文章目录
- 前言
- 一、用户登录设计
- 二、图像采集设计
- 1.本地视频
- 2.摄像头
- 3.RTSP
- 三、人脸识别原理
- 1.人脸库的建立及训练
- 2. 人脸检测算法的实现
- 3. 人脸识别算法的实现
- 四、数据存储设计
- 1.SQLite3
- 2.Excel
- 五、网络通信设计
- 1.邮件通知
- 2.阿里云
- 六、其他不重要功能展示
- 1.年龄、性别和表情识别
- 2.口罩检测
- 3.目标检测(YOLOv5)
- 4.自动驾驶全景分割
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
这个工程是机器视觉的课程设计作业涉及OpenCV图像处理、DNN网络模型部署、Mqtt阿里云连接以及SMTP邮件发送等几个知识点,以上基于Qt(C++)和OpenCV实现的,趁着寒假简单记录一下开发过程哈哈哈!

一、用户登录设计
在本项目中,使用该程序的用户可以注册个人信息、然后使用注册后的信息进行登录,注册的信息会保存到本地的sqlite3数据库,只要用户不注销,这边就会一直保存用户的信息,并且对用户设置的的密码进行MD5的加密。
MD5算法为计算机安全领域广泛使用的一种散列函数,用于提供消息的完整性,是计算机广泛使用的哈希算法之一。MD5算法叫做讯息摘要演算法,所谓摘要,从字面意思理解,是指内容的大概。在MD5算法中,这个摘要是指将任意数据映射成一个128位长的摘要信息。并且其是不可逆的,即从摘要信息无法反向推演中原文,在演算过程中,原文的内容也是有丢失的。
因为MD5算法最终生成的是一个128位长的数据,从原理上说,有2^128种可能,这是一个非常巨大的数据,约等于3.4乘10的38次方,虽然这个是个天文数字,但是世界上可以进行加密的数据原则上说是无限的,因此是可能存在不同的内容经过MD5加密后得到同样的摘要信息,但这个碰中的概率非常小。
MD5常用在密码加密中,一般为了保证用户密码的安全,在数据库中存储的都是用户的密码经过MD5加密后的值,在客户端用户输入密码后,也会使用MD5进行加密,这样即使用户的网络被窃听,窃听者依然无法拿到用户的原始密码,并且即使用户数据库被盗,没有存储明文的密码对用户来说也多了一层安全保障。如下图所示,在数据库中存储的就是用户的密码经过MD5处理后的数据。

MD5签名技术还常用于防止信息的篡改。使用MD5可以对信息进行签名,接收者拿到信息后只要重新计算签名和原始签名进行对比,即可知道数据信息是否中途被篡改了。
以下是程序的登录界面和注册界面设计。


二、图像采集设计
在本项目中图像的采集可以有三种来源:本地视频、摄像头、RTSP拉流,并且采用多线程可以同时处理四路视频流,可以通过双击鼠标右键进行某一个通道的放大与缩小。
1.本地视频
通过OpenCV从本地中读取多个视频,并将读取的视频使用QT界面进行实时显示出来。本地视频如下图所示。

这些视频从网上下载来,也可以通过录屏获取,然后保存在本地电脑上,通过选择不同的视频路径进行显示不同的视频流。并且不同的分辨率QT显示或者图像处理速度都有一定的差异,QT界面通过本地视频进行显示如下。

通过OpenCV直接读取本地视频处理,方便简单,但是应用场景受限。
2.摄像头
通过OpenCV从USB摄像头中读取视频流,并将读取的视频流使用QT界面进行实时显示出来。摄像头读取视频流如下图所示。

由于小组内只有一个摄像头,只针对通道1从摄像头中读取视频流,其他通道默认从本地视频中读取。通过OpenCV从摄像头读取视频流,方便比较简单,但是在加入比较复杂的图像处理算法,会受到摄像头本身采样率的限制,延时比较高。
3.RTSP
RTSP(Real Time Streaming Protocol 实时流协议)是一个实时传输流协议,是一个应用层的协议。RTSP建立并控制一个或几个时间同步的连续流媒体,对媒体流提供了诸如开始、暂停、快进、停止等控制,RTSP的作用相当于流媒体服务器的远程控制,而它本身并不传输数据。
RTSP是由Real network 和 Netscape共同提出的如何有效地在IP网络上传输流媒体数据的应用层协议,RTSP提供一种可扩展的框架,使能够提供能控制的,按需传输实时数据,如音频流、视频流、metadata; 遵循规范IETF RFC 2326,4567,6064,其语法和操作参考了HTTP/1.1,基于文本的协议,采用ISO10646字符集,使用UTF-8编码;承载RTSP的传输层协议为TCP,默认端口554;如果是RTSP-over-HTTP tunneling,则默认TCP端口为8080;实时流数据由不同的协议传输,比如RTP/RTCP完成数据流和控制命令的传输。
通常说的RTSP包括RTSP协议、RTP协议、RTCP协议。RTSP协议:负责服务器与客户端之间的请求与响应;RTP协议:负责传输媒体数据;RTCP协议:在RTP传输过程中提供传输信息;RTSP承载与RTP和RTCP之上,RTSP并不会发送媒体数据,而是使用RTP协议传输,RTP并没有规定发送方式,可以选择UDP发送或者TCP发送。
我们小组在Linux下搭建RTSP流媒体服务器,然后使用FFmpeg 将本地的视频进行推流,模拟从网络摄像头拉流进行图像的显示。
FFmpeg 是一个免费、开源的跨平台视频和音频流处理工具,其包含了大量处理视频的指令:
- UDP推流
ffmpeg -re -i input.mp4 -c copy -f rtsp rtsp://127.0.0.1:8554/stream
- TCP推流
ffmpeg -re -i input.mp4 -c copy -rtsp_transport tcp -f rtsp rtsp://127.0.0.1:8554/stream
- 循环推流
ffmpeg -re -stream_loop -1 -i input.mp4 -c copy -f rtsp rtsp://127.0.0.1:8554/stream
其中,-re 为以流的方式读取;-stream_loop 为循环读取视频源的次数,-1为无限循环;-i 为输入的文件;-f 为格式化输出到哪里;
在Linux终端中启用FFmpeg进行推流,推流过程如下:

在QT程序界面显示如下所示。

因为同时在使用FFmpeg进行推流以及拉流,处理视频的编解码工作量还是比较大的,并且没有使用GPU处理,如果同时推流、拉流不同分辨率的视频,界面就会比较卡顿,一般直接从网络摄像头读取视频流比较高效,低延迟的。
三、人脸识别原理
1.人脸库的建立及训练
人脸数据库中每个用户的人脸图像一张,主要为正脸图像或者微侧脸图像。人脸库的数据全部存放于一个名为face的文件夹,图片命名以”姓名“命名。如下图所示:

人脸库模型训练,是将人脸库中各个人的人脸图像进行处理,将人脸的特征提取出来并分类,训练样本, 并给样本打上标签。为了和后面人脸识别得的标签进行对比。本系统可以支持线上/线下注册人脸数据库。
人脸注册数据库登录界面如下所示,左边填写用户的个人信息,右边是人脸信息采集区,下面是所有的人脸考勤信息表格,可以看到与人脸数据库中的图片是一一对应的,在这个界面添加的人脸的数据,其图片会保存在该目录下。

2. 人脸检测算法的实现
几十年来,人脸检测一直是计算机视觉领域一个很有吸引力的话题。它是人脸识别、人脸美化、人脸对齐、人脸跟踪等人脸相关应用的一个先决条件。给定一幅图像,人脸检测通过包围框来定位人脸区域。从早期手工制作的特征(Haar)到目前基于cnn的特征,已经提出了许多方法来提高人脸检测性能。基于cnn的单级探测器近年来受到了广泛的欢迎。
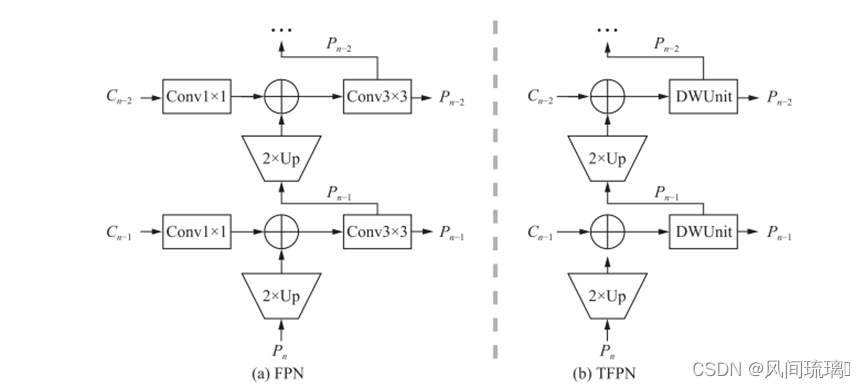
人脸检测使用YuNet网络,它是专门为边缘设备设计的,在提高效率和准确性方面有几个关键的贡献,其设计了一个用于人脸检测的微型网络。一个原则是专注于困难的小人脸,并从容易的大人脸中去除计算成本。另一种方法是用深度卷积和点卷积来代替标准卷积。YuNet 架构如下图所示,它包含一个Backbone、一个微小的特征金字塔网络(TFPN)的颈部和头部。

(1)Backbone
Backbone是网络的主体,用于提取特征进行检测,它必须是高效和轻量级的,要将卷积神经网络部署到设备上,就需要具有更少参数和更快速度的高效单元。深度可分卷积是分解卷积的一种形式,它将标准卷积分解为深度卷积和点卷积,它最初来自MobileNet网络。3×3深度可分卷积可实现约1/9到1/8的计算和参数代价的3×3标准卷积,唯一缺点是精度可能略有下降。YuNet中的DWUnit是由深度可分卷积及其后的批量归一化和激活层创建的,是该网络的主要模块。另一个模块是DWBlock单元,它包含两个DWUnit,其设计如上图的右上角所示。
Backbone由5个Stage组成。Stage0包含一个标准的卷积层(其卷积核为3x3,stride为2,然后经过BN层和Relu层)和DWUnit单元。Staege0之后是Stage1,它包含一个 Max-pooling和两个DWBlocks,并且通道数翻了4倍。前两个Stage将特征图减少到输入尺寸的1/4,并将通道从3增加到64。其余三个Stage:Stage 2-4,使用完全相同的网络结构,并将它们的分层输出特征映射到TFPN的颈部。
(2)TFPN
颈部用于融合多尺度特征以获得更高层次的特征。在YuNet 中,TFPN颈部利用了FPN和深度可分离卷积。由于Stage2的特征图深度不同,可以将Stage 4的特征图视为高级特征,而将Stage2的特征图视为低级特征。FPN引入自上向下和横向连接,结合多尺度特征。FPN中的自上向下路径可以通过从更高的金字塔层次上采样特征图来生成更高分辨率的特征。这些连接结合了来自主干和自顶向下路径的相同空间大小的特征图。下图显示了FPN融合多尺度特征的过程。
其融合可表示为: P i = F i ( R d i m ( C i ) + R s i z e ( C ( i + 1 ) ) ) P_i=F_i (R_{dim} (C_i)+R_{size} (C_(i+1))) Pi=Fi(Rdim(Ci)+Rsize(C(i+1)))
其 R d i m R_{dim} Rdim用于尺寸匹配的通道调整操作, R s i z e R_{size} Rsize是分辨率匹配的上采用操作,而 F i F_i Fi通常是用于特征处理的卷积运算。上图中(a)中的1x1卷积、2xUp和3x3卷积对应这三种操作。
然而,FPN中的标准卷积层计算量大,需要训练的参数较多。TFPN颈部使用深度可分离卷积来代替标准卷积。如上图(b)所示,DWUnit 取代了 FPN 的 Conv3×3。DWUnit是Backbone和neck的主要模块。它可以将FPN的参数数量减少到12%。计算成本也大大降低
(3)Head
YuNet Head采用无锚机制。与基于锚点的RetinaFace,相比,它将每个位置的候选值从 2个以上减少到1个,并让它们直接预测一个位置的四个值,即左上角的两个值、框的高度和宽度。并且采用了简单最优运输分配(simOTA)。对于正锚匹配。对于任何匹配的候选对象,计算预测的包围盒与 ground truth之间的并集(IOU)的交集作为软标签。然后利用 Crossentro- pyLoss 计算分类损失。边界盒回归、地标性回归和对象性的损失分别为扩展iouloss (EIOU)。SmoothL1Loss 和CrossEntropyLoss。在训练阶段,最小化多任务损失为:
L
=
1
/
N
∑
1
N
(
L
c
l
s
+
α
1
L
o
b
j
+
α
2
L
b
b
o
x
+
α
3
L
l
d
m
)
L=1/N ∑_1^N(L_{cls}+α_1 L_{obj}+α_2 L_{bbox}+α_3 L_{ldm})
L=1/N∑1N(Lcls+α1Lobj+α2Lbbox+α3Lldm)
式中,N为正样本总数。超参数 α 1 α_1 α1、 α 2 α_2 α2和 α 3 α_3 α3推荐值分别为1.0、5.0和0.1。
测试结果如下,YuNet网络模型成功地从下图中大约1000张报告的人脸中检测出619张。未被检测到的人脸只有几个像素,是模糊的,不能被人眼识别。在实际应用程序中,可以直接忽略它们。

其网络模型转换为onnx如下:

论文链接:https://github.com/ShiqiYu/libfacedetection.train
3. 人脸识别算法的实现
人脸识别是一项经典的人工智能应用。得益于海量的训练数据和深度学习的技术发展,人脸识别取得了突破性的性能提升,成为一项广泛应用的生物识别技术。
但人脸识别仍然存在诸多挑战:高质量的训练数据是高性能识别模型的基础,然而目前学术界可用的数据集存在诸多缺陷;隐私保护限制使得互联网上可收集的名人图像数据与现实应用场景存在差异;数据集呈现长尾分布,大量名人缺少充足的样本描述;数据集存在的严重噪声,例如低质量图片和标签噪声等。
为了解决这一难题,北京邮电大学邓伟洪教授团队设计了一种新型的S型约束球面损失函数SFace,通过S型函数分别对类内/类间损失产生的反馈梯度进行编辑,自适应地减小噪声样本对模型训练的影响,在多个人脸识别数据集上取得了最高的识别精度,提高了人脸识别的稳定性。
下图展示了SFace的整体示意图,该方法旨在有节制地增大类间距离而减小类内距离。考虑到大间隔鉴别损失函数的类内类间优化耦合,难以分别实现精确控制,形式上作者放弃了基于Softmax的损失函数,从最基本的思想出发:在一定程度上优化类内和类间距离,以提高模型的泛化能力。

对于训练样本的深度特征xi,优化方向始终沿着超球体的切线,而移动速度则由设计的梯度精确控制。xi与其目标中心Wyi的移动速度随着彼此靠近而逐渐减小,而xi与其他目标中心Wj的移动速度随着彼此开始靠近而迅速增大。在一定程度上优化训练样本,SFace 可以在减少干净样本的类内距离和防止过度拟合标签噪声之间取得更好的平衡,并有助于提供更鲁棒的深度人脸识别模型。

如上图,在标签噪声设置下,通过将带噪样本严格拖动到错误的标签标识,模型将过度适应标签噪声。相比之下,SFace可以在一定程度上缓解这一问题,因为它以温和的方式优化了噪声样本。通过精确控制,干净的训练样本可以更早、更轻松地进行优化,而标签噪声可以留在后面。
其网络模型导出onnx如下:

论文链接:https://github.com/zhongyy/SFace
人脸识别网络模型结构比较单一,只有一条支路用于提取人脸特征,最终输入128维的人脸特征向量。人脸识别结果如下所示,其准确率都还是比较高的。

四、数据存储设计
1.SQLite3
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。SQLite第一个Alpha版本诞生于2000年5月。 至2021年已经接近有21个年头,SQLite也迎来了一个版本 SQLite 3已经发布。
不像常见的客户-服务器范例,SQLite引擎不是个程序与之通信的独立进程,而是连接到程序中成为它的一个主要部分。所以主要的通信协议是在编程语言内的直接API调用。这在消耗总量、延迟时间和整体简单性上有积极的作用。整个数据库(定义、表、索引和数据本身)都在宿主主机上存储在一个单一的文件中。它的简单的设计是通过在开始一个事务的时候锁定整个数据文件而完成的。
在本程序中,我们小组采用SQLite3数据库存储了用户登录信息、人脸信息以及人员的考勤信息,数据以文件形式存储,可以在本地电脑上随时访问。如下图所示打开db文件可以看到用户的考勤情况,

同时在程序中,我们小组使用Qt的表格将数据库中的信息进行显示,如下图所示。

在该界面还可以设置考勤时间,搜索,删除以及修改表格中有误的信息,这些操作都会同步至数据库中。
2.Excel
在上面人员统计信息界面中还可以将数据库中的表格信息导出至Excel中,这样也能方便管理员进行统计和分析考勤情况,导出Excel如下图所示。

五、网络通信设计
1.邮件通知
电子邮件是一种异步通信方式,通信时不需要双方同时在场,发送者把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可以随时上网到自己使用的邮件服务器进行读取,如下图所示。

Email主要分为三大部分:
- 邮件客户端
邮件客户端(User Agent)是一种应用程序,允许用户读取和编写电子邮件消息。通过与邮件服务器的交互,用户可以接收和发送电子邮件。一些常见的邮件客户端应用包括Outlook、Foxmail和Thunderbird。此外,还有基于Web的邮件客户端,用户可以通过浏览器访问,例如Gmail、Outlook Web App等。这些客户端通过提供用户友好的界面和功能,使得电子邮件的管理变得更加方便和高效。
- 邮件服务器(组成电子邮件系统的核心)
邮件服务器是电子邮件系统的核心组件,以客户/服务器方式工作。其主要功能包括维护用户邮箱,存储接收和发送的邮件,以及维护消息队列,确保邮件按顺序发送。邮件服务器既充当客户端接收邮件,又充当服务器传递邮件至目标用户或下一个邮件服务器,实现了电子邮件系统的正常运作。
- 电子邮件使用的协议(SMTP、POP3)
电子邮件系统使用两种关键的协议来实现邮件的发送和接收。
①邮件发送协议:用于用户代理(邮件客户端)向邮件服务器发送邮件或在邮件服务器之间发送邮件。SMTP(Simple Mail Transfer Protocol)是用于电子邮件的标准发送协议,它定义了邮件是如何从发件人传输到接收人的过程。
②邮件读取协议:用于用户代理从邮件服务器读取邮件。POP3(Post Office Protocol 3)是一种常用的邮件读取协议,它允许用户从邮件服务器下载邮件到本地设备。用户可以通过POP3协议检索邮件,通常在检索后会将邮件从服务器删除,尽管也有一些配置选项可以保留在服务器上的副本。
这两个协议在电子邮件系统中扮演着不同但关键的角色,SMTP负责发送,而POP3负责接收和下载邮件。
SMTP采用的是”推“(Push)的通信方式,即在用户代理向邮件服务器发送邮件及在邮件服务器之间发送邮件时,SMTP客户端主动将邮件“推”送到SMTP服务器端;POP3采用的是“拉”(Pull)的通信方式,即用户读取邮件时,用户代理向邮件服务器发出请求,“拉”取用户邮箱中的邮件。
因此,要想实现邮件的通知功能只需要实现SMTP协议即可。SMTP协议是邮件服务器之间传递消息所使用的协议:SMTP规定了在两个相互通信的SMTP进程之间应如何交换信息,负责发送邮件的SMTP进程是SMTP客户,负责接收邮件的进程是SMTP服务器。SMTP规定了14条命令和21种应答信息,如下图所示SMTP发送过程。

在程序中邮件发送界面设计如下,可以设置收发邮件的用户信息,需注意的是发送用户的邮件需要开启STMP服务器。

这里将考勤的信息发送至QQ邮箱,如下图所示。

2.阿里云
将用户考勤信息发送到阿里云服务器中是为了方便连接网页或者小程序访问,使得管理员可以实时查看数据。这里使用MQTT协议与阿里云服务器进行通信。MQTT 是用于物联网 (IoT) 的 OASIS 标准消息传递协议。它被设计为一种极其轻量级的发布/订阅消息传输,如下图所示,非常适合以较小的代码占用空间和最小的网络带宽连接远程设备。如今,MQTT 已广泛应用于各个行业,例如汽车、制造、电信、石油和天然气等。

MQTT(Message Queuing Telemetry Transport),是一种基于发布/订阅(publish/subscribe)模式的"轻量级"通讯协议,如下图所示,该协议构建于TCP/IP协议上。

与请求/回答这种同步模式不同,发布/订阅模式解耦了发布消息的客户(发布者)与订阅消息的客户(订阅者)之间的关系,这意味着发布者和订阅者之间并不需要直接建立联系。一个发布者可以对应多个订阅者,当发布者发生变化的时候,他可以将消息一一通知给所有的订阅者。这种模式提供了更大的网络扩展性和更动态的网络拓扑。
从上图,我们知道实现MQTT协议需要:客户端和服务器端。在MQTT协议中有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为主题(Topic)和负载(payload)两部分。Topic,可以理解为消息的类型,订阅者订阅(Subscribe)后,就会收到该主题的消息内容(payload);payload,可以理解为消息的内容,是指订阅者具体要使用的内容。
MQTT最大优点在于,可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务,可以扩展以连接数百万个物联网设备。作为一种低开销、低带宽占用的即时通讯协议,使其在物联网、小型设备、移动应用等方面有较广泛的应用。
在本程序中使用官方提供的MQTT库配合Qt可以轻松实现上述功能,MQTT客户端设计界面如下所示。可以设置主机名和设备名、客户端以及端口,注意需要与阿里云服务器那边的设置相对应。

更新至阿里云的信息如下图所示。

六、其他不重要功能展示
这里就懒得去写啥原理性的东西啦哈哈哈哈,大部分模型基本上是从github上找的,直接看结果吧哈哈哈。
1.年龄、性别和表情识别

2.口罩检测

3.目标检测(YOLOv5)

4.自动驾驶全景分割

结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。



![[SWPUCTF 2021 新生赛]easyrce](https://img-blog.csdnimg.cn/direct/5d2217fae293475584b667610897cf89.png)