GLIP
- 核心思想
- GLIP 对比 BLIP、BLIP-2、CLIP
- 主要问题: 如何构建一个能够在不同任务和领域中以零样本或少样本方式无缝迁移的预训练模型?
- 统一的短语定位损失
- 语言意识的深度融合
- 预训练数据类型的结合
- 语义丰富数据的扩展
- 零样本和少样本迁移学习
- 效果
论文:https://arxiv.org/pdf/2112.03857.pdf
代码:https://github.com/microsoft/GLIP
核心思想
问题: 在现有的视觉识别任务中,模型通常是针对一组固定的对象类别进行训练的,这限制了它们在现实世界中的应用,因为遇到新的视觉概念时,需要额外的标注数据来进行泛化。
而且,要想理解图片中的细节(如对象检测、分割、姿态估计等),需要对象级别的、富含语义的视觉表征。
方法: GLIP尝试解决上述问题,通过以下步骤:
- 统一对象检测和短语定位: 将对象检测任务视为一种无上下文的短语定位任务,而短语定位可以看作是一种有上下文的对象检测任务。这样,两者可以在同一个框架内得到改进。
假设我们有一个图片,其中包含了一只猫和一辆车。
在传统的对象检测任务中,模型需要识别出图片中所有的对象(例如,猫和车),并为它们各自绘制一个边界框。
在短语定位任务中,如果给定一个描述性短语(如“黑色的猫”),模型需要找到图片中与这个短语对应的具体区域。
GLIP将这两个任务统一起来:它不仅学习如何识别和定位图片中的对象,还学习如何根据文本描述来精确地定位这些对象。
这意味着,如果输入是一张含猫和车的图片以及文本提示“黑色的猫”,GLIP能够理解这个提示,并准确地标出图片中黑色猫的位置。
- 预训练: 使用大量的图片-文本对(27M,包括3M人工标注和24M网络抓取)进行预训练。这些数据不仅包括了丰富的语义信息,还可以自动生成定位框(grounding boxes),从而扩大了学习的概念范围。
为了让GLIP学会这些技能,研究者使用了27M的图片-文本对进行预训练。
这其中包括3M是人工标注的高质量数据,24M是从网上抓取的图片和相应的描述文本。
通过这些数据,GLIP学习到了丰富的视觉概念和语义信息,比如什么是“猫”,它们长什么样,常出现在哪些场景中,以及如何根据不同的描述(例如“黑色的猫”)来识别和定位具体的对象。
- 转移学习: 预训练后的GLIP模型展示了在各种对象级别识别任务上的零样本和少样本转移能力,即使在模型预训练时没有见过特定图片,也能表现出色。
预训练完成后,GLIP能够在没有额外标注数据的情况下,直接应用到新的对象检测任务上。
比如,当GLIP遇到一个它在预训练数据中没有直接见过的新图片,即使这张图片中的对象是新的或者以新的方式出现,GLIP也能利用它从预训练中学到的知识,来识别和定位图片中的对象。
例如,如果在预训练数据中GLIP学到了如何识别各种各样的猫和车,当它看到一个全新的图片,图片中有一只特别的猫种或者是一种罕见的车型,GLIP仍然能够凭借之前学到的知识来识别和定位这些对象。
并且,如果给GLIP一个具体的描述,比如“在草地上的白色猫”,它也能够理解这个描述,并在图片中找到对应的猫。
结果:
- 在COCO和LVIS数据集上,GLIP模型在零样本设置下表现优异,超过了许多有监督的基准模型。
- 经过COCO数据集微调后,GLIP在验证集和测试集上的表现超过了之前的最佳模型。
- 在13个下游对象检测任务中,即使只用一个样本进行训练,GLIP也能与完全监督的模型竞争。
结论: GLIP通过统一对象检测和短语定位任务,并利用大量的图片-文本对进行预训练,成功学习了丰富的、可转移的对象级视觉表征,表现出强大的转移学习能力。
GLIP 对比 BLIP、BLIP-2、CLIP
BLIP:跨越视觉-语言界限:BLIP的多任务精细处理策略
BLIP-2:低计算视觉-语言预训练大模型
CLIP:对比预训练 + 文字图像相似度:离奇调查,如何训练视觉大模型?
GLIP(Grounded Language-Image Pre-training):
- 目标:学习对象级别、语言感知的、语义丰富的视觉表征。
- 方法:GLIP结合了对象检测和短语定位(phrase grounding)任务,通过预训练来统一这两种任务。
- 特点:
- 利用检测和定位数据改进这两个任务,并引导出好的定位模型。
- 利用大量图像-文本对通过自训练方式生成定位框,使学习到的表征丰富多样。
- 性能:在零样本和少样本迁移任务中展示了强大的性能,如直接在COCO和LVIS数据集上评估,没有在预训练中看到任何COCO图像,GLIP也实现了超过许多监督基线的性能。
结论:
GLIP强调在对象级别进行语言感知和语义丰富的视觉表征学习,并且特别强调短语定位任务的效率和可扩展性。
与此相比,BLIP和BLIP-2侧重于从预训练的模型启动,以减少训练时的计算成本并提高性能。
CLIP则更注重在图像级别学习视觉表征,并利用大量的图像-文本对进行对比学习,以实现强大的零样本和少样本迁移能力。
以图像识别任务为例,比较GLIP、BLIP/BLIP-2和CLIP的方法和优势:
GLIP的例子:
假设我们要识别一张图片中的特定物体(例如,一只戴帽子的猫),并且这张图片附带了一句描述(例如,“一只戴着红色帽子的猫坐在桌子上”)。
GLIP通过短语定位任务学习到的对象级别、语言感知的视觉表征能够准确识别出图片中“戴着红色帽子的猫”的位置,即使这个特定的短语在训练数据中从未出现过。
BLIP/BLIP-2的例子:
在相同的任务中,BLIP或BLIP-2可能会使用从大量图像-文本对中预训练的模型来识别图中的猫。
它们不一定能像GLIP那样精细定位帽子,但是它们在预训练阶段计算成本更低,并且能够利用现成的预训练模型(如冻结的图像编码器和语言模型)来提升性能。
CLIP的例子:
对于CLIP来说,虽然可能无法具体识别“戴着红色帽子的猫”,但它可以识别出图片中的猫,因为它在图像级别上学习了丰富的视觉表征。
通过分析大量图像-文本对,CLIP模型学会了将图像与其相关的文本概念关联起来,因此在没有具体的对象检测训练的情况下,它可能已经理解了“猫”这一概念,并且能够在零样本或少样本设置中将这种理解转移到识别任务上。
主要问题: 如何构建一个能够在不同任务和领域中以零样本或少样本方式无缝迁移的预训练模型?
在GLIP研究中,面临的主要挑战是创建一个能够轻松迁移到各种任务和领域的预训练模型,特别是在这些领域和任务中,模型可能没有接触过足够的样本(即零样本或少样本情况)。
统一的短语定位损失
- 子问题: 如何让模型理解语言中的指令,并将其定位到图像中的具体区域?
- 子解法: 统一的短语定位损失(Unified Grounding Loss)。
- 这种损失函数结合了对象检测的要素,把对象分类转变为短语定位问题,从而让模型学习如何将文本中的短语与图像中的区域相匹配。
- 之所以使用此解法,是因为对象检测的传统方法通常局限于预定义的类别集,而短语定位允许模型对任何在文本中提及的对象进行识别,使其在应对开放词汇检测时更加灵活。
使用统一的短语定位损失,GLIP模型能够理解“黑色短毛猫”这样的语言描述,并将其定位到图片中对应的区域,即使这种猫的类别在训练数据中未被明确定义过。
语言意识的深度融合
- 子问题: 如何提高模型在细粒度上对图像的理解,让其不仅识别图像中的对象,还能理解这些对象的语言描述?
- 子解法: 语言感知深度融合(Language-Aware Deep Fusion)。
- 通过在图像编码器和语言编码器之间进行深度融合,模型能够学习到更丰富的语言感知视觉特征,提升模型的短语定位性能。
- 之所以使用此解法,是因为仅在最后一层进行视觉语言融合(如CLIP所做)可能不足以学习到高质量的语言感知视觉特征,而深度融合可以让模型在整个编码过程中同时考虑视觉和语言信息。
通过语言感知深度融合,该模型可以进一步理解“黑色短毛猫在睡觉”的复杂描述 有更多细节,并识别出图像中相对应的睡觉姿势和猫的特征。
预训练数据类型的结合
- 子问题: 如何结合不同类型的数据来提升模型的语义丰富度和迁移能力?
- 子解法: 结合检测和短语定位数据进行预训练。
- 通过同时使用对象检测数据和短语定位数据进行预训练,模型可以学习到更丰富的语义信息,并改善对不同对象类别的检测能力。
- 之所以使用此解法,是因为短语定位数据在语义上比传统的对象检测数据更为丰富,能够提供更多的上下文信息,从而帮助模型更好地学习到不同对象的视觉特征。
预训练阶段结合了对象检测数据(比如猫的图片)和短语定位数据(比如“黑色短毛猫”的文本描述与相应图片)。
这种数据的结合让模型能够理解和学习更多关于对象和场景的细节。
语义丰富数据的扩展
- 子问题: 如何扩展对象检测的概念池,并且使其涵盖更广泛的视觉概念?
- 子解法: 利用大规模图像-文本配对数据。
- 使用已经预训练好的GLIP模型(教师模型)来自动为大量网络抓取的图像-文本对生成定位框(grounding boxes),以此来扩展学习数据集。
- 之所以使用此解法,是因为现有的人工标注数据在视觉概念的覆盖上成本高且有限,而大规模的图像-文本数据可以提供更为丰富的语义信息。
使用大量的图像-文本对来扩展模型的知识库,这包括从互联网抓取的各种图片和它们的描述。
这使得模型能够识别和理解更多种类的场景和对象,即使是它之前没有直接学习过的。
零样本和少样本迁移学习
- 子问题: 如何构建一个预训练模型,使其能够无缝迁移到不同的任务和领域?
- 子解法: 利用GLIP进行迁移学习。
- 通过在短语定位的基础上对对象检测任务进行重新构想,构建了一个能够适用于各种任务和领域的预训练模型。
- 之所以使用此解法,是因为短语定位与对象检测在概念上具有很大的相似性,GLIP通过这种重新构想使得模型能够在零样本或少样本的情况下进行有效迁移。
上传了一张新的照片,“在雪地上的白色长毛猫”,尽管这是一个新的场景,模型依旧能够准确识别出来。
效果
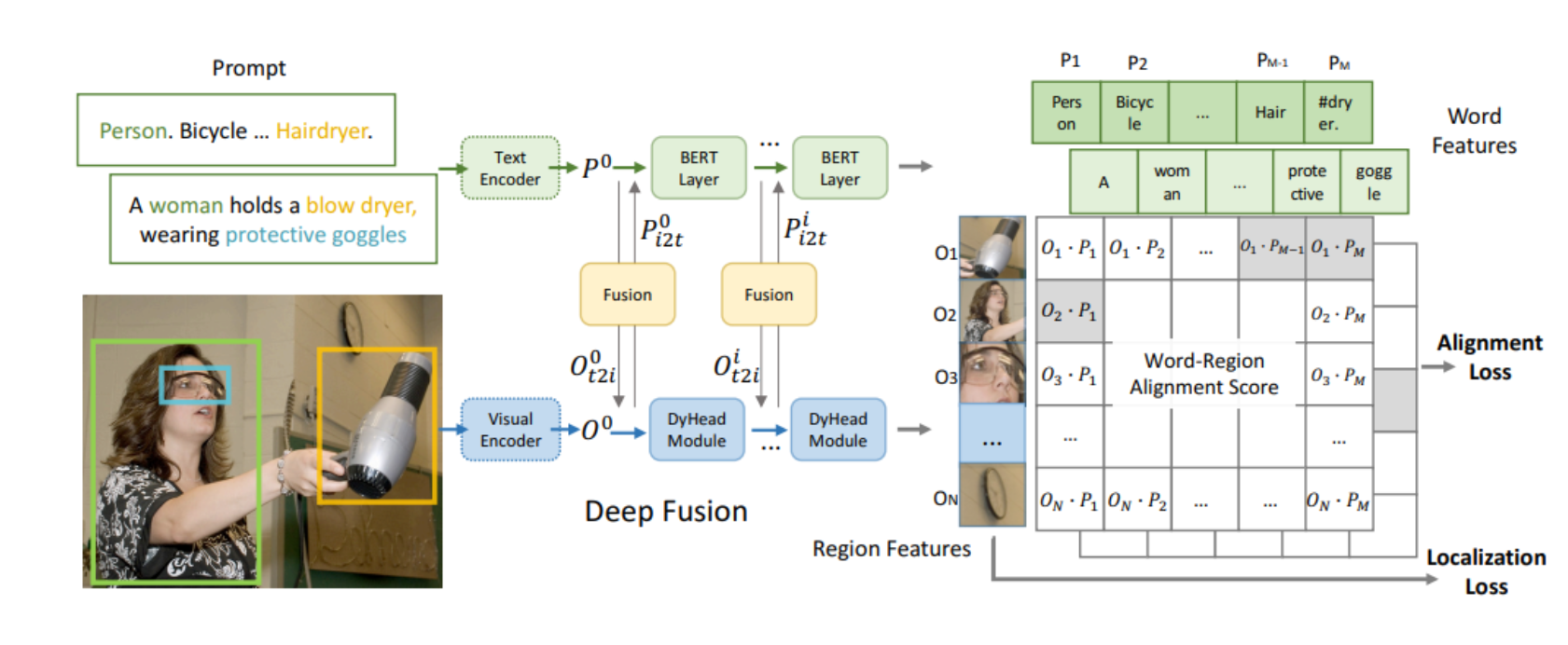
GLIP将检测任务重新构想为短语定位任务,通过联合训练图像编码器和语言编码器来预测区域和单词的正确配对。
上图一个女性持有吹风机并戴着防护眼镜的示例,同时提供了文本提示“Person. Bicycle … Hairdryer.”,模型通过深度融合技术学习语言感知的视觉表征。
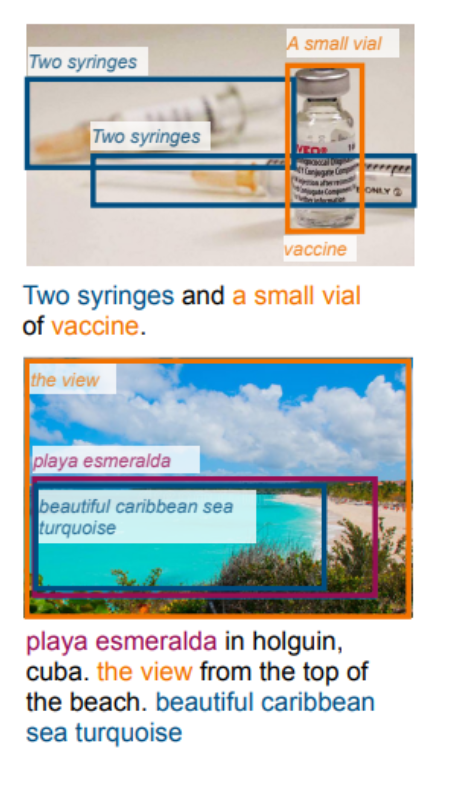
GLIP在预测定位中的能力,它能够定位图像中的稀有实体、具有属性的短语,甚至是抽象词汇。
上图 两个例子分别展示了模型如何识别和定位“两个注射器和一个小瓶疫苗”以及一个海滩景色,如“playa esmeralda in holguin, cuba. the view from the top of the beach. beautiful caribbean sea turquoise”。
说明模型不仅可以识别具体的物体,还能理解和定位与属性相关的短语和抽象概念。
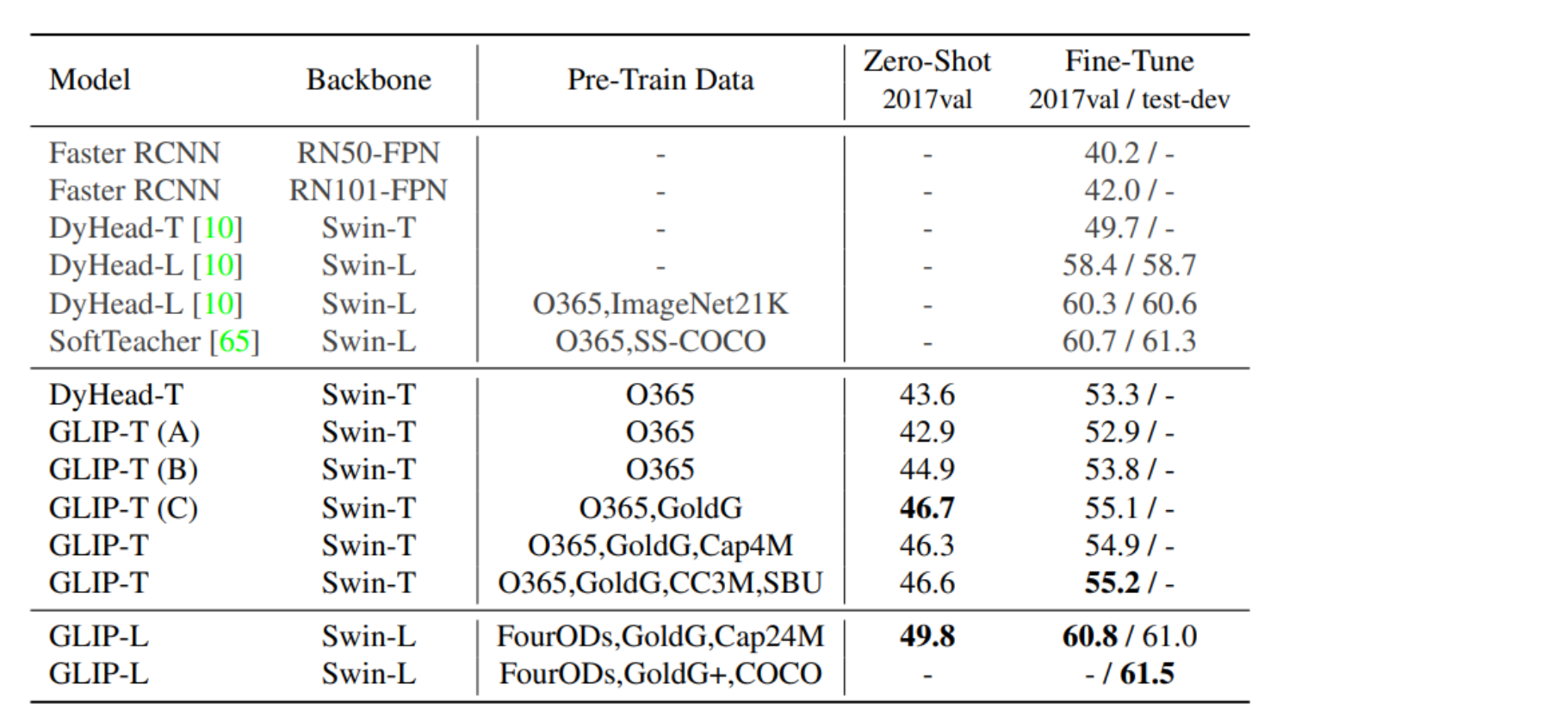
GLIP用于目标检测的好处:
- 强大的泛化能力:GLIP能在没有直接经过特定数据集训练的情况下进行有效的目标检测。
- 优秀的零样本学习性能:GLIP能识别训练数据中未包含的新类别。
- 在处理稀有类别上的优势:GLIP在LVIS数据集上的表现显示,它在处理少见或稀有对象时的识别能力优于传统模型。
- 短语定位的精准性:在Flickr30K数据集上,GLIP展示了高精度的短语定位能力,能够准确地将文本描述与图像中的具体区域相匹配。
- 微调后的性能提升:在COCO数据集上的微调表现优于当前最佳模型,表明其在特定任务上的适应性和提升潜力。
这些表现说明GLIP不仅能够适应新的和未知的目标检测任务,而且其性能可通过针对性训练进一步提升。












![BUUCTF-Real-ThinkPHP]5.0.23-Rce](https://img-blog.csdnimg.cn/direct/b9e802ae77ed4893b4b9746c72e589b3.png)