文章目录
- 01 引言
- 02 连接器依赖
- 2.1 kafka连接器依赖
- 2.2 base基础依赖
- 03 连接器使用方法
- 04 消息订阅
- 4.1 主题订阅
- 4.2 正则表达式订阅
- 4.3 Partition 列分区订阅
- 05 消息解析
- 06 起始消费位点
- 07 有界 / 无界模式
- 7.1 流式
- 7.2 批式
- 08 其他属性
- 8.1 KafkaSource 配置项
- (1)client.id.prefix
- (2)partition.discovery.interval.ms
- (3)register.consumer.metrics
- (4)commit.offsets.on.checkpoint
- 8.2 Kafka consumer 配置项
- (1) key.deserializer
- (2) value.deserializer
- (3) auto.offset.reset.strategy
- (4) partition.discovery.interval.ms
- 09 动态分区检查
- 10 事件时间和水印
- 11 消费位点提交
- 12 监控
- 12.1 指标范围
- 12.2 Kafka Consumer 指标
- 13 安全认证
- 14 Kafka source 实现原理
- 数据源分片(Source Split)
- 分片枚举器(Split Enumerator)
- 源读取器(Source Reader)
- 15 项目源码实战demo
- 15.1 包结构
- 15.2 引入依赖
- 15.3 创建配置文件
- (1)application.properties
- (2)log4j2.properties
- 15.4 创建kafka Connector作业
- 5.1 验证主题组合
- (1)组合一:设置单个主题消费
- (2)组合二:设置多个主题
- (3)组合三:设置主题list,如步骤(2)一样操作
- (4)组合四:设置正则表达式匹配主题,
- (5)组合五:订阅指定分区Partition,指定消费主题的哪一个分区
01 引言
Flink 提供了 Apache Kafka 连接器使用精确一次(Exactly-once)的语义在 Kafka topic 中读取和写入数据。
实战源码地址,一键下载可用:https://gitee.com/shawsongyue/aurora.git
模块:aurora_flink_connector_kafka
主类:KafkaSourceStreamingJob
02 连接器依赖
2.1 kafka连接器依赖
<!--kafka依赖 start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.2-1.18</version>
</dependency>
<!--kafka依赖 end-->
2.2 base基础依赖
若是不引入该依赖,项目启动直接报错:Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/flink/connector/base/source/reader/RecordEmitter
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.18.0</version>
</dependency>
03 连接器使用方法
Kafka Source 提供了构建类来创建 KafkaSource的实例。以下代码片段展示了如何构建 KafkaSource 来消费 “input-topic” 最早位点的数据, 使用消费组 “my-group”,并且将 Kafka 消息体反序列化为字符串 。
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
#以下属性在构建 KafkaSource 时是必须指定的:
1.Bootstrap server,通过 setBootstrapServers(String) 方法配置
2.消费者组 ID,通过 setGroupId(String) 配置
3.要订阅的 Topic / Partition
4.用于解析 Kafka 消息的反序列化器(Deserializer)
04 消息订阅
Kafka Source 提供了 3 种 Topic / Partition 的订阅方式
4.1 主题订阅
可以订阅 Topic 列表中所有 Partition 的消息
KafkaSource.builder().setTopics("topic-a", "topic-b");
4.2 正则表达式订阅
订阅与正则表达式所匹配的 Topic 下的所有 Partition
KafkaSource.builder().setTopicPattern("topic.*");
4.3 Partition 列分区订阅
订阅指定的 Partition
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"
new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);
05 消息解析
1.代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析。 反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema) 来指定,其中 KafkaRecordDeserializationSchema 定义了如何解析 Kafka 的 ConsumerRecord。
2.如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
3.也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder()
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
06 起始消费位点
Kafka source 能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费
KafkaSource.builder()
// 从消费组提交的位点开始消费,不指定位点重置策略
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费
.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))
// 从最早位点开始消费,默认使用
.setStartingOffsets(OffsetsInitializer.earliest())
// 从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest());
07 有界 / 无界模式
7.1 流式
流模式下运行通过使用 setUnbounded(OffsetsInitializer)`也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source 会退出运行。
7.2 批式
可以使用 setBounded(OffsetsInitializer) 指定停止偏移量使 Kafka Source 以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source 会退出运行。
08 其他属性
可以使用 setProperties(Properties) 和 setProperty(String, String) 为 Kafka Source 和 Kafka Consumer 设置任意属性
8.1 KafkaSource 配置项
(1)client.id.prefix
指定用于 Kafka Consumer 的客户端 ID 前缀
(2)partition.discovery.interval.ms
定义 Kafka Source 检查新分区的时间间隔
(3)register.consumer.metrics
指定是否在 Flink 中注册 Kafka Consumer 的指标
(4)commit.offsets.on.checkpoint
指定是否在进行 checkpoint 时将消费位点提交至 Kafka broker
8.2 Kafka consumer 配置项
(1) key.deserializer
始终设置为 ByteArrayDeserializer
(2) value.deserializer
始终设置为 ByteArrayDeserializer
(3) auto.offset.reset.strategy
被 OffsetsInitializer#getAutoOffsetResetStrategy() 覆盖
(4) partition.discovery.interval.ms
会在批模式下被覆盖为 -1
09 动态分区检查
为了在不重启 Flink 作业的情况下处理 Topic 扩容或新建 Topic 等场景,将 Kafka Source 配置为在提供的 Topic / Partition 订阅模式下定期检查新分区。要启用动态分区检查,partition.discovery.interval.ms设置为非负值:
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
10 事件时间和水印
默认情况下,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");
11 消费位点提交
Kafka source 在 checkpoint 完成时提交当前的消费位点 ,以保证 Flink 的 checkpoint 状态和 Kafka broker 上的提交位点一致。如果未开启 checkpoint,Kafka source 依赖于 Kafka consumer 内部的位点定时自动提交逻辑,自动提交功能由 enable.auto.commit 和 auto.commit.interval.ms 两个 Kafka consumer 配置项进行配置。
注意:Kafka source 不依赖于 broker 上提交的位点来恢复失败的作业。提交位点只是为了上报 Kafka consumer 和消费组的消费进度,以在 broker 端进行监控。
12 监控
12.1 指标范围
12.2 Kafka Consumer 指标
Kafka consumer 的所有指标都注册在指标组 KafkaSourceReader.KafkaConsumer 下。例如 Kafka consumer 的指标 records-consumed-total 将在该 Flink 指标中汇报: .operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
您可以使用配置项 register.consumer.metrics 配置是否注册 Kafka consumer 的指标 。默认此选项设置为 true。
关于 Kafka consumer 的指标,您可以参考 Apache Kafka 文档 了解更多详细信息。
13 安全认证
1.要启用加密和认证相关的安全配置,只需将安全配置作为其他属性配置在 Kafka source 上即可。下面的代码片段展示了如何配置 Kafka source 以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置
KafkaSource.builder()
.setProperty("security.protocol", "SASL_PLAINTEXT")
.setProperty("sasl.mechanism", "PLAIN")
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");
2.使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制 。 如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置
KafkaSource.builder()
.setProperty("security.protocol", "SASL_SSL")
// SSL 配置
// 配置服务端提供的 truststore (CA 证书) 的路径
.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks")
.setProperty("ssl.truststore.password", "test1234")
// 如果要求客户端认证,则需要配置 keystore (私钥) 的路径
.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks")
.setProperty("ssl.keystore.password", "test1234")
// SASL 配置
// 将 SASL 机制配置为 as SCRAM-SHA-256
.setProperty("sasl.mechanism", "SCRAM-SHA-256")
// 配置 JAAS
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");
14 Kafka source 实现原理
数据源分片(Source Split)
Kafka source 的数据源分片(source split)表示 Kafka topic 中的一个 partition。Kafka 的数据源分片包括:
- 该分片表示的 topic 和 partition
- 该 partition 的起始位点
- 该 partition 的停止位点,当 source 运行在批模式时适用
Kafka source 分片的状态同时存储该 partition 的当前消费位点,该分片状态将会在 Kafka 源读取器(source reader)进行快照(snapshot) 时将当前消费位点保存为起始消费位点以将分片状态转换成不可变更的分片。
可查看 KafkaPartitionSplit 和 KafkaPartitionSplitState 类来了解细节。
分片枚举器(Split Enumerator)
Kafka source 的分片枚举器负责检查在当前的 topic / partition 订阅模式下的新分片(partition),并将分片轮流均匀地分配给源读取器(source reader)。 注意 Kafka source 的分片枚举器会将分片主动推送给源读取器,因此它无需处理来自源读取器的分片请求。
源读取器(Source Reader)
Kafka source 的源读取器扩展了 SourceReaderBase,并使用单线程复用(single thread multiplex)的线程模型,使用一个由分片读取器 (split reader)驱动的 KafkaConsumer 来处理多个分片(partition)。消息会在从 Kafka 拉取下来后在分片读取器中立刻被解析。分片的状态 即当前的消息消费进度会在 KafkaRecordEmitter 中更新,同时会在数据发送至下游时指定事件时间。
15 项目源码实战demo
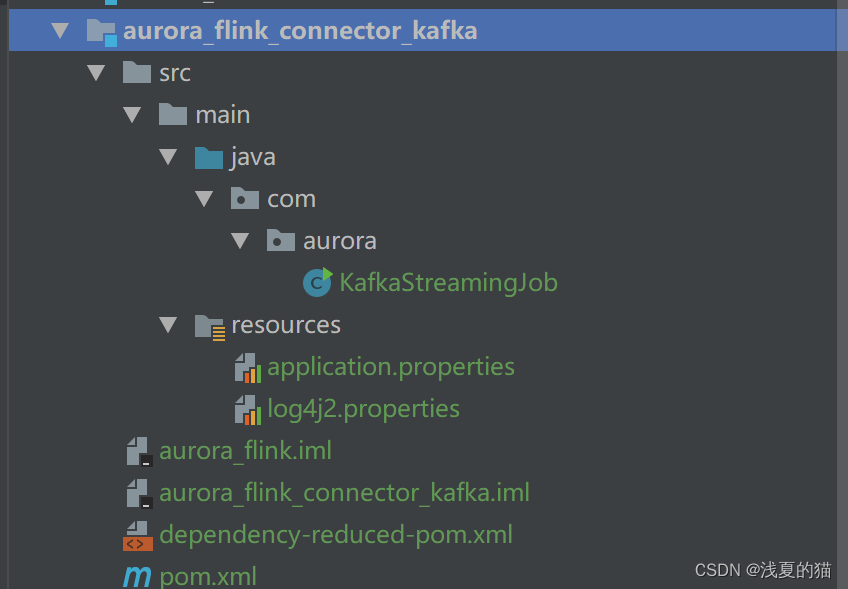
15.1 包结构
15.2 引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xsy</groupId>
<artifactId>aurora_flink_connector_kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<!--属性设置-->
<properties>
<!--java_JDK版本-->
<java.version>11</java.version>
<!--maven打包插件-->
<maven.plugin.version>3.8.1</maven.plugin.version>
<!--编译编码UTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--输出报告编码UTF-8-->
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!--json数据格式处理工具-->
<fastjson.version>1.2.75</fastjson.version>
<!--log4j版本-->
<log4j.version>2.17.1</log4j.version>
<!--flink版本-->
<flink.version>1.18.0</flink.version>
<!--scala版本-->
<scala.binary.version>2.11</scala.binary.version>
</properties>
<!--通用依赖-->
<dependencies>
<!-- json -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!--================================集成外部依赖==========================================-->
<!--集成日志框架 start-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<!--集成日志框架 end-->
<!--kafka依赖 start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.2-1.18</version>
</dependency>
<!--kafka依赖 end-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.18.0</version>
</dependency>
</dependencies>
<!--编译打包-->
<build>
<finalName>${project.name}</finalName>
<!--资源文件打包-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>org.google.code.flindbugs:jar305</exclude>
<exclude>org.slf4j:*</exclude>
<excluder>org.apache.logging.log4j:*</excluder>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.aurora.KafkaStreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<!--插件统一管理-->
<pluginManagement>
<plugins>
<!--maven打包插件-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<finalName>${project.build.finalName}</finalName>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<!--编译打包插件-->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<!--配置Maven项目中需要使用的远程仓库-->
<repositories>
<repository>
<id>aliyun-repos</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<!--用来配置maven插件的远程仓库-->
<pluginRepositories>
<pluginRepository>
<id>aliyun-plugin</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>
15.3 创建配置文件
(1)application.properties
#kafka集群地址
kafka.bootstrapServers=localhost:9092
#kafka消费者组
kafka.group=aurora_group
(2)log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
15.4 创建kafka Connector作业
package com.aurora;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.KafkaSourceBuilder;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashSet;
import java.util.regex.Pattern;
/**
* @author 浅夏的猫
* @description kafka 连接器使用demo作业
* @datetime 22:21 2024/2/1
*/
public class KafkaSourceStreamingJob{
private static final Logger logger = LoggerFactory.getLogger(KafkaStreamingJob.class);
public static void main(String[] args) throws Exception {
//===============1.获取参数==============================
//定义文件路径
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink_connector_kafka\\src\\main\\resources\\application.properties";
//方式一:直接使用内置工具类
ParameterTool paramsMap = ParameterTool.fromPropertiesFile(propertiesFilePath);
//================2.初始化kafka参数==============================
String bootstrapServers = paramsMap.get("kafka.bootstrapServers");
String topic = paramsMap.get("kafka.topic");
String group = paramsMap.get("kafka.group");
//=================3.创建kafka数据源=============================
KafkaSourceBuilder<String> kafkaSourceBuilder = KafkaSource.builder();
//(1)设置kafka地址
kafkaSourceBuilder.setBootstrapServers(bootstrapServers);
//(2)设置消费这组id
kafkaSourceBuilder.setGroupId(group);
//(3)设置主题,支持多种主题组合
setTopic(kafkaSourceBuilder);
//(4)设置消费模式,支持多种消费模式
setStartingOffsets(kafkaSourceBuilder);
//(5)设置反序列化器
setDeserializer(kafkaSourceBuilder);
//(6)构建全部参数
KafkaSource<String> kafkaSource = kafkaSourceBuilder.build();
//(7)动态检查新分区, 10 秒检查一次新分区
kafkaSourceBuilder.setProperty("partition.discovery.interval.ms", "10000");
//=================4.创建Flink运行环境=================
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source");
//=================5.数据简单处理======================
dataStreamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String record, Collector<String> collector) throws Exception {
logger.info("正在处理kafka数据:{}", record);
}
});
//=================6.启动服务=========================================
env.execute();
}
/**
*
* @description 主题模式设置
* 1.设置单个主题
* 2.设置多个主题
* 3.设置主题list
* 4.设置正则表达式匹配主题
* 5.订阅指定分区Partition
*
* @author 浅夏的猫
* @datetime 21:18 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setTopic(KafkaSourceBuilder<String> kafkaSourceBuilder) {
//组合1:设置单个主题
kafkaSourceBuilder.setTopics("topic_a");
//组合2:设置多个主题
// kafkaSourceBuilder.setTopics("topic_a", "topic_b");
//组合3:设置主题list
// kafkaSourceBuilder.setTopics(Arrays.asList("topic_a", "topic_b"));
//组合4:设置正则表达式匹配主题
// kafkaSourceBuilder.setTopicPattern(Pattern.compile("topic_a.*"));
//组合5:订阅指定分区Partition,指定消费主题的哪一个分区,也支持消费多个主题的多个分区
// final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic_a", 0), new TopicPartition("topic_b", 4)));
// kafkaSourceBuilder.setPartitions(partitionSet);
}
/**
* @description 消费模式
* 1.从消费组提交的位点开始消费,不指定位点重置策略
* 2.从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
* 3.从时间戳大于等于指定时间戳(毫秒)的数据开始消费
* 4.从最早位点开始消费
* 5.从最末尾位点开始消费,即从注册时刻开始消费
*
* @author 浅夏的猫
* @datetime 21:27 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setStartingOffsets(KafkaSourceBuilder<String> kafkaSourceBuilder){
//模式1: 从消费组提交的位点开始消费,不指定位点重置策略,这种策略会报异常,没有设置快照或设置自动提交offset:Caused by: org.apache.kafka.clients.consumer.NoOffsetForPartitionException: Undefined offset with no reset policy for partitions: [topic_a-3]
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.committedOffsets());
//模式2:从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST));
//模式3:从时间戳大于等于指定时间戳(毫秒)的数据开始消费
kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L));
//模式4:从最早位点开始消费
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.earliest());
//模式5:从最末尾位点开始消费,即从注册时刻开始消费
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.latest());
}
/**
* @description 设置反序列器,支持多种反序列号方式
* 1.自定义如何解析kafka数据
* 2.使用Kafka 提供的解析器处理
* 3.只设置kafka的value反序列化
*
* @author 浅夏的猫
* @datetime 21:35 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setDeserializer(KafkaSourceBuilder<String> kafkaSourceBuilder){
//1.自定义如何解析kafka数据
// KafkaRecordDeserializationSchema<String> kafkaRecordDeserializationSchema = new KafkaRecordDeserializationSchema<>() {
// @Override
// public TypeInformation<String> getProducedType() {
// return TypeInformation.of(String.class);
// }
//
// @Override
// public void deserialize(ConsumerRecord<byte[], byte[]> consumerRecord, Collector<String> collector) throws IOException {
// //自定义解析数据
// byte[] valueByte = consumerRecord.value();
// String value = new String(valueByte);
// //下发消息
// collector.collect(value);
// }
// };
// kafkaSourceBuilder.setDeserializer(kafkaRecordDeserializationSchema);
//2.使用Kafka 提供的解析器处理
// kafkaSourceBuilder.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
//3.只设置kafka的value反序列化
kafkaSourceBuilder.setValueOnlyDeserializer(new SimpleStringSchema());
}
}
5.1 验证主题组合
1.kafka搭建参考我的另外一篇博客:https://blog.csdn.net/weixin_40736233/article/details/136002105
2.使用kafka创建两个主题:topic_a,topic_b,1个副本5个分区(windows环境脚本是.bat,linux环境是.sh)
#创建主题
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 5 --topic topic_a
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 5 --topic topic_b
#查询主题
kafka-topics.bat --bootstrap-server localhost:9092 --list
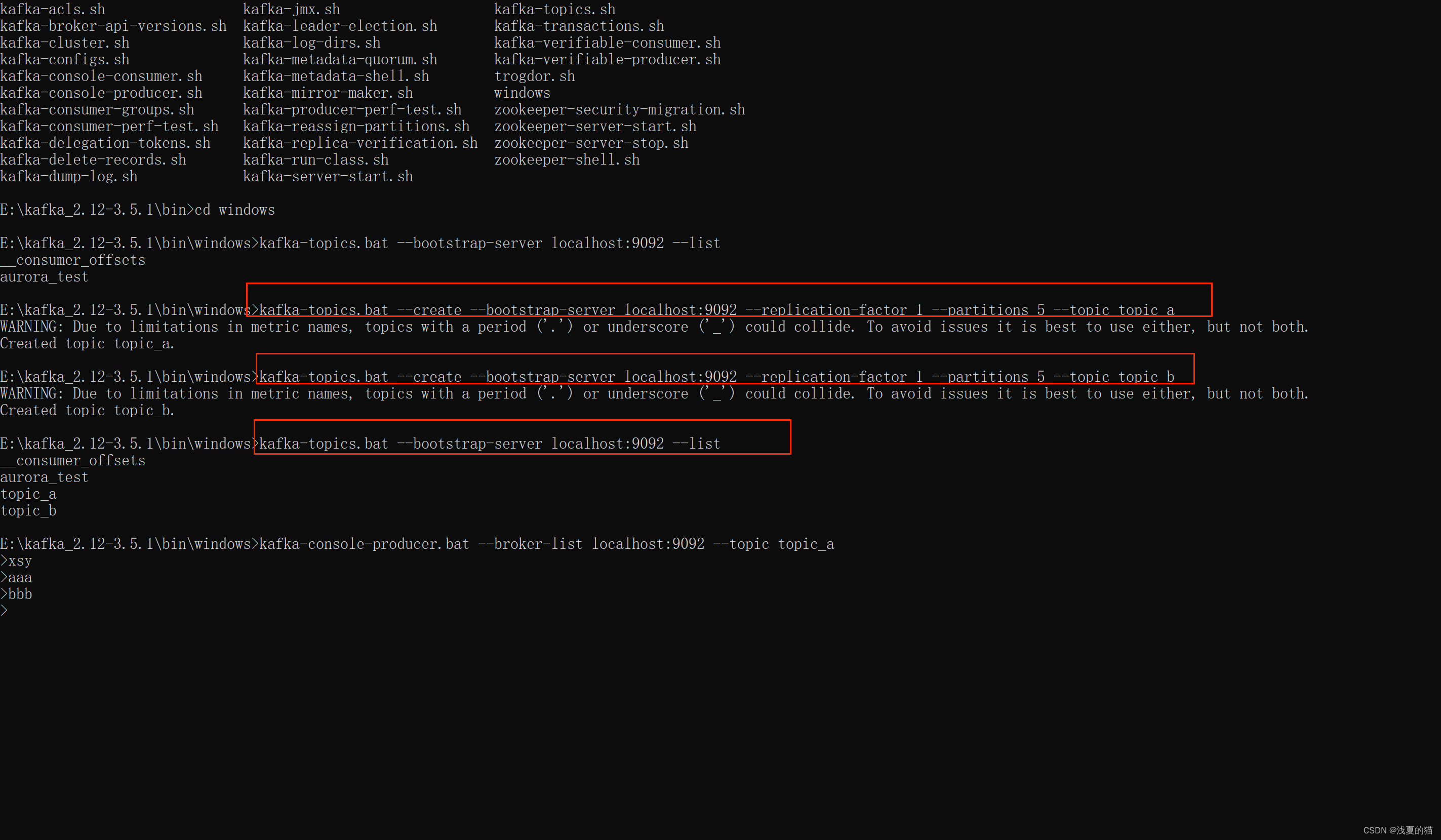
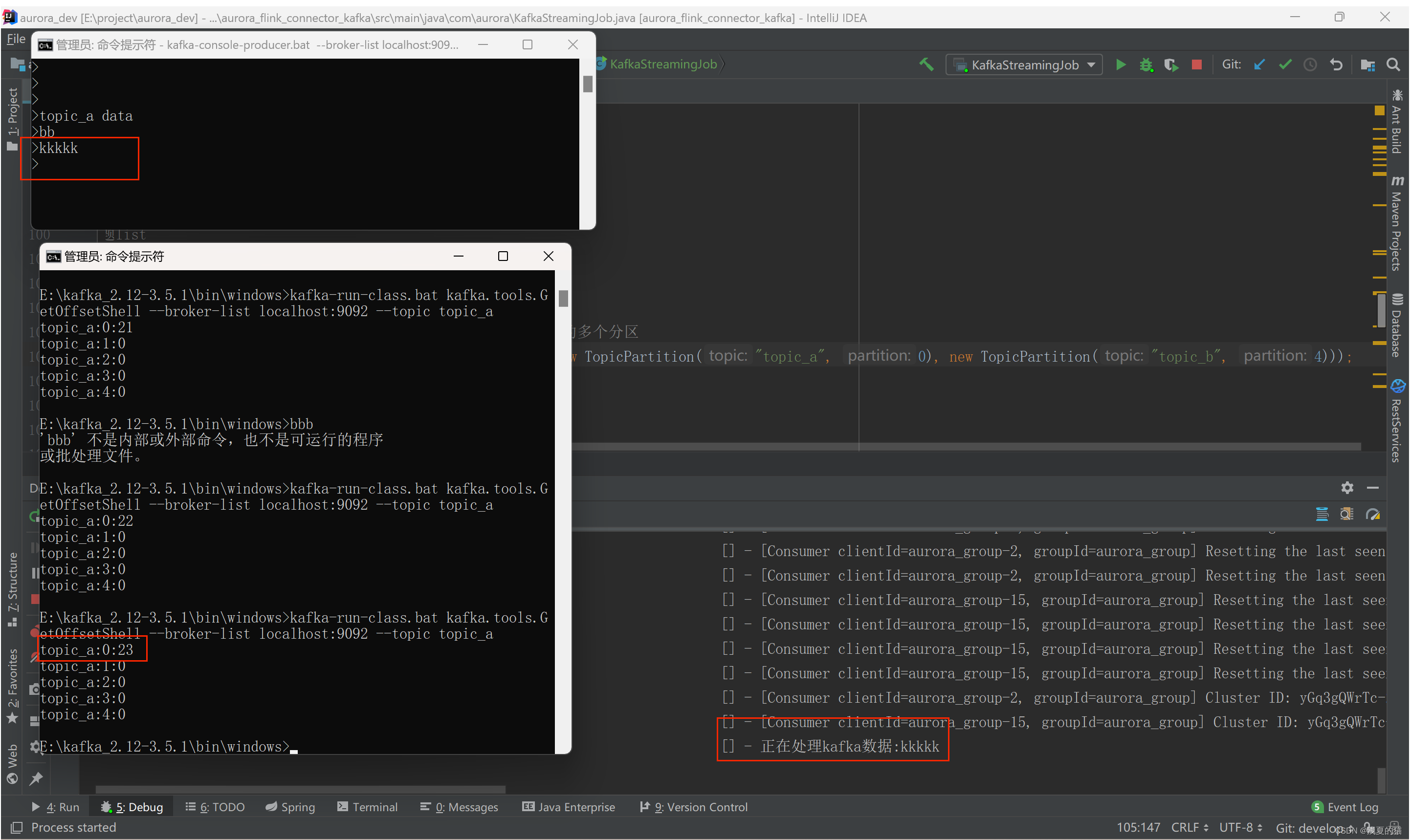
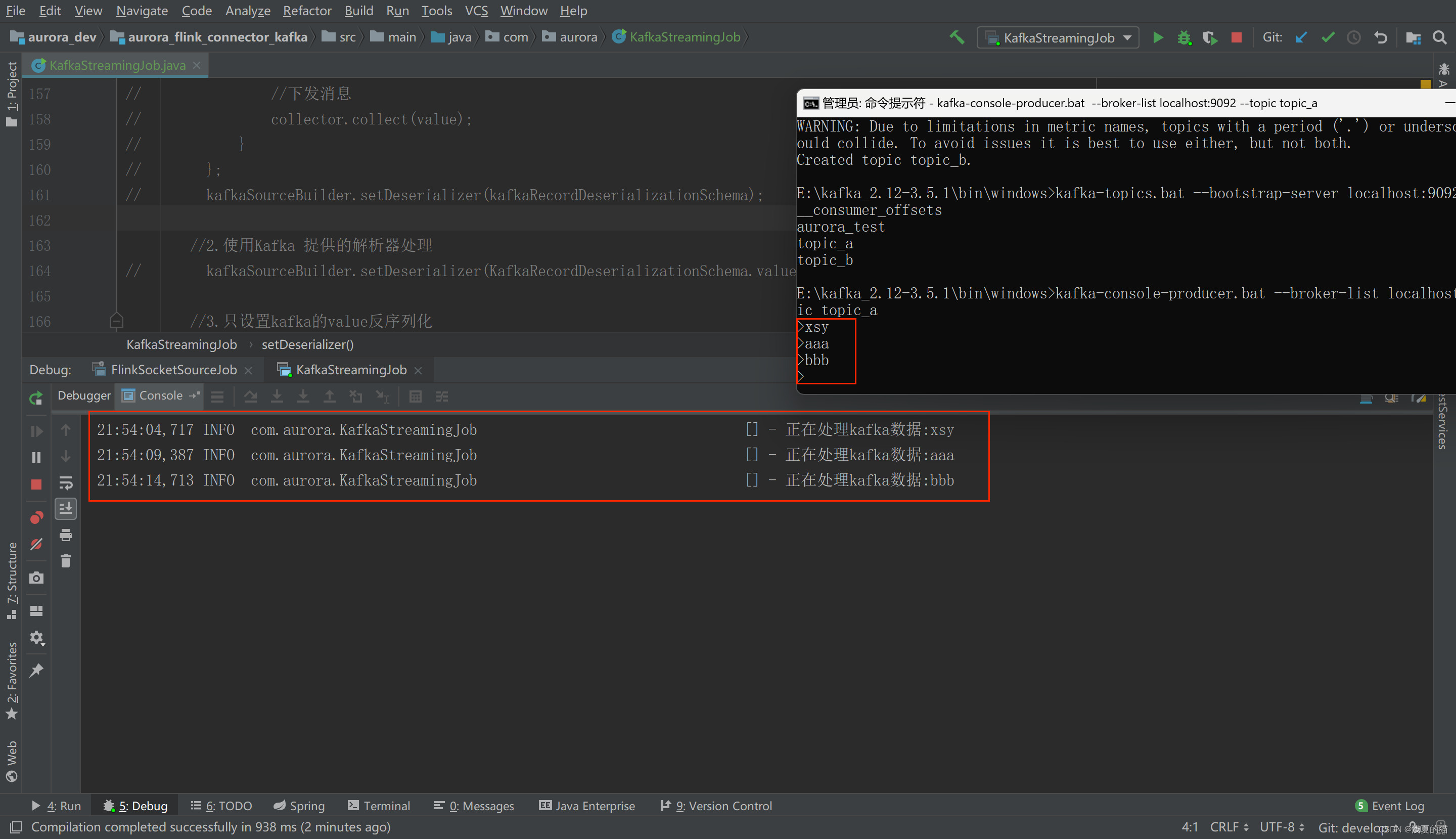
(1)组合一:设置单个主题消费
启动Flink程序消费,并且通过kafka命令启动一个生产者。模拟数据生成
#启动生产者
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_a
(2)组合二:设置多个主题
#放开注释组合二的代码
启动Flink程序消费,并且通过kafka命令启动一个生产者。模拟数据生成
#启动两个生产者,分别生产topic_a,topic_b数据
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_a
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_b
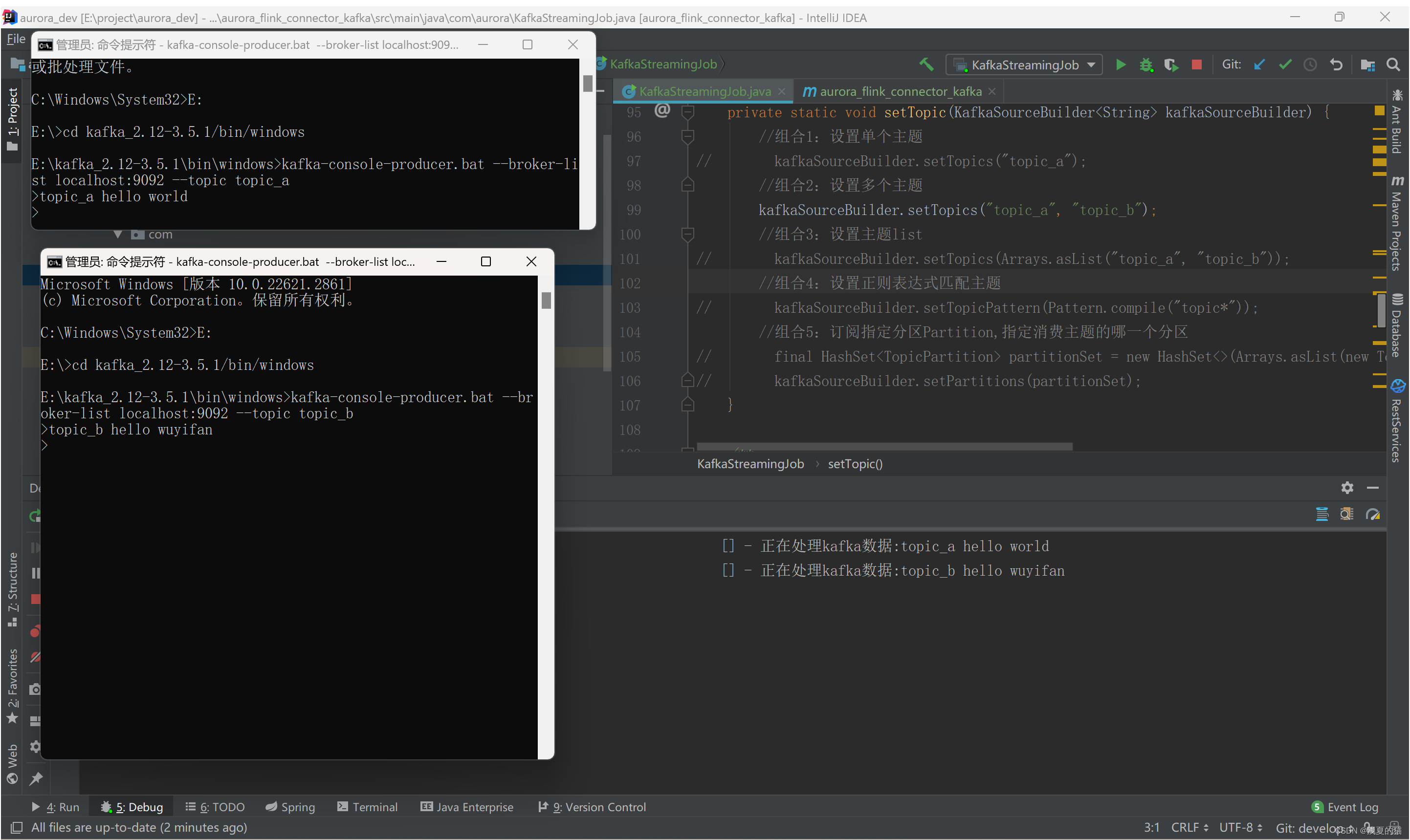
(3)组合三:设置主题list,如步骤(2)一样操作
(4)组合四:设置正则表达式匹配主题,
只订阅topic_a下面的全部分区,不订阅topic_b,程序只会消费topic_a,不会消费topic_b
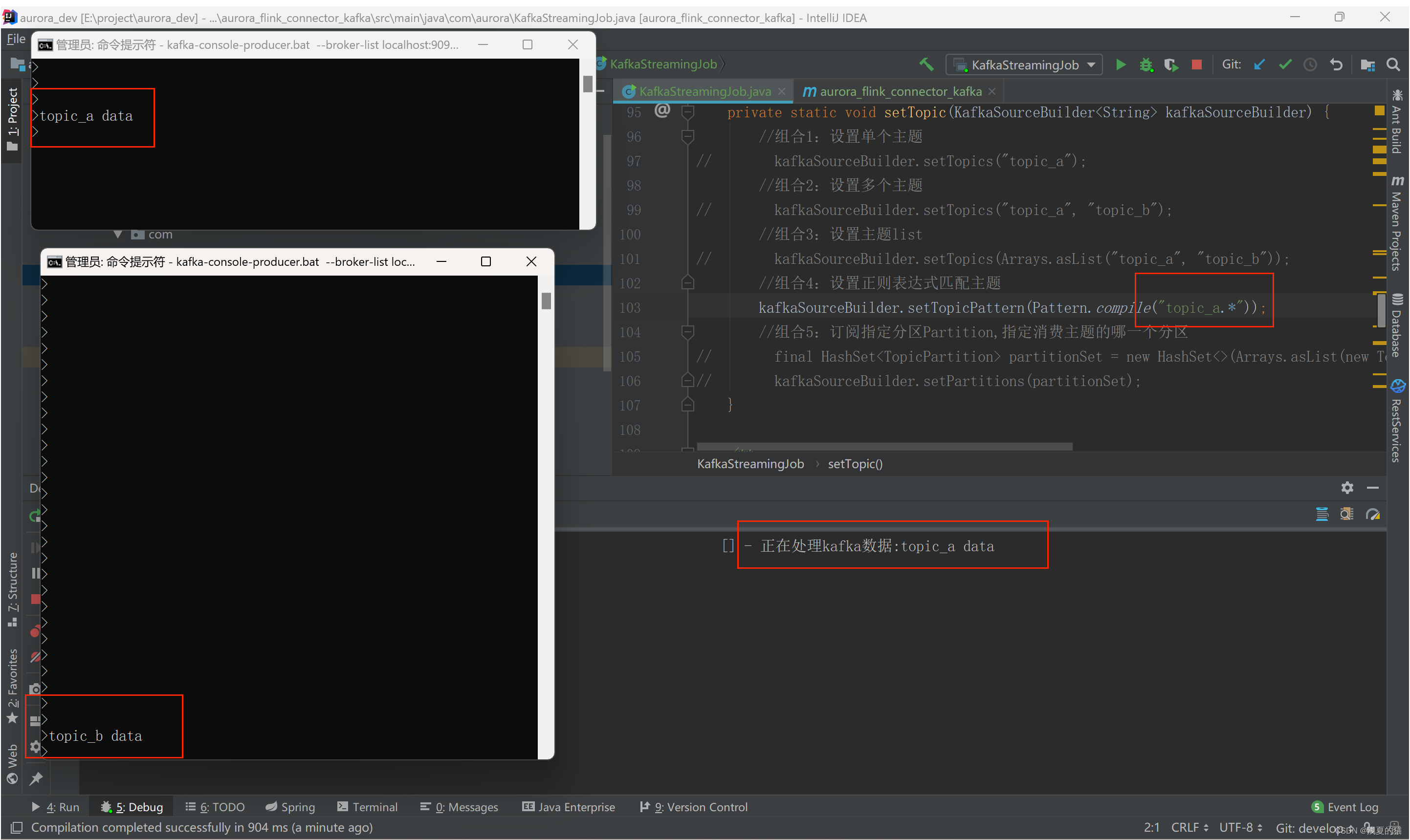
(5)组合五:订阅指定分区Partition,指定消费主题的哪一个分区
#查看消息落在哪个分区,落在0分区则消费,其他分区没有数
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic topic_a