在过去的几个月里,生成式人工智能领域出现了许多令人兴奋的新进展。 ChatGPT 于 2022 年底发布,席卷了人工智能世界。 作为回应,各行业开始研究大型语言模型以及如何将其纳入其业务中。 然而,在医疗保健、金融和法律行业等敏感应用中,ChatGPT 等公共 API 的隐私一直是一个问题。
然而,最近 Falcon 和 LLaMA 等开源模型的创新使得从开源模型中获得类似 ChatGPT 的质量成为可能。 这些模型的好处是,与 ChatGPT 或 GPT-4 不同,模型权重适用于大多数商业用例。 通过在定制云提供商或本地基础设施上部署这些模型,隐私问题得到缓解——这意味着大型行业现在可以开始认真考虑将生成式人工智能的奇迹融入到他们的产品中!
那么让我们深入了解各种大型语言模型 (LLM) 的经济学!

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
1、GPT-3.5/4 API 成本
ChatGPT API 按使用情况定价,1K 代币的费用为 0.002 美元。 每个令牌大约是一个单词的四分之三,单个请求中的令牌数量是提示 + 生成的输出令牌的总和。 假设您每天处理 1000 个小块文本,每个块都是一页文本,即 500 个单词或 667 个标记,并且输出的长度也是相同的长度(作为上限)。 这相当于每天 0.002 美元/1000x66721000= ~2.6 美元。 一点也不差!
但是,如果您每天处理一百万个此类文档,会发生什么情况? 那么每天就是 2,600 美元,或者每年大约 100 万美元! ChatGPT 从一个很酷的玩具变成了一项价值数百万美元的业务的一项主要开支(因此人们希望它是一项主要收入来源)!
OpenAI 还有其他更强大的模型,例如 ChatGPT 的 16K 上下文版本或更强大的 GPT-4 模型。 这里更大的上下文仅意味着您可以向法学硕士发送更多上下文,并要求其在较长的文档上完成诸如回答问题之类的任务。 以下是基于各种 OpenAI 模型的每天 1K 与 1M 请求的成本:

基于使用情况和 OpenAI 模型的年度成本
如您所见,低使用率的年成本从 1000 美元到 50000 美元不等,具体取决于型号。 或者对于高使用率,每年 100 万美元至 5600 万美元! 对于较低的使用率——我们认为 OpenAI API 模型是有意义的,因为它们的质量和成本效益。
但是,如果您的使用量超过 100 万美元,则即使您确实有多余的钱作为额外的零钱,您也需要认真考虑经济可行性。 有意义的是,如果你手边有多余的零钱,并且看到了LLM在你所在行业的价值,那就是将这些钱花在让你的组织发展成为特定领域LLM的行业领导者上,而不是花钱 纯粹是为了沉没成本。 相反,您可以使用它来自定义现有的开源模型,根据行业特定的数据对其进行微调,从而使您更具竞争力。
处理针对极长或大量文档提出问题的另一种方法是使用检索增强生成 (RAG)(请参阅这篇 Medium 文章)——这基本上相当于将数据存储在矢量数据库中的小块中——并使用矢量相似性 用于检索更有可能包含与您的需求相关的信息的文档块的指标。
另一种可能性是将钱花在 OpenAI API 成本上,但在如何处理 RAG 以及文档与 LLM 之间的复杂接口方面使自己成为创新者,例如这篇文章。
2、开源模型托管成本
如果您决定托管大型语言模型 - 主要成本与托管这些资源密集型 LLM 和每小时成本相关。 根据经验,在 GPU 内存中存储推理所需的 1B 参数 — 32 位浮点精度时需要 4 GB,16 位精度时需要 2 GB。 默认情况下,模型权重以较高的 32 位精度存储,但也有一些技术可以以 16 位(甚至 8 位)精度存储权重,从而将响应质量的损失降至最低。

GPU RAM 成本
因此,对于像 Falcon-7B 或 LLaMA2–7B 这样 16 位精度的 70 亿参数模型,这意味着您需要 14GB 的 GPU RAM。 它们适用于具有 16GB GPU 内存的 NVIDIA T4 GPU。 您可以看到 AWS 等典型云服务提供商的定价如下 - g4 实例均具有单个 T4 GPU,而 12X Large 则具有 4 个 GPU。 基本上,如果您想部署 7B 参数模型,则成本约为 2–3 美元/小时。 正如本博客中提到的 - 存在与发出的请求数量相关的成本,但这些成本通常低于端点成本。 粗略地说,1000 个请求的成本为 0.01 美元,100 万个请求的成本为 10 美元。

Machine Learning Service – Amazon SageMaker Pricing – AWS
较大的开源模型(如 Vicuna-33B 或 LLaMA-2-70b)比较小的模型表现更好 - 因此您可能会考虑部署这些较大的模型。 然而,为了拥有所需的 100-200 GB GPU 内存,这些技术更加昂贵,需要多个 GPU,并且成本约为 20 美元/小时。

https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
以下是更新后的成本,比较了开源模型和 OpenAI GPT 系列模型:

基于使用情况和 OpenAI/云托管模型的年度成本
值得注意的是,虽然上述成本用于内存和计算,但还需要考虑其他与云相关的基础设施的维护,以满足每秒/分钟的网络流量/请求。 其一,您可能需要多个带有负载均衡器的 GPU,以确保即使在大负载期间也能保持低延迟。 您可能需要根据您的使用案例考虑与可用性、减少停机时间、维护和监控相关的额外成本。
3、本地托管成本
本地托管是您希望完全隔离模型并在专用服务器上运行的地方。 为此,您需要购买 NVIDIA A10 或 A100 等高质量 GPU。 目前这些芯片短缺,A10(24GB GPU 内存)售价 3,000 美元,而 A100(40 GB 内存)售价 10-20,000 美元。
然而,有些公司提供像 Lambda Labs 这样的预构建产品,如下所示:
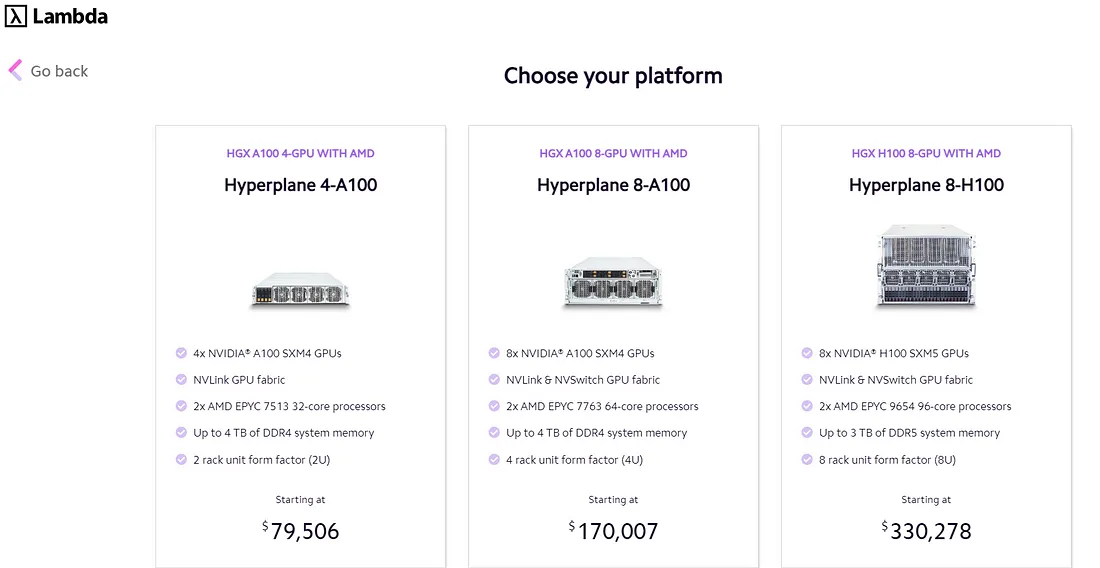
Lambda Labs NVIDIA GPU成本
与云托管模型中相同的延迟、可用性、维护和监控考虑因素也适用于本地托管。 但其中一个区别是,如果您希望在收到更多流量时开始扩展,那么使用云托管提供商意味着您可以虚拟地增加资源(当然要支付更多费用),但您无法在 - 场所,除非您实际购买更多基础设施,当然您现在负责正确设置一切以及维护。
4、结束语
我们已经介绍了 3 种不同的选项来提高部署 LLM 的难度:使用 ChatGPT 等封闭式 LLM API、在私有云实例上托管以及本地托管。 如果您很高兴尝试 LLM,但才刚刚开始探索,我们建议您首先尝试使用 ChatGPT/GPT-4。 一旦您确定LLM是您的出路,您就可以探索其他选择 - 如果您有隐私问题,或者希望在短时间内为数百万客户提供服务,这可能更有意义 - 对于 ChatGPT,尤其是 GPT- 4个都挺贵的。 或者您可能想要开发一个超专业的行业特定的LLM,托管是第一步,之后您需要根据自定义数据微调模型。
我们还没有讨论的最后一个选择是LLM服务提供商,他们可以帮助公司找出在云/本地堆栈上运行的模型。 例如,Snowflake 推出了使用自定义数据训练LLM的服务。 Databricks 提供了类似的解决方案。
原文链接:大模型经济学 - BimAnt