RepVGG:让 VGG 风格的 ConvNet 再次伟大
Title:RepVGG: Making VGG-style ConvNets Great Again
paper是清华发表在CVPR 2021的工作
paper链接
Abstract
我们提出了一种简单但功能强大的卷积神经网络架构,它具有类似 VGG 的推理时间主体,仅由 3 × 3 3 \times 3 3×3卷积和 ReLU 堆栈组成,而训练时间模型具有多分支拓扑。这种训练时间和推理时间架构的解耦是通过结构重参数化技术实现的,因此该模型被命名为 RepVGG。据我们所知,在 ImageNet 上,RepVGG 达到了超过 80% 的 top-1 准确率,这对于普通模型来说是第一次。在 NVIDIA 1080Ti GPU 上,RepVGG 模型的运行速度比 ResNet-50 快 83%,比 ResNet-101 快 101%,并且具有更高的精度,并且与 EfficientNet 和 RegNet 等最先进的模型相比,表现出良好的精度与速度权衡。代码和训练模型可在 https://github.com/megvii-model/RepVGG 上获取。
1. Introduction
经典的卷积神经网络(ConvNet)VGG [31]通过由卷积、ReLU 和池化组成的简单架构在图像识别方面取得了巨大成功。随着Inception [33,34,32,19],ResNet [12]和DenseNet [17]的出现,很多研究兴趣转移到了精心设计的架构上,使得模型变得越来越复杂。最近的一些架构基于自动[44,29,23]或手动[28]架构搜索,或搜索复合缩放策略[35]。
尽管许多复杂的卷积网络比简单的卷积网络具有更高的精度,但其缺点也很明显。1)复杂的多分支设计(例如ResNet中的残差加法和Inception中的分支cat)使得模型难以实现和定制,减慢了推理速度并降低了内存利用率。 2)一些组件(例如,Xception [3]和MobileNets [16, 30]中的深度卷积和ShuffleNets [24, 41]中的通道shuffle)增加了内存访问成本,并且缺乏各种设备的支持。由于影响推理速度的因素较多,浮点运算量(FLOPs)并不能准确反映实际速度。尽管一些新颖模型的 FLOPs 低于 VGG 和 ResNet-18/34/50 [12] 等老式模型,但它们的运行速度可能不会更快(表 4)。因此,VGG 和 ResNet 的原始版本仍然在学术界和工业界的实际应用中大量使用。
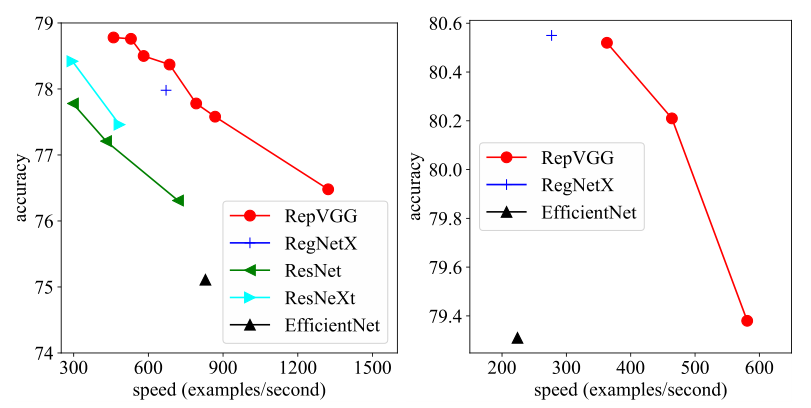
图 1:ImageNet 上的 Top-1 准确率与实际速度。左:轻量级和中量级 RepVGG 以及在 120 个 epoch 中训练的基线。右:经过 200 个 epoch 训练的重量级模型。速度是在相同的 1080Ti 上测试的,批量大小为 128、全精度 (fp32)、单一作物,并以示例/秒为单位进行测量。 EfficientNet-B3 [35] 的输入分辨率为 300,其他网络的输入分辨率为 224。
在本文中,我们提出了 RepVGG,这是一种 VGG 风格的架构,其性能优于许多复杂模型(图 1)。 RepVGG具有以下优点。
-
该模型具有类似 VGG 的普通(又称前馈)拓扑,没有任何分支,这意味着每一层都将其唯一的前一层的输出作为输入,并将输出馈送到其唯一的下一层。
-
该模型的主体仅使用 3 × 3 3 \times 3 3×3卷积和 ReLU。
-
具体架构(包括特定深度和层宽度)是在没有自动搜索[44]、手动细化[28]、复合缩放[35]或其他繁重设计的情况下实例化的。
普通模型要达到与多分支架构相当的性能水平具有挑战性。一种解释是,多分支拓扑(例如 ResNet)使模型成为许多较浅模型的隐式集成[36],因此训练多分支模型可以避免梯度消失问题。
由于多分支架构的优点都在于训练,而缺点对于推理来说是不受欢迎的,因此我们建议通过结构重新参数化来解耦训练时多分支和推理时普通架构,这意味着将架构从一种架构转换为另一种架构具体来说,一个网络结构与一组参数耦合,例如,一个卷积层由一个四阶核张量表示。如果某种结构的参数可以转换为另一种结构耦合的另一组参数,我们就可以等价地用后者代替前者,从而改变整个网络架构。
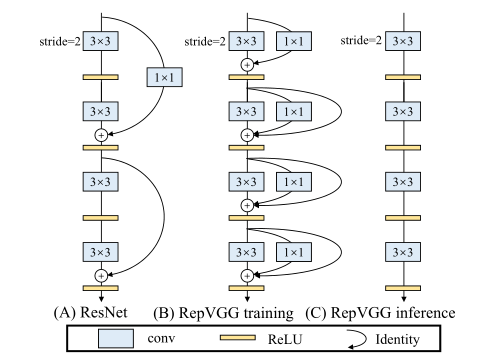
图 2:RepVGG 架构草图。 RepVGG有5个阶段,在阶段开始时通过stride-2卷积进行下采样。这里我们只展示特定阶段的前 4 层。受 ResNet [12] 的启发,我们还使用恒等和 1 × 1 1 \times 1 1×1分支,但仅用于训练。
具体来说,我们使用恒等和 1 × 1 1 \times 1 1×1分支构建训练时 RepVGG,这受到 ResNet 的启发,但方式不同,可以通过结构重新参数化来删除分支(图 2,4)。训练结束后,我们用简单的代数进行变换,因为恒等分支可以看作是退化的 1 × 1 1 \times 1 1×1conv,而后者可以进一步看作是退化的 3 × 3 3 \times 3 3×3conv,这样我们就可以构造一个单一的 3 × 3 3 \times 3 3×3内核,具有原始 3 × 3 3 \times 3 3×3内核、恒等和 1 × 1 1 \times 1 1×1分支以及批量归一化(BN)[19]层的训练参数。因此,转换后的模型具有 3 × 3 3 \times 3 3×3卷积层的堆栈,将其保存以供测试和部署。
值得注意的是,推理时间 RepVGG 的主体只有一种类型的运算符: 3 × 3 3 \times 3 3×3卷积,后跟 ReLU,这使得 RepVGG 在 GPU 等通用计算设备上速度更快。更好的是,RepVGG 允许专用硬件实现更高的速度,因为考虑到芯片尺寸和功耗,我们需要的运算符类型越少,我们可以在芯片上集成的计算单元就越多。因此,专门用于 RepVGG 的推理芯片可以拥有大量的 3 × 3 3 \times 3 3×3-ReLU 单元和更少的内存单元(因为简单的拓扑是内存经济的,如图 3 所示)。我们的贡献总结如下。
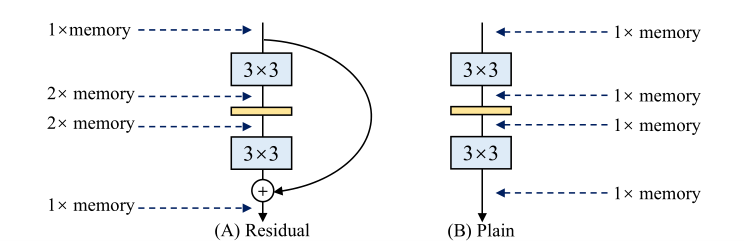
图 3:残差模型和普通模型中的峰值内存占用。如果残差块保持特征图的大小,则特征图占用的额外内存的峰值将是输入的2倍。与因此被忽略的特征相比,参数占用的内存很小。
-
我们提出了 RepVGG,这是一种简单的架构,与最先进的技术相比,具有有利的速度与精度权衡。
-
我们提出使用结构重参数化来将训练时多分支拓扑与推理时简单架构解耦。
-
我们展示了 RepVGG 在图像分类和语义分割方面的有效性,以及实现的效率和简易性。
2. Related Work
2.1. From Single-path to Multi-branch
在 VGG [31] 将 ImageNet 分类的 top-1 准确率提高到 70% 以上之后,在使 ConvNet 变得复杂以获得高性能方面出现了许多创新,例如当代的 GoogLeNet [33] 和后来的 Inception 模型 [34,32,19] 采用了精心设计的多分支架构,ResNet [12]提出了简化的两分支架构,而DenseNet [17]通过将较低级别的层与众多较高级别的层连接起来使拓扑变得更加复杂。神经架构搜索(NAS)[44,29,23,35]和手动设计空间设计[28]可以生成具有更高性能的ConvNet,但代价是大量的计算资源或人力。一些大型版本的 NAS 生成的模型甚至无法在普通 GPU 上进行训练,从而限制了应用。除了实现上的不便之外,复杂的模型可能会降低并行度[24],从而减慢推理速度。
2.2. Effective Training of Single-path Models
已经有人尝试在没有分支的情况下训练卷积网络。然而,先前的工作主要试图使非常深的模型以合理的精度收敛,但没有获得比复杂模型更好的性能。因此,这些方法和所得模型既不简单也不实用。提出了一种初始化方法[37]来训练极深的普通ConvNet。通过基于平均场理论的方案,10,000 层网络在 MNIST 上的训练精度超过 99%,在 CIFAR-10 上训练精度超过 82%。尽管这些模型并不实用(甚至 LeNet-5 [21] 在 MNIST 上可以达到 99.3% 的准确率,VGG-16 在 CIFAR10 上可以达到 93% 以上),但理论贡献是富有洞察力的。最近的一项工作 [25] 结合了多种技术,包括 Leaky ReLU、max-norm 和仔细初始化。在 ImageNet 上,它表明具有 147M 参数的普通 ConvNet 可以达到 74.6% 的 top-1 准确率,比其报告的基线(ResNet-101,76.6%,45M 参数)低 2%。
值得注意的是,本文不仅仅是证明普通模型可以很好地收敛,并且并不打算训练像 ResNet 这样的极深的 ConvNet。相反,我们的目标是构建一个具有合理深度和有利的精度-速度权衡的简单模型,该模型可以使用最常见的组件(例如常规卷积和 BN)和简单代数简单地实现。
2.3. Model Re-parameterization
DiracNet [39] 是一种与我们相关的重参数化方法。它通过将卷积层的内核编码为 W ^ = diag ( a ) I + diag ( b ) W norm \hat{W}=\operatorname{diag}(\mathbf{a}) \mathrm{I}+\operatorname{diag}(\mathbf{b}) \mathrm{W}_{\text {norm }} W^=diag(a)I+diag(b)Wnorm 来构建深层普通模型,其中 W ^ \hat{W} W^是用于卷积的最终权重(视为矩阵的四阶张量), a \mathbf{a} a和 b \mathbf{b} b是学习向量, W norm \mathrm{W}_{\text {norm }} Wnorm 是标准化的可学习内核。与参数数量相当的 ResNet 相比,DiracNet 的 top-1 准确率在 CIFAR100 上低 2.29%(78.46% vs. 80.75%),在 ImageNet 上低 0.62%(DiracNet-34 的 72.21% vs. ResNet 的 72.83%)。 DiracNet 在两个方面与我们的方法不同。 1)RepVGG 的训练时间行为是由实际数据流通过具体结构实现的,该结构可以稍后转换为另一个结构,而 DiracNet 仅使用另一种卷积核的数学表达式来更容易优化。换句话说,训练时 RepVGG 是真正的多分支模型,但 DiracNet 不是。 2)DiracNet 的性能高于正常参数化的普通模型,但低于可比的 ResNet,而 RepVGG 模型的性能大幅优于 ResNet。 Asym Conv Block (ACB) [10]、DO-Conv [1] 和 ExpandNet [11] 也可以被视为结构重参数化,因为它们将块转换为卷积。与我们的方法相比,不同之处在于它们是为组件级改进而设计的,并用作任何架构中卷积层的直接替代品,而我们的结构重参数化对于训练普通 ConvNet 至关重要,如第 4.2 节所示。
2.4. Winograd Convolution
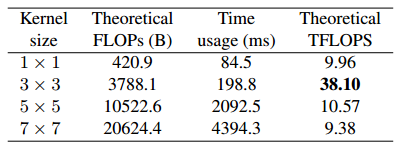
RepVGG 仅使用 3 × 3 3 \times 3 3×3卷积,因为它在 GPU 和 CPU 上通过一些现代计算库(如 NVIDIA cuDNN [2] 和 Intel MKL [18])进行了高度优化。表 1 显示了在 1080Ti GPU 上使用 cuDNN 7.5.0 测试的理论 FLOPs、实际运行时间和计算密度(以每秒万亿次浮点运算,TFLOPS 为单位测量)。 3 × 3 3 \times 3 3×3卷积的理论计算密度约为其他卷积的 4 倍,这表明总理论 FLOPs 并不能代表不同架构之间的实际速度。 Winograd [20] 是一种加速 3 × 3 3 \times 3 3×3卷积的经典算法(仅当步长为 1 时),它得到了 cuDNN 和 MKL 等库的良好支持(默认启用)。例如,使用标准 F ( 2 × 2 , 3 × 3 ) F(2 \times 2,3 \times 3) F(2×2,3×3)Winograd, 3 × 3 3 \times 3 3×3卷积的乘法量 (MUL) 减少到原始的 4 9 \frac{4}{9} 94。由于乘法比加法更耗时,因此我们在 Winograd 支持下计算 MUL 来衡量计算成本(在表 4、5 中用 Wino MULs 表示)。请注意,具体的计算库和硬件决定每个算子是否使用 Winograd,因为小规模卷积可能会因内存开销而无法加速。
表 1:NVIDIA 1080Ti 上不同内核大小和批量大小 = 32、输入通道 = 输出通道 = 2048、分辨率 = 56×56、步长 = 1 的速度测试。时间使用结果是硬件预热后运行 10 次的平均值。
3. Building RepVGG via Structural Re-param
3.1. Simple is Fast, Memory-economical, Flexible
使用简单的卷积网络至少有三个原因:快速、节省内存和灵活。
快速 许多最近的多分支架构的理论 FLOPs 低于 VGG,但可能运行速度并不快。例如,VGG-16 的 FLOPs 为 EfficientNet-B3 [35] 的 8.4 倍,但在 1080Ti 上运行速度快 1.8 倍(表 4),这意味着前者的计算密度是后者的 15 倍。除了Winograd conv带来的加速之外,FLOPs和速度之间的差异可以归因于两个对速度有很大影响但FLOPs没有考虑到的重要因素:内存访问成本(MAC)和并行度[24 ]。例如,虽然分支相加或cat所需的计算可以忽略不计,但 MAC 却很重要。此外,MAC 占据了分组卷积中大部分时间的使用。另一方面,在相同的 FLOPs 下,具有高并行度的模型可能比另一个具有低并行度的模型快得多。由于多分支拓扑在 Inception 和自动生成架构中被广泛采用,因此使用多个小型算子而不是几个大型算子。之前的一项工作[24]报道了NASNET-A[43]中碎片算子的数量(即一个构建块中单独的卷积或池化操作的数量)为13,这对于像GPU这样具有强大并行计算能力的设备不友好并引入额外的开销,例如内核启动和同步。相比之下,这个数字在ResNets中是2或3,我们将其设为1:单个卷积。
内存经济 多分支拓扑的内存效率较低,因为每个分支的结果都需要保留到相加或cat为止,从而显着提高了内存占用的峰值。图 3 显示残差块的输入需要保留到相加为止。假设块保持特征图大小,则额外内存占用的峰值为2×作为输入。相反,普通拓扑允许特定层的输入占用的内存在操作完成时立即释放。在设计专用硬件时,普通的 ConvNet 可以进行深度内存优化并降低内存单元的成本,以便我们可以将更多的计算单元集成到芯片上。
灵活 多分支拓扑对架构规范施加了限制。例如,ResNet 要求将卷积层组织为残差块,这限制了灵活性,因为每个残差块的最后一个卷积层必须产生相同形状的张量,否则快捷方式相加将没有意义。更糟糕的是,多分支拓扑限制了通道剪枝的应用[22, 14],这是一种去除一些不重要通道的实用技术,并且一些方法可以通过自动发现每层的适当宽度来优化模型结构[8] 。然而,多分支模型使修剪变得棘手,并导致性能显着下降或加速比低[7,22,9]。相比之下,简单的架构允许我们根据我们的要求自由配置每个卷积层并进行修剪以获得更好的性能效率权衡。
3.2. Training-time Multi-branch Architecture
普通卷积网络有很多优点,但有一个致命的缺点:性能不佳。例如,使用 BN [19] 等现代组件,VGG-16 在 ImageNet 上可以达到超过 72% 的 top-1 准确率,这似乎已经过时了。我们的结构重参数化方法受到 ResNet 的启发,它显式地构造一个快捷分支来将信息流建模为 y = x + f ( x ) y=x+f(x) y=x+f(x)并使用残差块来学习 f f f。当 x x x和 f ( x ) f(x) f(x)的维度不匹配时,就变成 y = g ( x ) + f ( x ) y=g(x)+f(x) y=g(x)+f(x),其中 g ( x ) g(x) g(x)是由 1 × 1 1 \times 1 1×1conv实现的卷积捷径。 ResNets 成功的一个解释是,这种多分支架构使模型成为众多浅层模型的隐式集合 [36]。具体来说,对于 n n n个块,模型可以解释为 2 n 2^n 2n个模型的集合,因为每个块将流分支为两条路径。
由于多分支拓扑在推理方面存在缺陷,但分支似乎有利于训练[36],因此我们使用多个分支来制作众多模型的仅训练时间集成。为了使大多数成员更浅或更简单,我们使用类似 ResNet 的恒等(仅当维度匹配时)和 1 × 1 1 \times 1 1×1分支,以便构建块的训练时信息流为 y = y= y= x + g ( x ) + f ( x ) x+g(x)+f(x) x+g(x)+f(x)。我们简单地堆叠几个这样的块来构建训练时间模型。从与[36]相同的角度来看,该模型成为具有 n n n个这样的块的 3 n 3^n 3n个成员的集合。
3.3. Re-param for Plain Inference-time Model
在本小节中,我们描述如何将经过训练的块转换为单个
3
×
3
3 \times 3
3×3卷积层以进行推理。请注意,我们在加法之前的每个分支中都使用了 BN(图 4)。形式上,我们使用
W
(
3
)
∈
R
C
2
×
C
1
×
3
×
3
\mathrm{W}^{(3)} \in \mathbb{R}^{C_2 \times C_1 \times 3 \times 3}
W(3)∈RC2×C1×3×3表示具有
C
1
C_1
C1输入通道和
C
2
C_2
C2输出通道的
3
×
3
3 \times 3
3×3卷积层的内核,并使用
W
(
1
)
∈
R
C
2
×
C
1
\mathrm{W}^{(1)} \in \mathbb{R}^{C_2 \times C_1}
W(1)∈RC2×C1表示内核
1
×
1
1 \times 1
1×1分支。我们使用
μ
(
3
)
,
σ
(
3
)
,
γ
(
3
)
,
β
(
3
)
\boldsymbol{\mu}^{(3)}, \boldsymbol{\sigma}^{(3)}, \boldsymbol{\gamma}^{(3)}, \boldsymbol{\beta}^{(3)}
μ(3),σ(3),γ(3),β(3)作为
3
×
3
3 \times 3
3×3卷积之后 BN 层的累积平均值、标准差以及学习缩放因子和偏差,
μ
(
1
)
,
σ
(
1
)
,
γ
(
1
)
,
β
(
1
)
\boldsymbol{\mu}^{(1)}, \boldsymbol{\sigma}^{(1)}, \boldsymbol{\gamma}^{(1)}, \boldsymbol{\beta}^{(1)}
μ(1),σ(1),γ(1),β(1)表示
1
×
1
1 \times 1
1×1卷积后的 BN,
μ
(
0
)
,
σ
(
0
)
,
γ
(
0
)
,
β
(
0
)
\boldsymbol{\mu}^{(0)}, \boldsymbol{\sigma}^{(0)}, \boldsymbol{\gamma}^{(0)}, \boldsymbol{\beta}^{(0)}
μ(0),σ(0),γ(0),β(0)表示恒等分支。设
M
(
1
)
∈
R
N
×
C
1
×
H
1
×
W
1
\mathrm{M}^{(1)} \in \mathbb{R}^{N \times C_1 \times H_1 \times W_1}
M(1)∈RN×C1×H1×W1,
M
(
2
)
∈
R
N
×
C
2
×
H
2
×
W
2
\mathrm{M}^{(2)} \in \mathbb{R}^{N \times C_2 \times H_2 \times W_2}
M(2)∈RN×C2×H2×W2分别为输入和输出,
∗
*
∗为卷积算子。如果
C
1
=
C
2
,
H
1
=
C_1=C_2, H_1=
C1=C2,H1=
H
2
,
W
1
=
W
2
H_2, W_1=W_2
H2,W1=W2,我们有
M
(
2
)
=
bn
(
M
(
1
)
∗
W
(
3
)
,
μ
(
3
)
,
σ
(
3
)
,
γ
(
3
)
,
β
(
3
)
)
+
bn
(
M
(
1
)
∗
W
(
1
)
,
μ
(
1
)
,
σ
(
1
)
,
γ
(
1
)
,
β
(
1
)
)
+
bn
(
M
(
1
)
,
μ
(
0
)
,
σ
(
0
)
,
γ
(
0
)
,
β
(
0
)
)
.
\begin{aligned} \mathrm{M}^{(2)} & =\operatorname{bn}\left(\mathrm{M}^{(1)} * \mathrm{~W}^{(3)}, \boldsymbol{\mu}^{(3)}, \boldsymbol{\sigma}^{(3)}, \boldsymbol{\gamma}^{(3)}, \boldsymbol{\beta}^{(3)}\right) \\ & +\operatorname{bn}\left(\mathrm{M}^{(1)} * \mathrm{~W}^{(1)}, \boldsymbol{\mu}^{(1)}, \boldsymbol{\sigma}^{(1)}, \boldsymbol{\gamma}^{(1)}, \boldsymbol{\beta}^{(1)}\right) \\ & +\operatorname{bn}\left(\mathrm{M}^{(1)}, \boldsymbol{\mu}^{(0)}, \boldsymbol{\sigma}^{(0)}, \boldsymbol{\gamma}^{(0)}, \boldsymbol{\beta}^{(0)}\right) . \end{aligned}
M(2)=bn(M(1)∗ W(3),μ(3),σ(3),γ(3),β(3))+bn(M(1)∗ W(1),μ(1),σ(1),γ(1),β(1))+bn(M(1),μ(0),σ(0),γ(0),β(0)).
否则,我们只是不使用恒等分支,因此上面的方程只有前两项。这里 bn 是推理时间 BN 函数,形式上,
∀
1
≤
i
≤
C
2
\forall 1 \leq i \leq C_2
∀1≤i≤C2,
bn
(
M
,
μ
,
σ
,
γ
,
β
)
:
,
i
,
:
,
:
=
(
M
:
,
i
,
:
,
:
−
μ
i
)
γ
i
σ
i
+
β
i
.
\operatorname{bn}(\mathrm{M}, \boldsymbol{\mu}, \boldsymbol{\sigma}, \boldsymbol{\gamma}, \boldsymbol{\beta})_{:, i,:,:}=\left(\mathrm{M}_{:, i,:,:}-\boldsymbol{\mu}_i\right) \frac{\boldsymbol{\gamma}_i}{\boldsymbol{\sigma}_i}+\boldsymbol{\beta}_i \text {. }
bn(M,μ,σ,γ,β):,i,:,:=(M:,i,:,:−μi)σiγi+βi.
我们首先将每个 BN 及其前面的卷积层转换为带有偏差向量的卷积。设
{
W
′
,
b
′
}
\left\{\mathrm{W}^{\prime}, \mathbf{b}^{\prime}\right\}
{W′,b′}为核,偏置由
{
W
,
μ
,
σ
,
γ
,
β
}
\{\mathrm{W}, \boldsymbol{\mu}, \boldsymbol{\sigma}, \boldsymbol{\gamma}, \boldsymbol{\beta}\}
{W,μ,σ,γ,β}转换而来,我们有
W
i
,
:
,
:
,
:
′
=
γ
i
σ
i
W
i
,
:
,
:
,
:
,
b
i
′
=
−
μ
i
γ
i
σ
i
+
β
i
.
\mathrm{W}_{i,:,:,:}^{\prime}=\frac{\gamma_i}{\sigma_i} \mathrm{~W}_{i,:,:,:}, \quad \mathbf{b}_i^{\prime}=-\frac{\boldsymbol{\mu}_i \gamma_i}{\sigma_i}+\boldsymbol{\beta}_i .
Wi,:,:,:′=σiγi Wi,:,:,:,bi′=−σiμiγi+βi.
那么很容易验证
∀
1
≤
i
≤
C
2
\forall 1 \leq i \leq C_2
∀1≤i≤C2,
bn
(
M
∗
W
,
μ
,
σ
,
γ
,
β
)
:
,
i
,
:
,
:
=
(
M
∗
W
′
)
:
,
i
,
:
,
:
+
b
i
′
\operatorname{bn}(\mathrm{M} * \mathrm{~W}, \boldsymbol{\mu}, \boldsymbol{\sigma}, \boldsymbol{\gamma}, \boldsymbol{\beta})_{:, i,:,:}=\left(\mathrm{M} * \mathrm{~W}^{\prime}\right)_{:, i,:,:}+\mathbf{b}_i^{\prime}
bn(M∗ W,μ,σ,γ,β):,i,:,:=(M∗ W′):,i,:,:+bi′
这种变换也适用于恒等分支,因为恒等可以被视为以恒等矩阵为核的 1 × 1 1 \times 1 1×1卷积。经过这样的转换,我们将拥有一个 3 × 3 3 \times 3 3×3内核、两个 1 × 1 1 \times 1 1×1内核和三个偏置向量。然后,我们通过将三个偏差向量相加得到最终的偏差,并通过将 1 × 1 1 \times 1 1×1核添加到 3 × 3 3 \times 3 3×3核的中心点来获得最终的 3 × 3 3 \times 3 3×3核,这可以通过首先对两个核进行零填充来轻松实现将 1 × 1 1 \times 1 1×1核转换为 3 × 3 3 \times 3 3×3并将三个核相加,如图 4 所示。请注意,这种转换的等价性要求 3 × 3 3 \times 3 3×3和 1 × 1 1 \times 1 1×1层具有相同的步幅,并且填充配置为后者应比前者少一个像素。例如,对于将输入填充一个像素的 3 × 3 3 \times 3 3×3层(这是最常见的情况), 1 × 1 1 \times 1 1×1层应将 padding = 0。
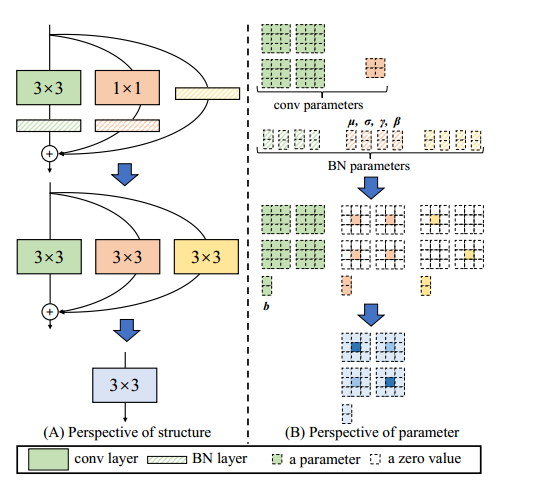
图 4:RepVGG 模块的结构重参数化。为了便于可视化,我们假设 C 2 = C 1 = 2 C_2=C_1=2 C2=C1=2,因此 3 × 3 3 \times 3 3×3层有四个 3 × 3 3 \times 3 3×3矩阵, 1 × 1 1 \times 1 1×1层的内核是 2 × 2 2 \times 2 2×2矩阵。
3.4. Architectural Specification
表 2 显示了 RepVGG 的规格,包括深度和宽度。 RepVGG 是 VGG 风格,因为它采用简单的拓扑并大量使用 3 × 3 3 \times 3 3×3卷积,但它不像 VGG 那样使用最大池化,因为我们希望主体只有一种类型的运算符。我们将 3×3 层分为 5 个阶段,阶段的第一层以步长 = 2 进行下采样。对于图像分类,我们使用全局平均池化,然后使用全连接层作为头部。对于其他任务,特定于任务的头可以用于任何层生成的特征。
表 2:RepVGG 的架构规范。这里 2 × 64a 意味着 stage2 有 2 层,每层有 64a 通道。

我们按照三个简单的准则来决定每个阶段的层数。 1)第一阶段以高分辨率运行,这很耗时,因此我们仅使用一层以降低延迟。 2)最后一级需要有更多的通道,因此我们只使用一层来保存参数。 3)我们将最多的层放入倒数第二阶段(ImageNet 上的输出分辨率为 14 × 14 14 \times 14 14×14),遵循 ResNet 及其最新变体 [12,28,38](例如,ResNet-101在其14×14分辨率阶段使用69层)。我们让这五个阶段分别有1、2、4、14、1层,构建一个名为RepVGG-A的实例。我们还构建了一个更深的 RepVGG-B,它在第 2、3 和 4 阶段又多了 2 层。我们使用RepVGG-A与其他轻量级和中量级模型(包括ResNet-18/34/50)竞争,并使用RepVGG-B与高性能模型竞争。
我们通过统一缩放经典宽度设置 [64, 128, 256, 512](例如 VGG 和 ResNets)来确定层宽度。我们使用乘数 a 来缩放前四个阶段,使用 b 来缩放最后一个阶段,并且通常设置 b > a,因为我们希望最后一层具有更丰富的特征用于分类或其他下游任务。由于 RepVGG 在最后阶段只有一层,因此较大的 b 不会显着增加延迟或参数量。具体来说,stage2、3、4、5的宽度分别为[64a,128a,256a,512b]。为了避免在高分辨率特征图上进行大规模卷积,如果 a < 1,我们缩小 stage1 但不放大,因此 stage1 的宽度为 min(64, 64a)。
为了进一步减少参数和计算量,我们可以选择将分组 3 × 3 3 \times 3 3×3卷积层与密集层交错,以牺牲准确性和效率。具体来说,我们为 RepVGG-A 的第 3、5、7、…、第 21 层以及 RepVGG-B 的附加第 23、25 和 27 层设置组数 g g g。为了简单起见,我们将这些层的 g g g全局设置为 1、2 或 4,而不进行逐层调整。我们不使用相邻的分组卷积层,因为这会禁用通道间信息交换并带来副作用[41]:某个通道的输出将仅来自输入通道的一小部分。请注意, 1 × 1 1 \times 1 1×1分支应具有与 3 × 3 3 \times 3 3×3卷积相同的 g g g。
4. Experiments
我们将 RepVGG 与 ImageNet 上的基线进行比较,通过一系列消融研究和比较证明结构重参数化的重要性,并验证语义分割的泛化性能[42]。
4.1. RepVGG for ImageNet Classification
我们将 RepVGG 与 ImageNet-1K [6] 上的经典和最先进的模型进行比较,包括 VGG-16 [31]、ResNet [12]、ResNeXt [38]、EfficientNet [35] 和 RegNet [28],其中包括 128 万张用于训练的图像和 5 万张用于验证的图像。我们分别使用 EfficientNet-B0/B3 和 RegNet3.2GF/12GF 作为中量级和重量级最先进模型的代表。我们改变乘数 a 和 b 以生成一系列 RepVGG 模型,以便与基线进行比较(表 3)。
表 3:由乘数 a 和 b 定义的 RepVGG 模型。
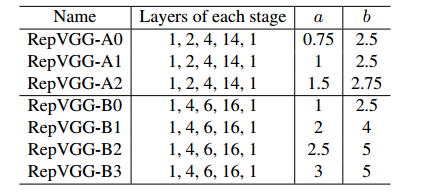
我们首先将 RepVGG 与 ResNets [12] 进行比较,这是最常见的基准。我们分别使用RepVGGA0/A1/A2与ResNet-18/34/50进行比较。为了与较大的模型进行比较,我们构建了更深的 RepVGG-B0/B1/B2/B3 并增加了宽度。对于那些具有交错分组层的 RepVGG 模型,我们将 g2/g4 后缀到模型名称。
为了训练轻量级和中量级模型,我们仅使用简单的数据增强管道,包括随机裁剪和左右翻转,遵循官方 PyTorch 示例 [27]。我们在 8 个 GPU 上使用 256 的全局批量大小、初始化为 0.1 的学习率和 120 个周期的余弦退火、动量系数为 0.9 的标准 SGD、卷积层和全连接层内核上的权重衰减为 10−4。对于包括 RegNetX-12GF、EfficientNet-B3 和 RepVGG-B3 在内的重量级模型,我们使用 5 epoch 预热、200 epoch 的余弦学习率退火、标签平滑 [34] 和 mixup [40](以下 [13]),以及Autoaugment [5] 的数据增强管道,随机裁剪和翻转。RepVGG-B2 及其 g2/g4 变体在两种设置下进行训练。我们在 1080Ti GPU 上测试批量大小为 128 的每个模型的速度,首先输入 50 个批次来预热硬件,然后输入 50 个批次并记录时间使用情况。为了公平比较,我们在同一 GPU 上测试所有模型,并且基线的所有 conv-BN 序列也转换为带有偏差的 conv(方程 3)。
表 4 显示了 RepVGG 有利的精度与速度权衡:RepVGG-A0 在精度和速度方面比 ResNet-18 好 1.25% 和 33%,RepVGGA1 比 ResNet-34 好 0.29%/64%,RepVGG-A2比 ResNet-50 好 0.17%/83%。通过交错的分组层 (g2/g4),RepVGG 模型进一步加速,但精度下降合理:RepVGG-B1g4 比 ResNet-101 好 0.37%/101%,而 RepVGGB1g2 的速度是 ResNet-152 的 2.66 倍,令人印象深刻。相同的精度。虽然参数数量不是我们主要关心的问题,但上述所有 RepVGG 模型的参数效率都比 ResNet 更高。与经典的VGG-16相比,RepVGG-B2只有58%的参数,运行速度提高了10%,准确率提高了6.57%。据我们所知,与使用 RePr [26](一种基于剪枝的训练方法)训练的最高准确率 (74.5%) VGG 相比,RepVGG-B2 的准确率高出 4.28%。
表 4:在 ImageNet 上进行 120 个时期的简单数据增强训练的结果。速度在 1080Ti 上测试,批量大小为 128,全精度 (fp32),并以示例/秒为单位进行测量。我们按照 2.4 节中的描述计算理论 FLOPs 和 Wino MUL。基线是我们在相同训练设置下的实现。
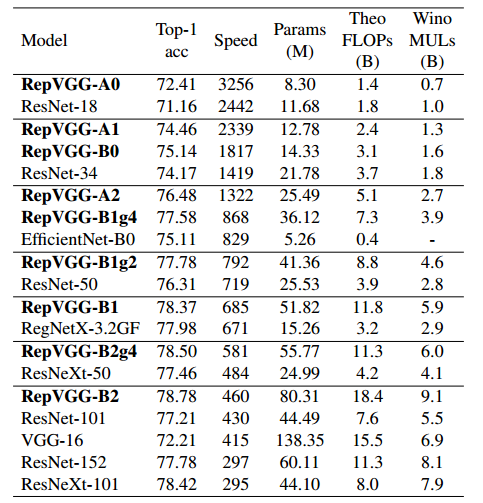
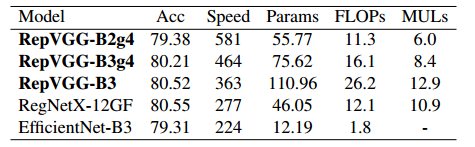
与最先进的基线相比,考虑到其简单性,RepVGG 也表现出了良好的性能:RepVGG-A2 比 EfficientNetB0 好 1.37%/59%,RepVGG-B1 比 RegNetX3.2GF 性能好 0.39%,并且运行速度稍快。值得注意的是,RepVGG 模型在 200 个 epoch 中达到了 80% 以上的准确率(表 5),据我们所知,这是普通模型第一次赶上最先进的技术。与 RegNetX-12GF 相比,RepVGG-B3 的运行速度快了 31%,考虑到 RepVGG 不需要像 RegNet [28] 那样需要大量人力来细化设计空间,并且架构超参数设置随意,这令人印象深刻。
表 5:使用 Autoaugment [5]、标签平滑和混合进行 200 个 epoch 训练的 ImageNet 结果。
作为计算复杂度的两个指标,我们计算理论 FLOP 和 Wino MUL,如第 2.4 节中所述.例如,我们发现 EfficientNet-B0/B3 中的所有卷积都没有通过 Winograd 算法加速。表 4 显示 Wino MUL 是 GPU 上更好的代理,例如,ResNet-152 的运行速度比 VGG-16 慢,理论 FLOPs 较低,但 Wino MUL 较高。当然,实际速度应该始终是黄金标准。
4.2. Structural Re-parameterization is the Key
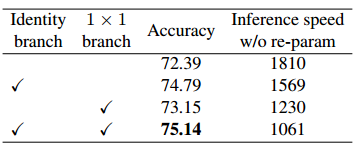
在本小节中,我们验证结构重参数化技术的重要性(表 6)。所有模型均使用上述相同的简单训练设置从头开始训练 120 个epoch。首先,我们通过从 RepVGG-B0 的每个块中删除同一性和/或 1 × 1 1 \times 1 1×1分支来进行消融研究。删除两个分支后,训练时模型退化为普通的普通模型,并且仅达到 72.39% 的准确率。 1 × 1 1 \times 1 1×1时准确率提升至 73.15%,同一性时准确率提升至 74.79%。全功能RepVGGB0的准确率为75.14%,比普通普通模型高2.75%。从训练时(即尚未转换)模型的推理速度来看,通过结构重参数化去除恒等和 1 × 1 1 \times 1 1×1分支带来了显着的加速。
表 6:RepVGG-B0 上 120 个时期的消融研究。使用转换前的模型测试没有重新参数的推理速度(示例/秒)(批量大小= 128)。再次注意,所有模型都具有相同的最终结构。
然后我们构建了一系列变体和基线以在 RepVGG-B0 上进行比较(表 7)。同样,所有模型都经过 120 个 epoch 从头开始训练。
-
Identity w/o BN 删除了 Identity 分支中的 BN。
-
Post-addition BN 去除了三个分支中的 BN 层,并在相加后追加了一个 BN 层。也就是说,BN的位置从预加变成了后加。
-
+ReLU in Branches 将 ReLU 插入到每个分支中(BN 之后、加法之前)。由于这样的块无法转换为单个卷积层,因此没有实际用途,我们只是想看看更多的非线性是否会带来更高的性能。
-
DiracNet [39] 采用了精心设计的卷积核重参数化,如第 2.2 节中所述。我们使用其官方 PyTorch 代码来构建层来替换原始的 3 × 3 3 \times 3 3×3卷积。
-
Trivial Re-param 是通过直接向 3 × 3 3 \times 3 3×3内核添加恒等内核来对卷积内核进行更简单的重参数化,可以将其视为 DiracNet 的降级版本( W ^ = I + W \hat{W}=I+W W^=I+W[39])。
-
不对称卷积块(ACB)[10]可以被视为结构重参数化的另一种形式。我们与 ACB 进行比较,看看结构重参数化的改进是否是由于组件级的过度参数化(即额外的参数使每个 3 × 3 3 \times 3 3×3卷积变得更强)。
-
Residual Reorg 通过以类似 ResNet 的方式重新组织每个阶段来构建每个阶段(每个块 2 层)。具体来说,生成的模型在第一阶段和最后阶段有一个 3 × 3 3 \times 3 3×3层,在第 2、3、4 阶段有 2、3、8 个残差块,并使用与 ResNet-18/34 类似的快捷方式。
我们认为结构重新参数相对于 DiractNet 和 Trivial Re-param 的优越性在于,前者依赖于通过具有非线性行为(BN)的具体结构的实际数据流,而后者仅使用卷积核的另一种数学表达式。前者的“re-param”意思是“使用一个结构体的参数来参数化另一个结构体”,而后者的意思是“先用另一组参数计算该参数,然后将它们用于其他计算”。对于像训练时间 BN 这样的非线性组件,前者不能用后者来近似。作为证据,删除 BN 会降低准确性,而添加 ReLU 会提高准确性。换句话说,虽然 RepVGG 块可以等效地转换为单个卷积进行推理,但推理时间等价并不意味着训练时间等价,因为我们无法构造一个具有与 RepVGG 块相同的训练时间行为的卷积层。
与 ACB 的比较表明,RepVGG 的成功不应简单地归因于每个组件的过度参数化的影响,因为 ACB 使用更多参数但性能较差。作为双重检查,我们用 RepVGG 块替换 ResNet-50 的每个 3 × 3 3 \times 3 3×3卷积,并从头开始训练 120 个 epoch。准确度为 76.34%,仅比 ResNet-50 基线高 0.03%,这表明 RepVGGstyle 结构重参数化不是通用的过参数化技术,而是训练强大的普通 ConvNet 的关键方法。与 Residual Reorg(具有相同数量的 3 × 3 3 \times 3 3×3卷积和额外的训练和推理快捷方式的真实残差网络)相比,RepVGG 的性能优于 0.58%,这并不奇怪,因为 RepVGG 的分支要多得多。例如,分支使 RepVGG 的 stage4 成为 2 × 3 15 = 2.8 × 1 0 7 2 \times 3^{15}=2.8 \times 10^7 2×315=2.8×107个模型的集合 [36],而 Residual Reorg 的数量为 2 8 = 256 2^8=256 28=256。
4.3. Semantic Segmentation
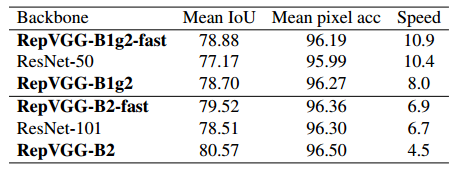
我们验证了 ImageNetpretrained RepVGG 在城市景观上的语义分割的泛化性能 [4](表 8)。我们使用 PSPNet [42] 框架,这是一个基数为 0.01、幂为 0.9、权重衰减为 10−4、全局批量大小为 16、在 8 个 GPU 上持续 40 个周期的多元学习率策略。为了公平比较,我们仅将 ResNet-50/101 主干更改为 RepVGG-B1g2/B2,并保持其他设置相同。继官方 PSPNet-50/101 [42] 在 ResNet-50/101 的最后两个阶段使用扩张卷积之后,我们也使 RepVGG-B1g2/B2 最后两个阶段的所有 3 × 3 卷积层扩张。然而,当前 3 × 3 扩张卷积的低效实现(尽管 FLOP 与 3 × 3 常规卷积相同)会减慢推理速度。为了便于比较,我们构建了另外两个 PSPNets(用 fast 表示),仅在最后 5 层(即 stage4 的最后 4 层和 stage5 的唯一层)进行扩张,因此 PSPNets 的运行速度略快于ResNet-50/101-主干对应。 RepVGG 主干网在平均 IoU 方面比 ResNet-50 和 ResNet-101 分别高出 1.71% 和 1.01%,且速度更快,而 RepVGG-B1g2-fast 在 mIoU 方面比 ResNet-101 主干网高 0.37,运行速度快 62%。有趣的是,扩张对于较大的模型似乎更有效,因为与 RepVGG-B1g2-fast 相比,使用更多扩张的卷积层并没有提高性能,但在合理的减速下将 RepVGG-B2 的 mIoU 提高了 1.05%。
表 8:在验证子集上测试的城市景观 [4] 语义分割。速度(示例/秒)是在同一 1080Ti GPU 上以批量大小 16、全精度 (fp32) 和输入分辨率 713 × 713 713 \times 713 713×713进行测试的。
4.4. Limitations
RepVGG 模型是快速、简单且实用的 ConvNet,专为 GPU 和专用硬件上的最大速度而设计,不太关心参数数量。它们比 ResNets 的参数效率更高,但可能不如低功耗设备的 MobileNets [16, 30, 15] 和 ShuffleNets [41, 24] 等移动机制模型受到青睐。
5. Conclusion
我们提出了 RepVGG,一种由 3 × 3 3 \times 3 3×3卷积和 ReLU 组成的堆栈的简单架构,特别适合 GPU 和专用推理芯片。通过我们的结构重参数化方法,它在 ImageNet 上达到了超过 80% 的 top-1 精度,并且与最先进的模型相比,显示出有利的速度与精度权衡。