原文地址: https://debezium.io/blog/2021/03/18/understanding-non-key-joins-with-quarkus-extension-for-kafka-streams/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
了解 Kafka Streams 的 Quarkus 扩展的非键连接
三月 18, 2021 作者: Anisha Mohanty
kafka 流 quarkus 示例
Kafka Streams是一个用于开发基于 Apache Kafka 的流处理应用程序的库。引用其文档,“Kafka Streams 应用程序通过拓扑实时处理记录流,以逐条记录的方式连续、并发地处理数据”。Kafka Streams DSL 提供一系列流处理操作,例如映射、过滤器、连接和聚合。
Kafka 流中的非键连接
Debezium 的 CDC 源连接器可以轻松捕获数据库中的数据更改,并将其近乎实时地推送到 Elasticsearch 等接收器系统。默认情况下,这会导致源数据库中的表、相应的 Kafka 主题以及接收器端的数据表示(例如 Elasticsearch 中的搜索索引)之间形成 1:1 关系。
在 1:n 关系的情况下,例如客户表和地址表之间,消费者通常对单个嵌套数据结构的数据视图感兴趣,例如代表客户及其所有信息的单个 Elasticsearch 文档。地址。
这就是KIP-213 (“Kafka 改进提案”)及其外键连接功能的用武之地:它是在Apache Kafka 2.4中引入的,“以缩小流中 KTable 的语义与关系数据库中表之间的差距”。在 KIP-213 之前,为了连接来自两个 Debezium 更改事件主题的消息,您通常必须手动重新设置至少一个主题的密钥,以确保连接两侧使用相同的密钥。
感谢 KIP-213,这不再需要,因为它允许在从 Kafka 消息值提取的字段上加入两个 Kafka 主题,以完全透明的方式自动处理所需的重新键入。与以前的方法相比,这大大减少了从 Debezium 的 CDC 事件创建聚合事件的工作量。
非键连接或更确切地说外键连接类似于 SQL 中的连接,如下所示:
SELECT * FROM CUSTOMER JOIN ADDRESS ON CUSTOMER.ID = ADDRESS.CUSTOMER_ID
在 Kafka Streams 术语中,此类连接的输出是KTable包含连接结果的新输出。
数据库概述
继续使用我们之前的客户和地址示例,让我们考虑具有以下数据模型的应用程序:
图片来自于原文
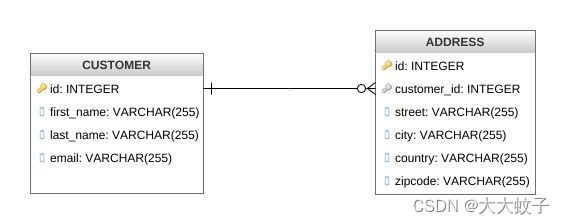
数据库概述
客户和地址这两个实体共享从地址到客户的外键关系,即一个客户可以有多个地址。如上所述,默认情况下 Debezium 将为每个表发出不同主题的事件。使用 Kafka Streams,两个表的更改事件主题将被加载到两个KTables 中,并在客户 id 上连接。Kafka Streams 应用程序将处理来自两个 Kafka 主题的数据。每当任一主题出现新的 CDC 事件(由记录的插入、更新或删除触发)时,都会重新执行联接。
作为 Kafka Streams 应用程序的运行时,我们将使用Quarkus,这是一个用于构建云原生微服务的堆栈,它(以及其他许多服务)还为 Kafka Streams 提供了扩展。虽然通常可以通过简单的main()方法运行 Kafka Streams 拓扑,但使用 Quarkus 和此扩展作为基础具有许多优点:
拓扑管理(例如等待创建所有输入主题)
通过环境变量、系统属性等进行配置。
暴露健康检查
公开指标
开发模式,一种在代码更改后自动热代码替换的流拓扑工作方式
支持通过GraalVM将 Kafka Streams 管道作为本机二进制文件执行,从而显着减少内存消耗和启动时间
图片来自于原文
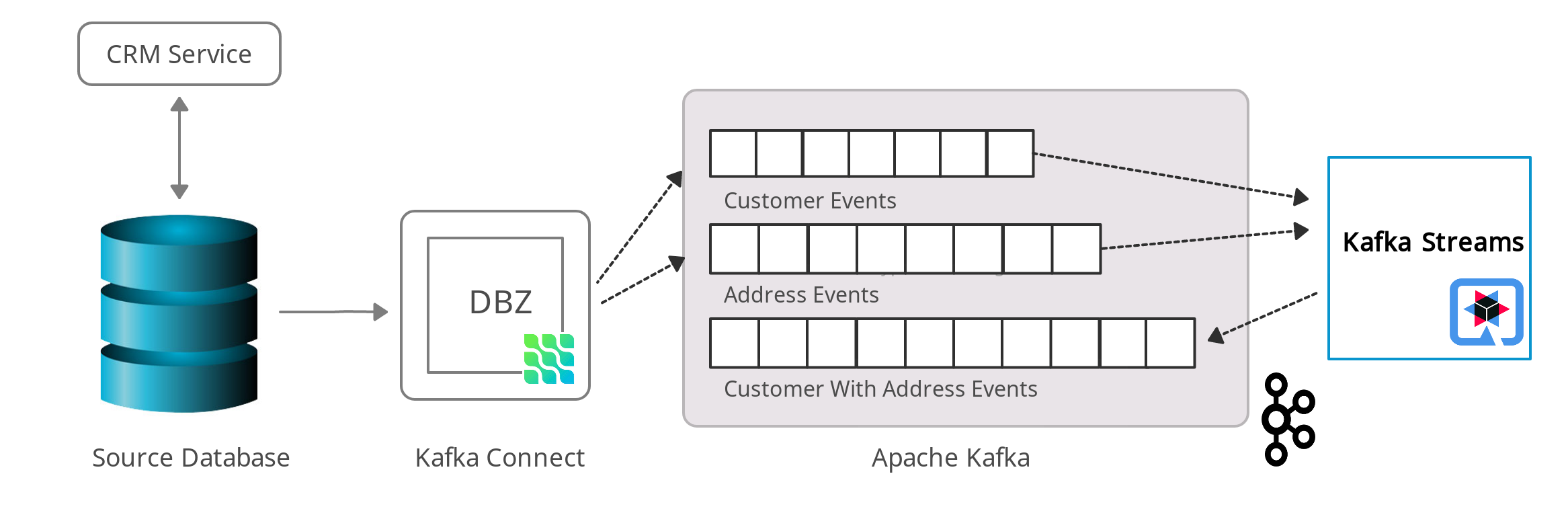
变更事件概述
此图显示了我们解决方案的概述。
使用 Quarkus Kafka Streams 扩展创建应用程序
要使用 Kafka Streams 扩展创建新的 Quarkus 项目,请运行以下命令:
mvn io.quarkus:quarkus-maven-plugin:1.12.2.Final:创建
-DprojectGroupId=org.acme
-DprojectArtifactId=客户地址聚合器
-Dextensions =“卡夫卡流”
cd 客户地址聚合器
了解流处理拓扑
我们有一个聚合器应用程序,它将读取两个 Kafka 主题并在流式管道中处理它们:
这两个主题通过客户 ID 连接起来
每个客户都拥有丰富的地址
该聚合数据被写入第三个主题,customersWithAddressesTopic
当使用 Kafka Streams 的 Quarkus 扩展时,我们所需要做的就是声明一个CDI 生产者方法,该方法返回流处理应用程序的拓扑。该方法必须用 注释@Produces,并且它必须返回一个Topology实例。Quarkus 扩展负责配置、启动和停止 Kafka Streams 引擎。现在让我们看一下实际的流查询实现本身。
@ApplicationScoped
public class TopologyProducer {
@ConfigProperty(name = "customers.topic")
String customersTopic;
@ConfigProperty(name = "addresses.topic")
String addressesTopic;
@ConfigProperty(name = "customers.with.addresses.topic")
String customersWithAddressesTopic;
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
Serde<Long> adressKeySerde = DebeziumSerdes.payloadJson(Long.class);
adressKeySerde.configure(Collections.emptyMap(), true);
Serde<Address> addressSerde = DebeziumSerdes.payloadJson(Address.class);
addressSerde.configure(Collections.singletonMap("from.field", "after"), false);
Serde<Integer> customersKeySerde = DebeziumSerdes.payloadJson(Integer.class);
customersKeySerde.configure(Collections.emptyMap(), true);
Serde<Customer> customersSerde = DebeziumSerdes.payloadJson(Customer.class);
customersSerde.configure(Collections.singletonMap("from.field", "after"), false);
JsonbSerde<AddressAndCustomer> addressAndCustomerSerde =
new JsonbSerde<>(AddressAndCustomer.class);
JsonbSerde<CustomerWithAddresses> customerWithAddressesSerde =
new JsonbSerde<>(CustomerWithAddresses.class);
KTable<Long, Address> addresses = builder.table(
addressesTopic,
Consumed.with(adressKeySerde, addressSerde)
);
KTable<Integer, Customer> customers = builder.table(
customersTopic,
Consumed.with(customersKeySerde, customersSerde)
);
KTable<Integer, CustomerWithAddresses> customersWithAddresses = addresses.join(
customers,
address -> address.customer_id,
AddressAndCustomer::new,
Materialized.with(Serdes.Long(), addressAndCustomerSerde)
)
.groupBy(
(addressId, addressAndCustomer) -> KeyValue.pair(
addressAndCustomer.customer.id, addressAndCustomer),
Grouped.with(Serdes.Integer(), addressAndCustomerSerde)
)
.aggregate(
CustomerWithAddresses::new,
(customerId, addressAndCustomer, aggregate) -> aggregate.addAddress(
addressAndCustomer),
(customerId, addressAndCustomer, aggregate) -> aggregate.removeAddress(
addressAndCustomer),
Materialized.with(Serdes.Integer(), customerWithAddressesSerde)
);
customersWithAddresses.toStream()
.to(
customersWithAddressesTopic,
Produced.with(Serdes.Integer(), customerWithAddressesSerde)
);
return builder.build();
}
}
主题名称使用MicroProfile Config API注入,值在 Quarkus 配置文件中提供application.properties(例如,可以使用环境变量覆盖它们)
创建 的实例StreamsBuilder,这有助于我们构建拓扑
为了将流管道中使用的 Java 类型序列化为 JSON 或从 JSON 序列化和反序列化,Quarkus 提供了class io.quarkus.kafka.client.serialization.JsonbSerde; Serde实现基于JSON-B
KTable-外键连接功能KTable用于提取customer#id并执行连接;StreamsBuilder#table()用于将两个Kafka主题分别读入KTableaddresses和中customers
来自主题的消息addresses与相应的主题连接customers;连接结果包含客户的数据及其地址之一
groupBy()操作将对记录进行分组customer#id
为了生成一个客户及其所有地址的嵌套结构,该aggregate()操作应用于每组记录(客户地址元组),更新每个CustomerWithAddresses客户的
管道的结果写出到customersWithAddressesTopic主题
当事件在流管道中处理时,该类CustomerWithAddresses会跟踪聚合值。
public class CustomerWithAddresses {
public Customer customer;
public List<Address> addresses = new ArrayList<>();
public CustomerWithAddresses addAddress(AddressAndCustomer addressAndCustomer) {
customer = addressAndCustomer.customer;
addresses.add(addressAndCustomer.address);
return this;
}
public CustomerWithAddresses removeAddress(AddressAndCustomer addressAndCustomer) {
Iterator<Address> it = addresses.iterator();
while (it.hasNext()) {
Address a = it.next();
if (a.id == addressAndCustomer.address.id) {
it.remove();
break;
}
}
return this;
}
}
Kafka Streams 扩展是通过 Quarkus 配置文件配置的application.properties。除了主题名称之外,此文件还包含有关 Kafka 引导服务器和多个流选项的信息:
customers.topic=dbserver1.inventory.customers
addresses.topic=dbserver1.inventory.addresses
customers.with.addresses.topic=customers-with-addresses
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-id=kstreams-fkjoin-aggregator
quarkus.kafka-streams.application-server=
h
o
s
t
n
a
m
e
:
8080
q
u
a
r
k
u
s
.
k
a
f
k
a
−
s
t
r
e
a
m
s
.
t
o
p
i
c
s
=
{hostname}:8080 quarkus.kafka-streams.topics=
hostname:8080quarkus.kafka−streams.topics={customers.topic},${addresses.topic}
streams options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG
kafka-streams.consumer.session.timeout.ms=150
kafka-streams.consumer.heartbeat.interval.ms=100
构建并运行应用程序
您现在可以像这样构建应用程序:
mvn清理包
为了运行应用程序和所有相关组件(Kafka、Kafka Connect 与 Debezium、Postgres 数据库),我们创建了一个Docker Compose 文件,您可以在debezium-examples存储库中找到该文件。要启动所有容器,同时构建聚合器容器映像,请运行以下命令:
导出 DEBEZIUM_VERSION=1.4
docker-compose up --build
要将 Debezium 连接器注册到 Kafka Connect,您需要指定配置属性,例如连接器名称、数据库主机名、用户、密码、端口、数据库名称等。创建包含以下内容的文件 register - postgres.json :
{
“connector.class”: “io.debezium.connector.postgresql.PostgresConnector”,
“tasks.max”: “1”,
“database.hostname”: “postgres”,
“database.port”: “5432”,
“database.user”: “postgres”,
“database.password”: “postgres”,
“database.dbname” : “postgres”,
“database.server.name”: “dbserver1”,
“schema.include”: “inventory”,
“decimal.handling.mode” : “string”,
“key.converter”: “org.apache.kafka.connect.json.JsonConverter”,
“key.converter.schemas.enable”: “false”,
“value.converter”: “org.apache.kafka.connect.json.JsonConverter”,
“value.converter.schemas.enable”: “false”
}
配置 Debezium 连接器:
http PUT http://localhost:8083/connectors/inventory-connector/config < register-postgres.json
现在运行容器镜像的实例debezium/tooling:
docker run --tty --rm
–network kstreams-fk-join-network
Debezium/工具:1.1
该镜像提供了几个有用的工具,例如kafkacat。在工具容器中,运行 kafkacat 以检查流管道的结果:
kafkacat -b kafka:9092 -C -o 开头 -q
-t 具有地址的客户 | jq .
您应该看到如下所示的记录,每条记录都包含一位客户的所有数据及其所有地址:
{
“addresses”: [
{
“city”: “Hamburg”,
“country”: “Canada”,
“customer_id”: 1001,
“id”: 100001,
“street”: “42 Main Street”,
“zipcode”: “90210”
},
{
“city”: “Berlin”,
“country”: “Canada”,
“customer_id”: 1001,
“id”: 100002,
“street”: “11 Post Dr.”,
“zipcode”: “90211”
}
],
“customer”: {
“email”: “sally.thomas@acme.com”,
“first_name”: “Sally”,
“id”: 1001,
“last_name”: “Thomas”
}
}
获取数据库的 shell,插入、更新或删除一些记录,连接将自动重新处理:
$ docker run --tty --rm -i
–network kstreams-fk-join-network
debezium/tooling:1.1
bash -c ‘pgcli postgresql://postgres:postgres@postgres:5432/postgres’
in pgcli, e.g. to update a customer record:
update inventory.customers set first_name = ‘Sarah’ where id = 1001;
本地运行
Kafka Streams 应用程序可以轻松横向扩展,即负载将在应用程序的多个实例之间共享,每个实例处理输入主题分区的子集。当 Quarkus 应用程序通过 GraalVM 编译为本机代码时,它占用的内存要少得多,并且启动时间非常快。无需担心内存管理,您可以并行启动 Kafka Streams 管道的多个实例。
如果您想在native模式下运行此应用程序,请设置QUARKUS_MODE为native并运行以下命令(确保安装了所需的 GraalVM 工具):
mvn clean 包-Pnative
要了解有关将 Kafka Streams 应用程序作为本机二进制文件运行的更多信息,请参阅参考指南。
关于 Kafka Streams 扩展的更多见解
Quarkus 扩展还可以帮助您解决构建流处理微服务时的一些常见要求。例如,为了在生产中运行 Kafka Streams 应用程序,您可以轻松地为数据管道添加运行状况检查和指标。
Micrometer Metrics提供了有关 Quarkus 应用程序的丰富指标,即通过监视应用程序内部发生的情况及其性能特征。Quarkus 允许您使用 JSON 格式或 OpenMetrics 格式通过 HTTP 公开这些指标。从那里,它们可以被Prometheus等工具抓取并存储以进行分析和可视化。
应用程序启动后,指标将在 下公开q/metrics,默认返回 OpenMetrics 格式的数据:
HELP kafka_producer_node_request_total The total number of requests sent
TYPE kafka_producer_node_request_total counter
kafka_producer_node_request_total{client_id=“kstreams-fkjoin-aggregator-b4ac1384-0e0a-4f19-8d52-8cc1ee4c6dfe-StreamThread-1-producer”,kafka_version=“2.5.0”,node_id=“node–1”,status=“up”,} 83.0
HELP kafka_producer_record_send_rate The average number of records sent per second.
TYPE kafka_producer_record_send_rate gauge
kafka_producer_record_send_rate{client_id=“kstreams-fkjoin-aggregator-b4ac1384-0e0a-4f19-8d52-8cc1ee4c6dfe-StreamThread-1-producer”,kafka_version=“2.5.0”,status=“up”,} 0.0
HELP jvm_gc_memory_allocated_bytes_total Incremented for an increase in the size of the (young) heap memory pool after one GC to before the next
TYPE jvm_gc_memory_allocated_bytes_total counter
jvm_gc_memory_allocated_bytes_total 1.1534336E8
…
HELP http_requests_total
TYPE http_requests_total counter
http_requests_total{status=“up”,uri="/api/customers",} 0.0
…
如果您不使用 Prometheus,您还有一些选择,例如 Datadog、Stackdriver 等。有关详细指南,请查看Quarkiverse Extensions。
另一方面,我们有MicroProfile Health规范,它提供有关应用程序活跃度的信息,即表明您的应用程序是否正在运行以及您的应用程序是否能够处理请求。要监控现有 Quarkus 应用程序的运行状况,您可以添加扩展smallrye-health:
mvn quarkus:add-extension -Dextensions=“smallrye-health”
Quarkus 将通过 HTTP 公开所有健康检查q/health,在我们的例子中显示管道的状态和任何缺失的主题:
{
“status”: “DOWN”,
“checks”: [
{
“name”: “Kafka Streams topics health check”,
“status”: “DOWN”,
“data”: {
“missing_topics”: “dbserver1.inventory.customers,dbserver1.inventory.addresses”
}
}
]
}
概括
Kafka Streams 的 Quarkus 扩展提供了在 JVM 上以及本机模式下运行流处理管道所需的一切,以及执行运行状况检查、指标等的额外好处。例如,您可以使用 Quarkus REST 支持轻松公开用于交互式查询的 REST API,并可能使用 MicroProfile REST 客户端 API从横向扩展的 Kafka Streams 应用程序的其他实例中检索数据。
在本文中,我们讨论了 Kafka Streams 中外键联接的流处理拓扑,以及如何使用 Quarkus Kafka Streams 扩展在 JVM 模式下运行和构建应用程序。您可以在 Debezium 示例存储库中找到实现的完整源代码。如果您有任何问题或反馈,请在下面的评论中告诉我们。我们期待您的建议!
参考
使用 Quarkus 构建 Kafka Streams 应用程序
使用 Debezium 和 Kafka Streams 更改数据捕获管道
千分尺应用监视器