XGBoost: A Scalable Tree Boosting System
目录
XGBoost: A Scalable Tree Boosting System
1.摘要
2.方法
2.1 正则化学习目标
2.2 梯度提升树
2.3 收缩率和列采样
2.4分裂点查找算法
1.摘要
提出了一种新的稀疏性感知算法,用于稀疏数据和加权全图草图,用于近似树学习。同时提供了一种缓存访问模式、数据压缩和分片,以构建可扩展的树增强系统。
支持在各个场景中使用。提出一种树学习方法,支持稀疏数据,并行化和分布式训练支持支持更快的模型探索。XGBoost是Boosting算法的一种工程实现。支持核外计算、缓存感知、和稀疏感知的学习。其次,支持正则化学习。
2.方法
2.1 正则化学习目标
加法模型
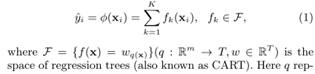
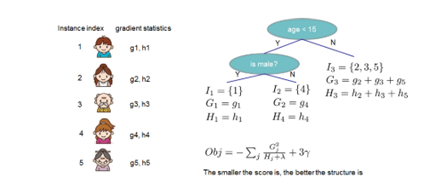
文章中给出了一个例子,对一个样本的预测值等于所有树预测值的加和
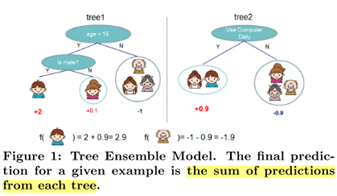
目标函数
损失和正则项,其中正则项包括,第k个叶子节点数量的正则项,以及叶子分数的正则项,这两项都是用来控制模型复杂度
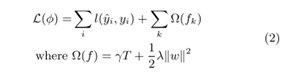
目标函数 = 损失 + 正则项
l是衡量预测值yi与真实值yi的损失函数,是一个可微的凸函数。Ω(fk)是用于控制模型复杂度的惩罚项。用于平滑学习的权重, 防止过拟合。使用正则项倾向于使用简单的预测函数。
2.2 梯度提升树
目标函数是第i个样本的真实值yi,预测值由前t-1棵树的输出yi(t-1)加上第t棵树的输出ft(xi),之间的误差,加上对第t棵树的正则项组成。
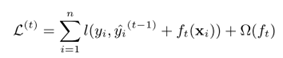
将目标函数对ft-1(x)进行泰勒展开,
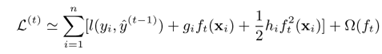
其中,![]() ,表示l对yi(t-1)的一阶偏导数,l对yi(t-1)的二阶偏导数为,
,表示l对yi(t-1)的一阶偏导数,l对yi(t-1)的二阶偏导数为,![]()
疑问:
(1)将目标函数展开成一阶偏导数和二阶偏导数的形式?
(2)为什么是对yi(t-1)的偏导数?
L(y,yit-1)为常数项,可以删除,于是目标函数变成以下形式
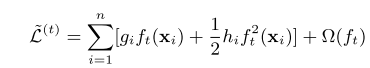
提前计算好每个样本的一阶导数和二阶导数,然后将每个叶子节点中每个样本的一阶导、二阶导分别相加,使用得分函数得到每个节点的分数Obj(w), 是让L=0,计算其极小值对应的分数.
树分裂的方式是,每个特征的每个值,找到分裂后增益最大(目标函数减小最多)的值作为分裂点。
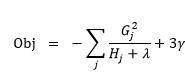
将样本形式的目标函数转换成叶子节点形式
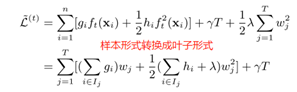
令L = 0,求L的极小值,得到w的最优解w*,并代入L求得L的最优解
![]()

公式(6)可以用于衡量树结构的好坏,分裂后目标函数L的减少量表示为
L分裂减少量 = L分裂前 – L分裂后
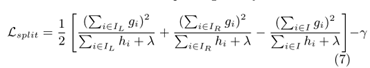
2.3 收缩率和列采样
如何理解收缩?
目标函数中12λj=1Twj2是指对每个叶子节点分数wj2(如果是回归,则是叶子内所有样本预测值的平均,分类则是投票)的正则项,收缩指的是使用λ这样一个正则化因子对叶子节点的分数进行正则化,使得原始的L变成带有约束项的优化。
文章解释这样做的目的是削弱当前树对最终预测的影响(因为是加法模型,每个样本的预测值为所有树预测的加和),留空间给后面的树进行学习,以提升模型
为什么不将一棵树学得很复杂? 防止过拟合!
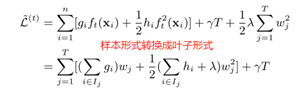
为什么进行列采样?
第二个技术是对特征(列)进行采样。文章提到,使用列(特征)采样比使用行(样本)采样更能防止过拟合。同时,列采样技术的使用也加快了后面描述的并行算法的计算速度。但是损失了最终的精度。
2.4分裂点查找算法
2.4.1 精确贪心算法
在分裂的时候需要枚举每个特征的每个值,找到分裂后目标函数减小的最多的特征和对应的值作为分裂点,时间复杂度高。因此对特征进行采样。
XGBoost把类别特征也当做了连续特征。为了能高效枚举分裂点,需要根据特征的值对数据进行排序,访问数据同时累加样本的梯度,来计算树的得分。

2.4.2 近似算法
精确贪心算法的不足在于,(1)时间复杂度高,(2)当数据量很大时,不能完全放入内存中去。
近似算法的做法是,根据分位数为每个特征提供一些候选的分裂点,并提前计算好这些分裂点的一阶和二阶导数。然后找到增益最大的特征及对应的值作为分裂点。

总结起来,在精确贪心算法上提出两个优化方向,第一个是列采样,通过减少特征数,来减少外层循环的枚举次数;第二个是近似算法,通过提供特征的候选分裂点(分位数点),减少内层循环的次数。这样做的代价是损失了模型精度。
For k = 1 to m do
GL = 0,GR = 0
For j in sorted(I, by xjk) do
GL = GL + gj, HL = HL + hj
GR = G – GL,HR = H – HL
Score = max(Score,Gain)
END
END









![[ctf.show pwn] 新手杯,七夕杯](https://img-blog.csdnimg.cn/img_convert/86a2d8e10ef011a24ca0bf675f169e5b.png)