什么是 ORM 框架? MyBatis 有哪些优缺点?
典型回答:
ORM(Object-Relational Mapping,对象关系映射)框架是一种将关系型数据库中的数据 与 应用程序中的对象进行映射的技术。它通过在程序代码中定义的类和属性来表示数据库表和字段,从而让开发人员能够以面向对象的方式来操作数据库。
ORM 框架的主要目的是减少应用程序与数据库之间的耦合度,提高开发效率,同时保持数据的一致性和安全性。常见的 ORM 框架有 MyBatis、Hibernate、Spring Data JPA 等。
MyBatis 有哪些优缺点?
MyBatis 作为一款轻量级的 ORM 框架,它的优缺点如下:
优点分析:
- **灵活:**MyBatis 允许开发者编写原生的 SQL,提供强大的灵活性,可以针对特定的场景写出高度优化的查询语句,对于复杂的查询和性能调优更友好。
- **易于学习和使用:**相较于 Hibernate 等全自动化 ORM 框架,MyBatis 的学习曲线较为平缓,且由于其半自动化的特性,使得开发者更容易理解和控制整个数据的处理过程。
- **解耦:**通过XML 或者注解的方式将 SQL 和 Java 代码分离,使得代码结构清晰,有利于维护。
- **轻量级:**MyBatis 依赖较少,运行时占用资源相对较小,适合于中小规模的项目或者对性能要求较高的场景。
- **支持动态 SQL:**MyBatis 提供了强大的动态 SQL 标签,可以方便地根据条件拼接不同的 SQL 语句。
缺点分析:
- **手动编写 SQL:**虽然 提供了灵活的 SQL 定制能力,但也意味着需要手动编写大量的 SQL,工作量比较大,尤其当业务逻辑复杂、表结构变更频繁时,SQL 管理成本较高。
- **移植性差:**由于SQL 是写死的,所以不同数据库之间的移植性较差,如果更换数据库类型,可能需要重新调整 SQL 语句。
- **易出错:**因为 SQL 语句手动编写,不小心可能引入 SQL 注入问题,而且在处理多表关联查询时容易出错。
所以,MyBatis 适合那些希望性能和灵活上有更多掌控权,并且愿意付出额为 SQL 编写成本的项目。而强调开发效率,可以使用 Hibernate 或 Spring Data JPA。
MyBatis、Hibernate 和 SpringDataJPA 有什么区别?
典型回答:
MyBatis、Hibernate、Spring Data JPA 都是 ORM 数据库的持久化框架,但它们都有特点,并适用于不同的应用场景,下面分别说明它们的主要区别:
- MyBatis:半自动 ORM 工具
- 特点:
- 需要开发者手动编写 SQL 语句,具有很高的灵活性。
- 通过 XML 或注解方式配置 SQL 查询以及结果映射,对 SQL 执行过程有完全的控制权。
- 轻量级,学习曲线较平缓,适合小型到中型项目,特别对于复杂的查询优化和特定数据库功能支持有较高要求的场景。
- Hibernate:全自动 ORM 框架
- 特点:
- 完全自动化管理对象和数据库表之间的映射关系,可以基于 Java 对象模型自动生成 SQL 语句。
- 支持延迟加载、级联操作、事务管理等功能,提供了丰富的查询 API 。
- 强大的缓存机制,包括一级缓存(Session 级别)和二级缓存(SessionFactory)级别。
- 对于大型项目或者希望快速开发并减少直接处理 SQL 的工作量时有很大的优势,但也可能导致性能瓶颈,尤其是复杂查询方面。
- Spring Data JPA:基于 JPA 规范的抽象实现,提供了一套面向 Repository 接口编程的数据访问模式
- 特点:
- 基于 Java Persistence API(JPA)规范构建,使用 JPA 的标准注解来定义实体和关系映射。
- Spring Data JPA 为数据库访问提供了强大的 repository 支持,允许通过简单声明式的方法命名规则来自动生成基本的 CRUD 操作,同时也能自定义复杂查询方法。
- 内置支持多种 JPA 提供商,如 Hibernate、EclipseLink 等,可以根据项目实际需求切换底层实现。
- 结合 Spring 框架后,能够更好地集成事务管理、依赖注入等功能,提高整体开发效率和代码可读性。
所以,总结来说:
- MyBatis 适合追求灵活、定制化 SQL 和 轻量化方案的项目。
- Hibernate 则适合需要高度自动化和全面 ORM 功能的大中型项目。
- Spring Data JPA 则是在保持一定灵活性的同时,极大提高开发效率和代码简洁度。
MyBatis 中属性名和数据库字段名不一致的解决方案有哪些?
典型回答:
在 MyBatis 中,如何程序中的属性名和字段名不一致,会导致查询和其他操作为 NULL 的情况,而它常见解决方案有以下几个:
- 更改程序中的属性名,或者是数据库的字段名,让二者保持一致。
- 使用结果映射,使用 映射对应的字段。
- 使用 MyBatis Plus 框架中的 @TableField 注解映射二者字段,如以下代码:
public class UserInfo {
@TableField("username")
private String loginname;
}
映射之后,查询或其他操作就不会出现 NULL 问题。
- 如果是查询操作,可以使用 as 重命名字段名,这样查询也就不会为 NULL 了。
说一下 MyBatis 执行流程?
典型回答:
MyBatis 执行流程如下:
- **加载配置文件:**MyBatis 的执行流程从加载配置文件开始。通常,MyBatis 的配置文件是一个 XML 文件,其中包含了数据源配置、SQL 映射配置、连接池配置等信息。
- **构建 SqlSessionFactory:**在配置文件加载后,MyBatis 使用配置信息来构建 SqlSessionFactory 对象。这是 MyBatis 的核心工厂类。SqlSessionFactory 是线程安全的,它用于创建 SqlSession 对象。
- **创建 SqlSession:**应用程序通过 SqlSessionFactory 创建 SqlSession 对象,SqlSession 代表一次数据库会话,它提供了执行 SQL 操作的方法。通常情况下,每个线程都应该有自己的 SqlSession 对象。
- **执行 SQL 查询:**在 SqlSession 中,开发人员可以执行 SQL 查询,这里可以通过两种方式实现:
- **使用 注解 + SQL:**MyBatis 提供了注解加执行 SQL 的实现方式,MyBatis 会为 Mapper 接口生成实现类的代理对象,实际执行 SQL 查询。
- **使用 XML 映射文件:**开发人员可以在 XML 映射文件中定义 SQL 查询语句和映射关系。然后,通过 SqlSession 执行这些 SQL 语句查询,将结果映射到 Java 对象上。
- **SQL 解析和执行:**MyBatis 会解析这些 SQL 查询,执行查询操作,并获取查询结果。
- **结果映射:**MyBatis 使用配置的结果映射,将查询结果映射到 Java 对象上。这包括将数据库列映射到 Java 对象的属性上,并处理关联关系。
- **返回结果:**查询结果被返回给应用程序,开发人员可以对结果进行进一步处理、展示或永久化。
- **关闭 SqlSession:**完成数据库操作后,关闭 SqlSession 释放资源。
总结一下:先加载配置文件,然后构建 SqlSessionFactory 对象,通过 SqlSessionFactory 类构建 SqlSession 对象,然后利用 SqlSession 对象获取 Mapper 接口的实例,进行 SQL 语句执行,根据映射关系配置,返回对应结果给对象上,最后关闭 SqlSession。
${} 和 #{} 有什么区别?什么情况下一定要使用 ${}?
典型回答:
${} 和 #{} 都是 MyBatis 中用来替换参数的特殊标识,其用法如下:
@Delete("delete from remark where rid = #{rid}")
int del(@Param("rid") Integer rid);
但它们二者区别很大,它们的主要区别如下:
- 含义不同:${} 是直接替换(运行时已经替换成具体的 SQL 了),而 #{} 是预处理(运行时只是设置了占位符 “?”,之后再通过声明器(statement)来替换占位符)。
- **使用场景不同:**普通参数使用 #{},如果传递的是 SQL 命令或者 SQL 关键字,需要使用 ${},但使用前一定要做好安全验证。
- **安全性不同:**使用 ${} 存在安全问题,如 SQL 注入,而 #{} 则不存在安全问题。
也就是说,为了防止安全问题,所以大部分场景都要使用 #{} 替换参数,但是如果传递的是 SQL 关键字,例如 order by xxx **asc/desc **时(传递 asc 或 desc),一定要使用 ${},因为它需要在执行时就被替换成关键字,而不能使用占位符替代(占位符不能用于 SQL 关键字,否则会报错)。
在传递 SQL 关键字时,一定要用 ${},但使用之前,一定要过滤和安全检查,以防止 SQL 注入。
什么是 SQL 注入?如何防止 SQL 注入?
典型回答:
SQL 注入即是指应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在应用程序中实现定义好的查询语句的末尾添加额为的 SQL 语句,在管理员不知道的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
也就是所谓的 SQL 注入指的是,使用某个特殊的 SQL 语句,利用 SQL 的执行特性,绕过 SQL 的安全检查,查询到本不该查询的结果。
比如以下代码:
<select id = "doLogin" resultType="com.example.demo.model.User">
select * from userinfo where username = '${name}' and password = '${pwd}'
</select>
sql 注入代码: 'or 1 = '1

从上述结果中可以看出,以上程序在应用程序不知情的情况下实现了非法操作,以此来实现欺骗数据库服务器执行非授权的铭感数据。
如何防止 SQL 注入?
防止 SQL 注入常见方法有以下两种:
- **预编译语句和参数化查询:**使用 PreparedStatement 可以有效防止 SQL 注入,因为它允许你先定义 SQL 语句的结果,然后将变量作为参数传入,数据库驱动程序就会自动处理这些参数的安全性,确保它们不会干扰 SQL 语句的结构,如下代码所示:
String sql = "select * from users where username = ? and password = ?";
PreparedStatement pstmt = connection.prepareStatement(sql);
pstmt.setString(1,UserInputUsername);
pstmt.setString(2,UserInputUsername);
ResultSet rs = pstmt.executeQuery();
- **输入验证和过滤:**对用户书输入的信息进行验证和过滤,确保其符合预期的类型和格式。
MyBatis 中如何实现分页?
典型回答:
MyBatis 中分页有以下两种方式:
- **物理分页:**物理分页是通过 SQL 查询语句,在数据库引擎层面实现的,如 MySQL 的 limit 语法进行分页。
- **逻辑分页:**逻辑分页是应用程序层面的分页,通常是先查询出所有符合条件的数据,然后在内存中对数据进行分页操作。
① 物理分页:
- 使用 limit 分页
- 物理分页可以直接在 XML 中拼接 SQL 进行分页:
<select id = "getUserList" resultType = "User">
select * from user
limit #{limit} offset #{offset}
</select>
- 使用 PageHelper 插件实现分页
- 物理分页还可以使用 PageHelper 插件来实现,分页插件的使用文档:
- https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md
- 它的关键实现代码:
PageHelper.startPage(1,10);
List<User> list = userMapper.selectIf(1);
PageHelper 实现原理解析
PageHelper 底层使用了 MyBatis 的拦截器(Interceptor)机制,在 MyBatis 进行查询时,拦截并对 SQL 语句进行动态修改(添加 limit 等分页查询操作),之后查询数据库、并对查询结果进行封装,包装成分页对象(如包含数据列表、总记录数、总页数等信息的分页对象),最后将这个分页对象返回给客户端。
② 逻辑分页:
MyBatis 自带的 RowBounds 进行分页就是逻辑分页,它是一次性查询很多语句,然后在数据中再进行检索,实现代码如下:
RowBounds rowBounds = new RowBounds(offset,limit);
List<User> users = sqlSession.selectList("getUserList",null,rowBounds);
其中 offset 为起始行偏移量,limit 是每页数据量,虽然只设置两个值,但是使用 RowBounds 时,它会一次性查询多条数据,然后在内存中进行 offset 和 limit 筛选,最后在返回符合结果的数据。
MyBatisPlus 是如何实现分页的?
典型回答:
MyBatis Plus 中实现分页功能,只需要以下两步
- 配置 MyBatis Plus 中的分页拦截器。
- 使用 Page 对象使用分页查询。
具体操作如下:
① 配置分页拦截器
@Configuration
public class PageConfig{
@Bean
public MyBatisPlusInterceptor mybatisPlusInterceptor(){
MyBatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 将 MP 里面的分页插件设置 MP
interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return interceptor;
}
}
因为 MP 内置了 PaginationInnerInterceptor 插件,所以可以在拦截器此处直接添加 new PaginationInnerInterceptor() 的代码。
分页插件支持的数据有以下这些:

更过内容,可以参考 MP 官网连接:
https://baomidou.com/pages/97710a/#paginationinnerinterceptor
② 使用 Page 对象实现分页
@RequestMapping("/getpage")
public Object getPage(Integer pageIndex){
// 分页对象
Page page = new Page(pageIndex,10);
Page<User> result = userService.page(page);
retuern result;
}
MyBatis Plus 分页功能的底层是如何实现的?
MyBatis Plus 分页功能底层是通过拦截器来实现的,实现 MyBatis Plus 的第一步就是添加拦截器,这个拦截器就是拦截 SQL 的请求,拦截之后会对 SQL 进行动态修改(添加 limit 等分页查询操作),之后查询数据库,然后对结果进行封装,包装成分页对象,最后再将分页对象返回给客户端。
什么是动态 SQL?
典型回答:
动态 SQL 是动态构建查询语句的机制,允许在 SQL 查询中根据不同的条件动态生成不同的 SQL 语句,以满足不同的查询需求。
动态 SQL 可以包含 条件判断、循环、参数替换等功能,使得 SQL 查询更具灵活性和可重用性。
在 MyBatis 中,动态 SQL 的主要元素:if、choose/when/otherwise、trim、where、set、foreach 等
- 标签: 元素允许在 SQL 查询中添加条件判断。它的工作方式类似于 Java 中的 if 语句,根据条件决定是否包含某部分 SQL 代码。示例如下:
<select id = "selectUsers" resultType = "User">
select * from users
where 1 = 1
<if test = "name != null">
and name = #{name}
</if>
</select>
- 、、标签: 元素用于在多个条件中选择一个满足的分支,类似于 Java 中的 switch 语句。 元素用于定义每个分支,而 元素用于定义默认分支。示例如下:
<select id = "selectUsers" resultType = "User">
select * from users
<choose>
<when test = "name != null">
and name = #{name}
</when>
<when test = "age != null">
and age = #{age}
</when>
<otherwise>
and status = 'active'
</otherwise>
</choose>
</select>
- 标签: 元素用于处理 SQL 查询中的空白字符,通常用于移除或添加 SQL 查询语句中的条件。示例如下:
<select id = "selectUsers" resultType = "User">
select * from users
where
<trim prefix = "(" suffix =")" prefixOverrides = "and">
<if test = "name != null">
and name = #{name}
</if>
<if test = "age != null">
and age = #{age}
</if>
</trim>
</select>
- 元素: 元素用于循环迭代集合,并生成多个 SQL 查询参数,常用于构建 IN 子句。示例如下:
<select id = "selectUsers" resultType = "User">
select * from users
where id in
<foreach collection = "idList" item = "id", open = "(" separator = "," close=")">
#{id}
</foreach>
</select>
这些动态 SQL 构建方式使得编写 能够根据不同条件动态生成 SQL 查询的代码 变得更加灵活和可维护。它们是 MyBatis 中的关键功能,用于处理各种复杂的查询需求。
更多详情文档,可以参考官方文档:https://mybatis.org/mybatis-3/dynamic-sql.html
说一下 MyBatis 的二级缓存?
典型回答:
MyBatis 二级缓存是用来提高 MyBatis 查询数据库的性能,和减少数据库访问的机制。
顾名思义,MyBatis 二级缓存中总共有两个缓存机制:
- 一级缓存:SqlSession 级别的,MyBatis 自带的缓存功能,并且无法关闭。因此当有两个 SqlSession 访问相同的 SQL 时,一级缓存也不会生效,也需要查询两次数据库。在一个 Service 调用两个相同的 mapper 方法时,依然时查询两次,因为它会创建两个 SqlSession 进行查询(为了提高性能)。
- 同一个 SqlSession 中共享一级缓存
- 二级缓存:Mapper级别,只要是同一个 Mapper ,无论使用多少个 SqlSession 操作,数据都是共享的。也就是说一个 SessionFactory 下的多个 Session 之间共享缓存,它的作用范围更大、生命周期更长,也可以减少数据库的查询次数,提高系统性能。但二级缓存默认是关闭的,需要手动开始。
如何开启 MyBatis 的二级?
典型回答:
二级缓存默认是不开启的,手动开启 MyBatis 二级缓存步骤如下:
- 在 mapper.xml 中添加 标签。
- 在需要缓存的标签上添加 useCache=“true”(新版本此步骤可以忽略,但为了兼容老版本,建议保留此项配置)
完整代码如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<mapper namespace="com.mybatis.demo.mapper.StudentMapper">
<cache/>
<select id="getStudentCount" resultType="Integer" useCache="true">
select count(*) from student
</select>
</mapper>
编写单元测试代码如下:
@SpringBootTest
class StudentMapperTest{
@Autowired
private StudentMapper studentMapper;
@Test
void getStudentCount(){
int count = studentMapper.getStudentCount();
System.out.println("查询结果:" + count);
int count2 = studentMapper.getStudentCount();
System.out.println("查询结果:" + coun2);
}
}
执行以上单元测试的执行结果如下:
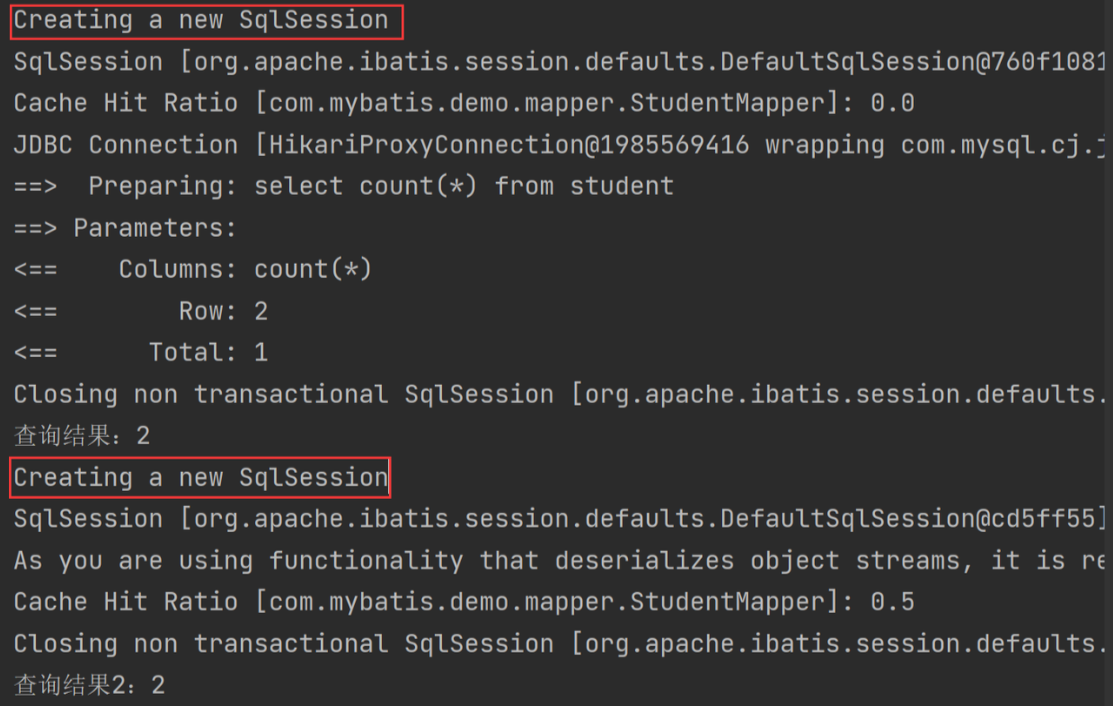
从以上结果可以看出,两次查询虽然使用了不同的 SqlSession,但第二次查询使用了缓存,并未查询数据库。
为什么 MyBatis 二级缓存默认不开启?
典型回答:
MyBatis 默认不开启二级缓存原因有以下几个:
- **分布式环境下数据一致性问题:**在一个分布式环境下,多个应用实例共享同一个数据库,如果开启了二级缓存,其中一个实例对数据库进行了更新操作,而其他实例的缓存仍然保持着旧数据,就到导致数据不一致的问题。
- **业务场景问题:**二级缓存适用于 读多写少 、数据相对静态的场景,在许多实际项目中,这类场景并不常见。因此,默认关闭二级缓存可以确保框架在多数情况下都能够灵活应对不同需求。
- **内存占用问题:**开启二级缓存后,缓存的数据占一定内存空间。如果没有合适的策略来管理缓存,可能会导致内存占用过多的问题。
- **复杂性和配置问题:**二级缓存的配置需要考虑很多因素,包括缓存的刷新策略、缓存的清理策略等等,这增加了配置的复杂性和可能引入配置错误的风险。
- **缓存设计相对简单:**MyBatis 中的缓存设计相对比较简单,例如 MyBatis 缓存的数据默认只能保存 1024个,且缓存淘汰策略比较简单,只有几种策略可供选择。
总结而言,就是分布式场景下可能会造成数据不一致问题,并且业务场景 下可能不适合等等。
MyBatis 有几种缓存淘汰策略? 如何设置缓存淘汰策略?
典型回答:
缓存淘汰策略也叫做缓存清除策略,是当缓存数据达到最大值时,如何清除(淘汰)缓存的策略。
MyBatis 二级缓存默认写法就是(在映射文件中添加一行)
<cache/>
上述标签的效果有以下几个:
- 映射语句文件中的所有 select 语句的结果都会被缓存,映射语句文件中所有 insert、update、delete 语句都会刷新缓存。
- 缓存会使用最近最少使用算法(LRU)来清除不需要的缓存。
- 缓存会保存列表或对象的个数最多是 1024个
- 缓存会被视为 读/写 缓存,这意味获取的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
这些属性可以通过 cache 元素的属性来修改,例如下:
<cache eviction="FIFO" flushInterval="60000" size="1024"/>
这里更高级的配置创建了一个 FIFO 缓存,每隔 60s 刷新(自动清空二级缓存),最多可以存储结果对象或列表 1024 个,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
MyBatis 有哪些缓存淘汰策略
- **LRU 最近最少使用:**移除最长时间不用的对象。
- **FIFO 先进先出:**按照对象进入的缓存的顺序来移除。
- **SOFT 软引用:**基于垃圾回收器状态和软引用规则移除对象。
- **WEAK 弱引用:**更积极地基于垃圾回收器状态和弱引用规则移除对象。
默认的缓存淘汰策略是 LRU
flushInterval(刷新间隔)默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。当设置 flushInterval后,MyBatis 会周期性地检査是否需要刷新二级缓存,避免数据过期或脏数据的问题。当超过设定的时间间隔时,MyBatis 会自动清空二级缓存,下次查询时会重新加载最新的数据到缓存中。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
MyBatis 中使用了哪些设计模式?
典型回答:
- 工厂模式:
- 工厂模式就是提供一个工厂类,只需要这个类就能创建实例,而不需要我们关心内部的实现。
- MyBatis 中典型代表 SqlSessionFactory。SqlSession 是 MyBatis 中重要的 Java 接口,可以通过该接口操作 SQL 命令、获取映射器示例和管理事务,而 SqlSessionFactory 就是用来产生 SqlSession 对象的。
- 建造者模式:
- 将一个复杂对象的构建 与 它的表示分离,使得同样的构造过程创建不同的表示。
- MyBatis 中典型代表 SqlSessionFactoryBuilder。普通对象都是通过 new 关键字直接创建的,但是创建对象需要构造参数很多,且不能保证每个参数都是正确的,所以需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建逻辑交给构建类,这样可以简化对象的构造。
- 链式调用就是建造者模式的一种常见表现形式。
- 单例模式:
- 单例模式,此模式保证某个类在运行期间,只有一个实例对外提供服务,而这个类就是单例类。
- MyBatis 中典型代表 ErrorContext(线程级别的单例),每个线程都有一个此对象的单例,用于记录该线程的执行环境的错误信息。
- 适配器模式:
- 将一个不兼容的接口转换成另一个可以兼容的接口。
- MyBatis 中日志模块适配了很多日志类型
- SLF4J
- Apache Commons Logging
- Log4J2
- Log4J
- JDK logging
- 代理模式:
- 给某一个对象提供一个代理对象,并由代理对象控制原对象的调用。
- MyBatis 中典型代表就是 MapperProxyFactory,MapperProxyFactory 的 newInstance() 方法就是生成一个具体的代理来实现某个功能。
- 模板方法模式:
- 模板方法模式:定义个操作算法的骨架,而将一些具体的实现步骤延迟到子类中去实现,使得子类可以不改变一个算法的结构重新定义算法特定步骤。
- MyBatis 中典型代表是 BaseExecutor,在 MyBatis 中 BaseExecutor 实现大部分 SQL 执行的逻辑。
- 装饰器模式:
- 装饰器模式允许向一个现有的对象添加新的功能,同时不改变其结构,这种类型设计模式属于结构型模式,它是作为现有类的一个包装。
- MyBatis 中典型代表就是 Cache,可以添加不同功能。