参数化教程
原文:
译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Mario Lezcano
注意
点击这里下载完整示例代码
在本教程中,您将学习如何实现并使用此模式来对模型进行约束。这样做就像编写自己的nn.Module一样容易。
对深度学习模型进行正则化是一项令人惊讶的挑战。传统技术,如惩罚方法,通常在应用于深度模型时效果不佳,因为被优化的函数的复杂性。当处理病态模型时,这一点尤为棘手。这些模型的示例包括在长序列上训练的 RNN 和 GAN。近年来已经提出了许多技术来对这些模型进行正则化并改善它们的收敛性。对于循环模型,已经提出控制 RNN 的循环核的奇异值以使其具有良好条件性。例如,可以通过使循环核正交来实现这一点。另一种正则化循环模型的方法是通过“权重归一化”。该方法建议将参数的学习与其范数的学习分离。为此,将参数除以其Frobenius 范数,并学习一个编码其范数的单独参数。类似的正则化方法也适用于以“谱归一化”命名的 GAN。该方法通过将网络的参数除以其谱范数而不是其 Frobenius 范数来控制网络的 Lipschitz 常数。
所有这些方法都有一个共同的模式:它们在使用参数之前以适当的方式转换参数。在第一种情况下,它们通过使用将矩阵映射到正交矩阵的函数使其正交。在权重和谱归一化的情况下,它们通过将原始参数除以其范数来实现。
更一般地,所有这些示例都使用一个函数在参数上添加额外的结构。换句话说,它们使用一个函数来约束参数。
它没有将层和参数化分开。如果参数化更加困难,我们将不得不为要在其中使用它的每个层重新编写其代码。
要求:torch>=1.9.0
参数化简介
假设我们想要一个具有对称权重的正方形线性层,即具有权重X,使得X = Xᵀ。一种方法是将矩阵的上三角部分复制到其下三角部分
import torch
import torch.nn as nn
import torch.nn.utils.parametrize as parametrize
def symmetric(X):
return X.triu() + X.triu(1).transpose(-1, -2)
X = torch.rand(3, 3)
A = symmetric(X)
assert torch.allclose(A, A.T) # A is symmetric
print(A) # Quick visual check
然后我们可以使用这个想法来实现具有对称权重的线性层
class LinearSymmetric(nn.Module):
def __init__(self, n_features):
super().__init__()
self.weight = nn.Parameter(torch.rand(n_features, n_features))
def forward(self, x):
A = symmetric(self.weight)
return x @ A
然后可以将该层用作常规线性层
layer = LinearSymmetric(3)
out = layer(torch.rand(8, 3))
尽管这种实现是正确且独立的,但存在一些问题:
-
它重新实现了该层。我们必须将线性层实现为
x @ A。对于线性层来说,这并不是非常困难,但想象一下必须重新实现 CNN 或 Transformer… -
手动实现参数化
-
每次使用该层时都会重新计算参数化。如果在前向传递期间多次使用该层(想象一下 RNN 的循环核),它将在每次调用该层时计算相同的
A。
原文:pytorch.org/tutorials/intermediate/parametrizations.html
参数化可以解决所有这些问题以及其他问题。
让我们从使用torch.nn.utils.parametrize重新实现上面的代码开始。我们唯一需要做的就是将参数化编写为常规的nn.Module
class Symmetric(nn.Module):
def forward(self, X):
return X.triu() + X.triu(1).transpose(-1, -2)
这就是我们需要做的全部。一旦我们有了这个,我们可以通过以下方式将任何常规层转换为对称层
layer = nn.Linear(3, 3)
parametrize.register_parametrization(layer, "weight", Symmetric())
现在,线性层的矩阵是对称的
A = layer.weight
assert torch.allclose(A, A.T) # A is symmetric
print(A) # Quick visual check
我们可以对任何其他层执行相同的操作。例如,我们可以创建一个具有斜对称核的 CNN。我们使用类似的参数化,将上三角部分的符号反转复制到下三角部分
class Skew(nn.Module):
def forward(self, X):
A = X.triu(1)
return A - A.transpose(-1, -2)
cnn = nn.Conv2d(in_channels=5, out_channels=8, kernel_size=3)
parametrize.register_parametrization(cnn, "weight", Skew())
# Print a few kernels
print(cnn.weight[0, 1])
print(cnn.weight[2, 2])
检查参数化模块
当一个模块被参数化时,我们发现模块以三种方式发生了变化:
-
model.weight现在是一个属性 -
它有一个新的
module.parametrizations属性 -
未参数化的权重已移动到
module.parametrizations.weight.original
在对weight进行参数化之后,layer.weight被转换为Python 属性。每当我们请求layer.weight时,此属性会计算parametrization(weight),就像我们在上面的LinearSymmetric实现中所做的那样。
注册的参数化存储在模块内的parametrizations属性下。
layer = nn.Linear(3, 3)
print(f"Unparametrized:\n{layer}")
parametrize.register_parametrization(layer, "weight", Symmetric())
print(f"\nParametrized:\n{layer}")
这个parametrizations属性是一个nn.ModuleDict,可以像这样访问
print(layer.parametrizations)
print(layer.parametrizations.weight)
这个nn.ModuleDict的每个元素都是一个ParametrizationList,它的行为类似于nn.Sequential。这个列表将允许我们在一个权重上连接参数化。由于这是一个列表,我们可以通过索引访问参数化。这就是我们的Symmetric参数化所在的地方
print(layer.parametrizations.weight[0])
我们注意到的另一件事是,如果我们打印参数,我们会看到参数weight已经移动
print(dict(layer.named_parameters()))
它现在位于layer.parametrizations.weight.original下
print(layer.parametrizations.weight.original)
除了这三个小差异之外,参数化与我们的手动实现完全相同
symmetric = Symmetric()
weight_orig = layer.parametrizations.weight.original
print(torch.dist(layer.weight, symmetric(weight_orig)))
参数化是一流公民
由于layer.parametrizations是一个nn.ModuleList,这意味着参数化已正确注册为原始模块的子模块。因此,在模块中注册参数的相同规则也适用于注册参数化。例如,如果参数化具有参数,则在调用model = model.cuda()时,这些参数将从 CPU 移动到 CUDA。
缓存参数化的值
参数化通过上下文管理器parametrize.cached()具有内置的缓存系统
class NoisyParametrization(nn.Module):
def forward(self, X):
print("Computing the Parametrization")
return X
layer = nn.Linear(4, 4)
parametrize.register_parametrization(layer, "weight", NoisyParametrization())
print("Here, layer.weight is recomputed every time we call it")
foo = layer.weight + layer.weight.T
bar = layer.weight.sum()
with parametrize.cached():
print("Here, it is computed just the first time layer.weight is called")
foo = layer.weight + layer.weight.T
bar = layer.weight.sum()
连接参数化
连接两个参数化就像在同一个张量上注册它们一样简单。我们可以使用这个来从简单的参数化创建更复杂的参数化。例如,Cayley 映射将斜对称矩阵映射到正行列式的正交矩阵。我们可以连接Skew和一个实现 Cayley 映射的参数化,以获得具有正交权重的层
class CayleyMap(nn.Module):
def __init__(self, n):
super().__init__()
self.register_buffer("Id", torch.eye(n))
def forward(self, X):
# (I + X)(I - X)^{-1}
return torch.linalg.solve(self.Id - X, self.Id + X)
layer = nn.Linear(3, 3)
parametrize.register_parametrization(layer, "weight", Skew())
parametrize.register_parametrization(layer, "weight", CayleyMap(3))
X = layer.weight
print(torch.dist(X.T @ X, torch.eye(3))) # X is orthogonal
这也可以用来修剪一个参数化模块,或者重用参数化。例如,矩阵指数将对称矩阵映射到对称正定(SPD)矩阵,但矩阵指数也将斜对称矩阵映射到正交矩阵。利用这两个事实,我们可以重用之前的参数化以获得优势
class MatrixExponential(nn.Module):
def forward(self, X):
return torch.matrix_exp(X)
layer_orthogonal = nn.Linear(3, 3)
parametrize.register_parametrization(layer_orthogonal, "weight", Skew())
parametrize.register_parametrization(layer_orthogonal, "weight", MatrixExponential())
X = layer_orthogonal.weight
print(torch.dist(X.T @ X, torch.eye(3))) # X is orthogonal
layer_spd = nn.Linear(3, 3)
parametrize.register_parametrization(layer_spd, "weight", Symmetric())
parametrize.register_parametrization(layer_spd, "weight", MatrixExponential())
X = layer_spd.weight
print(torch.dist(X, X.T)) # X is symmetric
print((torch.linalg.eigvalsh(X) > 0.).all()) # X is positive definite
初始化参数化
参数化带有初始化它们的机制。如果我们实现一个带有签名的right_inverse方法
def right_inverse(self, X: Tensor) -> Tensor
当分配给参数化张量时将使用它。
让我们升级我们的Skew类的实现,以支持这一点
class Skew(nn.Module):
def forward(self, X):
A = X.triu(1)
return A - A.transpose(-1, -2)
def right_inverse(self, A):
# We assume that A is skew-symmetric
# We take the upper-triangular elements, as these are those used in the forward
return A.triu(1)
现在我们可以初始化一个使用Skew参数化的层
layer = nn.Linear(3, 3)
parametrize.register_parametrization(layer, "weight", Skew())
X = torch.rand(3, 3)
X = X - X.T # X is now skew-symmetric
layer.weight = X # Initialize layer.weight to be X
print(torch.dist(layer.weight, X)) # layer.weight == X
当我们连接参数化时,这个right_inverse按预期工作。为了看到这一点,让我们将 Cayley 参数化升级,以支持初始化
class CayleyMap(nn.Module):
def __init__(self, n):
super().__init__()
self.register_buffer("Id", torch.eye(n))
def forward(self, X):
# Assume X skew-symmetric
# (I + X)(I - X)^{-1}
return torch.linalg.solve(self.Id - X, self.Id + X)
def right_inverse(self, A):
# Assume A orthogonal
# See https://en.wikipedia.org/wiki/Cayley_transform#Matrix_map
# (X - I)(X + I)^{-1}
return torch.linalg.solve(X + self.Id, self.Id - X)
layer_orthogonal = nn.Linear(3, 3)
parametrize.register_parametrization(layer_orthogonal, "weight", Skew())
parametrize.register_parametrization(layer_orthogonal, "weight", CayleyMap(3))
# Sample an orthogonal matrix with positive determinant
X = torch.empty(3, 3)
nn.init.orthogonal_(X)
if X.det() < 0.:
X[0].neg_()
layer_orthogonal.weight = X
print(torch.dist(layer_orthogonal.weight, X)) # layer_orthogonal.weight == X
这个初始化步骤可以更简洁地写成
layer_orthogonal.weight = nn.init.orthogonal_(layer_orthogonal.weight)
这个方法的名称来自于我们经常期望forward(right_inverse(X)) == X。这是一种直接重写的方式,即初始化为值X后的前向传播应该返回值X。在实践中,这个约束并不是强制执行的。事实上,有时可能有兴趣放宽这种关系。例如,考虑以下随机修剪方法的实现:
class PruningParametrization(nn.Module):
def __init__(self, X, p_drop=0.2):
super().__init__()
# sample zeros with probability p_drop
mask = torch.full_like(X, 1.0 - p_drop)
self.mask = torch.bernoulli(mask)
def forward(self, X):
return X * self.mask
def right_inverse(self, A):
return A
在这种情况下,并非对于每个矩阵 A 都成立forward(right_inverse(A)) == A。只有当矩阵A在与掩码相同的位置有零时才成立。即使是这样,如果我们将一个张量分配给一个被修剪的参数,那么这个张量实际上将被修剪也就不足为奇了
layer = nn.Linear(3, 4)
X = torch.rand_like(layer.weight)
print(f"Initialization matrix:\n{X}")
parametrize.register_parametrization(layer, "weight", PruningParametrization(layer.weight))
layer.weight = X
print(f"\nInitialized weight:\n{layer.weight}")
移除参数化
我们可以通过使用parametrize.remove_parametrizations()从模块中的参数或缓冲区中移除所有参数化
layer = nn.Linear(3, 3)
print("Before:")
print(layer)
print(layer.weight)
parametrize.register_parametrization(layer, "weight", Skew())
print("\nParametrized:")
print(layer)
print(layer.weight)
parametrize.remove_parametrizations(layer, "weight")
print("\nAfter. Weight has skew-symmetric values but it is unconstrained:")
print(layer)
print(layer.weight)
在移除参数化时,我们可以选择保留原始参数(即layer.parametriations.weight.original中的参数),而不是其参数化版本,方法是设置标志leave_parametrized=False
layer = nn.Linear(3, 3)
print("Before:")
print(layer)
print(layer.weight)
parametrize.register_parametrization(layer, "weight", Skew())
print("\nParametrized:")
print(layer)
print(layer.weight)
parametrize.remove_parametrizations(layer, "weight", leave_parametrized=False)
print("\nAfter. Same as Before:")
print(layer)
print(layer.weight)
脚本的总运行时间:(0 分钟 0.000 秒)
下载 Python 源代码:parametrizations.py
下载 Jupyter 笔记本:parametrizations.ipynb
Sphinx-Gallery 生成的画廊
修剪教程
原文:
pytorch.org/tutorials/intermediate/pruning_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整的示例代码
作者:Michela Paganini
最先进的深度学习技术依赖于难以部署的过度参数化模型。相反,生物神经网络已知使用高效的稀疏连接。通过识别优化的技术来通过减少模型中的参数数量来压缩模型是重要的,以便在减少内存、电池和硬件消耗的同时不牺牲准确性。这反过来使您能够在设备上部署轻量级模型,并通过设备上的私有计算来保证隐私。在研究方面,修剪被用来研究过度参数化和欠参数化网络之间学习动态的差异,研究幸运稀疏子网络和初始化(“彩票票”)的作用作为一种破坏性的神经架构搜索技术,等等。
在本教程中,您将学习如何使用torch.nn.utils.prune来稀疏化您的神经网络,以及如何扩展它以实现自己的自定义修剪技术。
需求
"torch>=1.4.0a0+8e8a5e0"
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
创建一个模型
在本教程中,我们使用来自 LeCun 等人的 1998 年的LeNet架构。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square conv kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device=device)
检查一个模块
让我们检查我们 LeNet 模型中的(未修剪的)conv1层。它将包含两个参数weight和bias,目前没有缓冲区。
module = model.conv1
print(list(module.named_parameters()))
[('weight', Parameter containing:
tensor([[[[ 0.1529, 0.1660, -0.0469, 0.1837, -0.0438],
[ 0.0404, -0.0974, 0.1175, 0.1763, -0.1467],
[ 0.1738, 0.0374, 0.1478, 0.0271, 0.0964],
[-0.0282, 0.1542, 0.0296, -0.0934, 0.0510],
[-0.0921, -0.0235, -0.0812, 0.1327, -0.1579]]],
[[[-0.0922, -0.0565, -0.1203, 0.0189, -0.1975],
[ 0.1806, -0.1699, 0.1544, 0.0333, -0.0649],
[ 0.1236, 0.0312, 0.1616, 0.0219, -0.0631],
[ 0.0537, -0.0542, 0.0842, 0.1786, 0.1156],
[-0.0874, 0.1155, 0.0358, 0.1016, -0.1219]]],
[[[-0.1980, -0.0773, -0.1534, 0.1641, 0.0576],
[ 0.0828, 0.0633, -0.0035, 0.1565, -0.1421],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0667, 0.1925, -0.1651, -0.1984]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.1033, -0.1363, 0.1061, -0.0808, 0.1214],
[-0.0475, 0.1144, -0.1554, -0.1009, 0.0610],
[ 0.0423, -0.0510, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0675, -0.0709, -0.1935]]],
[[[-0.1145, 0.0500, -0.0264, -0.1452, 0.0047],
[-0.1366, -0.1697, -0.1101, -0.1750, -0.1273],
[ 0.1999, 0.0378, 0.0616, -0.1865, -0.1314],
[-0.0666, 0.0313, -0.1760, -0.0862, -0.1197],
[ 0.0006, -0.0744, -0.0139, -0.1355, -0.1373]]],
[[[-0.1167, -0.0685, -0.1579, 0.1677, -0.0397],
[ 0.1721, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.1988, 0.0572, -0.0437],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.1033, 0.1615, 0.1822, -0.1586]]]], device='cuda:0',
requires_grad=True)), ('bias', Parameter containing:
tensor([ 0.0503, -0.0860, -0.0219, -0.1497, 0.1822, -0.1468], device='cuda:0',
requires_grad=True))]
print(list(module.named_buffers()))
[]
修剪一个模块
要修剪一个模块(在这个例子中,是我们的 LeNet 架构中的conv1层),首先在torch.nn.utils.prune中选择一个修剪技术(或者实现自己的方法,通过继承BasePruningMethod)。然后,指定要在该模块内修剪的模块和参数的名称。最后,使用所选修剪技术所需的适当关键字参数,指定修剪参数。
在这个例子中,我们将在conv1层的名为weight的参数中随机修剪 30%的连接。模块作为函数的第一个参数传递;name使用其字符串标识符在该模块内标识参数;amount指示要修剪的连接的百分比(如果是 0 和 1 之间的浮点数),或要修剪的连接的绝对数量(如果是非负整数)。
prune.random_unstructured(module, name="weight", amount=0.3)
Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
修剪通过从参数中删除weight并用一个名为weight_orig的新参数替换它(即将初始参数name附加"_orig")。weight_orig存储张量的未修剪版本。bias没有被修剪,因此它将保持不变。
print(list(module.named_parameters()))
[('bias', Parameter containing:
tensor([ 0.0503, -0.0860, -0.0219, -0.1497, 0.1822, -0.1468], device='cuda:0',
requires_grad=True)), ('weight_orig', Parameter containing:
tensor([[[[ 0.1529, 0.1660, -0.0469, 0.1837, -0.0438],
[ 0.0404, -0.0974, 0.1175, 0.1763, -0.1467],
[ 0.1738, 0.0374, 0.1478, 0.0271, 0.0964],
[-0.0282, 0.1542, 0.0296, -0.0934, 0.0510],
[-0.0921, -0.0235, -0.0812, 0.1327, -0.1579]]],
[[[-0.0922, -0.0565, -0.1203, 0.0189, -0.1975],
[ 0.1806, -0.1699, 0.1544, 0.0333, -0.0649],
[ 0.1236, 0.0312, 0.1616, 0.0219, -0.0631],
[ 0.0537, -0.0542, 0.0842, 0.1786, 0.1156],
[-0.0874, 0.1155, 0.0358, 0.1016, -0.1219]]],
[[[-0.1980, -0.0773, -0.1534, 0.1641, 0.0576],
[ 0.0828, 0.0633, -0.0035, 0.1565, -0.1421],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0667, 0.1925, -0.1651, -0.1984]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.1033, -0.1363, 0.1061, -0.0808, 0.1214],
[-0.0475, 0.1144, -0.1554, -0.1009, 0.0610],
[ 0.0423, -0.0510, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0675, -0.0709, -0.1935]]],
[[[-0.1145, 0.0500, -0.0264, -0.1452, 0.0047],
[-0.1366, -0.1697, -0.1101, -0.1750, -0.1273],
[ 0.1999, 0.0378, 0.0616, -0.1865, -0.1314],
[-0.0666, 0.0313, -0.1760, -0.0862, -0.1197],
[ 0.0006, -0.0744, -0.0139, -0.1355, -0.1373]]],
[[[-0.1167, -0.0685, -0.1579, 0.1677, -0.0397],
[ 0.1721, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.1988, 0.0572, -0.0437],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.1033, 0.1615, 0.1822, -0.1586]]]], device='cuda:0',
requires_grad=True))]
上面选择的修剪技术生成的修剪蒙版被保存为一个名为weight_mask的模块缓冲区(即将初始参数name附加"_mask")。
print(list(module.named_buffers()))
[('weight_mask', tensor([[[[1., 1., 1., 1., 1.],
[1., 0., 1., 1., 1.],
[1., 0., 0., 1., 1.],
[1., 0., 1., 1., 1.],
[1., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 1.],
[1., 1., 1., 1., 1.],
[0., 1., 1., 1., 0.],
[1., 1., 0., 1., 0.],
[0., 1., 0., 1., 1.]]],
[[[1., 0., 0., 0., 1.],
[1., 0., 1., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 0., 1., 1., 0.]]],
[[[1., 1., 1., 1., 1.],
[0., 1., 1., 1., 0.],
[1., 1., 1., 0., 1.],
[0., 0., 1., 1., 1.],
[1., 1., 0., 1., 1.]]],
[[[1., 0., 1., 1., 1.],
[1., 1., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[0., 1., 1., 0., 1.],
[1., 0., 0., 0., 1.]]],
[[[1., 0., 1., 0., 1.],
[0., 1., 1., 1., 1.],
[1., 1., 0., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 0., 0., 1., 1.]]]], device='cuda:0'))]
为了使前向传播无需修改工作,weight属性需要存在。在torch.nn.utils.prune中实现的修剪技术计算权重的修剪版本(通过将蒙版与原始参数组合)并将它们存储在属性weight中。请注意,这不再是module的参数,现在只是一个属性。
print(module.weight)
tensor([[[[ 0.1529, 0.1660, -0.0469, 0.1837, -0.0438],
[ 0.0404, -0.0000, 0.1175, 0.1763, -0.1467],
[ 0.1738, 0.0000, 0.0000, 0.0271, 0.0964],
[-0.0282, 0.0000, 0.0296, -0.0934, 0.0510],
[-0.0921, -0.0000, -0.0000, 0.1327, -0.1579]]],
[[[-0.0922, -0.0565, -0.1203, 0.0000, -0.1975],
[ 0.1806, -0.1699, 0.1544, 0.0333, -0.0649],
[ 0.0000, 0.0312, 0.1616, 0.0219, -0.0000],
[ 0.0537, -0.0542, 0.0000, 0.1786, 0.0000],
[-0.0000, 0.1155, 0.0000, 0.1016, -0.1219]]],
[[[-0.1980, -0.0000, -0.0000, 0.0000, 0.0576],
[ 0.0828, 0.0000, -0.0035, 0.1565, -0.0000],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0000, 0.1925, -0.1651, -0.0000]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.0000, -0.1363, 0.1061, -0.0808, 0.0000],
[-0.0475, 0.1144, -0.1554, -0.0000, 0.0610],
[ 0.0000, -0.0000, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0000, -0.0709, -0.1935]]],
[[[-0.1145, 0.0000, -0.0264, -0.1452, 0.0047],
[-0.1366, -0.1697, -0.0000, -0.0000, -0.0000],
[ 0.1999, 0.0378, 0.0000, -0.0000, -0.0000],
[-0.0000, 0.0313, -0.1760, -0.0000, -0.1197],
[ 0.0006, -0.0000, -0.0000, -0.0000, -0.1373]]],
[[[-0.1167, -0.0000, -0.1579, 0.0000, -0.0397],
[ 0.0000, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.0000, 0.0572, -0.0000],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.0000, 0.0000, 0.1822, -0.1586]]]], device='cuda:0',
grad_fn=<MulBackward0>)
最后,在每次前向传播之前应用修剪,使用 PyTorch 的forward_pre_hooks。具体来说,当module被修剪时,就像我们在这里所做的那样,它将为与之关联的每个参数获取一个forward_pre_hook。在这种情况下,因为我们目前只修剪了名为weight的原始参数,所以只有一个钩子存在。
print(module._forward_pre_hooks)
OrderedDict([(0, <torch.nn.utils.prune.RandomUnstructured object at 0x7f4c36e10e50>)])
为了完整起见,我们现在也可以修剪bias,以查看module的参数、缓冲区、hook 和属性如何变化。为了尝试另一种修剪技术,这里我们通过 L1 范数在偏置中修剪最小的 3 个条目,如l1_unstructured修剪函数中实现的那样。
prune.l1_unstructured(module, name="bias", amount=3)
Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
我们现在期望命名参数包括weight_orig(之前的)和bias_orig。缓冲区将包括weight_mask和bias_mask。这两个张量的修剪版本将存在作为模块属性,并且模块现在将有两个forward_pre_hooks。
print(list(module.named_parameters()))
[('weight_orig', Parameter containing:
tensor([[[[ 0.1529, 0.1660, -0.0469, 0.1837, -0.0438],
[ 0.0404, -0.0974, 0.1175, 0.1763, -0.1467],
[ 0.1738, 0.0374, 0.1478, 0.0271, 0.0964],
[-0.0282, 0.1542, 0.0296, -0.0934, 0.0510],
[-0.0921, -0.0235, -0.0812, 0.1327, -0.1579]]],
[[[-0.0922, -0.0565, -0.1203, 0.0189, -0.1975],
[ 0.1806, -0.1699, 0.1544, 0.0333, -0.0649],
[ 0.1236, 0.0312, 0.1616, 0.0219, -0.0631],
[ 0.0537, -0.0542, 0.0842, 0.1786, 0.1156],
[-0.0874, 0.1155, 0.0358, 0.1016, -0.1219]]],
[[[-0.1980, -0.0773, -0.1534, 0.1641, 0.0576],
[ 0.0828, 0.0633, -0.0035, 0.1565, -0.1421],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0667, 0.1925, -0.1651, -0.1984]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.1033, -0.1363, 0.1061, -0.0808, 0.1214],
[-0.0475, 0.1144, -0.1554, -0.1009, 0.0610],
[ 0.0423, -0.0510, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0675, -0.0709, -0.1935]]],
[[[-0.1145, 0.0500, -0.0264, -0.1452, 0.0047],
[-0.1366, -0.1697, -0.1101, -0.1750, -0.1273],
[ 0.1999, 0.0378, 0.0616, -0.1865, -0.1314],
[-0.0666, 0.0313, -0.1760, -0.0862, -0.1197],
[ 0.0006, -0.0744, -0.0139, -0.1355, -0.1373]]],
[[[-0.1167, -0.0685, -0.1579, 0.1677, -0.0397],
[ 0.1721, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.1988, 0.0572, -0.0437],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.1033, 0.1615, 0.1822, -0.1586]]]], device='cuda:0',
requires_grad=True)), ('bias_orig', Parameter containing:
tensor([ 0.0503, -0.0860, -0.0219, -0.1497, 0.1822, -0.1468], device='cuda:0',
requires_grad=True))]
print(list(module.named_buffers()))
[('weight_mask', tensor([[[[1., 1., 1., 1., 1.],
[1., 0., 1., 1., 1.],
[1., 0., 0., 1., 1.],
[1., 0., 1., 1., 1.],
[1., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 1.],
[1., 1., 1., 1., 1.],
[0., 1., 1., 1., 0.],
[1., 1., 0., 1., 0.],
[0., 1., 0., 1., 1.]]],
[[[1., 0., 0., 0., 1.],
[1., 0., 1., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 0., 1., 1., 0.]]],
[[[1., 1., 1., 1., 1.],
[0., 1., 1., 1., 0.],
[1., 1., 1., 0., 1.],
[0., 0., 1., 1., 1.],
[1., 1., 0., 1., 1.]]],
[[[1., 0., 1., 1., 1.],
[1., 1., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[0., 1., 1., 0., 1.],
[1., 0., 0., 0., 1.]]],
[[[1., 0., 1., 0., 1.],
[0., 1., 1., 1., 1.],
[1., 1., 0., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 0., 0., 1., 1.]]]], device='cuda:0')), ('bias_mask', tensor([0., 0., 0., 1., 1., 1.], device='cuda:0'))]
print(module.bias)
tensor([ 0.0000, -0.0000, -0.0000, -0.1497, 0.1822, -0.1468], device='cuda:0',
grad_fn=<MulBackward0>)
print(module._forward_pre_hooks)
OrderedDict([(0, <torch.nn.utils.prune.RandomUnstructured object at 0x7f4c36e10e50>), (1, <torch.nn.utils.prune.L1Unstructured object at 0x7f4c632815d0>)])
迭代修剪
模块中的同一参数可以多次修剪,各个修剪调用的效果等于串行应用的各个掩码的组合。新掩码与旧掩码的组合由PruningContainer的compute_mask方法处理。
例如,假设我们现在想要进一步修剪module.weight,这次使用张量的第 0 轴(第 0 轴对应于卷积层的输出通道,并且对于conv1,维度为 6)上的结构化修剪,基于通道的 L2 范数。这可以使用ln_structured函数实现,其中n=2和dim=0。
prune.ln_structured(module, name="weight", amount=0.5, n=2, dim=0)
# As we can verify, this will zero out all the connections corresponding to
# 50% (3 out of 6) of the channels, while preserving the action of the
# previous mask.
print(module.weight)
tensor([[[[ 0.0000, 0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000]]],
[[[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, 0.0000, -0.0000]]],
[[[-0.1980, -0.0000, -0.0000, 0.0000, 0.0576],
[ 0.0828, 0.0000, -0.0035, 0.1565, -0.0000],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0000, 0.1925, -0.1651, -0.0000]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.0000, -0.1363, 0.1061, -0.0808, 0.0000],
[-0.0475, 0.1144, -0.1554, -0.0000, 0.0610],
[ 0.0000, -0.0000, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0000, -0.0709, -0.1935]]],
[[[-0.0000, 0.0000, -0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, -0.0000, -0.0000],
[-0.0000, 0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, -0.0000, -0.0000, -0.0000, -0.0000]]],
[[[-0.1167, -0.0000, -0.1579, 0.0000, -0.0397],
[ 0.0000, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.0000, 0.0572, -0.0000],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.0000, 0.0000, 0.1822, -0.1586]]]], device='cuda:0',
grad_fn=<MulBackward0>)
相应的 hook 现在将是torch.nn.utils.prune.PruningContainer类型,并将存储应用于weight参数的修剪历史。
for hook in module._forward_pre_hooks.values():
if hook._tensor_name == "weight": # select out the correct hook
break
print(list(hook)) # pruning history in the container
[<torch.nn.utils.prune.RandomUnstructured object at 0x7f4c36e10e50>, <torch.nn.utils.prune.LnStructured object at 0x7f4c63282c50>]
序列化修剪模型
所有相关张量,包括掩码缓冲区和用于计算修剪张量的原始参数都存储在模型的state_dict中,因此如果需要,可以轻松序列化和保存。
print(model.state_dict().keys())
odict_keys(['conv1.weight_orig', 'conv1.bias_orig', 'conv1.weight_mask', 'conv1.bias_mask', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias'])
移除修剪重新参数化
要使修剪永久化,删除关于weight_orig和weight_mask的重新参数化,并删除forward_pre_hook,我们可以使用torch.nn.utils.prune中的remove功能。请注意,这不会撤消修剪,就好像从未发生过一样。它只是使其永久化,通过将参数weight重新分配给模型参数,以其修剪版本。
在移除重新参数化之前:
print(list(module.named_parameters()))
[('weight_orig', Parameter containing:
tensor([[[[ 0.1529, 0.1660, -0.0469, 0.1837, -0.0438],
[ 0.0404, -0.0974, 0.1175, 0.1763, -0.1467],
[ 0.1738, 0.0374, 0.1478, 0.0271, 0.0964],
[-0.0282, 0.1542, 0.0296, -0.0934, 0.0510],
[-0.0921, -0.0235, -0.0812, 0.1327, -0.1579]]],
[[[-0.0922, -0.0565, -0.1203, 0.0189, -0.1975],
[ 0.1806, -0.1699, 0.1544, 0.0333, -0.0649],
[ 0.1236, 0.0312, 0.1616, 0.0219, -0.0631],
[ 0.0537, -0.0542, 0.0842, 0.1786, 0.1156],
[-0.0874, 0.1155, 0.0358, 0.1016, -0.1219]]],
[[[-0.1980, -0.0773, -0.1534, 0.1641, 0.0576],
[ 0.0828, 0.0633, -0.0035, 0.1565, -0.1421],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0667, 0.1925, -0.1651, -0.1984]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.1033, -0.1363, 0.1061, -0.0808, 0.1214],
[-0.0475, 0.1144, -0.1554, -0.1009, 0.0610],
[ 0.0423, -0.0510, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0675, -0.0709, -0.1935]]],
[[[-0.1145, 0.0500, -0.0264, -0.1452, 0.0047],
[-0.1366, -0.1697, -0.1101, -0.1750, -0.1273],
[ 0.1999, 0.0378, 0.0616, -0.1865, -0.1314],
[-0.0666, 0.0313, -0.1760, -0.0862, -0.1197],
[ 0.0006, -0.0744, -0.0139, -0.1355, -0.1373]]],
[[[-0.1167, -0.0685, -0.1579, 0.1677, -0.0397],
[ 0.1721, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.1988, 0.0572, -0.0437],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.1033, 0.1615, 0.1822, -0.1586]]]], device='cuda:0',
requires_grad=True)), ('bias_orig', Parameter containing:
tensor([ 0.0503, -0.0860, -0.0219, -0.1497, 0.1822, -0.1468], device='cuda:0',
requires_grad=True))]
print(list(module.named_buffers()))
[('weight_mask', tensor([[[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]],
[[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]],
[[[1., 0., 0., 0., 1.],
[1., 0., 1., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 0., 1., 1., 0.]]],
[[[1., 1., 1., 1., 1.],
[0., 1., 1., 1., 0.],
[1., 1., 1., 0., 1.],
[0., 0., 1., 1., 1.],
[1., 1., 0., 1., 1.]]],
[[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]],
[[[1., 0., 1., 0., 1.],
[0., 1., 1., 1., 1.],
[1., 1., 0., 1., 0.],
[1., 1., 1., 1., 1.],
[1., 0., 0., 1., 1.]]]], device='cuda:0')), ('bias_mask', tensor([0., 0., 0., 1., 1., 1.], device='cuda:0'))]
print(module.weight)
tensor([[[[ 0.0000, 0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000]]],
[[[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, 0.0000, -0.0000]]],
[[[-0.1980, -0.0000, -0.0000, 0.0000, 0.0576],
[ 0.0828, 0.0000, -0.0035, 0.1565, -0.0000],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0000, 0.1925, -0.1651, -0.0000]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.0000, -0.1363, 0.1061, -0.0808, 0.0000],
[-0.0475, 0.1144, -0.1554, -0.0000, 0.0610],
[ 0.0000, -0.0000, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0000, -0.0709, -0.1935]]],
[[[-0.0000, 0.0000, -0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, -0.0000, -0.0000],
[-0.0000, 0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, -0.0000, -0.0000, -0.0000, -0.0000]]],
[[[-0.1167, -0.0000, -0.1579, 0.0000, -0.0397],
[ 0.0000, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.0000, 0.0572, -0.0000],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.0000, 0.0000, 0.1822, -0.1586]]]], device='cuda:0',
grad_fn=<MulBackward0>)
移除重新参数化后:
prune.remove(module, 'weight')
print(list(module.named_parameters()))
[('bias_orig', Parameter containing:
tensor([ 0.0503, -0.0860, -0.0219, -0.1497, 0.1822, -0.1468], device='cuda:0',
requires_grad=True)), ('weight', Parameter containing:
tensor([[[[ 0.0000, 0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000]]],
[[[-0.0000, -0.0000, -0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, -0.0000],
[ 0.0000, -0.0000, 0.0000, 0.0000, 0.0000],
[-0.0000, 0.0000, 0.0000, 0.0000, -0.0000]]],
[[[-0.1980, -0.0000, -0.0000, 0.0000, 0.0576],
[ 0.0828, 0.0000, -0.0035, 0.1565, -0.0000],
[ 0.0126, -0.1365, 0.0617, -0.0689, 0.0613],
[-0.0417, 0.1659, -0.1185, -0.1193, -0.1193],
[ 0.1799, 0.0000, 0.1925, -0.1651, -0.0000]]],
[[[-0.1565, -0.1345, 0.0810, 0.0716, 0.1662],
[-0.0000, -0.1363, 0.1061, -0.0808, 0.0000],
[-0.0475, 0.1144, -0.1554, -0.0000, 0.0610],
[ 0.0000, -0.0000, 0.1192, 0.1360, -0.1450],
[-0.1068, 0.1831, -0.0000, -0.0709, -0.1935]]],
[[[-0.0000, 0.0000, -0.0000, -0.0000, 0.0000],
[-0.0000, -0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000, -0.0000, -0.0000],
[-0.0000, 0.0000, -0.0000, -0.0000, -0.0000],
[ 0.0000, -0.0000, -0.0000, -0.0000, -0.0000]]],
[[[-0.1167, -0.0000, -0.1579, 0.0000, -0.0397],
[ 0.0000, 0.0623, -0.1694, 0.1384, -0.0550],
[-0.0767, -0.1660, -0.0000, 0.0572, -0.0000],
[ 0.0779, -0.1641, 0.1485, -0.1468, -0.0345],
[ 0.0418, 0.0000, 0.0000, 0.1822, -0.1586]]]], device='cuda:0',
requires_grad=True))]
print(list(module.named_buffers()))
[('bias_mask', tensor([0., 0., 0., 1., 1., 1.], device='cuda:0'))]
在模型中修剪多个参数
通过指定所需的修剪技术和参数,我们可以轻松地在网络中修剪多个张量,也许根据它们的类型,正如我们将在本例中看到的。
new_model = LeNet()
for name, module in new_model.named_modules():
# prune 20% of connections in all 2D-conv layers
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
# prune 40% of connections in all linear layers
elif isinstance(module, torch.nn.Linear):
prune.l1_unstructured(module, name='weight', amount=0.4)
print(dict(new_model.named_buffers()).keys()) # to verify that all masks exist
dict_keys(['conv1.weight_mask', 'conv2.weight_mask', 'fc1.weight_mask', 'fc2.weight_mask', 'fc3.weight_mask'])
全局修剪
到目前为止,我们只看了通常被称为“局部”修剪的内容,即通过将每个条目的统计数据(权重大小、激活、梯度等)与该张量中的其他条目进行比较,逐个修剪模型中的张量的做法。然而,一种常见且可能更强大的技术是一次性修剪整个模型,例如,通过删除整个模型中最低的 20%连接,而不是在每一层中删除最低的 20%连接。这可能会导致每层不同的修剪百分比。让我们看看如何使用torch.nn.utils.prune中的global_unstructured来实现这一点。
model = LeNet()
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2,
)
现在我们可以检查每个修剪参数中引入的稀疏性,这在每个层中不会等于 20%。然而,全局稀疏性将是(大约)20%。
print(
"Sparsity in conv1.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv1.weight == 0))
/ float(model.conv1.weight.nelement())
)
)
print(
"Sparsity in conv2.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv2.weight == 0))
/ float(model.conv2.weight.nelement())
)
)
print(
"Sparsity in fc1.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc1.weight == 0))
/ float(model.fc1.weight.nelement())
)
)
print(
"Sparsity in fc2.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc2.weight == 0))
/ float(model.fc2.weight.nelement())
)
)
print(
"Sparsity in fc3.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc3.weight == 0))
/ float(model.fc3.weight.nelement())
)
)
print(
"Global sparsity: {:.2f}%".format(
100. * float(
torch.sum(model.conv1.weight == 0)
+ torch.sum(model.conv2.weight == 0)
+ torch.sum(model.fc1.weight == 0)
+ torch.sum(model.fc2.weight == 0)
+ torch.sum(model.fc3.weight == 0)
)
/ float(
model.conv1.weight.nelement()
+ model.conv2.weight.nelement()
+ model.fc1.weight.nelement()
+ model.fc2.weight.nelement()
+ model.fc3.weight.nelement()
)
)
)
Sparsity in conv1.weight: 4.67%
Sparsity in conv2.weight: 13.92%
Sparsity in fc1.weight: 22.16%
Sparsity in fc2.weight: 12.10%
Sparsity in fc3.weight: 11.31%
Global sparsity: 20.00%
使用自定义修剪函数扩展torch.nn.utils.prune
要实现自己的修剪函数,您可以通过继承BasePruningMethod基类来扩展nn.utils.prune模块,就像所有其他修剪方法一样。基类为您实现了以下方法:__call__、apply_mask、apply、prune和remove。除了一些特殊情况,您不应该重新实现这些方法以适应您的新修剪技术。但是,您需要实现__init__(构造函数)和compute_mask(根据修剪技术的逻辑指示如何计算给定张量的掩码)。此外,您还需要指定此技术实现的修剪类型(支持的选项为global、structured和unstructured)。这是为了确定如何在迭代应用修剪时组合掩码。换句话说,当修剪预修剪参数时,当前修剪技术应该作用于参数的未修剪部分。指定PRUNING_TYPE将使PruningContainer(处理修剪掩码的迭代应用)能够正确识别要修剪的参数切片。
例如,假设您想要实现一种修剪技术,该技术修剪张量中的每个其他条目(或者 - 如果张量以前已被修剪 - 则修剪张量的剩余未修剪部分中的每个其他条目)。这将是PRUNING_TYPE='unstructured',因为它作用于层中的单个连接,而不是整个单元/通道('structured')或跨不同参数('global')。
class FooBarPruningMethod(prune.BasePruningMethod):
"""Prune every other entry in a tensor
"""
PRUNING_TYPE = 'unstructured'
def compute_mask(self, t, default_mask):
mask = default_mask.clone()
mask.view(-1)[::2] = 0
return mask
现在,要将此应用于nn.Module中的参数,您还应提供一个简单的函数,该函数实例化该方法并应用它。
def foobar_unstructured(module, name):
"""Prunes tensor corresponding to parameter called `name` in `module`
by removing every other entry in the tensors.
Modifies module in place (and also return the modified module)
by:
1) adding a named buffer called `name+'_mask'` corresponding to the
binary mask applied to the parameter `name` by the pruning method.
The parameter `name` is replaced by its pruned version, while the
original (unpruned) parameter is stored in a new parameter named
`name+'_orig'`.
Args:
module (nn.Module): module containing the tensor to prune
name (string): parameter name within `module` on which pruning
will act.
Returns:
module (nn.Module): modified (i.e. pruned) version of the input
module
Examples:
>>> m = nn.Linear(3, 4)
>>> foobar_unstructured(m, name='bias')
"""
FooBarPruningMethod.apply(module, name)
return module
让我们试一试!
model = LeNet()
foobar_unstructured(model.fc3, name='bias')
print(model.fc3.bias_mask)
tensor([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
脚本的总运行时间:(0 分钟 0.373 秒)
下载 Python 源代码:pruning_tutorial.py
下载 Jupyter 笔记本:pruning_tutorial.ipynb
由 Sphinx-Gallery 生成的图库
(beta)LSTM 单词语言模型上的动态量化
原文:
pytorch.org/tutorials/advanced/dynamic_quantization_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
作者:James Reed
编辑者:Seth Weidman
介绍
量化涉及将模型的权重和激活从浮点转换为整数,这可以使模型大小更小,推理速度更快,只会对准确性产生轻微影响。
在本教程中,我们将应用最简单形式的量化 - 动态量化 - 到基于 LSTM 的下一个单词预测模型,紧随 PyTorch 示例中的word language model。
# imports
import os
from io import open
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
1. 定义模型
在这里,我们定义 LSTM 模型架构,遵循单词语言模型示例中的model。
class LSTMModel(nn.Module):
"""Container module with an encoder, a recurrent module, and a decoder."""
def __init__(self, ntoken, ninp, nhid, nlayers, dropout=0.5):
super(LSTMModel, self).__init__()
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken, ninp)
self.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output)
return decoded, hidden
def init_hidden(self, bsz):
weight = next(self.parameters())
return (weight.new_zeros(self.nlayers, bsz, self.nhid),
weight.new_zeros(self.nlayers, bsz, self.nhid))
2. 加载文本数据
接下来,我们将Wikitext-2 数据集加载到一个 Corpus 中,再次遵循单词语言模型示例中的预处理。
class Dictionary(object):
def __init__(self):
self.word2idx = {}
self.idx2word = []
def add_word(self, word):
if word not in self.word2idx:
self.idx2word.append(word)
self.word2idx[word] = len(self.idx2word) - 1
return self.word2idx[word]
def __len__(self):
return len(self.idx2word)
class Corpus(object):
def __init__(self, path):
self.dictionary = Dictionary()
self.train = self.tokenize(os.path.join(path, 'train.txt'))
self.valid = self.tokenize(os.path.join(path, 'valid.txt'))
self.test = self.tokenize(os.path.join(path, 'test.txt'))
def tokenize(self, path):
"""Tokenizes a text file."""
assert os.path.exists(path)
# Add words to the dictionary
with open(path, 'r', encoding="utf8") as f:
for line in f:
words = line.split() + ['<eos>']
for word in words:
self.dictionary.add_word(word)
# Tokenize file content
with open(path, 'r', encoding="utf8") as f:
idss = []
for line in f:
words = line.split() + ['<eos>']
ids = []
for word in words:
ids.append(self.dictionary.word2idx[word])
idss.append(torch.tensor(ids).type(torch.int64))
ids = torch.cat(idss)
return ids
model_data_filepath = 'data/'
corpus = Corpus(model_data_filepath + 'wikitext-2')
3. 加载预训练模型
这是关于动态量化的教程,这是一种在模型训练后应用的量化技术。因此,我们将简单地将一些预训练权重加载到这个模型架构中;这些权重是通过在单词语言模型示例中使用默认设置进行五个时期的训练获得的。
ntokens = len(corpus.dictionary)
model = LSTMModel(
ntoken = ntokens,
ninp = 512,
nhid = 256,
nlayers = 5,
)
model.load_state_dict(
torch.load(
model_data_filepath + 'word_language_model_quantize.pth',
map_location=torch.device('cpu')
)
)
model.eval()
print(model)
LSTMModel(
(drop): Dropout(p=0.5, inplace=False)
(encoder): Embedding(33278, 512)
(rnn): LSTM(512, 256, num_layers=5, dropout=0.5)
(decoder): Linear(in_features=256, out_features=33278, bias=True)
)
现在让我们生成一些文本,以确保预训练模型正常工作 - 类似于之前,我们遵循这里。
input_ = torch.randint(ntokens, (1, 1), dtype=torch.long)
hidden = model.init_hidden(1)
temperature = 1.0
num_words = 1000
with open(model_data_filepath + 'out.txt', 'w') as outf:
with torch.no_grad(): # no tracking history
for i in range(num_words):
output, hidden = model(input_, hidden)
word_weights = output.squeeze().div(temperature).exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input_.fill_(word_idx)
word = corpus.dictionary.idx2word[word_idx]
outf.write(str(word.encode('utf-8')) + ('\n' if i % 20 == 19 else ' '))
if i % 100 == 0:
print('| Generated {}/{} words'.format(i, 1000))
with open(model_data_filepath + 'out.txt', 'r') as outf:
all_output = outf.read()
print(all_output)
| Generated 0/1000 words
| Generated 100/1000 words
| Generated 200/1000 words
| Generated 300/1000 words
| Generated 400/1000 words
| Generated 500/1000 words
| Generated 600/1000 words
| Generated 700/1000 words
| Generated 800/1000 words
| Generated 900/1000 words
b'.' b'Ross' b"'" b'final' b'focus' b'respects' b'with' b'rice' b'Rajeev' b'implements' b'.' b'<unk>' b'Darwin' b',' b'a' b'comfortably' b',' b'called' b'that' b'it'
b'is' b'"' b'significant' b'alive' b'"' b'from' b'perform' b'@-@' b'hearted' b',' b'can' b'be' b'among' b'what' b'he' b'is' b'a' b'Sixth' b'minister' b'as'
b'a' b'analysis' b',' b'bathtub' b'for' b'1798' b'and' b'an' b'Nourrit' b'who' b'left' b'the' b'same' b'name' b',' b'which' b'they' b'saw' b'to' b'"'
b'let' b'most' b'or' b'me' b'of' b'its' b'all' b'time' b'that' b'might' b'have' b'done' b'on' b'back' b'on' b'their' b'character' b'position' b'.' b'"'
b'<eos>' b'The' b'2010' b'Peach' b'Bird' b"'" b'Union' b'(' b'1888' b')' b',' b'which' b'could' b'be' b'actively' b'composed' b'in' b'London' b'and' b'in'
b'1609' b'.' b'The' b'work' b'have' b'October' b',' b'but' b',' b'since' b'the' b'parish' b'of' b'times' b'is' b'hard' b'and' b'severely' b'ignored' b'the'
b'plums' b',' b'they' b'<unk>' b'or' b'Giuseppe' b'Leo' b'Rodman' b'for' b'the' b'game' b'<unk>' b',' b'and' b'were' b'released' b'and' b'because' b'it' b'apparently'
b'spent' b'before' b'with' b'those' b'arena' b'to' b'deciding' b'.' b'"' b'strumming' b'on' b'You' b'then' b'heard' b'enough' b'that' b'we' b'have' b'rhythm' b'channels'
b'in' b'a' b'video' b'off' b'his' b'complete' b'novel' b'"' b'.' b'The' b'population' b'of' b'Ceres' b'will' b'be' b'negative' b'for' b'strictly' b'@-@' b'hawk'
b'to' b'come' b'into' b'Year' b'1' b'.' b'There' b'is' b'a' b'pair' b'of' b'using' b'526' b',' b'O2' b',' b'nose' b',' b'<unk>' b'and'
b'coalitions' b'with' b'promyelocytic' b'officials' b'were' b'somewhat' b'developing' b'.' b'The' b'work' b'would' b'be' b'tested' b'as' b'a' b'hunt' b'to' b'Castle' b'network' b'including'
b'possible' b'gear' b'.' b'<eos>' b'<eos>' b'=' b'=' b'Behavior' b'=' b'=' b'<eos>' b'<eos>' b'<unk>' b'Michael' b'David' b'J.' b'M.' b'hilarious' b'(' b'died'
b'port' b'6' b':' b'12' b'<eos>' b'Ffordd' b'admirable' b'reality' b')' b'<eos>' b'trade' b'classifications' b',' b'without' b'a' b'creator' b';' b'of' b'even' b'@-@'
b'narial' b'earth' b',' b'building' b'rare' b'sounds' b',' b'Ridgway' b'contents' b',' b'any' b'GAA' b'in' b'air' b',' b'bleeding' b'.' b'<eos>' b'John' b'Leonard'
b'Rick' b'Smith' b'(' b'Evangeline' b'J.' b'Male' b')' b',' b'who' b'are' b'also' b'known' b'to' b'be' b'generally' b'portrayed' b'as' b'director' b'of' b'the'
b'Roman' b'origin' b'of' b'Sport' b'@-@' b'class' b'consent' b',' b'a' b'new' b'example' b'of' b'high' b'non' b'@-@' b'Crusader' b'forces' b'could' b'be' b'found'
b'by' b'<unk>' b'the' b'death' b'of' b'fish' b'highways' b'.' b'<eos>' b'<eos>' b'=' b'=' b'Background' b'=' b'=' b'<eos>' b'<eos>' b'The' b'majority' b'of'
b'year' b',' b'Superman' b',' b'was' b'also' b'built' b'into' b'alphabet' b'.' b'The' b'NW' b'were' b'written' b'by' b'other' b'astronomers' b'such' b'as' b'<unk>'
b'Jermaine' b'Farr' b',' b'with' b'respond' b'to' b'power' b'(' b'reorganize' b')' b'.' b'These' b'birds' b'have' b'had' b'hosted' b'North' b'AIDS' b'since' b'vocalization'
b'.' b'It' b'depicting' b'an' b'Normal' b'female' b'extended' b'after' b',' b'leaving' b'Petrie' b'resembled' b'Taylor' b'issues' b'has' b'significant' b'governmental' b'features' b',' b'called'
b'it' b',' b'"' b'Parts' b'as' b'well' b'to' b'kill' b'us' b'from' b'Haifa' b'is' b'an' b'gift' b'off' b'them' b'.' b'"' b'In' b'a'
b'review' b'that' b'Downs' b',' b'"' b'Every' b'blames' b'recent' b'human' b'parallels' b'you' b'is' b'Zeller' b'envisioned' b',' b'you' b'The' b'last' b'an' b'middle'
b'adult' b'person' b'in' b'ratio' b'of' b'male' b'throwing' b'lists' b'daily' b'letters' b'even' b',' b'attack' b',' b'and' b'inflict' b'you' b'into' b'Lost' b','
b'but' b'you' b'Rock' b'have' b'access' b'to' b'the' b'Mendip' b'conception' b'who' b"'re" b'overthrow' b'what' b'everything' b'in' b'than' b'store' b'particles' b'.' b'"'
b'The' b'face' b'recognized' b'Innis' b'was' b'of' b'unrepentant' b'Ulaid' b'.' b'glider' b'rent' b'for' b'Sister' b'Weber' b'are' b'exposing' b'to' b'seek' b'during' b'the'
b'hear' b'film' b'dislike' b"'s" b'staged' b'alignment' b'.' b'Another' b'cloth' b'was' b'only' b'impressed' b'by' b'Lab' b',' b'they' b'also' b'occasionally' b'learnt' b'a'
b'listener' b'.' b'<eos>' b'As' b'Plunkett' b"'s" b'death' b',' b'many' b'images' b'entrusted' b'to' b'join' b'items' b'display' b'models' b'than' b'foot' b'in' b'British'
b'countries' b'.' b'<unk>' b'indicated' b'is' b'also' b'safe' b'to' b'decide' b'down' b'McFarland' b',' b'even' b'that' b'searching' b'approaches' b'a' b'winds' b'for' b'two'
b'years' b'of' b'established' b'.' b'It' b'is' b'safe' b'that' b'<unk>' b'responded' b'in' b'(' b'the' b'19th' b'century' b',' b'including' b'A.' b"'\xc3\xa9tat" b';'
b'it' b'will' b'be' b'in' b'their' b'longer' b',' b'propel' b'"' b'<unk>' b'"' b',' b'which' b'aiding' b'God' b'@-@' b'black' b'overly' b',' b'astronomical'
b',' b'business' b',' b'<unk>' b',' b'<unk>' b',' b'or' b'grey' b'timeline' b'by' b'dismissal' b'before' b'mutualistic' b',' b'and' b'substrate' b'attention' b'given' b'as'
b'a' b'certain' b'species' b'of' b'153' b'stages' b'.' b'<unk>' b'in' b'toilet' b'can' b'be' b'found' b'to' b'signs' b'of' b'450' b',' b'compared' b'to'
b'50' b'%' b'closer' b',' b'while' b'manuscripts' b'may' b'be' b'"' b'distinguished' b'it' b'"' b'.' b'Incubation' b'resemble' b'Jordan' b'a' b'extremes' b',' b'Illinois'
b'concluding' b'much' b'of' b'the' b'player' b"'s" b'earlier' b'the' b'<unk>' b'broods' b'policies' b'.' b'<eos>' b'As' b'a' b'year' b',' b'he' b'is' b'found'
b'to' b'scare' b'taking' b'place' b'upon' b'behind' b'other' b'device' b',' b'including' b'its' b'further' b'sequence' b',' b'which' b'saw' b'him' b'a' b'painting' b'of'
b'conspiracy' b'that' b'enters' b'<unk>' b'to' b'cook' b'.' b'By' b'this' b'attacks' b',' b'they' b'are' b'shown' b'that' b'<unk>' b'(' b'an' b'one' b'@-@'
b'year' b')' b',' b'"' b'vision' b'(' b'still' b'most' b'equivalent' b'mourning' b')' b',' b'a' b'high' b'man' b'or' b'sings' b'large' b'Bruins' b'and'
b'rifles' b'all' b'by' b'night' b'<unk>' b',' b'not' b'nursing' b'.' b'"' b'Some' b'authors' b'like' b'H.' b'<unk>' b'<unk>' b'is' b'a' b'pure' b'character'
b'.' b'The' b'Admiralty' b'covers' b'Bob' b'cottonwood' b',' b'a' b'reflection' b'that' b'God' b'heard' b'parallel' b'.' b'reporters' b'went' b'forward' b'with' b'his' b'unusually'
b'controversial' b'Fern\xc3\xa1ndez' b',' b'back' b'"' b'that' b'many' b'authors' b"'re" b'forbidden' b'between' b'Black' b'Island' b'worker' b'!' b"'" b'learns' b'"' b'(' b'2006'
b')' b',' b'whose' b'<unk>' b'will' b'be' b'seen' b'as' b'a' b'child' b'.' b'Scully' b'is' b'trouble' b'apart' b'in' b'the' b'nominally' b',' b'and'
b'only' b'they' b'can' b'not' b'specifically' b'specify' b'after' b'they' b'could' b'be' b'rapidly' b'known' b'.' b'However' b',' b'it' b'may' b'assassinate' b'double' b'in'
b'other' b'ways' b',' b'even' b'because' b'he' b'provide' b'11' b'shock' b',' b'<unk>' b'the' b'Canary' b'Sun' b'breaker' b'.' b'<unk>' b'even' b'<unk>' b'by'
b'a' b'variety' b'of' b'other' b'factors' b',' b'which' b'Canterbury' b'doesn' b"'t" b'be' b'named' b'as' b'they' b'have' b'the' b'127th' b'mention' b'.' b'flocks'
b'fail' b'to' b'be' b'Allah' b',' b'depressed' b'peninsula' b',' b'<unk>' b',' b'and' b'@-@' b'head' b'ice' b'<unk>' b',' b'which' b'may' b'be' b'applied'
b'to' b'both' b'New' b'Zealand' b'.' b'The' b'food' b'and' b'so' b'they' b'can' b'react' b'into' b'Blue' b'or' b'eye' b'itself' b'.' b'They' b'may'
b'improve' b'their' b'position' b'complimented' b'up' b'or' b'place' b'resulted' b'on' b'all' b'Alfa' b'to' b'keep' b'care' b'of' b'Ceres' b',' b'orbiting' b'or' b'wide'
b',' b'then' b'by' b'its' b'space' b'.' b'<unk>' b',' b'they' b'were' b'will' b'try' b'the' b'kakapo' b'of' b'unusual' b',' b'<unk>' b'<unk>' b'or'
b'synthesize' b'Dead' b'(' b'860' b'<unk>' b'<unk>' b')' b'on' b'Activision' b'rather' b'@-@' b'thirds' b'of' b'spotlight' b'its' b'spectrum' b':' b'dying' b',' b'when'
b'British' b'behaviour' b'was' b'a' b'calculate' b'compound' b'to' b'merge' b',' b'with' b'some' b'chicks' b'to' b'use' b'their' b'bestow' b'.' b'It' b'may' b'indicate'
虽然不是 GPT-2,但看起来模型已经开始学习语言结构!
我们几乎准备好演示动态量化了。我们只需要定义几个更多的辅助函数:
bptt = 25
criterion = nn.CrossEntropyLoss()
eval_batch_size = 1
# create test data set
def batchify(data, bsz):
# Work out how cleanly we can divide the dataset into ``bsz`` parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the ``bsz`` batches.
return data.view(bsz, -1).t().contiguous()
test_data = batchify(corpus.test, eval_batch_size)
# Evaluation functions
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].reshape(-1)
return data, target
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
def evaluate(model_, data_source):
# Turn on evaluation mode which disables dropout.
model_.eval()
total_loss = 0.
hidden = model_.init_hidden(eval_batch_size)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
data, targets = get_batch(data_source, i)
output, hidden = model_(data, hidden)
hidden = repackage_hidden(hidden)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
4. 测试动态量化
最后,我们可以在模型上调用torch.quantization.quantize_dynamic!具体来说,
-
我们指定我们希望模型中的
nn.LSTM和nn.Linear模块被量化。 -
我们指定希望将权重转换为
int8值
import torch.quantization
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.LSTM, nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
LSTMModel(
(drop): Dropout(p=0.5, inplace=False)
(encoder): Embedding(33278, 512)
(rnn): DynamicQuantizedLSTM(512, 256, num_layers=5, dropout=0.5)
(decoder): DynamicQuantizedLinear(in_features=256, out_features=33278, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
模型看起来一样;这对我们有什么好处?首先,我们看到模型大小显著减小:
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
Size (MB): 113.944064
Size (MB): 79.738484
其次,我们看到推理时间更快,评估损失没有差异:
注意:我们将线程数设置为一个,以进行单线程比较,因为量化模型是单线程运行的。
torch.set_num_threads(1)
def time_model_evaluation(model, test_data):
s = time.time()
loss = evaluate(model, test_data)
elapsed = time.time() - s
print('''loss: {0:.3f}\nelapsed time (seconds): {1:.1f}'''.format(loss, elapsed))
time_model_evaluation(model, test_data)
time_model_evaluation(quantized_model, test_data)
loss: 5.167
elapsed time (seconds): 205.3
loss: 5.168
elapsed time (seconds): 116.8
在 MacBook Pro 上本地运行,不进行量化推理大约需要 200 秒,进行量化后只需要大约 100 秒。
结论
动态量化可以是一种简单的方法,可以减小模型大小,同时对准确性的影响有限。
感谢阅读!我们随时欢迎任何反馈意见,如果您有任何问题,请在这里创建一个问题。
脚本的总运行时间:(5 分钟 30.807 秒)
下载 Python 源代码:dynamic_quantization_tutorial.py
下载 Jupyter 笔记本:dynamic_quantization_tutorial.ipynb
Sphinx-Gallery 生成的画廊
(beta)BERT 上的动态量化
原文:
pytorch.org/tutorials/intermediate/dynamic_quantization_bert_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
提示
为了充分利用本教程,我们建议使用这个Colab 版本。这将允许您尝试下面介绍的信息。
作者:Jianyu Huang
审阅者:Raghuraman Krishnamoorthi
编辑者:Jessica Lin
介绍
在本教程中,我们将在 BERT 模型上应用动态量化,紧随HuggingFace Transformers 示例中的 BERT 模型。通过这一逐步旅程,我们想演示如何将像 BERT 这样的知名最先进模型转换为动态量化模型。
-
BERT,即来自 Transformers 的双向嵌入表示,是一种新的预训练语言表示方法,在许多流行的自然语言处理(NLP)任务上取得了最先进的准确性结果,例如问答、文本分类等。原始论文可以在这里找到。
-
PyTorch 中的动态量化支持将浮点模型转换为具有静态 int8 或 float16 数据类型的量化模型,用于权重和动态量化用于激活。当权重量化为 int8 时,激活会动态量化(每批次)为 int8。在 PyTorch 中,我们有torch.quantization.quantize_dynamic API,它将指定的模块替换为动态仅权重量化版本,并输出量化模型。
-
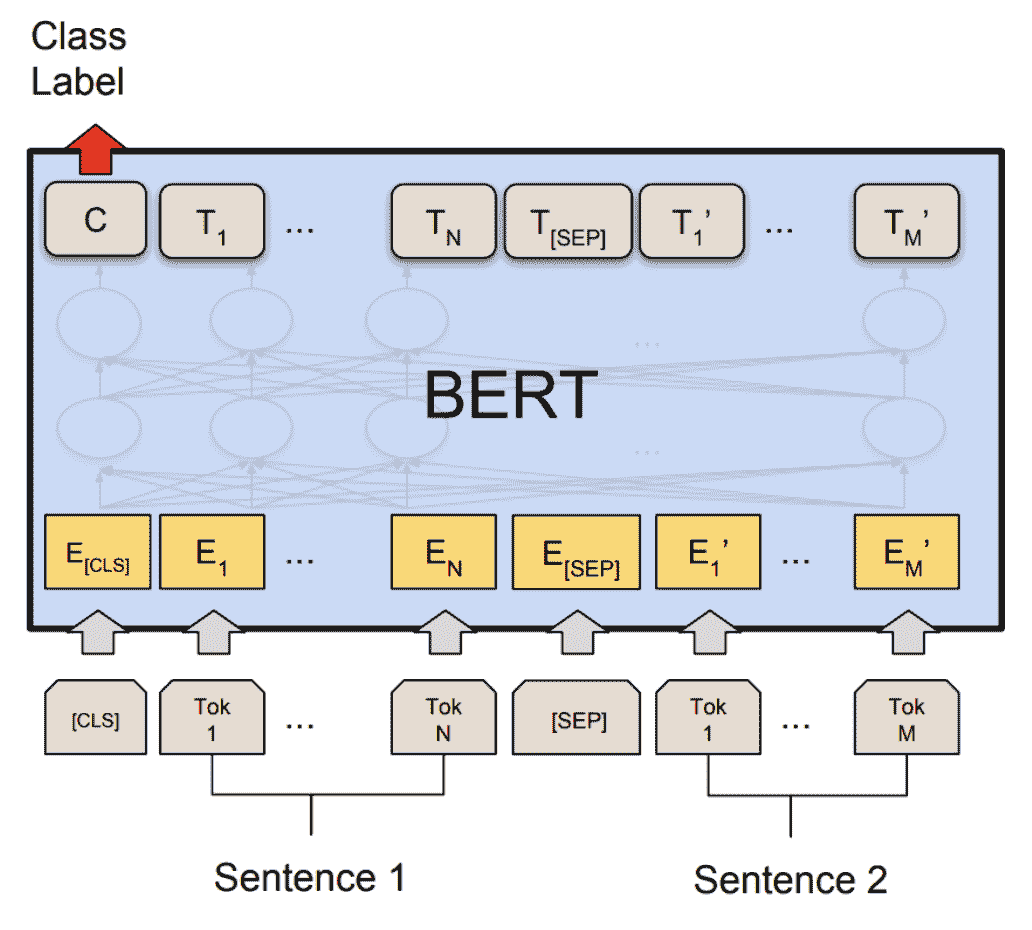
我们在Microsoft Research Paraphrase Corpus (MRPC)任务上展示了准确性和推理性能结果,该任务属于通用语言理解评估基准(GLUE)。MRPC(Dolan 和 Brockett,2005)是从在线新闻来源自动提取的句子对语料库,其中包含对句子是否语义等价的人工注释。由于类别不平衡(68%积极,32%消极),我们遵循常见做法并报告F1 分数。如下所示,MRPC 是一个常见的 NLP 任务,用于语言对分类。
1. 设置
1.1 安装 PyTorch 和 HuggingFace Transformers
要开始本教程,让我们首先按照 PyTorch 的安装说明这里和 HuggingFace Github Repo 这里进行安装。此外,我们还安装scikit-learn包,因为我们将重用其内置的 F1 分数计算辅助函数。
pip install sklearn
pip install transformers==4.29.2
由于我们将使用 PyTorch 的 beta 部分,建议安装最新版本的 torch 和 torchvision。您可以在本地安装的最新说明这里。例如,在 Mac 上安装:
yes y | pip uninstall torch tochvision
yes y | pip install --pre torch -f https://download.pytorch.org/whl/nightly/cu101/torch_nightly.html
1.2 导入必要的模块
在这一步中,我们导入本教程所需的 Python 模块。
import logging
import numpy as np
import os
import random
import sys
import time
import torch
from argparse import Namespace
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler,
TensorDataset)
from tqdm import tqdm
from transformers import (BertConfig, BertForSequenceClassification, BertTokenizer,)
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_output_modes as output_modes
from transformers import glue_processors as processors
from transformers import glue_convert_examples_to_features as convert_examples_to_features
# Setup logging
logger = logging.getLogger(__name__)
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.WARN)
logging.getLogger("transformers.modeling_utils").setLevel(
logging.WARN) # Reduce logging
print(torch.__version__)
我们设置线程数,以比较 FP32 和 INT8 性能之间的单线程性能。在教程结束时,用户可以通过使用正确的并行后端构建 PyTorch 来设置其他线程数。
torch.set_num_threads(1)
print(torch.__config__.parallel_info())
1.3 了解辅助函数
助手函数内置在 transformers 库中。我们主要使用以下助手函数:一个用于将文本示例转换为特征向量;另一个用于测量预测结果的 F1 分数。
glue_convert_examples_to_features函数将文本转换为输入特征:
-
对输入序列进行标记化;
-
在开头插入[CLS];
-
在第一个句子和第二个句子之间以及结尾处插入[SEP];
-
生成标记类型 ID,以指示标记属于第一个序列还是第二个序列。
glue_compute_metrics函数具有计算F1 分数的计算指标,可以解释为精确度和召回率的加权平均值,其中 F1 分数在 1 时达到最佳值,在 0 时达到最差值。精确度和召回率对 F1 分数的相对贡献相等。
- F1 分数的方程式是:
F 1 = 2 ∗ ( 精确度 ∗ 召回率 ) / ( 精确度 + 召回率 ) F1 = 2 * (\text{精确度} * \text{召回率}) / (\text{精确度} + \text{召回率}) F1=2∗(精确度∗召回率)/(精确度+召回率)
1.4 下载数据集
在运行 MRPC 任务之前,我们通过运行此脚本下载GLUE 数据,并将其解压到目录glue_data中。
python download_glue_data.py --data_dir='glue_data' --tasks='MRPC'
2. 微调 BERT 模型
BERT 的精神是预先训练语言表示,然后在广泛的任务上微调深度双向表示,具有最少的任务相关参数,并取得了最先进的结果。在本教程中,我们将重点放在使用预训练的 BERT 模型进行微调,以对 MRPC 任务中的语义等效句子对进行分类。
要为 MRPC 任务微调预训练的 BERT 模型(HuggingFace transformers 中的bert-base-uncased模型),可以按照示例中的命令进行操作:
export GLUE_DIR=./glue_data
export TASK_NAME=MRPC
export OUT_DIR=./$TASK_NAME/
python ./run_glue.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $GLUE_DIR/$TASK_NAME \
--max_seq_length 128 \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--save_steps 100000 \
--output_dir $OUT_DIR
我们为 MRPC 任务提供了微调后的 BERT 模型这里。为节省时间,您可以直接将模型文件(~400 MB)下载到本地文件夹$OUT_DIR中。
2.1 设置全局配置
在这里,我们设置了全局配置,用于在动态量化之前和之后评估微调后的 BERT 模型。
configs = Namespace()
# The output directory for the fine-tuned model, $OUT_DIR.
configs.output_dir = "./MRPC/"
# The data directory for the MRPC task in the GLUE benchmark, $GLUE_DIR/$TASK_NAME.
configs.data_dir = "./glue_data/MRPC"
# The model name or path for the pre-trained model.
configs.model_name_or_path = "bert-base-uncased"
# The maximum length of an input sequence
configs.max_seq_length = 128
# Prepare GLUE task.
configs.task_name = "MRPC".lower()
configs.processor = processors[configs.task_name]()
configs.output_mode = output_modes[configs.task_name]
configs.label_list = configs.processor.get_labels()
configs.model_type = "bert".lower()
configs.do_lower_case = True
# Set the device, batch size, topology, and caching flags.
configs.device = "cpu"
configs.per_gpu_eval_batch_size = 8
configs.n_gpu = 0
configs.local_rank = -1
configs.overwrite_cache = False
# Set random seed for reproducibility.
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(42)
2.2 加载微调后的 BERT 模型
我们从configs.output_dir加载标记化器和微调后的 BERT 序列分类器模型(FP32)。
tokenizer = BertTokenizer.from_pretrained(
configs.output_dir, do_lower_case=configs.do_lower_case)
model = BertForSequenceClassification.from_pretrained(configs.output_dir)
model.to(configs.device)
2.3 定义标记化和评估函数
我们重用了Huggingface中的标记化和评估函数。
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
def evaluate(args, model, tokenizer, prefix=""):
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
eval_outputs_dirs = (args.output_dir, args.output_dir + '-MM') if args.task_name == "mnli" else (args.output_dir,)
results = {}
for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
os.makedirs(eval_output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset) if args.local_rank == -1 else DistributedSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu eval
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[3]}
if args.model_type != 'distilbert':
inputs['token_type_ids'] = batch[2] if args.model_type in ['bert', 'xlnet'] else None # XLM, DistilBERT and RoBERTa don't use segment_ids
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
if args.output_mode == "classification":
preds = np.argmax(preds, axis=1)
elif args.output_mode == "regression":
preds = np.squeeze(preds)
result = compute_metrics(eval_task, preds, out_label_ids)
results.update(result)
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return results
def load_and_cache_examples(args, task, tokenizer, evaluate=False):
if args.local_rank not in [-1, 0] and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
processor = processors[task]()
output_mode = output_modes[task]
# Load data features from cache or dataset file
cached_features_file = os.path.join(args.data_dir, 'cached_{}_{}_{}_{}'.format(
'dev' if evaluate else 'train',
list(filter(None, args.model_name_or_path.split('/'))).pop(),
str(args.max_seq_length),
str(task)))
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
label_list = processor.get_labels()
if task in ['mnli', 'mnli-mm'] and args.model_type in ['roberta']:
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
examples = processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
features = convert_examples_to_features(examples,
tokenizer,
label_list=label_list,
max_length=args.max_seq_length,
output_mode=output_mode,
pad_on_left=bool(args.model_type in ['xlnet']), # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4 if args.model_type in ['xlnet'] else 0,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
if args.local_rank == 0 and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
if output_mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif output_mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
3. 应用动态量化
我们在模型上调用torch.quantization.quantize_dynamic,对 HuggingFace BERT 模型应用动态量化。具体来说,
-
我们指定希望模型中的 torch.nn.Linear 模块被量化;
-
我们指定希望权重转换为量化的 int8 值。
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
3.1 检查模型大小
让我们首先检查模型大小。我们可以观察到模型大小显著减小(FP32 总大小:438 MB;INT8 总大小:181 MB):
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
本教程中使用的 BERT 模型(bert-base-uncased)具有 30522 个词汇大小 V。具有 768 的嵌入大小,单词嵌入表的总大小为~4(字节/FP32)* 30522 * 768 = 90 MB。因此,在量化的帮助下,非嵌入表部分的模型大小从 350 MB(FP32 模型)减少到 90 MB(INT8 模型)。
3.2 评估推理准确性和时间
接下来,让我们比较原始 FP32 模型和动态量化后的 INT8 模型之间的推理时间和评估准确性。
def time_model_evaluation(model, configs, tokenizer):
eval_start_time = time.time()
result = evaluate(configs, model, tokenizer, prefix="")
eval_end_time = time.time()
eval_duration_time = eval_end_time - eval_start_time
print(result)
print("Evaluate total time (seconds): {0:.1f}".format(eval_duration_time))
# Evaluate the original FP32 BERT model
time_model_evaluation(model, configs, tokenizer)
# Evaluate the INT8 BERT model after the dynamic quantization
time_model_evaluation(quantized_model, configs, tokenizer)
在 MacBook Pro 上本地运行,不进行量化时,推理(对 MRPC 数据集中的所有 408 个示例)大约需要 160 秒,而进行量化后,只需要大约 90 秒。我们总结了在 MacBook Pro 上运行量化 BERT 模型推理的结果如下:
| Prec | F1 score | Model Size | 1 thread | 4 threads |
| FP32 | 0.9019 | 438 MB | 160 sec | 85 sec |
| INT8 | 0.902 | 181 MB | 90 sec | 46 sec |
在对 MRPC 任务上对微调后的 BERT 模型应用后训练动态量化后,我们的 F1 分数准确率降低了 0.6%。作为对比,在一篇最近的论文(表 1)中,通过应用后训练动态量化获得了 0.8788,通过应用量化感知训练获得了 0.8956。主要区别在于我们支持 PyTorch 中的不对称量化,而该论文仅支持对称量化。
请注意,在本教程中,我们将线程数设置为 1 以进行单线程比较。我们还支持这些量化 INT8 运算符的 intra-op 并行化。用户现在可以通过torch.set_num_threads(N)(N是 intra-op 并行化线程数)来设置多线程。启用 intra-op 并行化支持的一个初步要求是使用正确的后端构建 PyTorch,如 OpenMP、Native 或 TBB。您可以使用torch.__config__.parallel_info()来检查并行设置。在同一台 MacBook Pro 上使用具有 Native 后端的 PyTorch 进行并行化,我们可以在大约 46 秒内处理 MRPC 数据集的评估。
3.3 序列化量化模型
在跟踪模型后,我们可以序列化和保存量化模型以备将来使用,使用 torch.jit.save。
def ids_tensor(shape, vocab_size):
# Creates a random int32 tensor of the shape within the vocab size
return torch.randint(0, vocab_size, shape=shape, dtype=torch.int, device='cpu')
input_ids = ids_tensor([8, 128], 2)
token_type_ids = ids_tensor([8, 128], 2)
attention_mask = ids_tensor([8, 128], vocab_size=2)
dummy_input = (input_ids, attention_mask, token_type_ids)
traced_model = torch.jit.trace(quantized_model, dummy_input)
torch.jit.save(traced_model, "bert_traced_eager_quant.pt")
要加载量化模型,我们可以使用 torch.jit.load
loaded_quantized_model = torch.jit.load("bert_traced_eager_quant.pt")
结论
在本教程中,我们演示了如何将像 BERT 这样的知名最先进的 NLP 模型转换为动态量化模型。动态量化可以减小模型的大小,同时对准确性的影响有限。
感谢阅读!我们一如既往地欢迎任何反馈,如果您有任何问题,请在此处提出。
参考文献
[1] J.Devlin, M. Chang, K. Lee and K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018).
[2] HuggingFace Transformers.
[3] O. Zafrir, G. Boudoukh, P. Izsak, and M. Wasserblat (2019). Q8BERT: Quantized 8bit BERT.