Lecture1: Basic Concepts in Reinforcement Learning
MDP(Markov Decision Process)
Key Elements of MDP
Set
State: The set of states S \mathcal{S} S(状态 S \mathcal{S} S的集合)
Action: the set of actions A ( s ) \mathcal{A}(s) A(s) is associated for state s ∈ S s \in \mathcal{S} s∈S(对应于状态 s ∈ S s \in \mathcal{S} s∈S 的行为集合 A ( s ) \mathcal{A(s)} A(s))
Reward: the set of rewards R ( s , a ) \mathcal{R}(s, a) R(s,a)(对应于某一状态 s ∈ S s \in \mathcal{S} s∈S 和在该状态的某一行为 a ∈ A ( s ) a \in \mathcal{A}(s) a∈A(s)的奖励分数,是一个实数)
Probability distribution
State transition probability: at state
s
s
s ,taking action
a
a
a, the probability to transit to state
s
′
s'
s′ is (状态转移概率,在状态
s
s
s,行为
a
a
a,转移到状态
s
′
s'
s′的概率)
p
(
s
′
∣
s
,
a
)
p(s' | s, a)
p(s′∣s,a)
Reward probability: at state
s
s
s, taking action
a
a
a, the probability to get reward
r
r
r is (在状态
s
s
s,行为
a
a
a,得到的奖励分数
r
r
r)
p
(
r
∣
s
,
a
)
p(r | s, a)
p(r∣s,a)
Policy
Policy: at state
s
s
s, the probability to choose action
a
a
a is(在状态
s
∈
S
s \in \mathcal{S}
s∈S,选择状态
a
∈
A
(
s
)
a \in \mathcal{A}(s)
a∈A(s)的概率)
π
(
a
∣
s
)
\pi (a | s)
π(a∣s)
Markov Property
Markov property: memoryless property (无记忆性;无后效性)
p
(
s
t
+
1
∣
a
t
+
1
,
s
t
,
.
.
.
,
a
1
,
s
0
)
=
p
(
s
t
+
1
∣
a
t
+
1
,
s
t
)
p
(
r
t
+
1
∣
a
t
+
1
,
s
t
,
.
.
.
,
a
1
,
s
0
)
=
p
(
r
t
+
1
∣
a
t
+
1
,
s
t
)
p(s_{t + 1} | a_{t + 1}, s_t, ..., a_1, s_0) = p(s_{t + 1} | a_{t + 1}, s_t) \\ p(r_{t + 1} | a_{t + 1}, s_t, ..., a_1, s_0) = p(r_{t + 1} | a_{t + 1}, s_t)
p(st+1∣at+1,st,...,a1,s0)=p(st+1∣at+1,st)p(rt+1∣at+1,st,...,a1,s0)=p(rt+1∣at+1,st)
Grid-World Example
以grid-world为例对上面例子进行解释

Key Elements
state: 每个表格所在的位置即为state, 因此其有9个state s 1 , s 2 , . . . , s 9 s_1, s_2, ..., s_9 s1,s2,...,s9。
每个表格所在的位置即为state, 因此其有9个state s 1 , s 2 , . . . , s 9 s_1, s_2, ..., s_9 s1,s2,...,s9。
state space: S = { s i } i = 1 9 \mathcal{S} = \{ s_i \}^9_{i=1} S={si}i=19
action:对于每一个state,有五个可能的action
- a 1 a_1 a1: move upwards
- a 2 a_2 a2: move rightwards
- a 3 a_3 a3: move downwards
- a 4 a_4 a4: move leftwards
- a 5 a_5 a5: stay unchanged
Action space of a state:特定state其所有可能的action的集合 A ( s ) = { a i } i = 1 5 \mathcal{A}(s)= \{ a_i \}^5_{i=1} A(s)={ai}i=15
state transition
当采取action时,agent可能会从一个state转移到另一个state。例如 s 1 ⟶ a 2 s 1 s_1 \stackrel{a_2}{\longrightarrow}s_1 s1⟶a2s1
-
tubular representation: 使用表格表示state transition
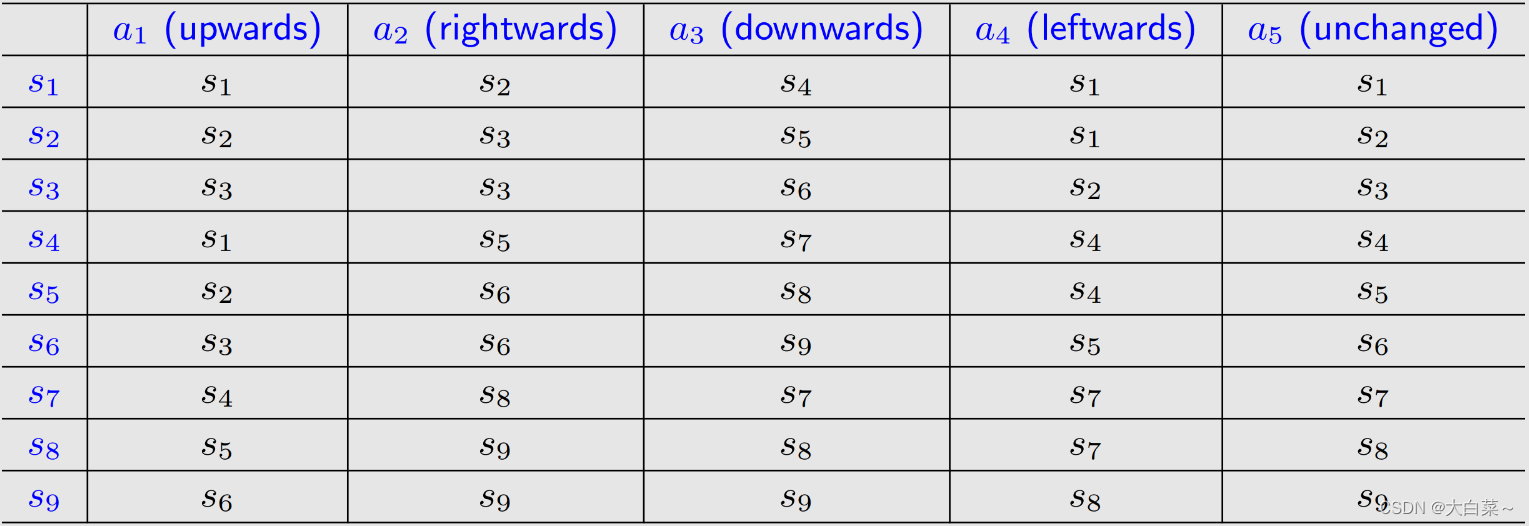
-
state transition probability: 使用概率描述state transition
-
intuition: 在state s 1 s_1 s1,如果选择action a 2 a_2 a2,下一个state是 s 2 s_2 s2
-
math:
p ( s 2 ∣ s 1 , a 2 ) = 1 p ( s i ∣ s 1 , a 2 ) = 0 ∀ ≠ 2 \begin{align*} &p(s_2 | s_1, a_2) = 1\\ &p(s_i | s_1, a_2) = 0 \;\;\; \forall \ne 2 \end{align*} p(s2∣s1,a2)=1p(si∣s1,a2)=0∀=2
-
Policy
告诉agent在某个state下要采取什么action。
直观表示如下图所示:

基于以上policy,针对不同的start area和end area,最优路径如下:

mathematical representation: 使用条件概率表示
π
(
a
1
∣
s
1
)
=
0
π
(
a
2
∣
s
1
)
=
1
π
(
a
3
∣
s
1
)
=
0
π
(
a
4
∣
s
1
)
=
0
π
(
a
5
∣
s
1
)
=
0
\pi(a_1 | s_1) = 0\\ \pi(a_2 | s_1) = 1 \\ \pi(a_3 | s_1) = 0 \\ \pi(a_4 | s_1) = 0 \\ \pi(a_5 | s_1) = 0 \\
π(a1∣s1)=0π(a2∣s1)=1π(a3∣s1)=0π(a4∣s1)=0π(a5∣s1)=0
其上为确定概率,也有随机概率:

π
(
a
1
∣
s
1
)
=
0
π
(
a
2
∣
s
1
)
=
0.5
π
(
a
3
∣
s
1
)
=
0.5
π
(
a
4
∣
s
1
)
=
0
π
(
a
5
∣
s
1
)
=
0
\begin{align*} &\pi(a_1 | s_1) = 0\\ &\pi(a_2 | s_1) = 0.5 \\ &\pi(a_3 | s_1) = 0.5 \\ &\pi(a_4 | s_1) = 0 \\ &\pi(a_5 | s_1) = 0 \\ \end{align*}
π(a1∣s1)=0π(a2∣s1)=0.5π(a3∣s1)=0.5π(a4∣s1)=0π(a5∣s1)=0
tabular representation: 使用表格表示

Reward
在采取某个action后得到的实数
- 正数代表鼓励去采取这种action
- 复数代表惩罚采取这种action
- 零代表不鼓励不惩罚
对于grid-world样例,reward可以设计成以下四种:
- 如果agent尝试逃出表格边界: r r o u n d = − 1 r_{round}=-1 rround=−1
- 如果agent尝试进入禁区(蓝色方块): r f o r b i d = − 1 r_{forbid}=-1 rforbid=−1
- 如果agent到达目标单元: r t a r g e t = 1 r_{target}=1 rtarget=1
- 其他情况: r = 0 r=0 r=0
reward可以理解为human-machine interface,通过它我们可以引导agent按照我们的期望行事。
-
tabular representation:
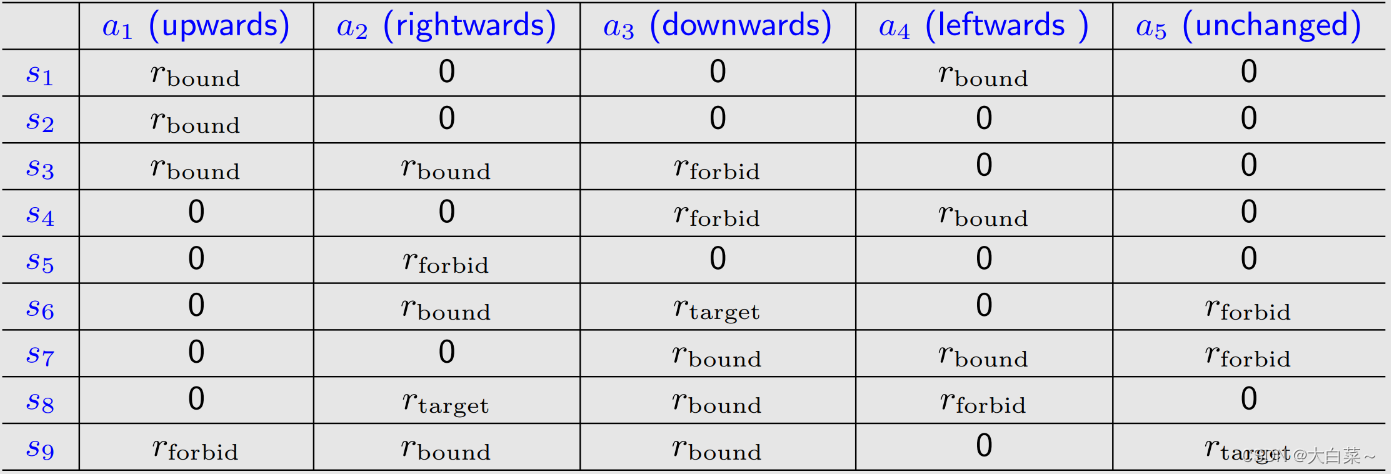
-
Mathematical description:
p ( r = − 1 ∣ s 1 , a 1 ) = 1 p ( r ≠ − 1 ∣ s 1 , a 1 ) = 0 p(r=-1 | s_1, a_1) = 1 \\ p(r \ne -1 | s_1, a_1) = 0 p(r=−1∣s1,a1)=1p(r=−1∣s1,a1)=0
Trajectory and Return
如下图:

trajectory 是一个state-action-reward 链:
s
1
→
r
=
0
a
2
s
2
→
r
=
0
a
3
s
5
→
r
=
0
a
3
s
8
→
r
=
1
a
2
s
9
s_1 \xrightarrow[r=0]{a_2} s_2\xrightarrow[r=0]{a_3} s_5\xrightarrow[r=0]{a_3} s_8\xrightarrow[r=1]{a_2} s_9
s1a2r=0s2a3r=0s5a3r=0s8a2r=1s9
return是沿该轨迹收集的所有奖励的总和:
return
=
0
+
0
+
0
+
1
=
1
\text{return}=0 + 0 + 0 + 1 = 1
return=0+0+0+1=1
Discounted return
对于下图trajectory :

其可以定义为:
s
1
→
a
2
s
2
→
a
3
s
5
→
a
3
s
8
→
a
2
s
9
→
a
5
s
9
→
a
5
s
9
.
.
.
s_1 \xrightarrow[]{a_2} s_2 \xrightarrow[]{a_3} s_5 \xrightarrow[]{a_3} s_8 \xrightarrow[]{a_2} s_9 \xrightarrow[]{a_5} s_9 \xrightarrow[]{a_5} s_9 ...
s1a2s2a3s5a3s8a2s9a5s9a5s9...
return为:
return
=
0
+
0
+
0
+
1
+
1
+
1
+
.
.
.
=
∞
\text{return} = 0 + 0 + 0 + 1 + 1 + 1 + ... = \infty
return=0+0+0+1+1+1+...=∞
需要引入discount rate
γ
∈
[
0
,
1
)
\gamma \in [0, 1)
γ∈[0,1)
discount return:
discount return
=
0
+
γ
0
+
γ
2
0
+
γ
3
1
+
γ
4
1
+
.
.
.
=
γ
3
(
1
+
γ
+
γ
2
+
.
.
.
)
=
γ
3
1
1
−
γ
\begin{align*} \text{discount return} &= 0 + \gamma0 + \gamma^20 + \gamma^31 + \gamma^41 + ... \\ & = \gamma^3(1 + \gamma + \gamma^2 + ...)\\ &=\gamma^3 \frac{1}{1 - \gamma} \end{align*}
discount return=0+γ0+γ20+γ31+γ41+...=γ3(1+γ+γ2+...)=γ31−γ1
- 如果 γ \gamma γ接近于0,则discounted return的值主要由近期获得的reward决定。
- 如果 γ \gamma γ接近于1,则discounted return的值主要由远期获得的reward决定。
Episode
当遵循policy与环境交互时,agent可能会停在某些terminal states。 由此产生的轨迹称为一个episode(或一次trail)。

如上图,episode为:
s
1
→
r
=
0
a
2
s
2
→
r
=
0
a
3
s
5
→
r
=
0
a
3
s
8
→
r
=
1
a
2
s
9
s_1 \xrightarrow[r=0]{a_2} s_2\xrightarrow[r=0]{a_3} s_5\xrightarrow[r=0]{a_3} s_8\xrightarrow[r=1]{a_2} s_9
s1a2r=0s2a3r=0s5a3r=0s8a2r=1s9
一个episode通常被假设为一个有限的trajectory。 具有episodes的任务称为episodic tasks
有些任务可能没有终止状态(terminal states),这意味着与环境的交互永远不会结束。 此类任务称为连续任务(continuing tasks)
事实上,可以通过将episodic 任务转换为连续任务,以统一的数学方式来处理episodic任务和连续任务。
- 选择1:将目标状态视为特殊的吸收状态(absorbing state)。 一旦agent达到吸收状态,它就永远不会离开。 随之而来的奖励 r = 0 r = 0 r=0
- 选择2:将目标状态视为具有策略的正常状态。 agent仍然可以离开目标状态,并在进入目标状态时获得 r = + 1 r = +1 r=+1。
选择2是较多人选择的方法。
Markov decision process (MDP)

grid-world可以抽象为一个更通用的模型,即马尔可夫过程。
圆圈代表state,带箭头的链接代表state transition。
一旦给出policy,马尔可夫决策过程就变成马尔可夫过程。
以上内容为B站西湖大学智能无人系统 强化学习的数学原理 公开课笔记。