目录
- 安装 PyTorch
- 张量
- 创建张量
- 操作张量
- 索引、切片、联合操作
- CUDA张量
本系列博文我们将使用 PyTorch 来实现深度学习模型等。PyTorch 是一个开源的、社区驱动的深度学习框架。拥有强大的工具和库生态系统,包含 TorchVision(用于图像处理)、TorchText(用于文本处理)、TorchAudio(用于音频处理)等。
安装 PyTorch
网址:https://pytorch.org/
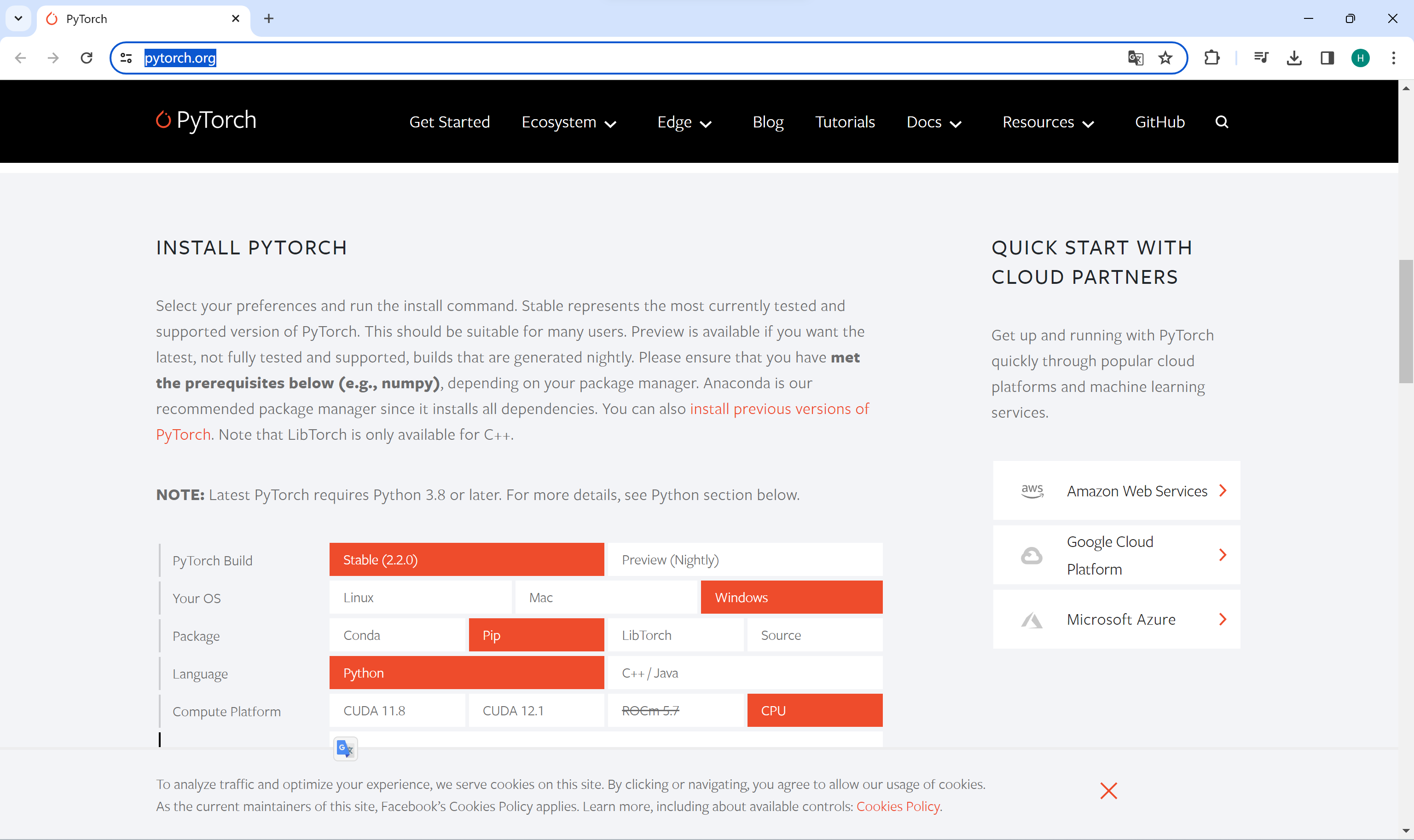
根据系统以及是否有 GPU 进行安装 PyTorch 库;
如我在 Windows 电脑上安装 CPU 版本的 PyTorch, Anaconda Prompt 中输入命令为:
pip3 install torch torchvision torchaudio
张量
PyTorch 库的核心是张量,是一种多维的数据结构,类似于 NumPy 中的 ndarray。但是张量在自动微分和深度学习方面提供了更多的操作和功能。张量在 PyTorch 中的地位类似于矩阵在 MATLAB 中的地位,是进行计算的基础。
零阶张量: 零阶张量只是一个数字或标量;
一阶张量: 一阶张量是数组或者向量;
二阶张量: 二阶张量是向量数组或矩阵;
N阶张量: 张量可以概括为标量的 N 维数组。
创建张量
torch.tensor():从数据创建张量。
torch.zeros():创建一个指定大小和数据类型的全零张量。
torch.ones():创建一个指定大小和数据类型的全一张量。
torch.rand():创建一个指定大小和数据类型的随机张量。
torch.randn():创建一个指定大小和数据类型的标准正态分布张量。
torch.full():创建一个指定大小和数据类型的填充张量。
e . g . e.g. e.g.
import torch
# 从数据创建张量
x = torch.tensor([1, 2, 3])
# 创建3行2列全零张量
zero_tensor = torch.zeros(3, 2)
# 创建3行2列全1张量
one_tensor = torch.ones(3, 2)
# 创建3行2列随机张量
random_tensor = torch.rand(3, 2)
# 创建3行2列标准正态分布张量
normal_tensor = torch.randn(3, 2)
# 创建3行2列填充张量
full_tensor = torch.full((3, 2), 5)
处理 Numpy 与 PyTorch 张量之间的转换很重要:
import torch
import numpy as np
npy = np.random.rand(2, 3)
tf_npy = torch.from_numpy(npy)
print(tf_npy)
由此,我们将 Numpy 数组变换为 PyTorch 张量。
操作张量
import torch
x = torch.tensor([[1.2, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 操作1:获取张量的形状大小
print(x.shape)
print(x.size())
# 操作2:计算总和
sum_x = torch.sum(x)
print(sum_x)
# 操作3:计算平均值
mean_x = torch.mean(x)
print(mean_x)
# 操作4:计算最小值和最大值
min_x = torch.min(x)
max_x = torch.max(x)
print(min_x, max_x)
# 操作5:找到最小值和最大值的索引
argmin_x = torch.argmin(x)
argmax_x = torch.argmax(x)
print(argmin_x, argmax_x)
索引、切片、联合操作
索引:
import torch
x = torch.tensor([[1.2, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 根据条件选择元素,被筛选掉的用torch.tensor(x)中x替代
where_tensor = torch.where(x > 2, x, torch.tensor(10))
print(where_tensor)
# 根据索引选择元素
index_selected = x[torch.tensor([0, 2])]
print(index_selected)
切片:
import torch
x = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 操作1:获取张量的一部分
subset = x[1:3,2]
print(subset)
# 操作2:获取张量的单行元素
element = x[0]
print(element)
# 操作3:使用布尔掩码选择元素
mask = x > 2
selected = x[mask]
print(selected)
拼接和堆叠
# 拼接
import torch
a = torch.tensor([[1, 2, 3],
[4, 5, 6]])
b = torch.tensor([[7, 8, 9]])
# 拼接张量
# 注意通过 dim 判断行列
cat_tensor = torch.cat((x, y), dim=0)
print(cat_tensor)
# 堆叠
import torch
a = torch.tensor([[1, 2],
[4, 5],
[7, 8]])
b = torch.tensor([[3, 11],
[6, 12],
[9, 13]])
# 堆叠张量
# 注意通过dim指定行列
stack_tensor = torch.stack((a, b), dim=1)
print(stack_tensor)
CUDA张量
CUDA张量核心的优势在于它们可以同时执行多个浮点运算,并且高度优化了内存访问模式,从而在执行矩阵乘法和其他线性代数运算时提供了极高的吞吐量。这对于执行深度学习中的大规模并行计算非常有用。
- 首先检查 GPU、CUDA 是否可用
import torch
print(torch.cuda.is_available())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
如果在含有 GPU 的笔记本显示 CUDA 不可用,可以尝试从 “PyTorch 安装了 CPU 版本”,或者 “GPU 驱动更新” 等角度查找问题。需要注意的是,苹果电脑没有 GPU,自然不存在 CUDA。
- 步骤1 CUDA 可用,那么实例化张量并将其移动到 GPU 上
x = torch.rand(3, 3).to(device)
要对 CUDA 和非 CUDA 对象进行操作,需要确保在用一设备上,否则运算将中断。且 GPU CPU 来回移动数据的成本很高,所以典型的过程是在 GPU 上进行并行化的计算,仅在最终结果出来后传输回 CPU。
此外,如果你有多个 GPU,最佳实践是在执行程序时候使用:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py
发布:2024/2/2
版本:第一版
如有任何疑问,请联系我,谢谢!