一、状态码
200 – 服务器成功返回网页
404 – 请求的网页不存在
503 – 服务器超时
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态码。
100(继续) 请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
表示成功处理了请求的状态码。
200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果是对您的 robots.txt 文件显示此状态码,则表示 Googlebot 已成功检索到该文件。
201(已创建) 请求成功并且服务器创建了新的资源。
202(已接受) 服务器已接受请求,但尚未处理。
203(非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204(无内容) 服务器成功处理了请求,但没有返回任何内容。
205(重置内容) 服务器成功处理了请求,但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向)
要完成请求,需要进一步操作。通常,这些状态码用来重定向。Google 建议您在每次请求中使用重定向不要超过 5 次。您可以使用网站管理员工具查看一下 Googlebot 在抓取重定向网页时是否遇到问题。诊断下的网络抓取页列出了由于重定向错误导致 Googlebot 无法抓取的网址。
300(多种选择) 针对请求,服务器可执行多种操作。服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301(永久移动) 请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
302(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
303(查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
如果网页自请求者上次请求后再也没有更改过,您应将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,进而节省带宽和开销。
305(使用代理) 请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。
307(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 <a href=answer.py?answer=>301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个页面或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
4xx(请求错误)
这些状态码表示请求可能出错,妨碍了服务器的处理。
400(错误请求) 服务器不理解请求的语法。
401(未授权) 请求要求身份验证。对于登录后请求的网页,服务器可能返回此响应。
403(禁止) 服务器拒绝请求。如果您在 Googlebot 尝试抓取您网站上的有效网页时看到此状态码(您可以在 Google 网站管理员工具诊断下的网络抓取页面上看到此信息),可能是您的服务器或主机拒绝了 Googlebot 访问。
404(未找到)
服务器找不到请求的网页。例如,对于服务器上不存在的网页经常会返回此代码。
如果您的网站上没有 robots.txt 文件,而您在 Google 网站管理员工具“诊断”标签的 robots.txt 页上看到此状态码,则这是正确的状态码。但是,如果您有 robots.txt 文件而又看到此状态码,则说明您的 robots.txt 文件可能命名错误或位于错误的位置(该文件应当位于顶级域,名为 robots.txt)。
如果对于 Googlebot 抓取的网址看到此状态码(在”诊断”标签的 HTTP 错误页面上),则表示 Googlebot 跟随的可能是另一个页面的无效链接(是旧链接或输入有误的链接)。
405(方法禁用) 禁用请求中指定的方法。
406(不接受) 无法使用请求的内容特性响应请求的网页。
407(需要代理授权) 此状态码与 <a href=answer.py?answer=35128>401(未授权)类似,但指定请求者应当授权使用代理。如果服务器返回此响应,还表示请求者应当使用代理。
408(请求超时) 服务器等候请求时发生超时。
409(冲突) 服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,以及两个请求的差异列表。
410(已删除) 如果请求的资源已永久删除,服务器就会返回此响应。该代码与 404(未找到)代码类似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。如果资源已永久移动,您应使用 301 指定资源的新位置。
411(需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415(不支持的媒体类型) 请求的格式不受请求页面的支持。
416(请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态码。
417(未满足期望值) 服务器未满足”期望”请求标头字段的要求。
5xx(服务器错误)
这些状态码表示服务器在处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
500(服务器内部错误) 服务器遇到错误,无法完成请求。
501(尚未实施) 服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
502(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503(服务不可用) 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
504(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505(HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
二、https
1、什么是https
https是基于http协议的,通过对http的传输加密和身份认证保证了传输的安全性。如果你还 不了解http请看阿鲤的这篇博客简单介绍http协议;
https的主要作用:
对数据进行加密,并建立一个信息安全通道,来保证传输过程数据的安全;对网站服务器进行真实的身份认证。 比如我们访问一个https会发现上面有一个锁:
2、为什么需要https
这是因为http协议没有对数据加密和身份认证,在传输过程中是明文的,这样就会导致很多问题,比如数据泄露,数据篡改,流量劫持,钓鱼攻击。
那么https就是来解决这个问题的,首先需要明白的是http并非应用层的新协议,而是将http通信接口部分用SSL和STL协议所代替 + 数字签证;
3、加密算法
据记载,公元前400年,古希腊人就发明了置换密码;在第二次世界大战期间,德国军方启用了“恩尼格玛”密码机,所以密码学在社会发展中有着广泛的用途。
(1)对称加密
有流式、分组两种,加密和解密都是使用的同一个密钥。
例如:DES、AES-GCM、ChaCha20-Poly1305等
(2)、非对称加密
加密使用的密钥和解密使用的密钥是不相同的,分别称为:公钥、私钥,公钥和算法都是公开的,私钥是保密的。非对称加密算法性能较低,但是安全性超强,由于其加密特性,非对称加密算法能加密的数据长度也是有限的。
例如:RSA、DSA、ECDSA、 DH、ECDHE
(3)、哈希算法
将任意长度的信息转换为较短的固定长度的值,通常其长度要比信息小得多,且算法不可逆。
例如:MD5、SHA-1、SHA-2、SHA-256 等
(4)、数字签名
签名就是在信息的后面再加上一段内容(信息经过hash后的值),可以证明信息没有被修改过。hash值一般都会加密后(也就是签名)再和信息一起发送,以保证这个hash值不被修改。
4、HTTPS的加密流程
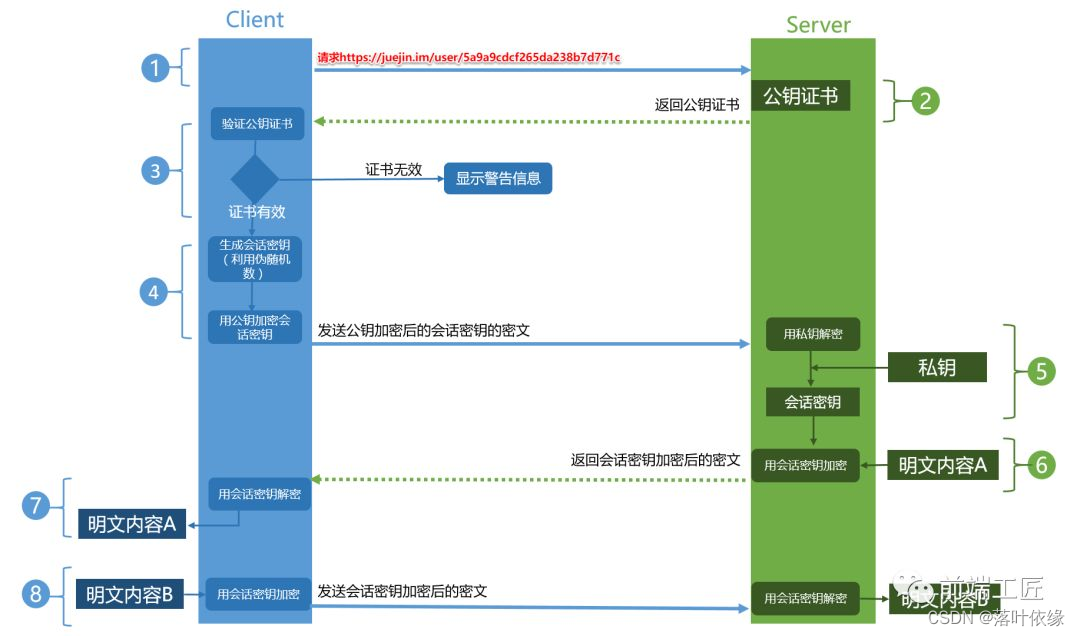
5、HTTPS 缺点:
(1)、SSL 证书费用很高,以及其在服务器上的部署、更新维护非常繁琐
(2)、HTTPS 降低用户访问速度(多次握手)
(3)、网站改用HTTPS 以后,由HTTP 跳转到 HTTPS 的方式增加了用户访问耗时(多数网站采用302跳转)
(4)、HTTPS 涉及到的安全算法会消耗 CPU 资源,需要增加大量机器(https访问过程需要加解密
三、dns解析过程
域名解析包含两种查询方式,分别是递归查询和迭代查询。
递归查询
如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。
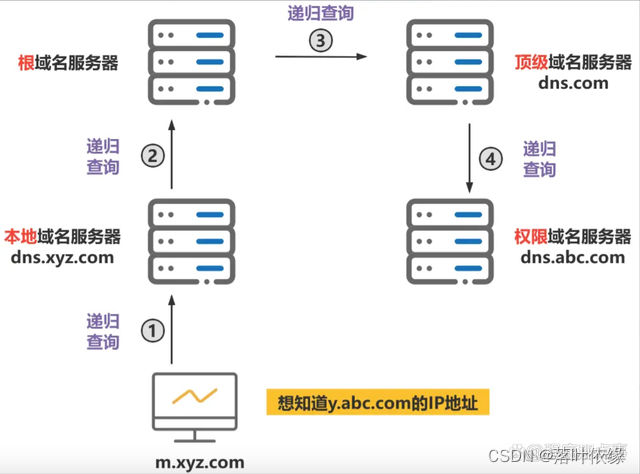
我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。
1、主机首先向其本地域名服务器进行递归查询。
2、本地域名服务器收到递归查询的委托后,也采用递归查询的方式向某个根域名服务器查询。
3、根域名服务器收到递归查询的委托后,也采用递归查询的方式向某个顶级域名服务器查询。
4、顶级域名服务器收到递归查询的委托后,也采用递归查询的方式向某个权限域名服务器查询。
过程如图所示:
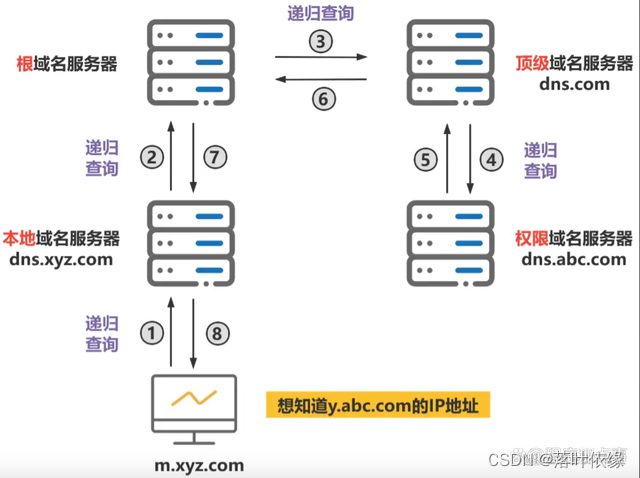
当查询到域名对应的IP地址后,查询结果会在之前受委托的各域名服务器之间传递,最终传回给用户主机。
过程如图所示:
迭代查询
当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。
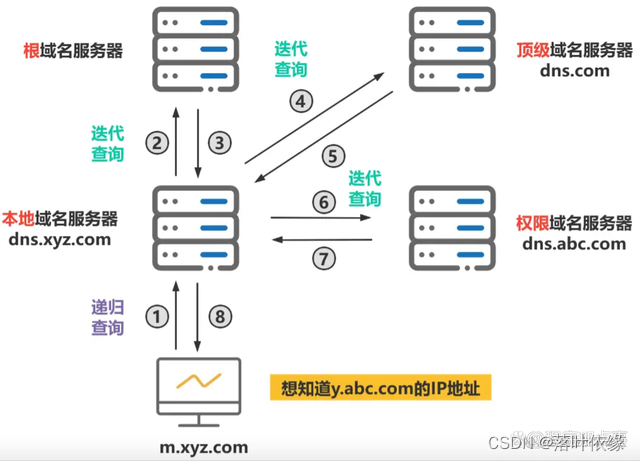
迭代查询过程如下:
1、主机首先向其本地域名服务器进行递归查询。
2、本地域名服务器采用迭代查询,它先向某个根域名服务器查询。
3、根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器的IP地址。
4、本地域名服务器向顶级域名服务器进行迭代查询。
5、顶级域名服务器告诉本地域名服务器,下一次应查询的权限域名服务器的IP地址。
6、本地域名服务器向权限域名服务器进行迭代查询。
7、权限域名服务器告诉本地域名服务器所查询的域名的IP地址。
8、本地域名服务器最后把查询的结果告诉主机。
过程如图所示:
由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。











![[ctf.show pwn] 新手杯,七夕杯](https://img-blog.csdnimg.cn/img_convert/86a2d8e10ef011a24ca0bf675f169e5b.png)
