一 Dynamic Resource Allocation(动态资源分配)
了解Shuffle Service之前,我们需要先了解和Shuffle Service有关的另一个特性:动态资源分配。
Spark管理资源有两种方式:静态资源分配和动态资源分配。
- 静态资源分配:spark提交任务前,指定固定的资源,在spark运行任务过程中,一直占用这些资源不释放,job运行结束后才会释放。
- 动态资源分配:Spark 会根据工作负荷,动态地调整作业使用的资源。具体一点来说,当工作负荷增大,Spark 会申请更多的 Executor,当工作负荷变小,则会移除多余的 Executor。这里所指的资源,主要是指 Executor 分配的 CPU/Memory,当然也包括一个 Executor JVM 进程占用的 Disk 和 Network IO 等等,而这里所指的工作负荷是指处于 Pending 和 Running 状态的 Task。
Spark 最早是从 on Yarn 模式支持 Dynamic Resouce Allocation 的特性。至少从 Spark 1.2 开始就已经可用了。
二 External Shuffle Service
与 Dynamic Resouce Allocation 关系紧密的是 External Shuffle Service。
正常来说,Executor 退出有两种情况,一是整个 Spark 任务结束,这是属于正常结束;二是 Executor 遇到 failure,会导致异常退出。在 Dynamic Resouce Allocation 的场景下,由于 Executor 数量会根据工作负荷增加或者移除,当 Spark Job 下游 Stage 需要读取上游 Stage 的状态(一般来说是数据 ShuffleMapStage 的数据),那么由于原来的 Executor 被 如果被移除了,随着 Executor 的退出,磁盘上的临时目录也会被移除。此时相关的数据就需要通过 RDD 的血缘重新计算了,通常来说这是非常耗时。
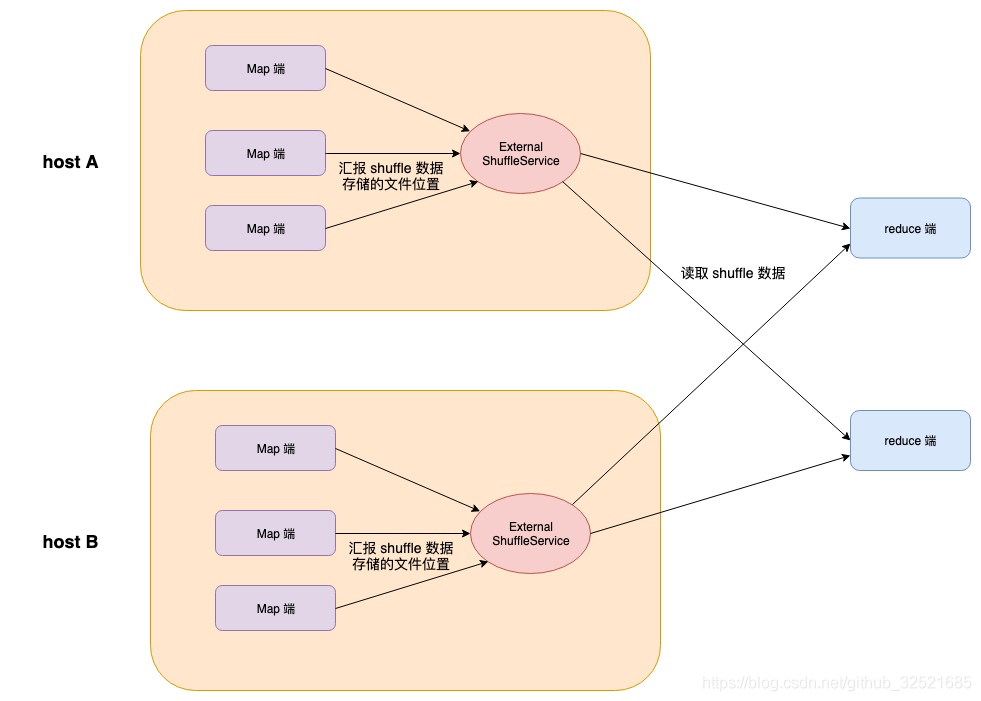
所以 Spark 需要一个 External Shuffle Service 来管理 Shuffle 数据,External Shuffle Service 本质上是一个辅助进程,原来在读取 Shuffle 数据的时候,是每个 Executor 互相读取,现在则是直接读取 External Shuffle Service,也相当于解耦了计算和读取数据的过程。
External Shuffle Service模式如下图所示:
2.1 Shuffle分类
Shuffle是分布式计算框架用来衔接上下游任务的数据重分布过程,在分布式计算中所有涉及到数据上下游衔接的过程都可以理解为shuffle。针对不同的分布式框架,shuffle有几种实现形态:
-
基于文件的pull based shuffle,如MapReduce、Spark。这种shuffle方式多用于类MR的框架,比如MapReduce、Spark,它的特点是具有较高的容错性,适合较大规模的批处理作业。由于实现的是基于文件的shuffle方案,因此失败重跑时只须重跑失败的task、stage,而无须重跑整个job。
-
基于管道的push based shuffle,比如Flink、Storm等。基于管道的push based shuffle的实现方式多用于Flink、Storm等流式框架,或是一些MPP框架,如Presto、Greenplum等,它的特点是具有较低的延迟和较高的性能,但是比较大的问题是由于没有将shuffle数据持久化下来,因此任务的失败会导致整个作业的重跑。
Shuffle是分布式框架里面最为重要的一个环节,shuffle的性能和稳定性直接影响到了整个框架的性能和稳定性,因此改进shuffle框架是非常有必要的。
2.1.1 Spark pull based shuffle
在Spark 3.2之前采用的是 pull based shuffle。
传统的Spark shuffle 是 pull based 模型,详细 shuffle 过程如下:
- Executor启动时向当前机器的 ESS 服务进行注册,同步 shuffle 目录配置等信息。
- Map task 执行完会将计算结果写到本地磁盘, 然后将所有 blocks 信息上报给Driver。
- Reduce task启动时会向 Driver 获取shuffle信息,提取当前 reduce task 需要读取的 blocks信息。Shuffle 请求使用线程池异步向所有 map task 所在的ESS 服务请求 shuffle 数据,reduce task 轮询消费请求结果,执行 reduce 计算。

Pull based shuffle 模型实际只发生一次从ESS服务到 reduce task 的网络传输,设计相对简单,大部分时候表现稳定。但是如果 spark job 非常大(比如 map task 和 reduce task 都是一万个,那么理论上的请求就有一亿个)也会存在如下一些问题:
- **磁盘 I/O 效率低。**虽然 map task 最终会将 shuffle 结果合并成一个文件,但是每个reduce task 在请求 shuffle 数据的时候,一次只会请求一个 block 数据分片;ESS 服务在接收到无序的 shuffle 数据请求时,只能重复通过随机 I/O 方式读取大小在数十 KB 的 block 数据,因此磁盘吞吐会非常低。
- **Shuffle 网络连接可靠性问题。**Spark executor 使用连接池来管理不同机器间的网络连接,对于相同地址的请求,会复用同一个连接。当 map tasks 的 shuffle 结果存储在 S 个 ESS 服务上,reduce tasks 分布在 E 个 executors 上,那么理论上还是会建立 E * S 个网络连接,生产环境中大的Spark job,E 和 S 都可能会超过1000,那么网络出现问题的概率就会比较大。虽然在网络出现问题的时候,即使 Spark 内部通过重试,恢复网络连接,重新获取到了 shuffle 数据,但是这些 task 的执行时间也会变长,从而影响 Spark job 执行时间。
- **Shuffle 数据的本地性不好。**现在的计算机硬件,CPU速度远大于磁盘和网络 I/O,所以对于分布式系统,将计算分配到数据所在机器,可以得到更好的性能提升。但是 pull based shuffle 模型中,reduce task 计算需要的 shuffle 数据分散在不同的节点上,虽然在 Spark 中,fetch shuffle 数据和reduce task 计算可以同时进行,但是reduce task的计算一般还是快于 shuffle 数据的获取过程,从而限制了 reduce task 计算速度。
2.1.2 Spark push based shuffle
虽然Spark已经对 shuffle 过程做了很多优化,但是当集群的规模足够大的时候,shuffle read 仍然会有很多不稳定的情况。Linkedin 向 Spark社区贡献了他们内部基于 push based shuffle 实现的框架 Magnet [2],并在社区 Spark 3.2 版本 [3]实现基本可用。在 pull based shuffle 模型中,每个 reduce task 需要主动 pull 其 map stage 中每个 map task 输出的对应的 reduce 分片数据,但是在 push based shuffle 模型中,所有 map task 都会主动将同一个 reduce task 的数据 push 到同一个 ESS 服务, reduce task 就可以到这个 ESS 服务 fetch 合并好的 shuffle 数据了。
详细 shuffle 流程如下:
-
Executor启动时候向当前机器的 ESS 服务进行注册,同步 shuffle 目录配置等信息。
-
Map 阶段在启动之前,DAG scheduler 会尝试给该Stage 选择一组ESS 服务作为 PushMergerLocations 。
-
Map task 执行完会将计算结果写到本地磁盘, 然后将所有 blocks 信息上报给Driver。最后多了一个判断,如果开启 push based shuffle, map task会启动一个线程池读取本地的 shuffle 数据,将 shuffle block 数据推送到 block 所属的 reduce task 对应的 remote ESS 服务。
-
ESS 服务接收自不同 Executor 推送过来的 shuffle blocks,相同 reduce 的 shuffle 数据会合并到同一文件中,多个 shuffle blocks 会合并成一个 chunk 进行存储,此外还会有 index 文件和 meta 文件来保证数据的可靠性。
-
Reduce 阶段在启动之前会有一个等待,让更多的 map 结果被 push 到 remote ESS,然后 Spark driver 会向所有 PushMergerLocations 的 ESS 发送一个 FinalizeShuffleMerge 请求,ESS 服务收到请求后,停止接收 pushed shuffle 数据,并持久化所有缓存数据到文件中,最后向 Driver 返回最终 merged shuffle blocks 信息。
-
Reduce task启动后获取 shuffle Map Status 元数据和 merged status 元数据。对于已经 merge 好的 shuffle 数据,reduce task 先向ESS 服务请求获取 merged shuffle blocks 的 meta 数据,然后获取对应的 merged shuffle 数据;对于还没有被 merge 的 shuffle 数据,直接从原来的map task 所在节点的 ESS 服务请求读取 shuffle 数据。获取到 shuffle 数据后,继续执行 reduce task。

2.1.3 push based shuffle优点
Push based shuffle模型相比于 pull based shuffle 模型需要额外将 shuffle 数据传输到 remote ESS服务,但是为什么开启Push based shuffle 还会更快呢?
2.1.3.1 push shuffle数据和map tasks同时进行
Spark DAG在计算调度的时候,会将Job划分为stage,然后根据依赖关系逐个调度 stage来执行,其中reduce stage一定会等待map stage的所有task执行完成。因此在 map stage执行完成之前,先执行完 map task 的 executor 就有机会将 shuffle 数据传输到 remote ESS服务,而不影响 executor 同时执行其他 job 的tasks,所以开启push based shuffle并不影响集群的计算吞吐。
作为对比,在MapReduce 框架中有一个类似的优化。当 map tasks 和 reduce tasks 非常多的时候,一般情况下 map tasks 不会同时完成。为了优化 shuffle 过程, MapReduce 框架允许当 map tasks 完成一定的百分比后,就开始提前调度和启动部分 reduce task,这样提前启动的 reduce tasks 在仍有 map tasks 在计算的时候,就可以读取 shuffle 数据了;但是提前启动的这部分 reduce tasks还是依赖于全部map task 的输出,所以要等待所有map tasks执行完成,才能接着完成reduce task,同时还占用着集群的计算资源,所以在MapReduce框架要协调好他们之间的调度,才能更好的优化计算任务。
2.2.3.2 合并Shuffle blocks请求
Reduce shuffle wait 一般主要是因为ESS响应慢导致的。面对一个大的Spark Job时,ESS服务面临的是请求量大,请求时间比较集中,请求的数据量较小的 shuffle 数据请求。比如我们有十万个map task和一万个reduce task, 每个map task shuffle写数据是200M,如不考虑本地读 shuffle 数据的情况,则平均每个reduce 要向ESS服务发送十万个,平均大小为20k的 block请求,如果我们Spark集群有1000台ESS服务机器,则每个ESS服务要在短时间内服务一百万个平均大小为20k的shuffle block read RPC请求。
每个ESS服务使用Netty 线程池来响应这些请求,但受限于机器的CPU和磁盘资源,RPC请求量大的时候,仍会有请求等待Netty 分配线程来响应;对收到的 shuffle 数据请求,ESS服务先通过磁盘读取shuffle index文件,然后读取shuffle data 文件中对应的 shuffle block数据,最后返回结果。如果map task的 shuffle 数据是存储在 SSD磁盘上,磁盘I/O时间相对会快一些;但如果 shuffle 数据存储在HDD磁盘,shuffle block数据又非常小,频繁的随机 I/O 会导致整体磁盘吞吐下降,shuffle 请求延迟变大。
一般情况下,shuffle 服务都是和其他大数据组件部署在一起的。当 shuffle 节点上其他服务占用较多CPU或磁盘I/0资源时,也有可能会导致 ESS 服务响应比平时慢。当集群 ESS 节点较多时,这种情况发生概率更高。
开启push based shuffle 之后,ESS服务会将接收到的同一个 reduce task 的多个 shuffle block 数据合并为文件大小更大的 chunks,reduce 在请求 shuffle 数据的时候,每次返回一个chunk,,大大减轻了网络请求的压力,同时磁盘I/O从随机读取变成顺序读取,I/O效率明显提升,所以ESS服务响应更快更稳定。
2.1.3.3 Reduce本地读shuffle数据
Remote ESS 服务接收到shuffle 数据后,会将同一个 reduce task 的shuffle数据合并成同一个文件。Spark 为了避免 reduce task再通过网络读取该reduce task的 shuffle 数据,当remote ESS 服务合并了超过 REDUCER_PREF_LOCS_FRACTION (默认 20%)的 blocks 时,Spark DAG scheduler 会尽可能的把 reduce task调度到该 romote ESS 服务所在机器上执行,该reduce task的大部分shuffle数据就是本机读取,不再需要网络传输。
三 Magnet
为了解决Shuffle问题,LinkedIn的三位大佬提出、设计并实现了 Magnet,这是一种新颖的基于推送(push-based)的 shuffle 服务。Magnet 项目在今年早些时候作为 VLDB 2020 上发表的工业跟踪论文首次向社区亮相,您可以在此处阅读我们的 VLDB 论文:Magnet: Push-based Shuffle Service for Large-scale Data Processing。
Spark较低版本的shuffle和MapReduce很类似,中间的shuffle结果数据都是all-to-all的传输。也就是,所有的MapTask执行得到结果,然后需要传到所有的ReducerTask上执行。这几位LinkedIn的大佬提出了Magent(磁铁)一种全新的shuffle机制,可以扩展到具有数千个节点的Spark集群,处理PB级的shuffle数据。它的设计考虑到了本地的Spark集群、以及基于云的集群都可以使用。它会将一些小的中间shuffle结果合并到大的block来解决重要的shuffle扩展性的瓶颈。Magnet主要就是合并shuffle块,并且让合并后的block能够让Reducer任务高效读取。Magnet可以显著提高独立于底层硬件的shuffle性能,将LinkedIn生产上的Spark作业端到端运行时间减少近30%。
Spark 3.2实现了Magnet
四 Remote Shuffle Service
目前各大厂商实现了 Remote Shuffle Service,其实就是Spark push based shuffle service的一种变种。将spark shuffle的计算与存储分离,来适配云原生环境下的Spark。
- 使用Push-Style Shuffle代替Pull-Style,减少Mapper的内存压力。
- 支持IO聚合,Shuffle Read的连接数从M*N降到N,同时更改随机读为顺序读。
- 支持两副本机制,降低Fetch Fail概率。
- 支持计算与存储分离架构,可以部署Shuffle Service至特殊硬件环境中,与计算集群分离。
- 解决Spark on Kubernetes时对本地磁盘的依赖。
本质是Spark push based shuffle serviced的一种变种,解决spark on k8s shuffle数据无法本地化问题
故,spark on yarn(spark 3.2+以上版本)无需Remote Shuffle Service.
五 Spark On Yarn ESS和RSS对比测试
ESS(Spark 3.2 External Shuffle Service)和 RSS(celeborn: 阿里开源的 Remote Shuffle service)

采用数仓用户资料加工流程进行验证,通过结果我们可以看出,在Spark on Yarn下 ESS和RSS性能基本相同。因为Spark 3.2的 ESS和 RSS本质上都是基于push based shuffle service的一个变种。
因好多云环境(k8s),无法(或者不允许)本地化数据,此时,ESS无法使用,RSS因此场景而产生。