3.8 Redis基数统计(HyperLogLog)
需求
统计某个网站的UV、统计某个文章的UV
-
什么是UV
-
unique Visitor ,独立访客,一般理解为客户端IP
-
大规模的防止作弊,需要去重复统计独立访客
比如IP同样就认为是同一个客户
-
-
需要去重考虑
-
用户搜索网站的关键词的数量
统计用户每天搜索不同词条个数
是什么?
去重复统计功能的基数估计算法-就是HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总 是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HvoerLogL0g 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HvperLogLog 不能像集合那样,返回输入的各个元素。
何为基数
是一种数据集,去重复后的真实个数

基数统计
用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
即:去重脱水后的真实数据 , 有0.81%的差
基本命令
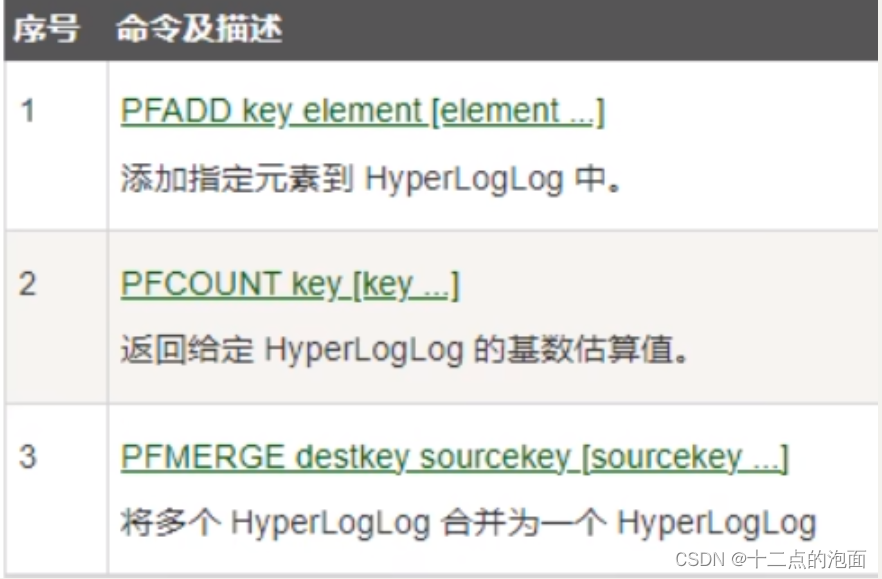
pfadd hll01 1 3 5 7 9
pfadd hll01 1 2 3 4 4 4 5 9 10
pfcount hll01 #输出 5
pfcount hll02 #输出 6
pfmerge hllresult hll01 hll02
pfcount hllresult #输出 8



![[大厂实践] Pinterest通用计算平台实践](https://img-blog.csdnimg.cn/img_convert/098e178bbff342e880248bcf845652ce.png)