什么是弱锁,强锁?
为了提高并发控制,PG通过将锁信息在本地缓存(**LOCALLOCK**)和快速处理常见锁(fastpath),减少了对共享内存的访问,提高性能。从而出现了弱锁和强锁的概念。
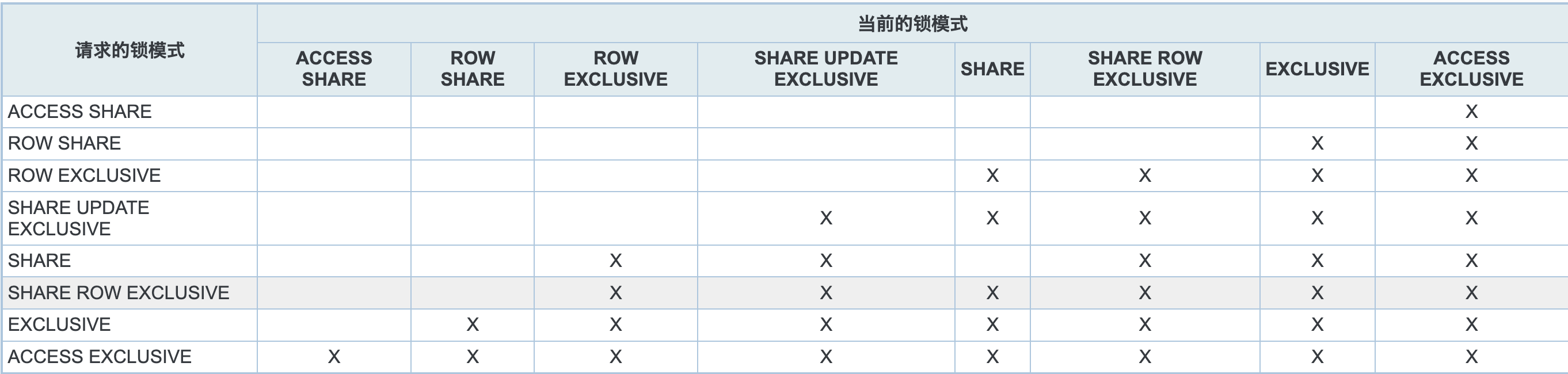
ShareUpdateExclusiveLock是强锁和弱锁的分界线。
以下是相关源码:
弱锁
#define EligibleForRelationFastPath(locktag, mode) \
((locktag)->locktag_lockmethodid == DEFAULT_LOCKMETHOD && \
(locktag)->locktag_type == LOCKTAG_RELATION && \
(locktag)->locktag_field1 == MyDatabaseId && \
MyDatabaseId != InvalidOid && \
(mode) < ShareUpdateExclusiveLock)
强锁
#define ConflictsWithRelationFastPath(locktag, mode) \
((locktag)->locktag_lockmethodid == DEFAULT_LOCKMETHOD && \
(locktag)->locktag_type == LOCKTAG_RELATION && \
(locktag)->locktag_field1 != InvalidOid && \
(mode) > ShareUpdateExclusiveLock)
理解相关结构体 LOCK, PROCLOCK, PROCLOCKTAG, LOCALLOCK, LOCALLOCKTAG
PostgreSQL 的锁系统设计相当复杂,涵盖了多种结构和层次,以适应数据库在并发控制和一致性保证方面的需求。理解 **LOCK**, **PROCLOCK**, **PROCLOCKTAG**, **LOCALLOCK**, **LOCALLOCKTAG**, 以及 FASTPATH 之间的关系?
LOCK
typedef struct LOCK
{
/* hash key */
LOCKTAG tag; /* unique identifier of lockable object */
/* data */
LOCKMASK grantMask; /* bitmask for lock types already granted */
LOCKMASK waitMask; /* bitmask for lock types awaited */
SHM_QUEUE procLocks; /* list of PROCLOCK objects assoc. with lock */
PROC_QUEUE waitProcs; /* list of PGPROC objects waiting on lock */
int requested[MAX_LOCKMODES]; /* counts of requested locks */
int nRequested; /* total of requested[] array */
int granted[MAX_LOCKMODES]; /* counts of granted locks */
int nGranted; /* total of granted[] array */
} LOCK;
- 描述: LOCK 结构表示一个特定的锁对象,它与数据库中的一个具体项(如表或行)相关联。
- 目的: 用于管理对数据库对象的锁定状态。每个 LOCK 对象可以被多个进程共享。
PROCLOCK
typedef struct PROCLOCK
{
/* tag */
PROCLOCKTAG tag; /* unique identifier of proclock object */
/* data */
PGPROC *groupLeader; /* proc's lock group leader, or proc itself */
LOCKMASK holdMask; /* bitmask for lock types currently held */
LOCKMASK releaseMask; /* bitmask for lock types to be released */
SHM_QUEUE lockLink; /* list link in LOCK's list of proclocks */
SHM_QUEUE procLink; /* list link in PGPROC's list of proclocks */
} PROCLOCK;
- 描述: PROCLOCK 是进程锁,表示特定进程持有的特定 LOCK 的状态。
- 目的: 管理每个进程对特定 LOCK 对象的访问。它允许系统跟踪哪个进程持有了哪个锁,以及这些锁的模式。
PROCLOCKTAG
typedef struct PROCLOCKTAG
{
/* NB: we assume this struct contains no padding! */
LOCK *myLock; /* link to per-lockable-object information */
PGPROC *myProc; /* link to PGPROC of owning backend */
} PROCLOCKTAG;
- 描述: PROCLOCKTAG 是 PROCLOCK 的标识符,通常包含指向 LOCK 对象和对应进程的指针。
- 目的: 用于唯一标识一个 PROCLOCK 实体,使得可以快速找到与特定 LOCK 和进程关联的 PROCLOCK。
LOCALLOCK
typedef struct LOCALLOCK
{
/* tag */
LOCALLOCKTAG tag; /* unique identifier of locallock entry */
/* data */
uint32 hashcode; /* copy of LOCKTAG's hash value */
LOCK *lock; /* associated LOCK object, if any */
PROCLOCK *proclock; /* associated PROCLOCK object, if any */
int64 nLocks; /* total number of times lock is held */
int numLockOwners; /* # of relevant ResourceOwners */
int maxLockOwners; /* allocated size of array */
LOCALLOCKOWNER *lockOwners; /* dynamically resizable array */
bool holdsStrongLockCount; /* bumped FastPathStrongRelationLocks */
bool lockCleared; /* we read all sinval msgs for lock */
} LOCALLOCK;
- 描述: LOCALLOCK 是本地锁,它在每个进程的本地内存中维护了 LOCK 和 PROCLOCK 的状态。
- 目的: 优化锁的管理和访问。通过在本地存储锁的信息,减少了对全局锁表的访问,提高了效率。
nLocks解释
- 作用: nLocks 字段记录了某个特定锁被当前进程持有的总次数。这是一个计数器,每当进程再次获得已经持有的锁时,此计数器就会递增。
- 用途: 这个计数器非常重要,因为 PostgreSQL 允许同一个进程对同一个对象的锁进行多次获取,这种情况通常称为锁的重入。nLocks 确保了锁释放操作可以正确进行:只有当 nLocks 降至 0 时,系统才认为锁真正地被释放了,这意味着进程不再持有该锁。
- 举例: 如果一个事务先后两次对同一行数据加了共享锁,那么 nLocks 会从 0 增加到 2。只有当事务释放了两次共享锁,使得 nLocks 再次变为 0 时,锁才会被实际释放。
lockCleared解释
- 作用: lockCleared 字段是一个布尔值,指示是否已经读取了与该锁相关的所有共享无效消息(shared invalidation messages)。共享无效消息用于 PostgreSQL 的缓存失效机制,当数据库对象的定义发生变化时(如表结构的修改),相关的缓存需要被清除以保证数据的一致性。
- 用途: 在锁被释放之后,相关的缓存条目可能需要被更新或清除。lockCleared 保证了在锁被释放后,任何必要的缓存失效操作都已经完成,从而避免了因为使用了过时的缓存数据而导致的数据不一致问题。
- 举例: 假设一个事务修改了表结构,这可能会触发针对这个表的共享无效消息。如果另一个事务持有对该表的锁,它需要在释放锁之前处理这些无效消息,确保自己之后的操作不会使用到过时的缓存。lockCleared 为 true 表明所有相关的无效消息都已处理完毕。
总之,nLocks 跟踪了锁的持有次数,确保锁可以正确地被重入和释放;而 lockCleared 确保了在锁被持有期间发生的任何可能影响到数据一致性的结构变化都被适当地处理了。这两个字段共同保证了 PostgreSQL 锁机制的正确性和数据的一致性。
LOCALLOCKTAG
- 描述: LOCALLOCKTAG 是 LOCALLOCK 的标识符,包含了锁定对象的信息和锁模式。
- 目的: 用于唯一标识一个 LOCALLOCK 实体,使得可以快速找到对应的本地锁信息。
Fastpath
- 描述: Fastpath 是一种优化机制,用于快速授予和释放对某些常用资源的锁,例如行级锁。
- 目的: 提高常见锁操作的性能。对于简单的锁请求,fastpath 避免了访问复杂的全局锁结构,直接在本地进程中处理锁的授予和释放。
结构体之间的关系
- LOCK 和 PROCLOCK 结构存在于共享内存中,由所有数据库后端进程共享。LOCK 表示特定资源的锁,而 PROCLOCK 表示特定进程持有的特定 LOCK 的状态。
- PROCLOCKTAG 和 LOCALLOCKTAG 作为标识符,帮助系统快速识别和定位相应的 PROCLOCK 和 LOCALLOCK。
- LOCALLOCK 存储在每个进程的本地内存中,保存了该进程对共享内存中 LOCK 和 PROCLOCK 的本地视图。这样可以减少对共享内存的访问,提高效率。
- Fastpath 机制用于处理那些可以简化处理的锁请求,比如对于频繁访问且冲突较少的行级锁,直接在本地进行管理,从而进一步提高性能。
设计原因
- 并发控制:PostgreSQL 需要能够在多个进程间有效地管理锁,以保持数据一致性和防止死锁。
- 性能优化:通过将锁信息在本地缓存(LOCALLOCK)和快速处理常见锁(fastpath),减少了对共享内存的访问,提高了性能。
- 灵活性和可扩展性:这种分层和模块化的设计使得 PostgreSQL 可以适应不同类型的锁请求和不同的锁策略,同时保持良好的性能和可靠性。
总的来说,PostgreSQL 的这种锁设计旨在实现高效的并发控制,同时优化常见操作的性能,确保数据库在高并发环境下的稳定和高效。
功能说明
这个函数的行为取决于其参数。例如,如果用 HASH_ENTER 操作,它会查找是否已有匹配的键;如果没有,它会插入一个新元素。如果用 HASH_FIND,它只查找而不修改表。
这个函数是 PostgreSQL 中众多基于哈希表的内部操作的基础,允许高效地处理键值对,特别是在数据库的内部锁管理和其他核心功能中。
LockAcquireExtended
(1)GrantLockLocal:申请本地锁,如果未申请到,进行到下一步。申请到则直接返回
if (locallock->nLocks > 0)
{
GrantLockLocal(locallock, owner);
if (locallock->lockCleared)
return LOCKACQUIRE_ALREADY_CLEAR;
else
return LOCKACQUIRE_ALREADY_HELD;
}
(2)EligibleForRelationFastPath:检查申请的是否弱锁且槽位小于16个,如果申请不到锁,进行到下一步。申请到则直接返回
(3)ConflictsWithRelationFastPath:申请锁可能是强锁或者槽位大于16,需要转移fastpath到主表锁。
3.1 FastPathTransferRelationLocks
FastPathTransferRelationLocks(LockMethod lockMethodTable, const LOCKTAG *locktag,
uint32 hashcode)
3.1.1 SetupLockInTable 等于relid且是弱锁,则创建进程锁(如果未找到),并挪到主表锁中,即转移。
(4)SetupLockInTable:创建本次申请的锁的进程锁(如果不存在)。使用locktag和MyProc创建。
static PROCLOCK *
SetupLockInTable(LockMethod lockMethodTable, PGPROC *proc,
const LOCKTAG *locktag, uint32 hashcode, LOCKMODE lockmode)
(5)检查是当前请求锁否有其他waiters冲突(检查与waiter冲突)。
if (lockMethodTable->conflictTab[lockmode] & lock->waitMask)
(6)检查当前申请的锁模式是否与已经被其他事务持有的锁模式冲突(检查与其他已持有锁冲突)。
found_conflict = LockCheckConflicts(lockMethodTable, lockmode,
lock, proclock);
(7)上述5,6检查没有冲突,直接grant锁
GrantLock(lock, proclock, lockmode);
GrantLockLocal(locallock, owner);
(8)上述5,6检查有冲突,如果申请锁是dontWait,直接返回LOCKACQUIRE_NOT_AVAIL,如果申请不是dontWait,则进入等待WaitOnLock(locallock, owner);
申请锁流程说明
当一个进程(如进程A)申请的锁与fast path发生冲突时,系统需要确定哪些fast path与该申请的锁存在对应关系。以下是查找这种对应关系的一般过程:
- LOCKTAG分析:
- 每个锁(无论是快速路径锁还是传统锁)都由一个 LOCKTAG 结构标识,该结构包含锁定对象的类型(如表)、数据库ID、关系ID等。
- 当进程A请求锁时,它会指定一个 LOCKTAG,这对于确定与哪些快速路径锁冲突至关重要。
- 检查快速路径锁:
- PostgreSQL 维护了一个快速路径锁数组,每个后端进程都有自己的快速路径锁槽(最多16个,宏定义:FP_LOCK_SLOTS_PER_BACKEND硬代码)。
- 如果申请锁和fastpath有冲突,系统遍历所有活动的后端进程,检查它们的快速路径锁槽。
- 对于每个后端的快速路径锁槽,系统会检查锁标签(LOCKTAG)和锁模式是否与进程A请求的锁兼容或冲突。
- 匹配和冲突检测:
- 如果某个快速路径锁的 LOCKTAG 与进程A请求的锁的 LOCKTAG 相匹配,并且锁模式之间存在冲突(例如,一个是共享锁,另一个是排他锁),那么就确定了一对冲突的锁。
- 这个匹配和冲突检测过程通常涉及比较数据库ID、关系ID等字段。
- 处理冲突:
- 一旦确定了冲突的锁,系统可能需要采取行动,如将快速路径锁迁移到传统的共享锁表中。
- 这可以通过调用如 FastPathTransferRelationLocks 这样的函数来实现,该函数负责将快速路径锁转移到共享哈希表中。
- 重新尝试获取锁:
- 迁移完冲突的快速路径锁后,进程A可以重新尝试获取其请求的锁。这次,系统将通过标准的锁获取流程(如通过 LockAcquireExtended)处理锁请求,此时所有相关的锁都已经在共享哈希表中。
总的来说,查找冲突的快速路径锁涉及到比较请求的锁标签与系统中所有快速路径锁槽的锁标签和模式,以确定是否存在兼容性或冲突。这是一个涉及多个后端进程和多种锁类型的复杂过程,是 PostgreSQL 锁管理系统用于维护数据一致性和事务隔离性的关键部分。
hash_search_with_hash_value解释
hash_search_with_hash_value 是 PostgreSQL 中的一个内部函数,用于在哈希表中查找、插入或删除元素。这个函数特别之处在于它允许调用者直接提供哈希值,而不是仅仅依赖于键本身来计算哈希值。(下面源码说明中很多用到)下面是对这个函数及其参数的详细解释:
函数功能
hash_search_with_hash_value 在哈希表中执行查找、插入或删除操作,具体取决于传入的参数。
参数解析
- 第一个参数 - 哈希表:
- 这是要操作的哈希表,通常是一个指向 HTAB 结构的指针。在 PostgreSQL 中,许多内部数据结构(如锁表)都使用这种类型的哈希表。
- 第二个参数 - 键:
- 这是要查找、插入或删除的元素的键。它是一个 **void *** 类型,意味着可以是任何类型的数据,但必须与哈希表中存储的元素类型匹配。
- 第三个参数 - 哈希值:
- 这是元素键的哈希值。通常,哈希表会根据键自己计算这个值,但这个函数允许直接传入。这对于优化很有用,特别是在键的哈希值已经提前计算好的情况下。
- 第四个参数 - 操作类型:
- 这个参数指定函数应该执行的操作类型。它通常是以下几个选项之一:
- HASH_FIND:仅查找元素。
- HASH_ENTER:插入一个新元素,如果键已存在,则返回现有元素。
- HASH_ENTER_NULL:尝试插入一个新元素,但如果内存不足,则返回 NULL。
- HASH_REMOVE:删除与键匹配的元素。
- 这些选项决定了函数如何响应键是否已经存在于表中,以及是否有足够的内存来插入新元素。
- 这个参数指定函数应该执行的操作类型。它通常是以下几个选项之一:
- 第五个参数 - 找到标志:
- 这是一个指向布尔值的指针,函数会设置这个值以指示是否找到了一个匹配的元素(对于查找操作)或是否创建了一个新元素(对于插入操作)。
源码说明
(1)申请锁(LockAcquireExtended)
LockAcquireResult
LockAcquireExtended(const LOCKTAG *locktag,
LOCKMODE lockmode,
bool sessionLock,
bool dontWait,
bool reportMemoryError,
LOCALLOCK **locallockp)
{
LOCKMETHODID lockmethodid = locktag->locktag_lockmethodid;
LockMethod lockMethodTable;
LOCALLOCKTAG localtag;
LOCALLOCK *locallock;//本地锁
LOCK *lock;//主表锁
PROCLOCK *proclock;//
bool found;
ResourceOwner owner;
uint32 hashcode;//获取本地锁hash值
LWLock *partitionLock;
bool found_conflict;
bool log_lock = false;
if (lockmethodid <= 0 || lockmethodid >= lengthof(LockMethods))
elog(ERROR, "unrecognized lock method: %d", lockmethodid);
lockMethodTable = LockMethods[lockmethodid];
if (lockmode <= 0 || lockmode > lockMethodTable->numLockModes)
elog(ERROR, "unrecognized lock mode: %d", lockmode);
if (RecoveryInProgress() && !InRecovery &&
(locktag->locktag_type == LOCKTAG_OBJECT ||
locktag->locktag_type == LOCKTAG_RELATION) &&
lockmode > RowExclusiveLock)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("cannot acquire lock mode %s on database objects while recovery is in progress",
lockMethodTable->lockModeNames[lockmode]),
errhint("Only RowExclusiveLock or less can be acquired on database objects during recovery.")));
#ifdef LOCK_DEBUG
if (LOCK_DEBUG_ENABLED(locktag))
elog(LOG, "LockAcquire: lock [%u,%u] %s",
locktag->locktag_field1, locktag->locktag_field2,
lockMethodTable->lockModeNames[lockmode]);
#endif
/* Identify owner for lock */
if (sessionLock)
owner = NULL;
else
owner = CurrentResourceOwner;
/*
* Find or create a LOCALLOCK entry for this lock and lockmode
*/
MemSet(&localtag, 0, sizeof(localtag)); /* must clear padding */
localtag.lock = *locktag;
localtag.mode = lockmode;
locallock = (LOCALLOCK *) hash_search(LockMethodLocalHash,
(void *) &localtag,
HASH_ENTER, &found);
/*
* if it's a new locallock object, initialize it
*/
if (!found)
{
locallock->lock = NULL;
locallock->proclock = NULL;
locallock->hashcode = LockTagHashCode(&(localtag.lock));
locallock->nLocks = 0;
locallock->holdsStrongLockCount = false;
locallock->lockCleared = false;
locallock->numLockOwners = 0;
locallock->maxLockOwners = 8;
locallock->lockOwners = NULL; /* in case next line fails */
locallock->lockOwners = (LOCALLOCKOWNER *)
MemoryContextAlloc(TopMemoryContext,
locallock->maxLockOwners * sizeof(LOCALLOCKOWNER));
}
else
{
/* Make sure there will be room to remember the lock */
if (locallock->numLockOwners >= locallock->maxLockOwners)
{
int newsize = locallock->maxLockOwners * 2;
locallock->lockOwners = (LOCALLOCKOWNER *)
repalloc(locallock->lockOwners,
newsize * sizeof(LOCALLOCKOWNER));
locallock->maxLockOwners = newsize;
}
}
hashcode = locallock->hashcode;
if (locallockp)
*locallockp = locallock;
/*
* If we already hold the lock, we can just increase the count locally.
*
* If lockCleared is already set, caller need not worry about absorbing
* sinval messages related to the lock's object.
*/
if (locallock->nLocks > 0)
{
GrantLockLocal(locallock, owner);
if (locallock->lockCleared)
return LOCKACQUIRE_ALREADY_CLEAR;
else
return LOCKACQUIRE_ALREADY_HELD;
}
/*
* We don't acquire any other heavyweight lock while holding the relation
* extension lock. We do allow to acquire the same relation extension
* lock more than once but that case won't reach here.
*/
Assert(!IsRelationExtensionLockHeld);
/*
* Prepare to emit a WAL record if acquisition of this lock needs to be
* replayed in a standby server.
*
* Here we prepare to log; after lock is acquired we'll issue log record.
* This arrangement simplifies error recovery in case the preparation step
* fails.
*
* Only AccessExclusiveLocks can conflict with lock types that read-only
* transactions can acquire in a standby server. Make sure this definition
* matches the one in GetRunningTransactionLocks().
*/
if (lockmode >= AccessExclusiveLock &&
locktag->locktag_type == LOCKTAG_RELATION &&
!RecoveryInProgress() &&
XLogStandbyInfoActive())
{
LogAccessExclusiveLockPrepare();
log_lock = true;
}
/*
* Attempt to take lock via fast path, if eligible. But if we remember
* having filled up the fast path array, we don't attempt to make any
* further use of it until we release some locks. It's possible that some
* other backend has transferred some of those locks to the shared hash
* table, leaving space free, but it's not worth acquiring the LWLock just
* to check. It's also possible that we're acquiring a second or third
* lock type on a relation we have already locked using the fast-path, but
* for now we don't worry about that case either.
* 如果可以取得弱锁,并且FP_LOCK_SLOTS_PER_BACKEND槽位小于16个,则直接获取弱锁fastpath
*/
if (EligibleForRelationFastPath(locktag, lockmode) &&
FastPathLocalUseCount < FP_LOCK_SLOTS_PER_BACKEND)
{
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode);
bool acquired;
/*
* LWLockAcquire acts as a memory sequencing point, so it's safe to
* assume that any strong locker whose increment to
* FastPathStrongRelationLocks->counts becomes visible after we test
* it has yet to begin to transfer fast-path locks.
*/
LWLockAcquire(&MyProc->fpInfoLock, LW_EXCLUSIVE);
if (FastPathStrongRelationLocks->count[fasthashcode] != 0)
acquired = false;
else
acquired = FastPathGrantRelationLock(locktag->locktag_field2,
lockmode);
LWLockRelease(&MyProc->fpInfoLock);
if (acquired)
{
/*
* The locallock might contain stale pointers to some old shared
* objects; we MUST reset these to null before considering the
* lock to be acquired via fast-path.
*/
locallock->lock = NULL;
locallock->proclock = NULL;
GrantLockLocal(locallock, owner);
return LOCKACQUIRE_OK;
}
}
/*
* If this lock could potentially have been taken via the fast-path by
* some other backend, we must (temporarily) disable further use of the
* fast-path for this lock tag, and migrate any locks already taken via
* this method to the main lock table.
* 如果这个锁可能已经通过快速路径被其他后端获取 且 当前申请的锁和已经有的fastpath冲突,
* 我们必须(临时地)禁用这个锁标签的快速路径的进一步使用,并且将通过这种方法已经获取的任何锁迁移到主锁表中。
*/
if (ConflictsWithRelationFastPath(locktag, lockmode))
{
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode);
BeginStrongLockAcquire(locallock, fasthashcode);
/*FastPathTransferRelationLocks作用是将符合特定条件的锁从每个后端(backend)的快速路径数组转移到共享的哈希表中*/
if (!FastPathTransferRelationLocks(lockMethodTable, locktag,
hashcode))
{
AbortStrongLockAcquire();
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
}
/*
* We didn't find the lock in our LOCALLOCK table, and we didn't manage to
* take it via the fast-path, either, so we've got to mess with the shared
* lock table.
*/
partitionLock = LockHashPartitionLock(hashcode);
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/*
* Find or create lock and proclock entries with this tag
*
* Note: if the locallock object already existed, it might have a pointer
* to the lock already ... but we should not assume that that pointer is
* valid, since a lock object with zero hold and request counts can go
* away anytime. So we have to use SetupLockInTable() to recompute the
* lock and proclock pointers, even if they're already set.
*/
proclock = SetupLockInTable(lockMethodTable, MyProc, locktag,
hashcode, lockmode);
if (!proclock)
{
AbortStrongLockAcquire();
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
locallock->proclock = proclock;
lock = proclock->tag.myLock;
locallock->lock = lock;
/*
* If lock requested conflicts with locks requested by waiters, must join
* wait queue. Otherwise, check for conflict with already-held locks.
* (That's last because most complex check.)
* 重要1:检查是当前请求锁否有其他waiters冲突(检查与waiter冲突)。
* 场景: 如果其他事务正在等待一个与当前请求冲突的锁模式,当前事务也需要等待,以避免潜在的死锁或数据不一致
*/
if (lockMethodTable->conflictTab[lockmode] & lock->waitMask)
found_conflict = true;
else
/*
重要2:检查当前申请的锁模式是否与已经被其他事务持有的锁模式冲突(检查与其他已持有锁冲突)。
场景: 即使没有事务正在等待获取锁(第一次检查通过),当前事务的请求仍可能与其他事务已经持有的锁模式冲突。
*/
found_conflict = LockCheckConflicts(lockMethodTable, lockmode,
lock, proclock);
if (!found_conflict)
{
当没有发现与当前请求的锁模式冲突的情况时(!found_conflict),执行以下操作:
GrantLock:授予锁。这意味着更新 LOCK 和 PROCLOCK 结构,标记当前进程现在持有请求的锁。
GrantLockLocal:在本地锁结构(LOCALLOCK)中记录锁的授予。这是为了在进程的本地上下文中跟踪锁的状态,
减少对共享锁结构的访问,优化性能。
/* No conflict with held or previously requested locks */
GrantLock(lock, proclock, lockmode);
GrantLockLocal(locallock, owner);
}
else
{
/*
* We can't acquire the lock immediately. If caller specified no
* blocking, remove useless table entries and return
* LOCKACQUIRE_NOT_AVAIL without waiting.
*/
/*存在冲突情况
当检测到当前请求的锁模式与其他事务的请求或持有的锁模式存在冲突时,需要进行进一步的处理:
如果调用者指定了不等待(dontWait),则执行以下操作:
AbortStrongLockAcquire:取消当前的锁获取尝试。这可能涉及清理已经进行的一些操作。
如果当前 PROCLOCK 没有持有任何锁(holdMask == 0),则需要从锁管理结构中移除该 PROCLOCK,释放资源。
SHMQueueDelete 和 hash_search_with_hash_value 被用来从共享内存结构中删除不再需要的 PROCLOCK 条目。
更新 LOCK 结构的计数器,反映锁请求的取消。
如果本地锁 (LOCALLOCK) 也不再被任何锁请求引用,那么也将其移除。*/
if (dontWait)
{
AbortStrongLockAcquire();
if (proclock->holdMask == 0)
{
uint32 proclock_hashcode;
proclock_hashcode = ProcLockHashCode(&proclock->tag, hashcode);
SHMQueueDelete(&proclock->lockLink);
SHMQueueDelete(&proclock->procLink);
if (!hash_search_with_hash_value(LockMethodProcLockHash,
(void *) &(proclock->tag),
proclock_hashcode,
HASH_REMOVE,
NULL))
elog(PANIC, "proclock table corrupted");
}
else
PROCLOCK_PRINT("LockAcquire: NOWAIT", proclock);
lock->nRequested--;
lock->requested[lockmode]--;
LOCK_PRINT("LockAcquire: conditional lock failed", lock, lockmode);
Assert((lock->nRequested > 0) && (lock->requested[lockmode] >= 0));
Assert(lock->nGranted <= lock->nRequested);
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
return LOCKACQUIRE_NOT_AVAIL;
}
/*
* Set bitmask of locks this process already holds on this object.
*/
MyProc->heldLocks = proclock->holdMask;
/*
* Sleep till someone wakes me up.
*/
TRACE_POSTGRESQL_LOCK_WAIT_START(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
/*
如果允许等待锁释放,执行以下操作:
记录当前进程已经持有的锁模式。
进入等待状态,直到锁变为可用。WaitOnLock 函数挂起当前进程,直到锁被释放并唤醒该进程。
*/
WaitOnLock(locallock, owner);
TRACE_POSTGRESQL_LOCK_WAIT_DONE(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
/*
* NOTE: do not do any material change of state between here and
* return. All required changes in locktable state must have been
* done when the lock was granted to us --- see notes in WaitOnLock.
*/
/*
* Check the proclock entry status, in case something in the ipc
* communication doesn't work correctly.
*/
if (!(proclock->holdMask & LOCKBIT_ON(lockmode)))
{
AbortStrongLockAcquire();
PROCLOCK_PRINT("LockAcquire: INCONSISTENT", proclock);
LOCK_PRINT("LockAcquire: INCONSISTENT", lock, lockmode);
/* Should we retry ? */
LWLockRelease(partitionLock);
elog(ERROR, "LockAcquire failed");
}
PROCLOCK_PRINT("LockAcquire: granted", proclock);
LOCK_PRINT("LockAcquire: granted", lock, lockmode);
}
/*
* Lock state is fully up-to-date now; if we error out after this, no
* special error cleanup is required.
*/
FinishStrongLockAcquire();
LWLockRelease(partitionLock);
/*
* Emit a WAL record if acquisition of this lock needs to be replayed in a
* standby server.
*/
if (log_lock)
{
/*
* Decode the locktag back to the original values, to avoid sending
* lots of empty bytes with every message. See lock.h to check how a
* locktag is defined for LOCKTAG_RELATION
*/
LogAccessExclusiveLock(locktag->locktag_field1,
locktag->locktag_field2);
}
return LOCKACQUIRE_OK;
}
(2)转移fastpath到主表锁(FastPathTransferRelationLocks)
将符合特定条件的锁从每个后端(backend)的快速路径数组转移到共享的哈希表中。这里需要循环所有进程。
/*
作用:
函数的目的是将锁从后端进程的快速路径锁数组迁移到共享的哈希表中。
这主要发生在当一个锁可能与快速路径锁发生冲突,或者需要通过更传统的锁机制处理时
*/
static bool
FastPathTransferRelationLocks(LockMethod lockMethodTable, const LOCKTAG *locktag,
uint32 hashcode)
{
LWLock *partitionLock = LockHashPartitionLock(hashcode);
Oid relid = locktag->locktag_field2;
uint32 i;
/*
* Every PGPROC that can potentially hold a fast-path lock is present in
* ProcGlobal->allProcs. Prepared transactions are not, but any
* outstanding fast-path locks held by prepared transactions are
* transferred to the main lock table.
*/
/*
* 所有可能持有快速路径锁的 PGPROC 都存在于 ProcGlobal->allProcs 中。
* prepared事务不包括在内,但prepared事务持有的所有未完成的快速路径锁
* 都被转移到主锁表中。
*/
for (i = 0; i < ProcGlobal->allProcCount; i++)
{
PGPROC *proc = &ProcGlobal->allProcs[i];
uint32 f;
LWLockAcquire(&proc->fpInfoLock, LW_EXCLUSIVE);
/*
* If the target backend isn't referencing the same database as the
* lock, then we needn't examine the individual relation IDs at all;
* none of them can be relevant.
*
* proc->databaseId is set at backend startup time and never changes
* thereafter, so it might be safe to perform this test before
* acquiring &proc->fpInfoLock. In particular, it's certainly safe to
* assume that if the target backend holds any fast-path locks, it
* must have performed a memory-fencing operation (in particular, an
* LWLock acquisition) since setting proc->databaseId. However, it's
* less clear that our backend is certain to have performed a memory
* fencing operation since the other backend set proc->databaseId. So
* for now, we test it after acquiring the LWLock just to be safe.
*/
/*
* 如果目标后端没有引用与锁相同的数据库,那么我们就不需要检查
* 各个关系 ID;它们都不相关。
*/
if (proc->databaseId != locktag->locktag_field1)
{
LWLockRelease(&proc->fpInfoLock);
continue;
}
for (f = 0; f < FP_LOCK_SLOTS_PER_BACKEND; f++)
{
uint32 lockmode;
/* Look for an allocated slot matching the given relid. */
/* 如果relid不相等或者当前锁模式没有弱锁,不用转移 */
if (relid != proc->fpRelId[f] || FAST_PATH_GET_BITS(proc, f) == 0)
continue;
/* Find or create lock object. /在主锁表中找到或创建锁对象。 */
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/*
FAST_PATH_LOCKNUMBER_OFFSET值从1开始,实际上1代表Accesssharelock,
就是所谓的1号锁。弱锁从1开始,到FAST_PATH_BITS_PER_SLOT结束,总共3个
*/
for (lockmode = FAST_PATH_LOCKNUMBER_OFFSET;
lockmode < FAST_PATH_LOCKNUMBER_OFFSET + FAST_PATH_BITS_PER_SLOT;
++lockmode)
{
PROCLOCK *proclock;
if (!FAST_PATH_CHECK_LOCKMODE(proc, f, lockmode))
continue;
/*创建或找到主锁表中的锁对象 (SetupLockInTable):
这个函数负责在主锁表中为给定的locktag和模式找到或创建一个 PROCLOCK 结构。
这是锁从快速路径转移到主锁表的关键步骤*/
proclock = SetupLockInTable(lockMethodTable, proc, locktag,
hashcode, lockmode);
if (!proclock)
{
LWLockRelease(partitionLock);
LWLockRelease(&proc->fpInfoLock);
return false;
}
/*一旦锁对象在主锁表中创建或找到,GrantLock 函数会被调用来在 PROCLOCK 上设置相应的锁状态*/
GrantLock(proclock->tag.myLock, proclock, lockmode);
FAST_PATH_CLEAR_LOCKMODE(proc, f, lockmode);
}
LWLockRelease(partitionLock);
/* No need to examine remaining slots. */
break;
}
LWLockRelease(&proc->fpInfoLock);
}
return true;
}
(3)创建PROCLOCK结构(SetupLockInTable其实就是转移fastpath的主要步骤)
/*目的:
为新的锁请求找到或创建必要的 LOCK 和 PROCLOCK 对象。
如果由于共享内存不足而失败,则返回 NULL。
在函数开始时和结束时,必须持有适当的分区锁。
*/
static PROCLOCK *
SetupLockInTable(LockMethod lockMethodTable, PGPROC *proc,
const LOCKTAG *locktag, uint32 hashcode, LOCKMODE lockmode)
{
LOCK *lock;//主表锁
PROCLOCK *proclock;//进程锁表
PROCLOCKTAG proclocktag;//主表锁和进程的关系,该值为proclock的的hash key
uint32 proclock_hashcode;
bool found;
/*
* Find or create a lock with this tag.
*/
/*
* 根据这个标签找到或创建一个锁。
*/
lock = (LOCK *) hash_search_with_hash_value(LockMethodLockHash,
(const void *) locktag,
hashcode,
HASH_ENTER_NULL,
&found);
if (!lock)
return NULL;
/*
* if it's a new lock object, initialize it
* 如果没找到,则初始化
*/
if (!found)
{
lock->grantMask = 0;
lock->waitMask = 0;
SHMQueueInit(&(lock->procLocks));
ProcQueueInit(&(lock->waitProcs));
lock->nRequested = 0;
lock->nGranted = 0;
MemSet(lock->requested, 0, sizeof(int) * MAX_LOCKMODES);
MemSet(lock->granted, 0, sizeof(int) * MAX_LOCKMODES);
LOCK_PRINT("LockAcquire: new", lock, lockmode);
}
else
{
// 如果找到了 PROCLOCK 对象,进行断言检查
LOCK_PRINT("LockAcquire: found", lock, lockmode);
Assert((lock->nRequested >= 0) && (lock->requested[lockmode] >= 0));
Assert((lock->nGranted >= 0) && (lock->granted[lockmode] >= 0));
Assert(lock->nGranted <= lock->nRequested);
}
/*
* Create the hash key for the proclock table.
* 为proclock创建Hash key
*/
proclocktag.myLock = lock;
proclocktag.myProc = proc;
proclock_hashcode = ProcLockHashCode(&proclocktag, hashcode);
/*
* Find or create a proclock entry with this tag
* 根据proclocktag查找或者创建proclock
*/
proclock = (PROCLOCK *) hash_search_with_hash_value(LockMethodProcLockHash,
(void *) &proclocktag,
proclock_hashcode,
HASH_ENTER_NULL,
&found);
if (!proclock)
{
/* Oops, not enough shmem for the proclock */
if (lock->nRequested == 0)
{
/*
* There are no other requestors of this lock, so garbage-collect
* the lock object. We *must* do this to avoid a permanent leak
* of shared memory, because there won't be anything to cause
* anyone to release the lock object later.
*/
Assert(SHMQueueEmpty(&(lock->procLocks)));
if (!hash_search_with_hash_value(LockMethodLockHash,
(void *) &(lock->tag),
hashcode,
HASH_REMOVE,
NULL))
elog(PANIC, "lock table corrupted");
}
return NULL;
}
/*
* If new, initialize the new entry
* 如果是新的,则初始化新的entry
*/
if (!found)
{
uint32 partition = LockHashPartition(hashcode);
/*
* It might seem unsafe to access proclock->groupLeader without a
* lock, but it's not really. Either we are initializing a proclock
* on our own behalf, in which case our group leader isn't changing
* because the group leader for a process can only ever be changed by
* the process itself; or else we are transferring a fast-path lock to
* the main lock table, in which case that process can't change it's
* lock group leader without first releasing all of its locks (and in
* particular the one we are currently transferring).
*/
proclock->groupLeader = proc->lockGroupLeader != NULL ?
proc->lockGroupLeader : proc;
proclock->holdMask = 0;
proclock->releaseMask = 0;
/* Add proclock to appropriate lists */
SHMQueueInsertBefore(&lock->procLocks, &proclock->lockLink);
SHMQueueInsertBefore(&(proc->myProcLocks[partition]),
&proclock->procLink);
PROCLOCK_PRINT("LockAcquire: new", proclock);
}
else
{
PROCLOCK_PRINT("LockAcquire: found", proclock);
Assert((proclock->holdMask & ~lock->grantMask) == 0);
#ifdef CHECK_DEADLOCK_RISK
/*
* Issue warning if we already hold a lower-level lock on this object
* and do not hold a lock of the requested level or higher. This
* indicates a deadlock-prone coding practice (eg, we'd have a
* deadlock if another backend were following the same code path at
* about the same time).
*
* This is not enabled by default, because it may generate log entries
* about user-level coding practices that are in fact safe in context.
* It can be enabled to help find system-level problems.
*
* XXX Doing numeric comparison on the lockmodes is a hack; it'd be
* better to use a table. For now, though, this works.
*/
{
int i;
for (i = lockMethodTable->numLockModes; i > 0; i--)
{
if (proclock->holdMask & LOCKBIT_ON(i))
{
if (i >= (int) lockmode)
break; /* safe: we have a lock >= req level */
elog(LOG, "deadlock risk: raising lock level"
" from %s to %s on object %u/%u/%u",
lockMethodTable->lockModeNames[i],
lockMethodTable->lockModeNames[lockmode],
lock->tag.locktag_field1, lock->tag.locktag_field2,
lock->tag.locktag_field3);
break;
}
}
}
#endif /* CHECK_DEADLOCK_RISK */
}
/*
* lock->nRequested and lock->requested[] count the total number of
* requests, whether granted or waiting, so increment those immediately.
* The other counts don't increment till we get the lock.
*/
lock->nRequested++;
lock->requested[lockmode]++;
Assert((lock->nRequested > 0) && (lock->requested[lockmode] > 0));
/*
* We shouldn't already hold the desired lock; else locallock table is
* broken.
* 确保我们不应该已经持有所需的锁;否则本地锁表有问题。
*/
if (proclock->holdMask & LOCKBIT_ON(lockmode))
elog(ERROR, "lock %s on object %u/%u/%u is already held",
lockMethodTable->lockModeNames[lockmode],
lock->tag.locktag_field1, lock->tag.locktag_field2,
lock->tag.locktag_field3);
return proclock;
}
在 PostgreSQL 中,proclock->holdMask 和 LOCKBIT_ON(lockmode) 用于处理锁的状态,具体来说:
- proclock->holdMask:
- proclock->holdMask 是当前进程锁(PROCLOCK 结构)所持有的锁模式的一个位掩码。
- 每个位代表一个不同的锁模式。如果某个位被设置(即为 1),表示该进程当前持有对应的锁模式。
- 例如,如果 holdMask 为 0b010(二进制表示),并且每个位代表一个特定的锁模式(假设第二位代表共享锁),则这表示当前进程持有一个共享锁。
- LOCKBIT_ON(lockmode):
- LOCKBIT_ON(lockmode) 是一个宏,它根据给定的锁模式(lockmode)生成一个位掩码,其中只有对应该锁模式的位被设置为 1,其他位为 0。
- 这个掩码用于表示将要请求或检查的锁模式。例如,如果 lockmode 表示排他锁,并且排他锁对应的位是第三位,那么 LOCKBIT_ON(lockmode) 将生成 0b100。
关系和用途
- proclock->holdMask 表示当前持有的锁:它显示了该进程已经获取的锁的模式。如果进程试图获取新的锁,首先需要检查它是否已经持有该模式的锁。
- LOCKBIT_ON(lockmode) 表示将要检查或请求的锁模式:这是进程希望获取或释放的锁的模式。
使用场景
- 检查是否已持有特定模式的锁:
- 使用 proclock->holdMask & LOCKBIT_ON(lockmode) 可以检查一个进程是否已经持有特定模式的锁。
- 如果结果非零,表示 proclock->holdMask 中对应 LOCKBIT_ON(lockmode) 设置的位已被设置,即该进程已持有该模式的锁。
- 如果结果为零,表示该进程尚未持有该模式的锁。
这种机制是 PostgreSQL 锁系统管理锁状态的关键部分,确保了锁请求的正确性和有效性。