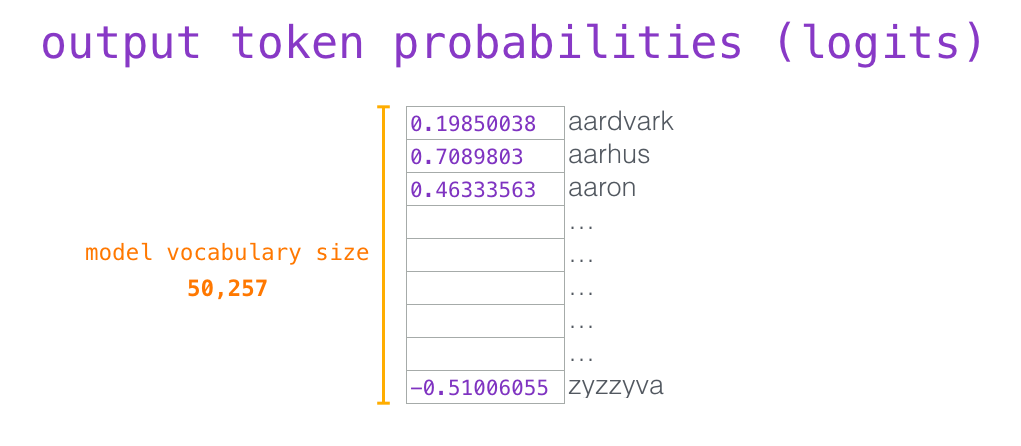
我们可以从中选出分数最高的那个词(top_k=1)。但是模型考虑其他词汇可能会取得更好的结果。因此一个更好的策略是使用这个分数进行随机采样,从中抽一个词出来,这样分数高的词汇被选中的概率也高。还有一种更一般的方法是将tok_k设置为40,从中选取40个得分最高的词汇。
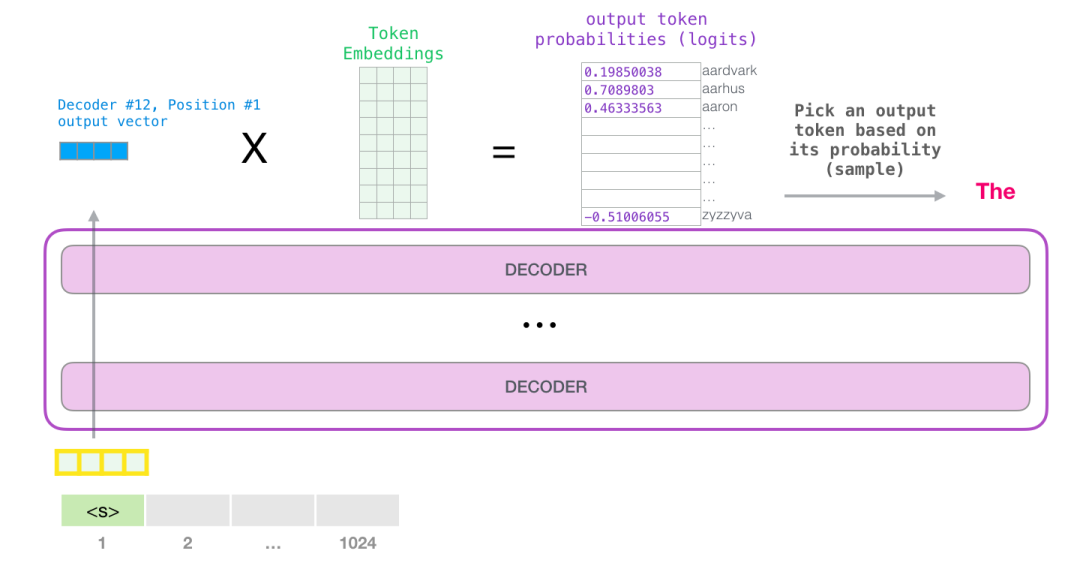
这样,模型就完成了一次迭代,最终输出了一个单词。该模型继续迭代,直到生成整个上下文(GPT-2序列上限1024个token)或直到生成序列结束的token<e>。
1.7 GPT-2小结
现在我们知道了GPT-2是如何工作的了。如果你想继续了解自注意力层是如何运作的,接下来的额外部分就是为你准备的。我补充这部分内容是为了更详细地图解自注意力机制,以便引入更多基于Transformer的模型(比如TransformerXL、XLNet等)。
另外要指出在这篇文章中一些过分简化的内容:
-
原文中没有明确区分“words”和“tokens” 的概念。但是实际上GPT-2 使用 Byte Pair Encoding创建单词表的tokens。这意味着GPT-2中token是word的一部分。
-
本文用的示例都是GPT的推理、评估模式,这就是为什么一次只处理一个单词。在训练的时候GPT-2是可以对长文本序列进行并行处理的。同样在训练时候,不同于评估时候batch为1,GPT-2可以处理的batch大小为512。
-
为了更好安排文章图像的空间,我对一些向量进行了转置。但在模型执行的时候必须更精确。
-
Transformers 使用大量的层归一化(layer normalization)我们在《图解Transformer》中提到过,但在这篇文章中我们主要是讲自注意力。
-
有时候我需要用更多的块块表示一个向量,我是这样画的。
2 图解自注意力机制
在《图解Transformer》中,我们通过下面这张图片来展示在处理单词"it"时自注意力是如何被应用的。

在这一部分,我们将详细介绍如何实现自注意力。请注意,我们将以一种能够理解个别单词处理过程的方式来进行介绍。这就是为什么我们会展示许多单个向量。实际实现是通过相乘巨型矩阵完成的。但是在这里,我想重点关注对单词层面的直观理解。
2.1没有掩码的自注意力
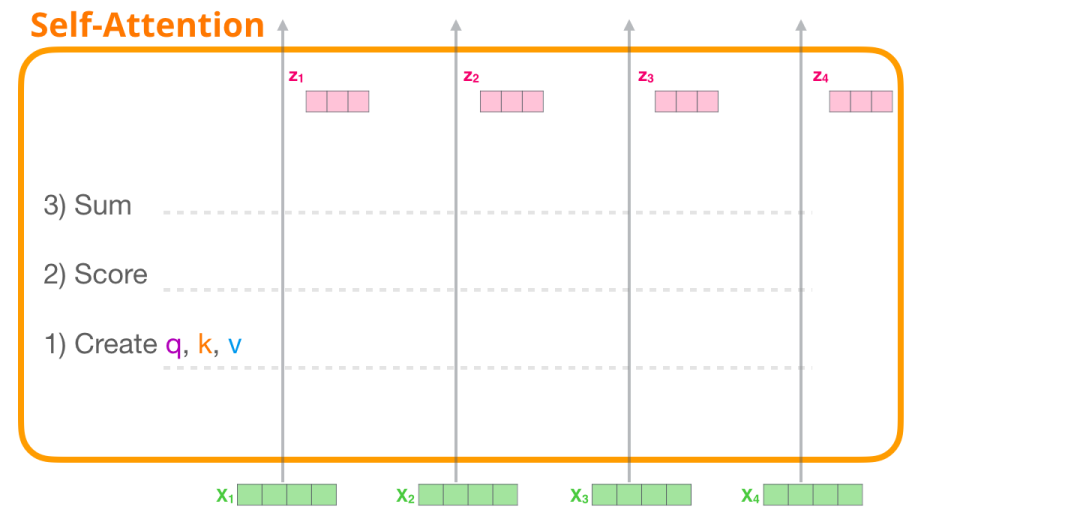
让我们从编码器中自注意力开始。我们来看一个只能一次处理四个标记的Transformer块。
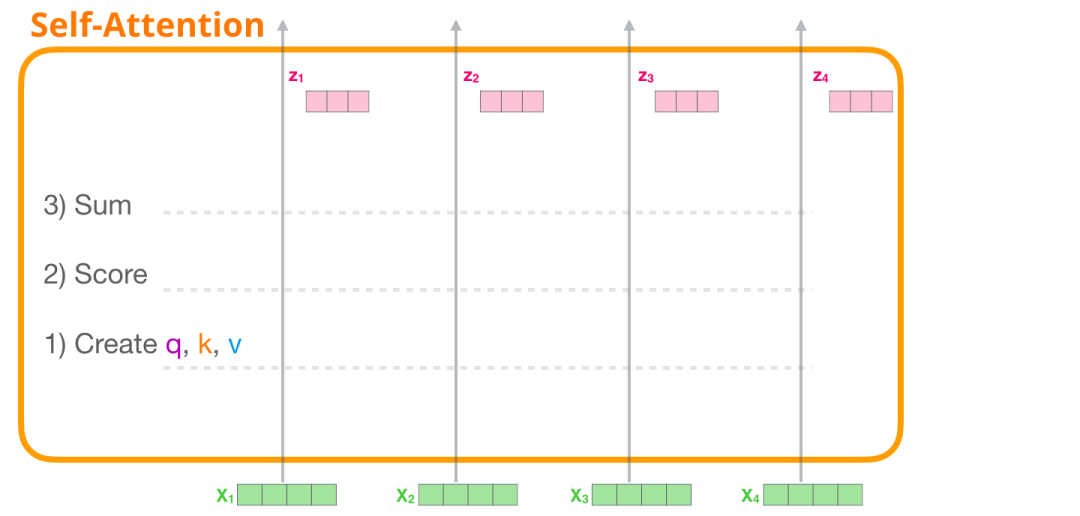
自注意力通过三个主要步骤来应用:
-
为每个路径创建查询(Query)、键(Key)和值(Value)向量。
-
对于每个输入标记,使用其查询向量与所有其他键向量进行打分。
-
将值向量与它们关联的分数相乘后进行求和。
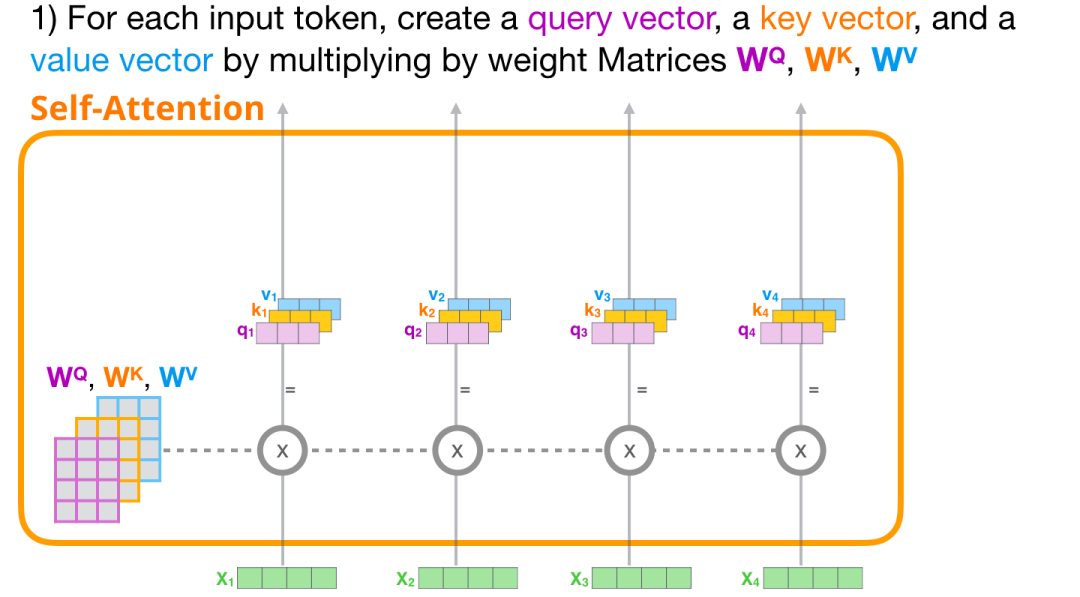
2.1.1 创建q/k/v向量
让我们专注于第一条路径。我们将使用它的查询向量与所有键进行比较,从而为每个键生成一个分数。自注意力的第一步是为每个标记路径计算三个向量(暂时忽略注意力头):
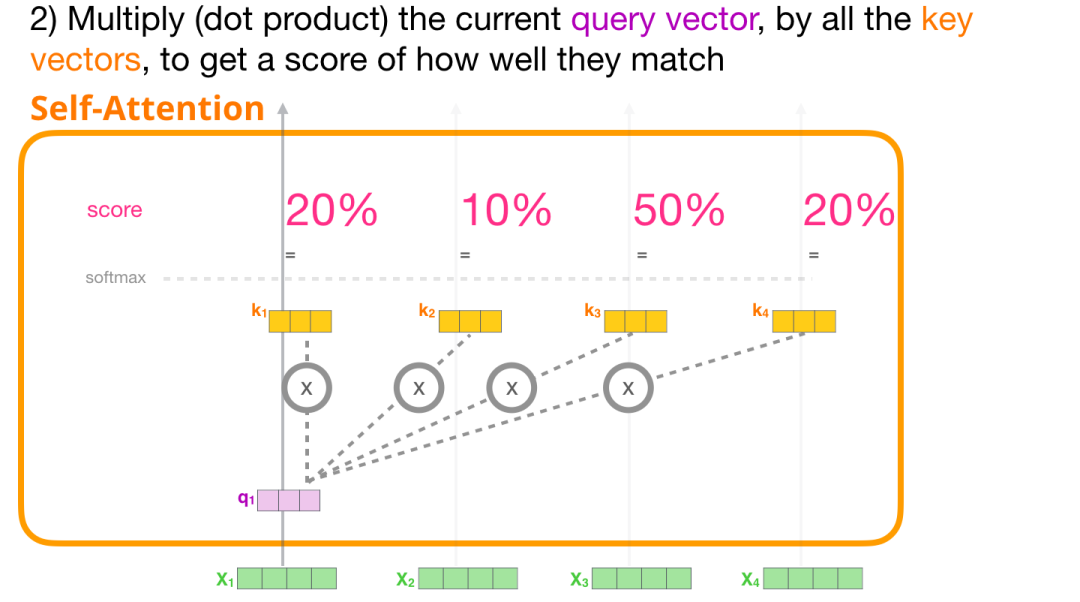
2.1.2计算注意力分数
现在我们有了这些向量,我们只在第2步中使用查询和键向量。由于我们专注于第一个标记,我们将其查询向量与其他所有键向量相乘,从而为这四个标记中的每个标记生成一个分数。
2.1.3加和
现在,我们可以将分数与值向量相乘。具有高分数的值将在我们对它们进行求和后构成结果向量的大部分。
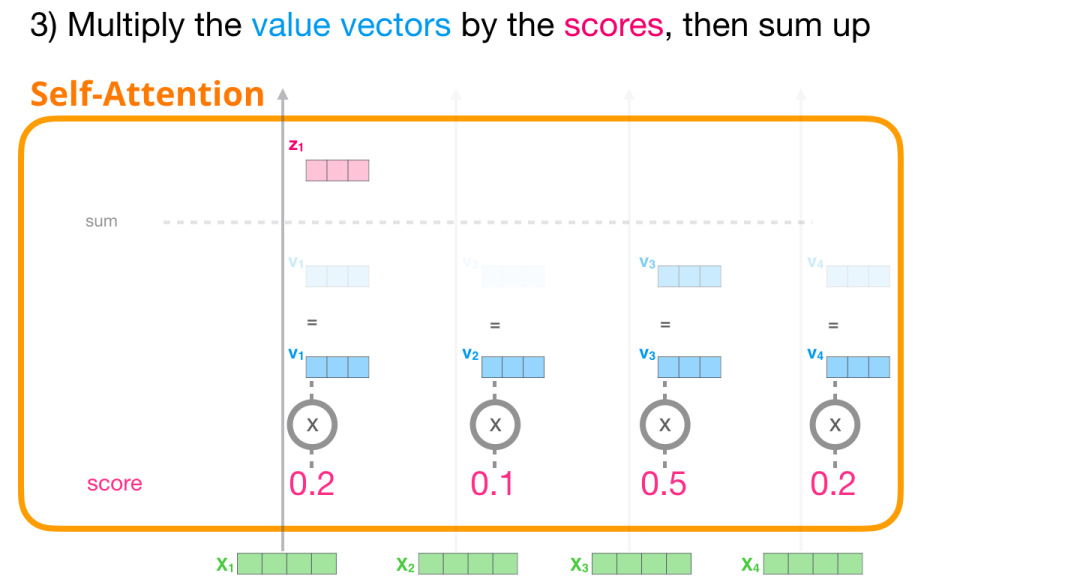
对每个路径执行相同的操作,我们最终会得到一个表示每个标记的向量,其中包含该标记的适当上下文。然后,这些向量被呈现给Transformer块中的下一个子层(即前馈神经网络)。
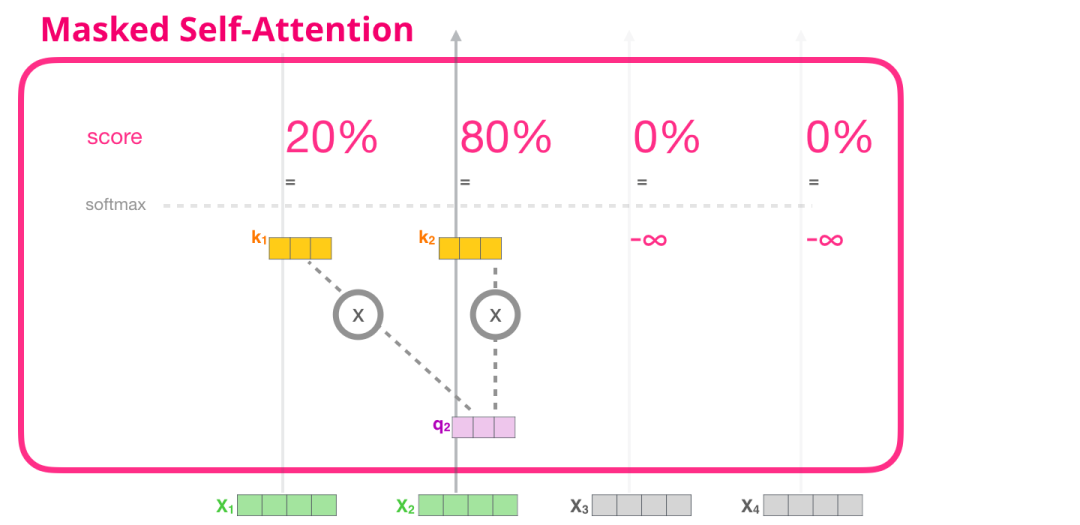
2.2 掩码自注意力
现在我们已经了解了Transformer的自注意力步骤,让我们继续看一下掩码自注意力。掩码自注意力与自注意力相同,只在第2步有所不同。假设模型只有两个输入标记,并且我们正在观察第二个标记。在这种情况下,最后两个标记被掩码。因此,模型在打分步骤中进行干预。它基本上总是将未来的标记的分数设为0,以防止模型窥探未来的单词。
这种掩码通常被实现为一个称为注意力掩码的矩阵。想象一下一个由四个单词组成的序列(例如,“robot must obey orders”)。在语言建模场景中,这个序列被分为四个步骤 - 每个单词一个步骤(暂时假设每个单词是一个标记)。由于这些模型是批处理工作的,我们可以假设这个玩具模型的批处理大小为4,它将整个序列(包括四个步骤)作为一个批次进行处理。

以矩阵形式,我们通过将一个查询矩阵乘以一个键矩阵来计算分数。让我们将其可视化如下,不过在单元格中的位置上,不是单词,而是与该单词关联的查询(或键)向量:
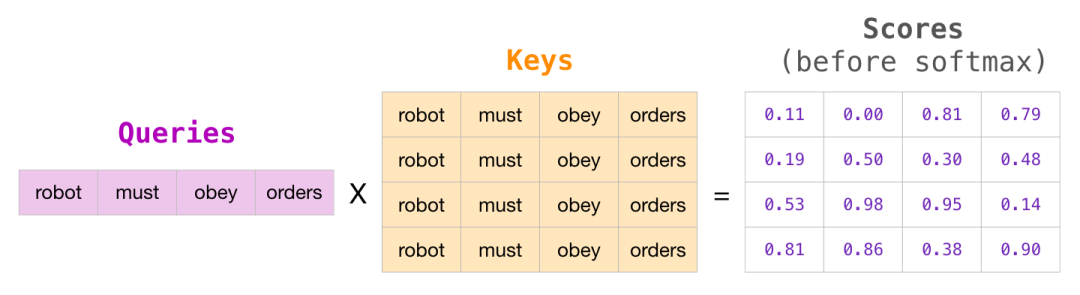
在进行乘法运算后,我们将注意力掩码三角形应用于结果上。它将我们想要掩盖的单元格设置为负无穷或一个非常大的负数(例如,在GPT2中为-10亿)。

接下来,对每一行应用softmax函数,得到我们用于自注意力的实际分数:
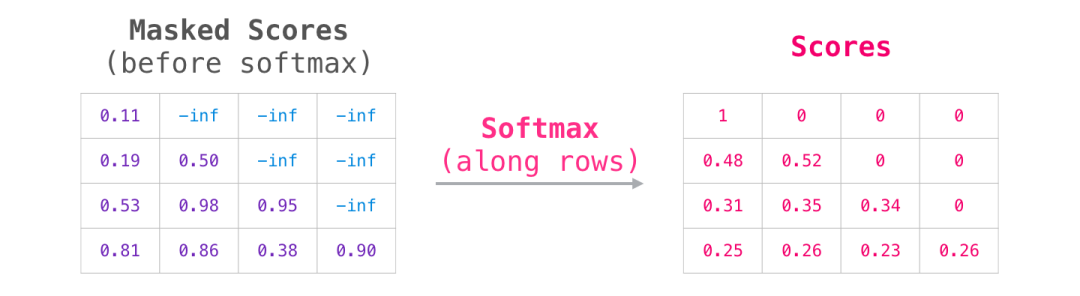
这个分数表的含义如下:
-
当模型处理数据集中的第一个示例(第一行)时,该示例只包含一个单词("robot"),模型的注意力完全集中在这个单词上。
-
当模型处理数据集中的第二个示例(第二行)时,该示例包含单词("robot must"),当模型处理单词"must"时,48%的注意力集中在"robot"上,52%的注意力集中在"must"上。
-
依此类推。
2.3 GPT-2中的掩码自注意力
让我们更详细地了解GPT-2的遮蔽自注意力。
评估时间:一次处理一个token
我们可以让GPT-2的操作方式与掩码自注意力完全相同。但在评估过程中,当我们的模型每次迭代后只添加一个新词时,重新计算已经处理过的标记的早期路径上的自注意力是低效的。
在这种情况下,我们处理第一个标记(暂时忽略<s>)。
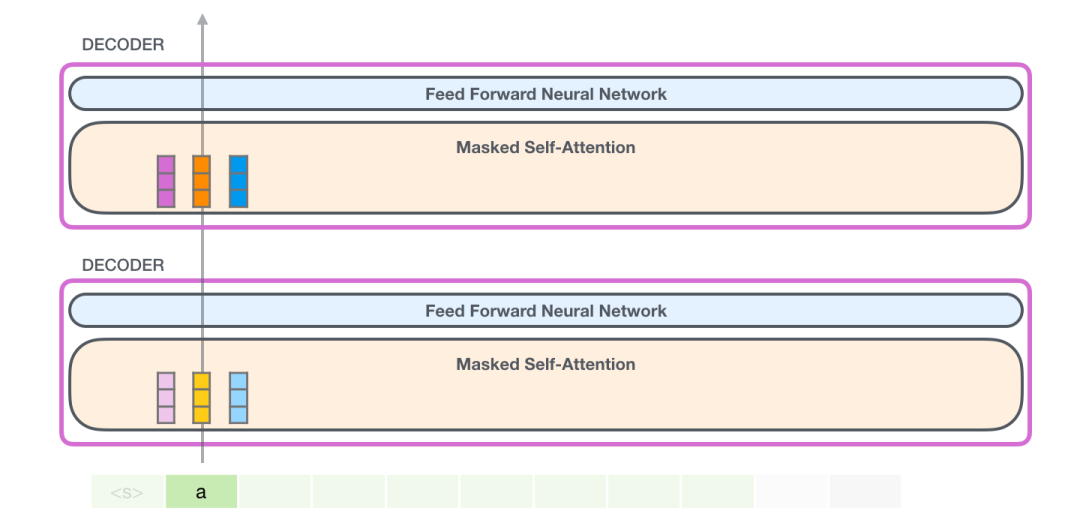
GPT-2保留了一个token的键(key)和值(value)向量。每个自注意力层都保留了对应token的键和值向量:
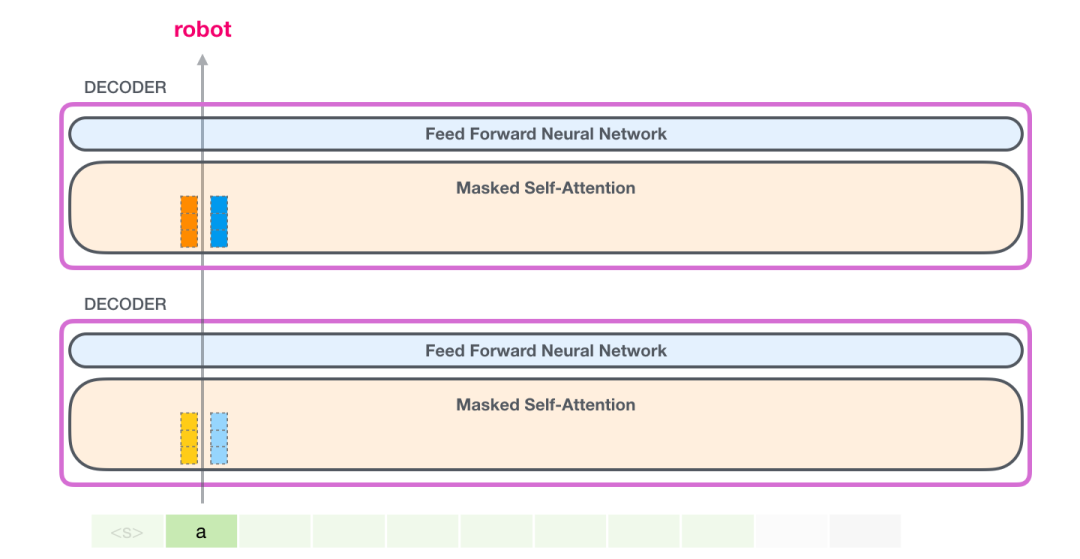
在下一次迭代中,当模型处理单词"robot"时,它不需要为标记"a"生成查询(query)、键(key)和值(value)查询。它只需重用保存在第一次迭代中的那些:
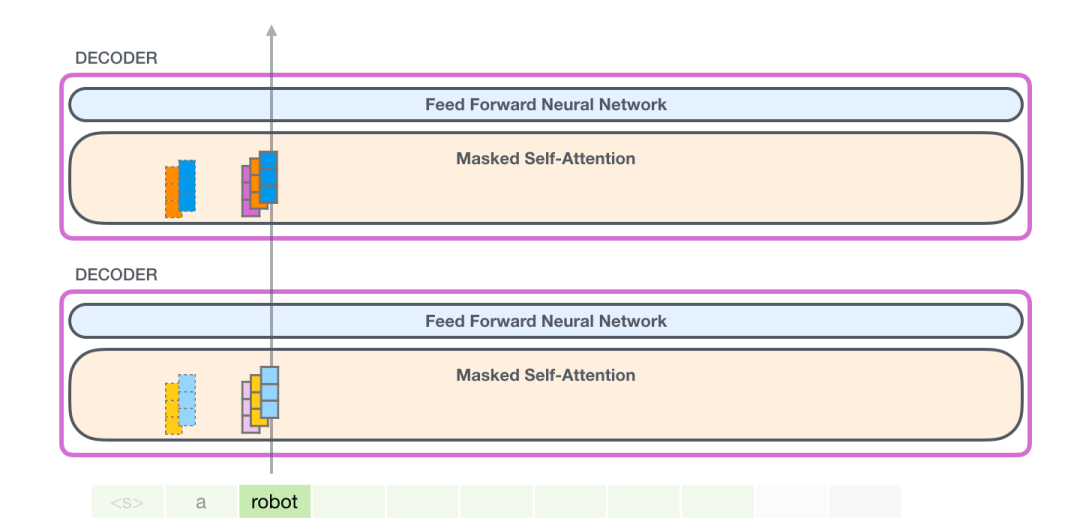
2.3.1 GPT-2自注意力:1- 创建查询(queries)、键(keys)和值(values)
假设模型正在处理单词"it"。如果我们谈论的是最底部注意力层,则该token的输入将是"it"的嵌入(embedding)+位置编码(positional encoding)的第9个位置的编码:

Transformer中的每个块都有它自己的权重(稍后在文章中会详细介绍)。我们首先遇到的是用于创建查询(queries)、键(keys)和值(values)的权重矩阵。
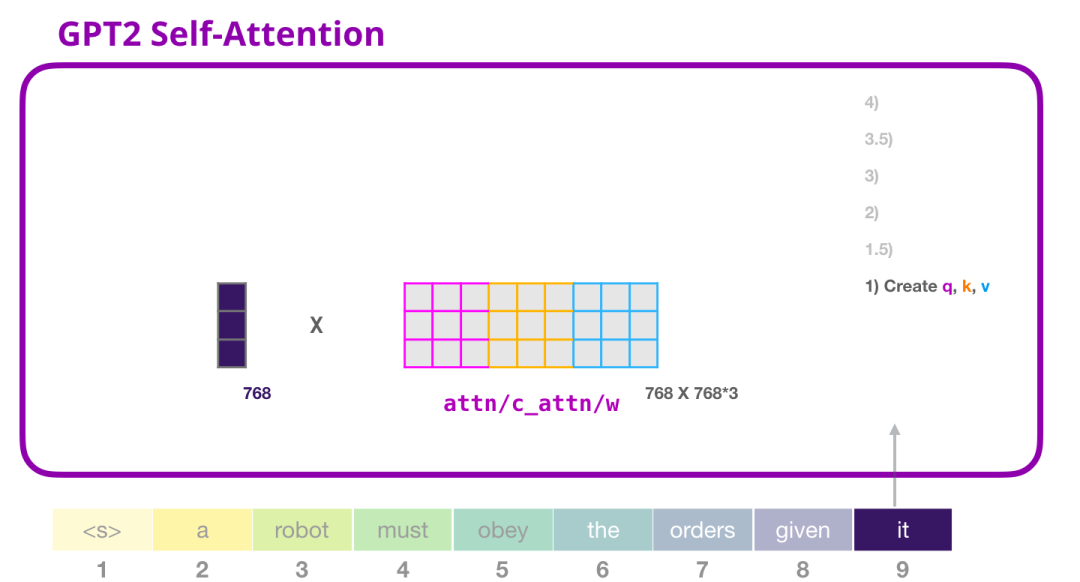
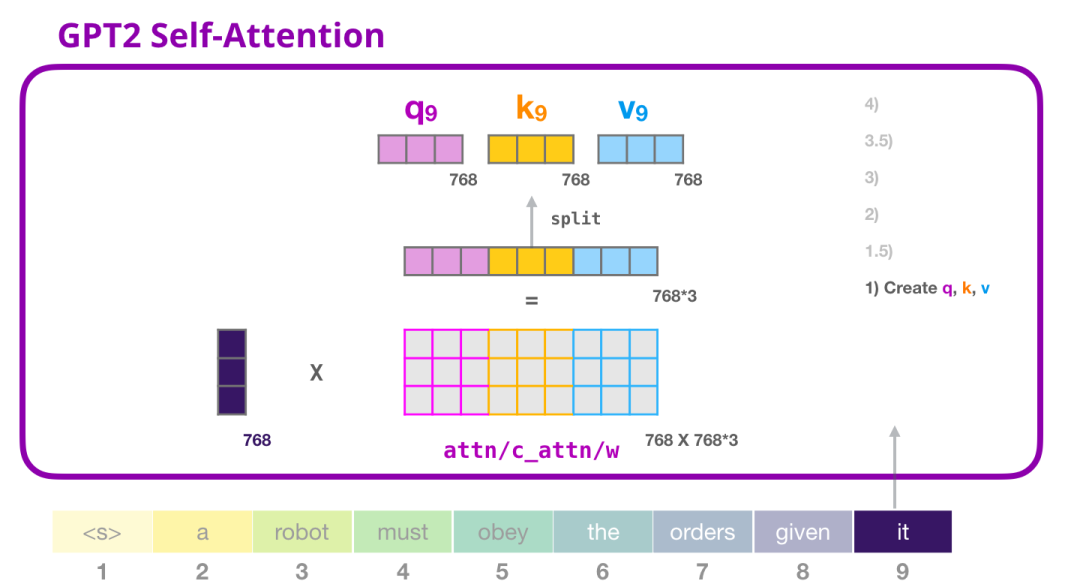
乘法的结果是一个向量,基本上是单词"it"的查询(query)、键(key)和值(value)向量的串联。
2.3.1.1 GPT-2自注意力:分割为注意力头(Splitting into attention heads)
在前面的例子中,我们直接深入研究了自注意力,忽略了“多头”部分。现在我们需要对这个概念进行一些解释。自注意力在Q、K、V向量的不同部分上进行多次操作。“分割”注意力头只是将长向量重新reshape为一个矩阵。小型GPT2具有12个注意力头,因此这将是reshape矩阵的第一个维度:
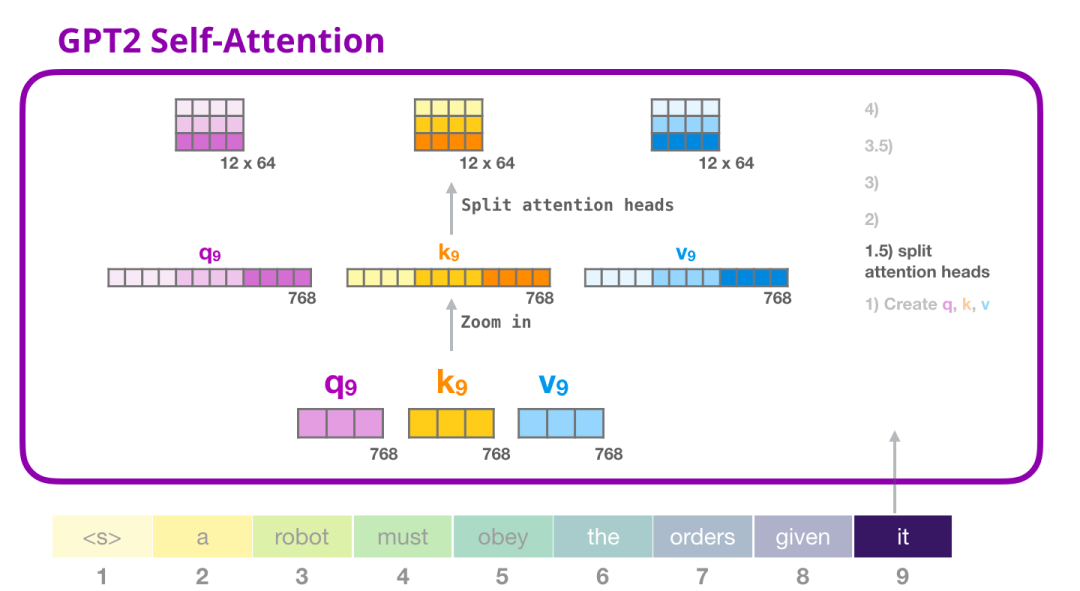
在之前的例子中,我们看了一个注意力头内部发生的情况。想象一下多个注意力头的一种方式是这样的(如果我们只想可视化其中三个注意力头):
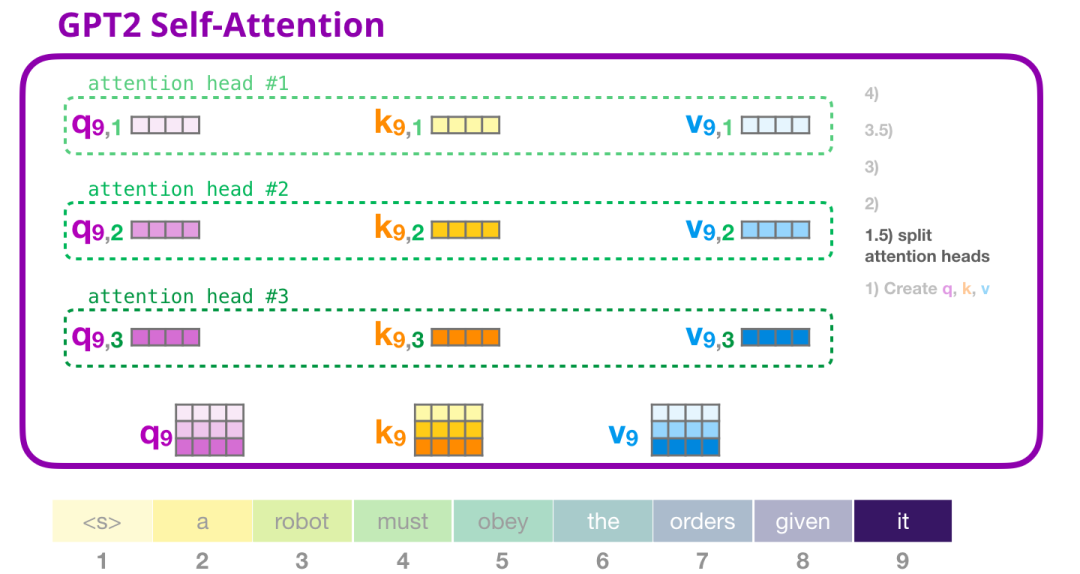
2.3.2 GPT-2自注意力:2- 打分(Scoring)
现在我们可以进行打分了 - 需要注意的是,我们只看一个注意力头(其他的注意力头执行类似的操作):
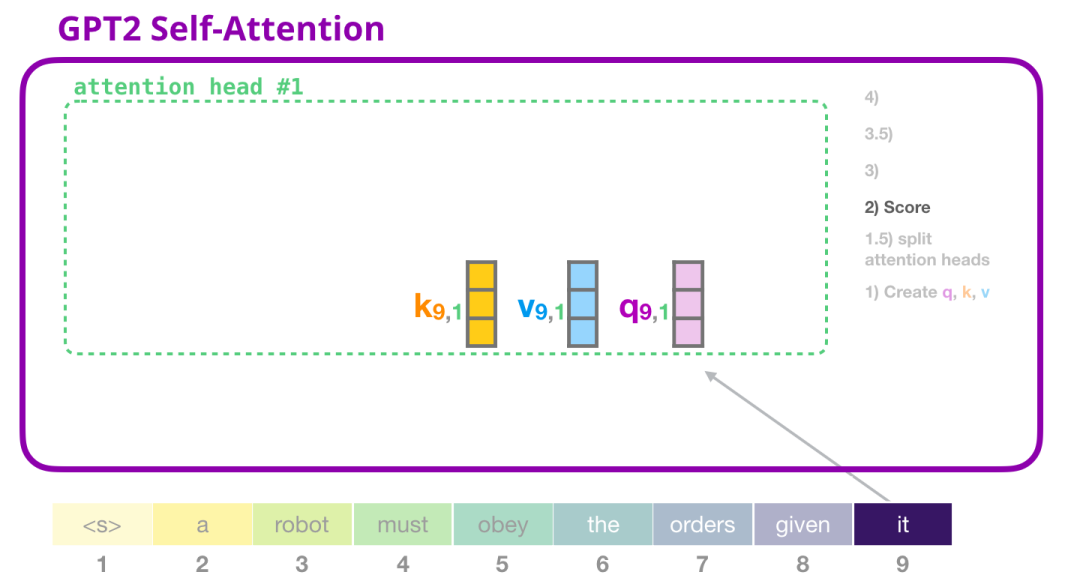
现在,该标记可以与其他标记的所有键进行打分(这些键是在先前的迭代中在注意力头#1中计算的):
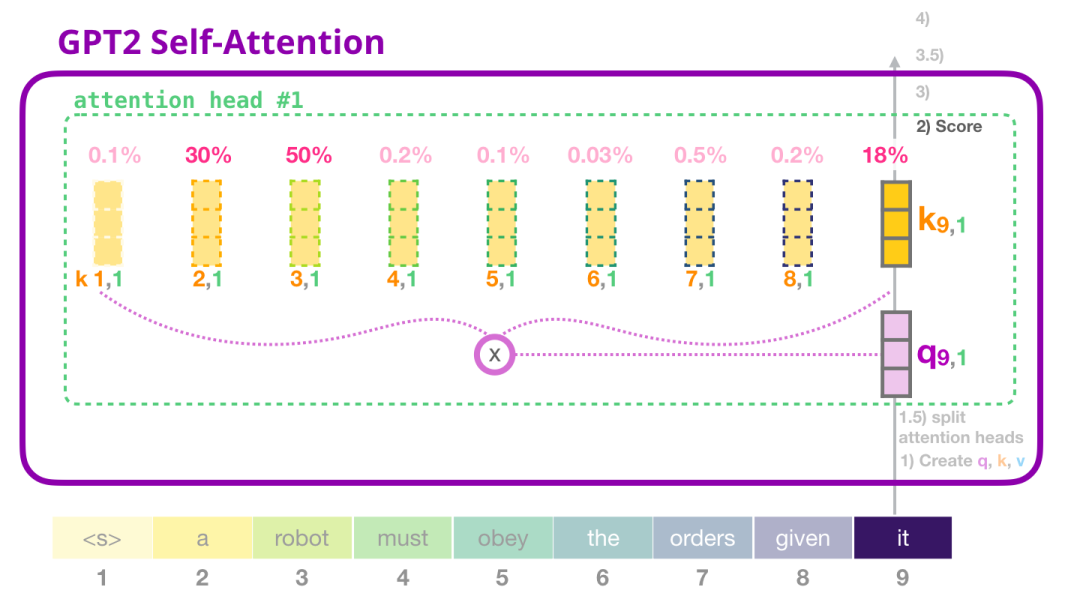
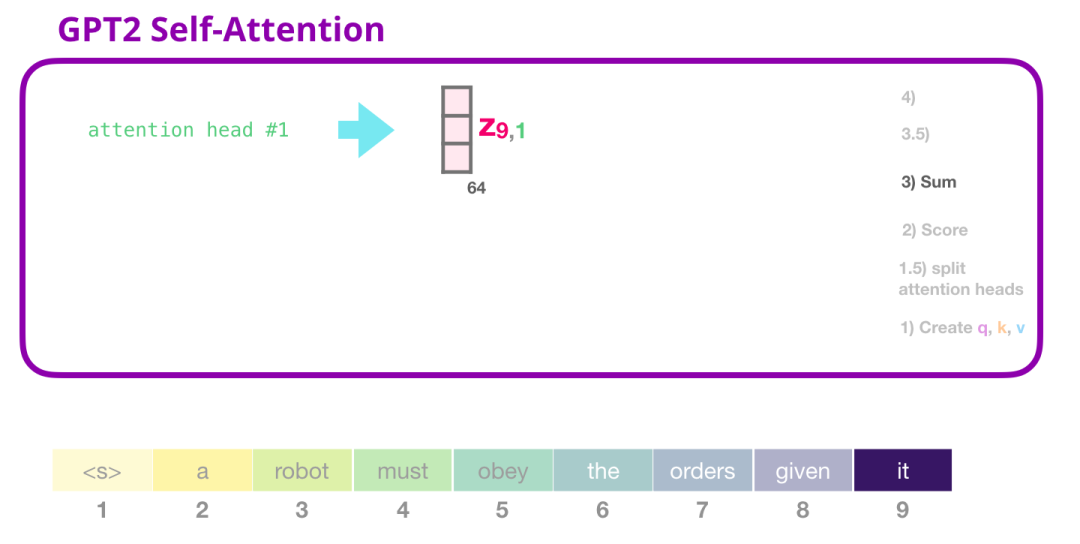
2.3.3 GPT-2自注意力:求和(Sum)
正如我们之前所看到的,现在我们将每个值与其分数相乘,然后将它们相加,得到注意力头#1的自注意力结果:
2.3.3.1 GPT-2自注意力:合并注意力头
我们处理不同注意力头的方式是首先将它们连接成一个向量:
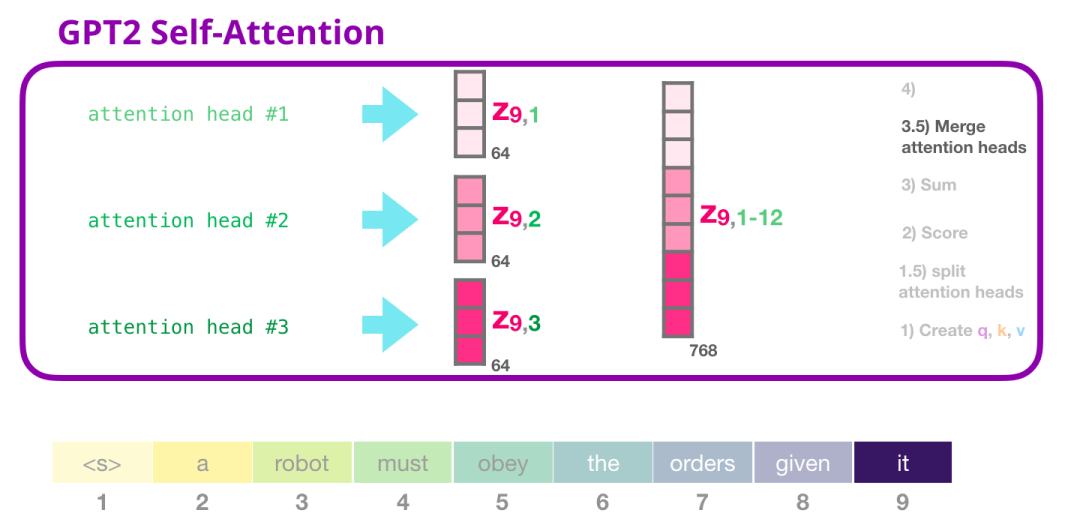
但是这个向量还没有准备好被发送到下一个子层。我们首先需要将这个隐藏状态转化为一个均匀的表示。
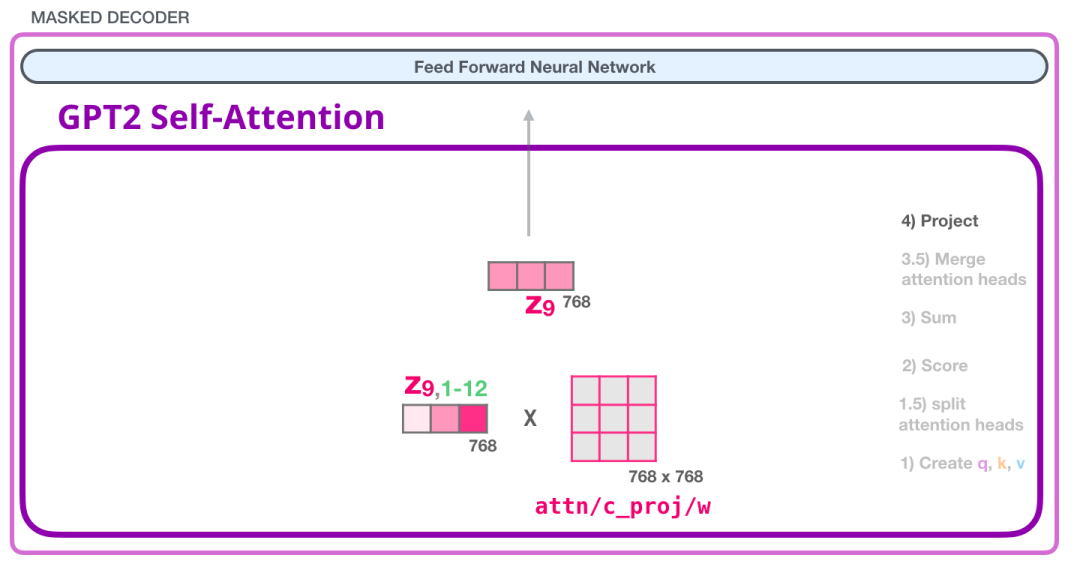
2.3.4 GPT-2自注意力:投影(Projecting)
我们将让模型学习如何最好地将连接的自注意力结果映射到前馈神经网络可以处理的向量。接下来,我们使用第二个大型权重矩阵将注意力头的结果投影到自注意力子层的输出向量中:
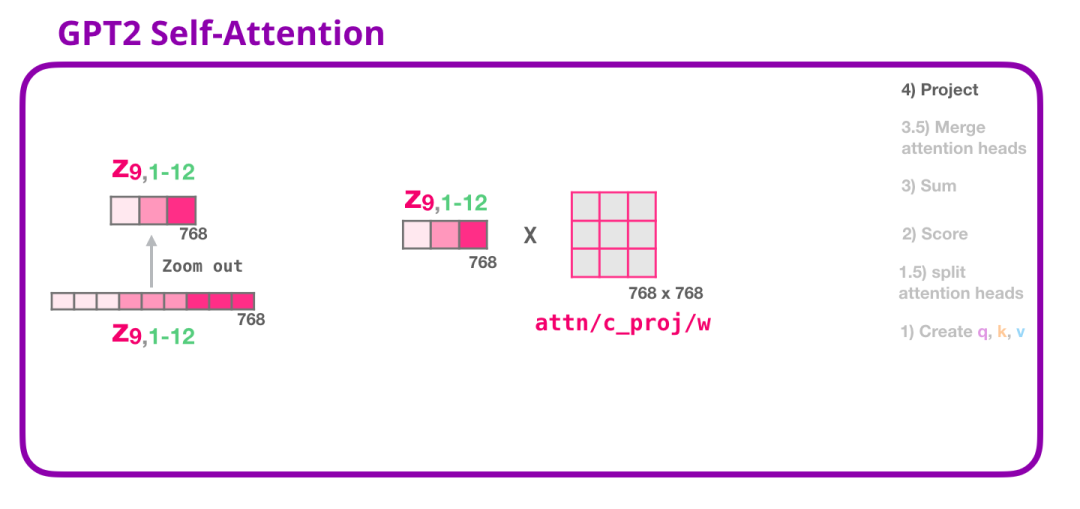
有了这个,我们就产生了可以发送到下一层的向量:
2.3.5 GPT-2全连接神经网络:第一层
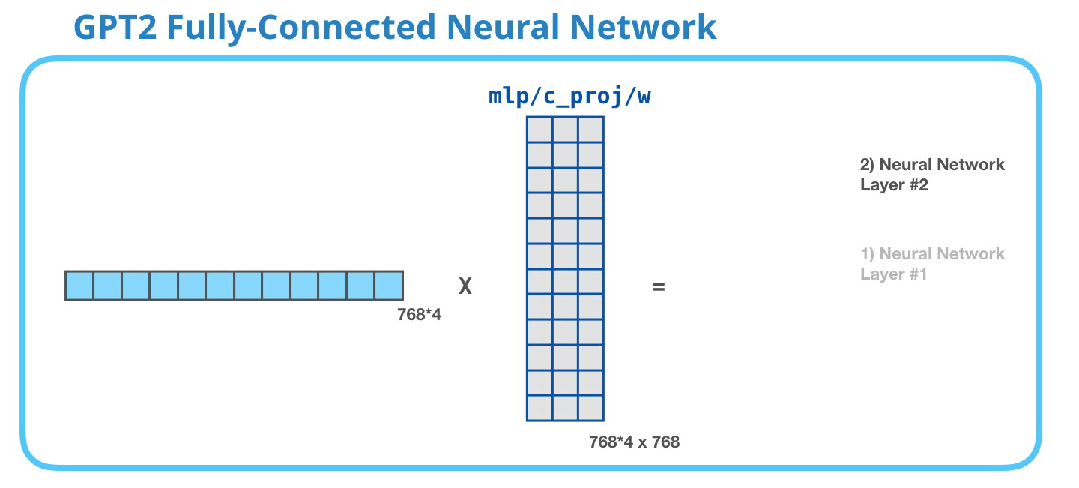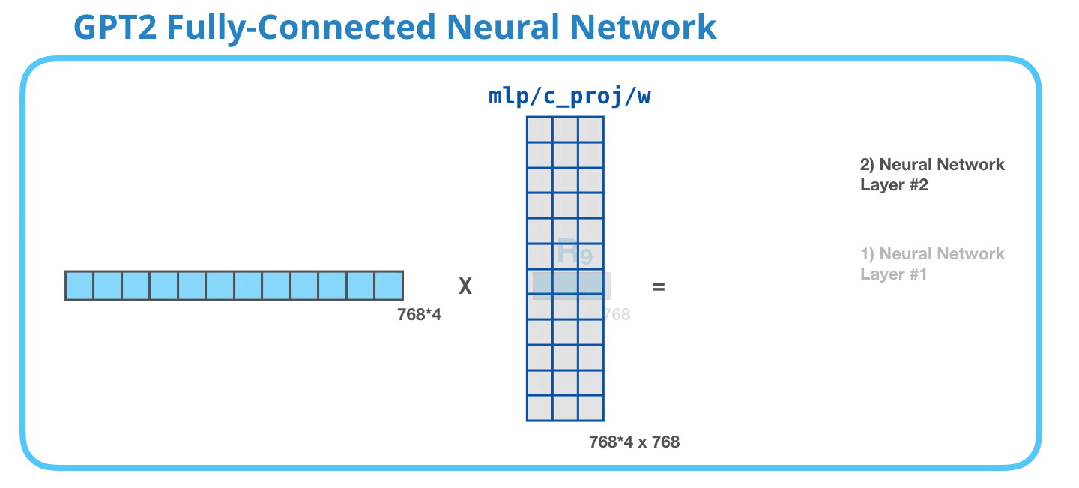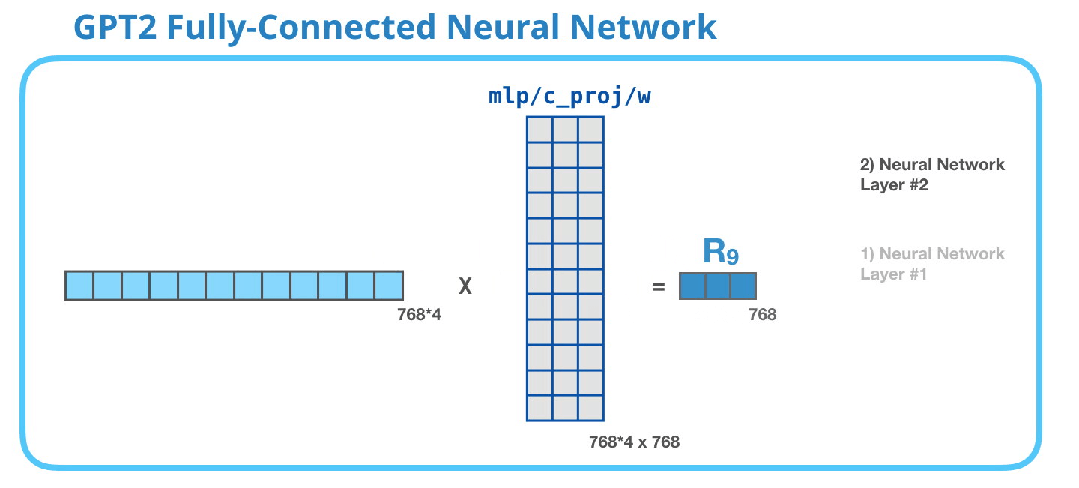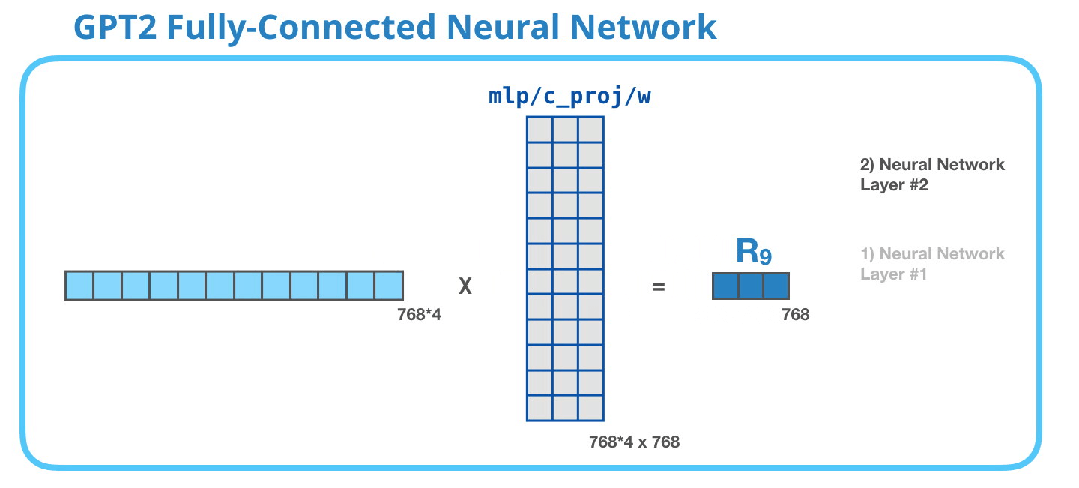
全连接神经网络是在自注意力层将适当的上下文包含在其表示中之后。它由两个层组成。第一层是模型大小的四倍(由于GPT2 small的大小为768,因此该网络将有768 * 4 = 3072个单元)。为什么是四倍?这只是原始transformer中所采用的大小(模型维度为512,该模型的第一层为2048)。这似乎为transformer模型提供了足够的表征能力来处理目前所面临的任务。

GPT-2全连接神经网络:第二层 - 投影到模型维度
第二层将第一层的结果投影回模型维度(对于小型GPT2为768)。这个乘法的结果就是这个transformer块对这个token的处理结果。
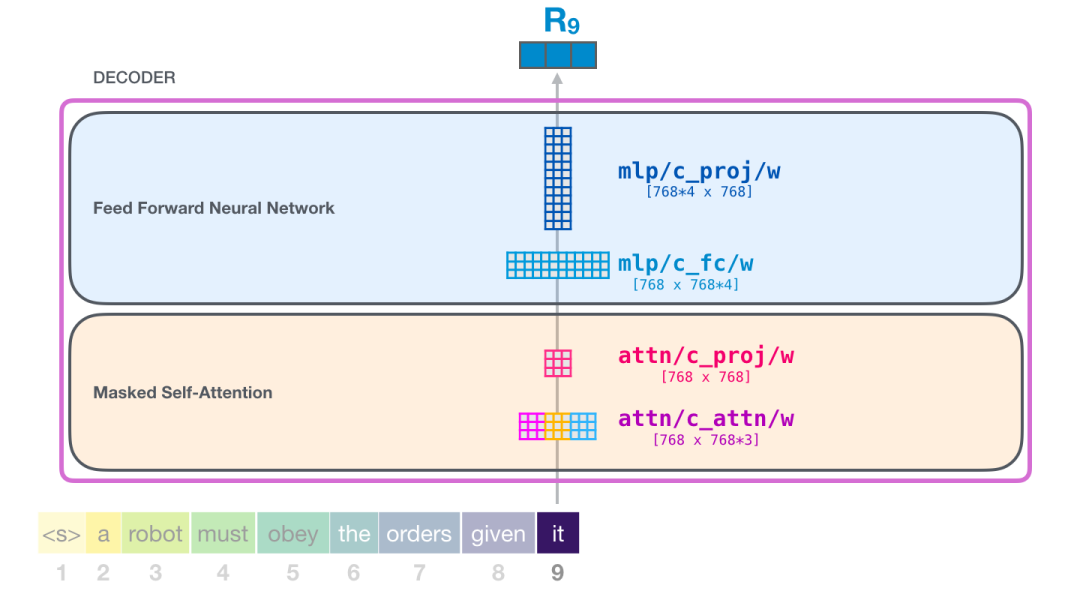
您已经成功了!
这就是我们将要深入研究的transformer块的最详细版本!现在,您基本上已经对transformer语言模型内部发生的事情有了绝大部分的了解。回顾一下,我们的输入向量会遇到这些权重矩阵:
每个block块都有自己的这些权重集合。另一方面,模型只有一个标记嵌入矩阵和一个位置编码矩阵:
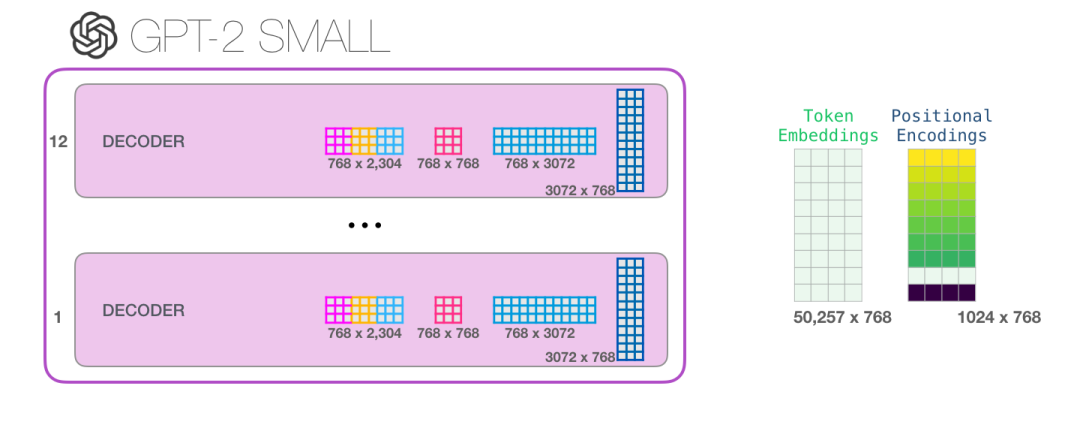
若您想要查看模型的所有参数,我已将它们汇总在此:
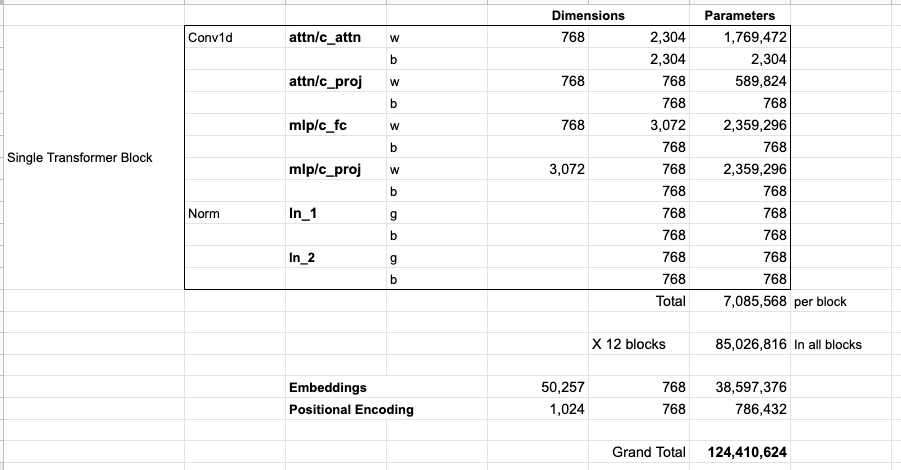
由于某种原因,它们的参数总数为124M,而不是117M。我不确定原因是什么,但这是在发布的代码中似乎存在的参数数量(如果我有错,请纠正我)。
3 Beyond Language Modeling
只有decoder的transformer不断显示出超越语言模型(LM)的前景。它在许多应用场景中都取得了很好的效果,也可以简单图解一下。接下来我们就介绍几个应用场景来结束我们这篇文章。
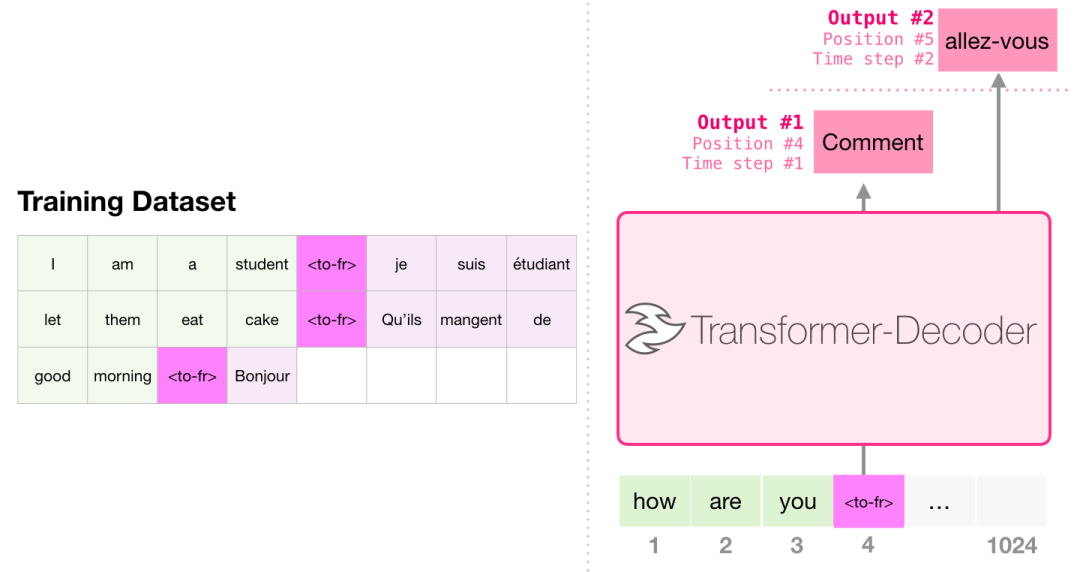
3.1 机器翻译 machine translation
翻译任务不需要编码器,只用解码器就可以进行翻译了。
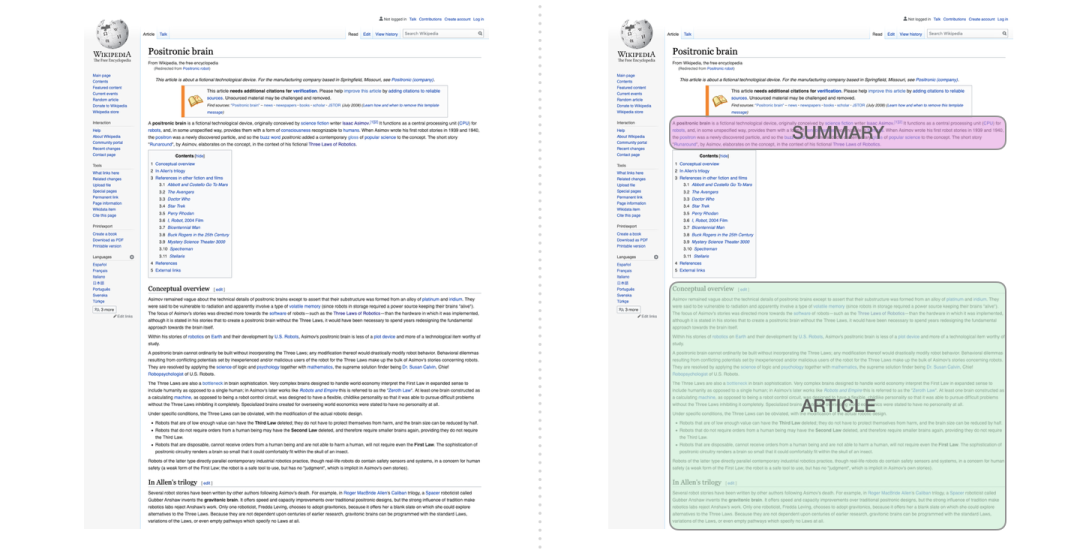
3.2 摘要 Summarization
这是只有编码器的transformer训练的第一个任务,训练它阅读维基百科的文章(不包括目录前边的开头部分),前边的开头部分作为训练数据的标签。
GPT-2就是使用wikipedia的文章进行训练的,因此训练好的模型可以直接拿来做摘要。
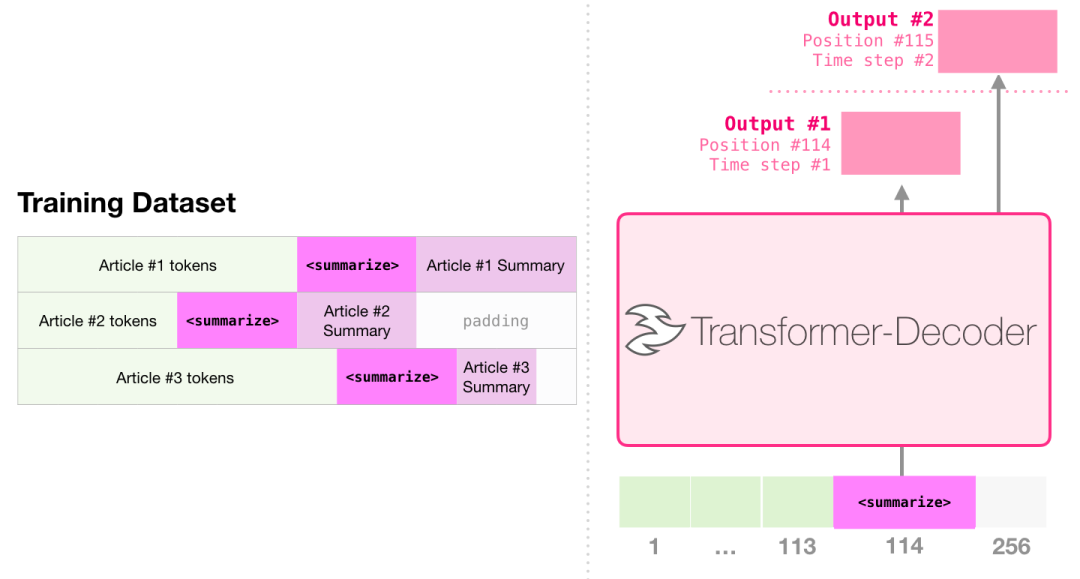
3.3 迁移学习 Transfer Learning
在《Sample Efficient Text Summarization Using a Single Pre-Trained Transformer》,只有解码器的transformer结构首先在语言模型上进行预训练,然后微调做摘要任务,结果证明,在有限的数据设置中,它比预先训练的编码器-解码器变压器取得更好的结果。
GPT-2的论文原文也展示了在语言建模上对模型进行预训练后做摘要任务的结果。
3.4 音乐生成 Music Generation
音乐Transformer使用的是只有解码器的Transformer结构来生成具有表现力的音乐。“音乐建模”就像语言建模一样,让模型以一种无监督的方式学习音乐,然后让它对输出进行采样(我们之前称之为“rambling”)。
你可能会好奇音乐是如何表示的。语言建模可以通过字(characters)、词(words)或token作为某个单词(word)的表示,并将其转化为向量表示。在音乐演奏中(比如钢琴),我们除了要表示音符,还要表示速度——衡量钢琴键按得有多用力。
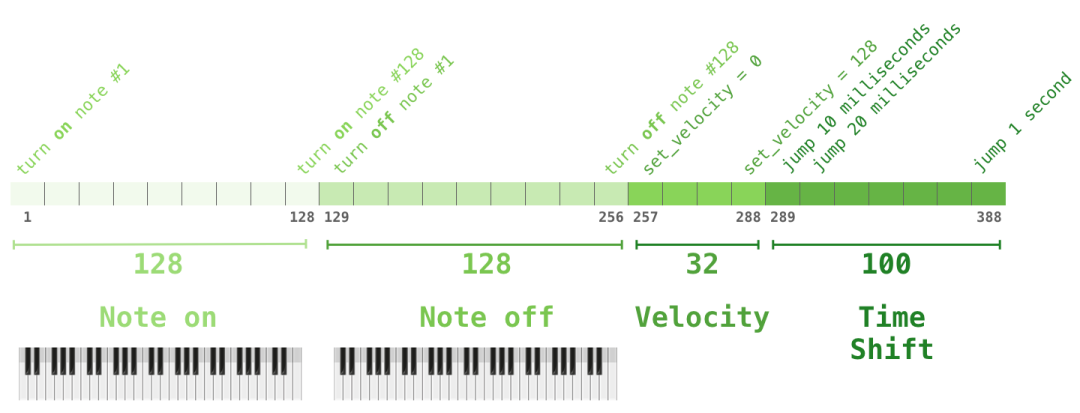
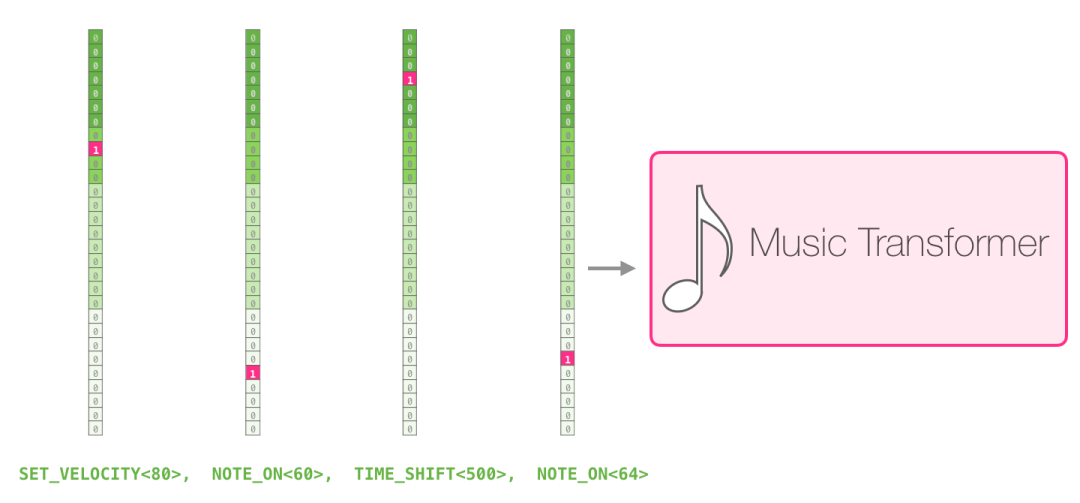
一个表演只是一组one-hot向量而已。一个mini文件可以转化为下图的格式。
论文中输入序列的示例如下图:

这个输入序列的 one-hot 向量表示如下:
我很喜欢这篇论文中的音乐transformer的自注意力图像。在这里我添加了一些注释:
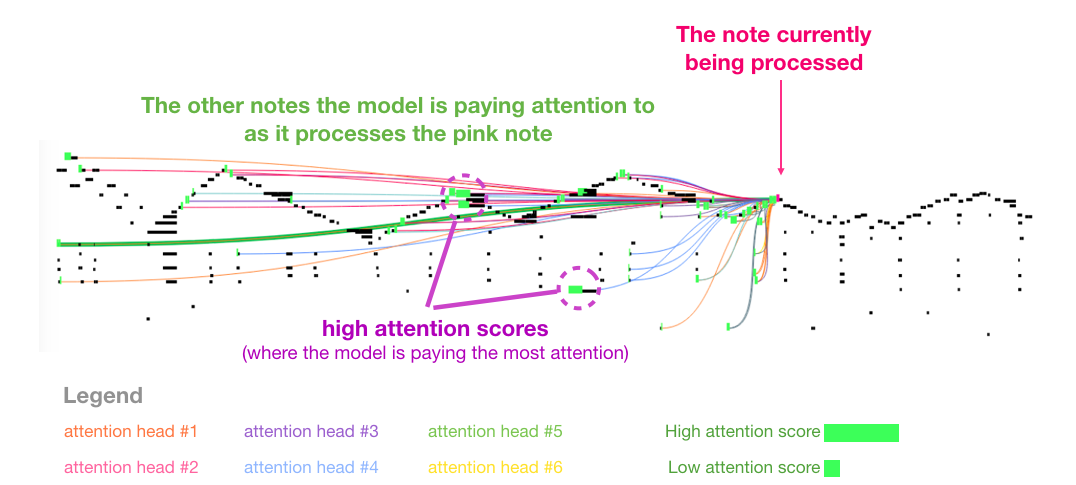
这个音乐中有明显的三角形循环。query在最后一个三角形的峰值上,它会注意到之前所有的三角形的高音峰值(包括乐曲最开始的峰值)。图中的线表示query都关注到了哪些位置,荧光绿色的条条代表的是attention分数,绿条条越长代表在这个位置投入的注意力越多。
如果你不懂图中黑色条条块块的音符表示方法可以看一下这个视频:d小调托卡塔与赋格
4 总结
GPT-2到这里就介绍完了。本文对GPT-2以及它的父模型(只有解码器的Transformer结构)的探索。我希望你在读完这篇文章后,对自关注力机制有了更深入的理解,并且对Transformer的工作机制有了更多的了解。
参考:
[1]https://blog.csdn.net/qq_36667170/article/details/125529598
[2]终于有人将大模型可视化了