数据结构与算法——链表原理及C语言实现
- 链表的原理
- 链表的基本属性设计
- 创建一个空链表
- 链表的遍历(显示数据)
- 释放链表内存空间
- 链表的基本操作设计(增删改查)
- 链表插入节点
- 链表删除节点
- 链表查找节点
- 增删改查测试程序
- 链表的复杂操作程序设计
- 单链表的反转
- 相邻节点最大值
- 有序链表的合并
- 链表的排序
参考博文1:【数据结构与算法】程序内功篇三–单链表
参考博文2:链表基础知识详解(非常详细简单易懂)
参考博文3:关于链表,看这一篇就足够了!(新手入门)
参考博文4:单链表——单链表的定义及基本操作
链表的原理
链表含义
由于顺序表的插入删除操作需要移动大量的元素,影响了运行效率,因此引入了线性表的链式存储——单链表。
单链表的特点:
- 单链表不要求逻辑上相邻的两个元素在物理位置上也相邻,因此链表两个节点的存储空间不相邻。
- 单链表是非随机的存储结构,即不能直接找到表中某个特定的结点。查找某个特定的结点时,需要从表头开始遍历,依次查找。
- 对于每个链表结点,分为存放数据的数据域以及存放下个节点地址的地址域
链表节点的定义:
typedef int data_t;
//结点定义
typedef struct node{
data_t data; //结点数据域
struct node *next; //结点后继指针域
}listNode;
链表的基本属性设计
创建一个空链表
通常会用头指针来标识一个单链表,头指针为NULL时表示一个空表。但是,为了操作方便,会在单链表的第一个结点之前附加一个结点,称为头结点。头结点的数据域可以不设任何信息,也可以记录表长等信息。头结点的指针域指向线性表的第一个元素结点。

创建空链表(头指针)主要分为:①申请节点内存空间 ②成员变量赋初始值 ③返回头节点 三大步骤:
- 功能:创建一个空链表 node为虚拟头节点
- 参数:void
- 返回值:头节点地址
/*
功能:创建一个空链表 node为虚拟头节点
参数:void
返回值:头节点地址
*/
listNode* link_create()
{
//申请内存空间
listNode* node = (listNode *)malloc(sizeof(listNode));
if(node == NULL){
printf("link_create: malloc error\n");
return NULL;
}
//链表成员变量赋值
node->data = 0;
node->next = NULL;
//返回链表地址
return node;
}
链表的遍历(显示数据)
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
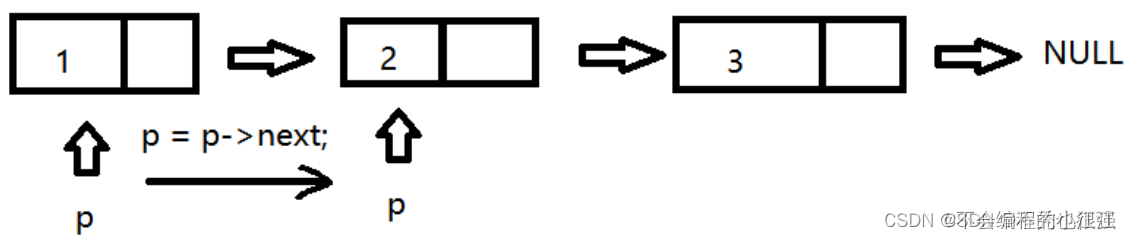
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移

第三步:以此类推,直到节点的指针域为NULL
通过遍历链表读取链表的数据并显示:
- 功能:显示链表数据
- 参数:para: 链表头
- 返回值:成功返回0 失败返回-1
/*
功能:显示链表数据
参数:para: 链表头
返回值:成功返回0; 失败返回-1
*/
int link_show(listNode* head)
{
//入口参数检查
if(head == NULL)
return -1;
//遍历链表
while(head->next != NULL)
{
printf("%d ", head->next->data);
head = head->next;
}
printf("\n");
return 0;
}
释放链表内存空间
通过遍历链表节点,释放每个节点的内存空间
- 功能:释放链表内存空间
- 参数:para: 链表头
- 返回值: NULL
/*
功能:释放链表内存空间
参数:para :链表头
返回值: NULL
*/
listNode* link_free(listNode* head)
{
//入口参数检查
if(head == NULL){
printf("list_insert: para error\n");
return NULL;
}
//封装临时节点
listNode *temp = head;
while(head != NULL)
{
temp = head;
//printf("free: %d\n", head->data);
//这两行不能反 必须先指向下一个再释放当前地址
head = head->next;
free(temp);
}
return NULL;
}
链表的基本操作设计(增删改查)
链表插入节点
同顺序表一样,向链表中增添元素,根据添加位置不同,可分为以下 3 种情况:
- 插入到链表的头部(头节点之后),作为首元节点;
- 插入到链表中间的某个位置;
- 插入到链表的最末端,作为链表中最后一个数据元素;
虽然新元素的插入位置不固定,但是链表插入元素的思想是固定的,只需做以下两步操作,即可将新元素插入到指定的位置:
- 将新结点的 next 指针指向插入位置后的结点;
- 将插入位置前结点的 next 指针指向插入结点;
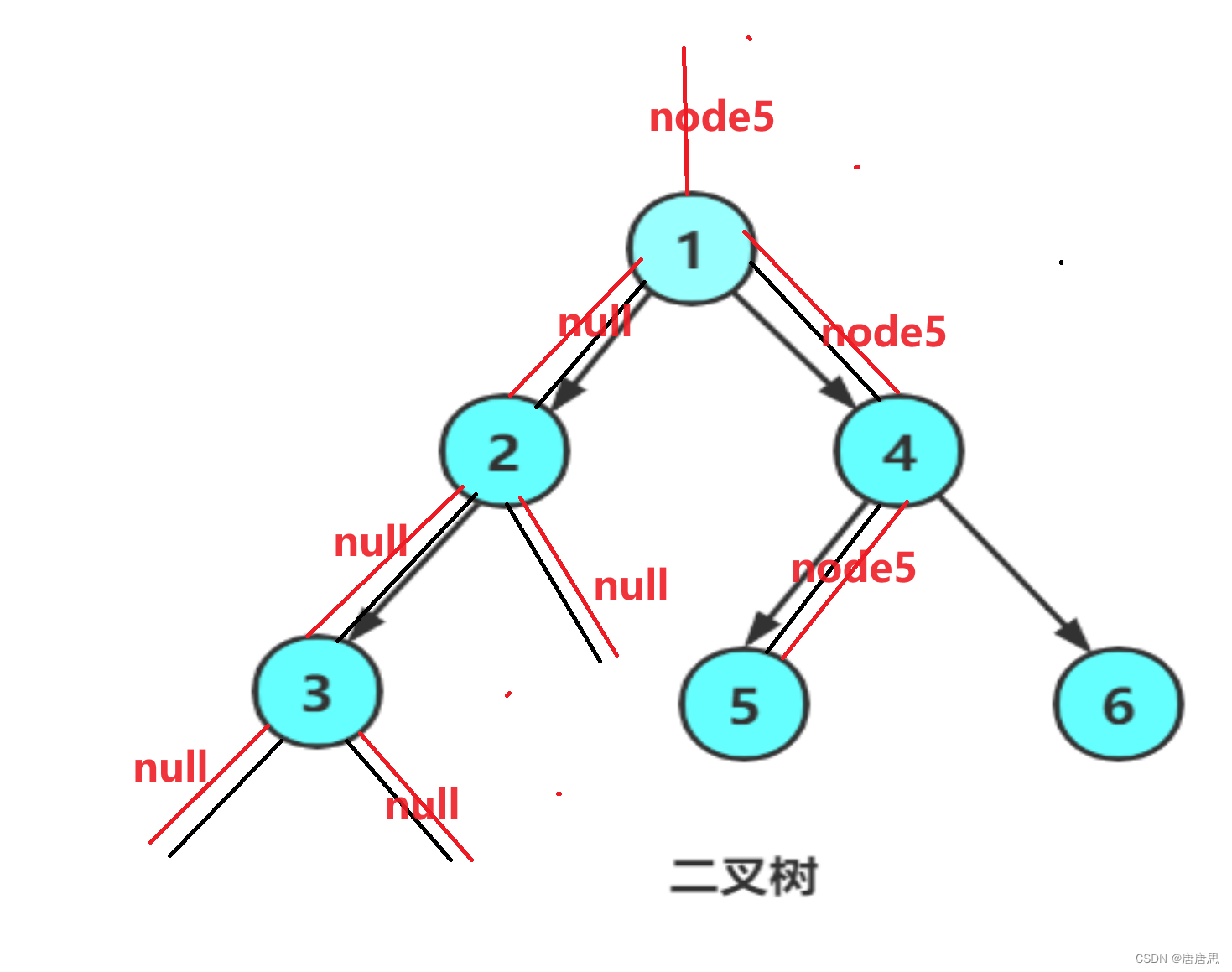
例如,我们在链表{1,2,3,4}的基础上分别实现在头部、中间部位、尾部插入新元素 5,其实现过程如下图 所示:
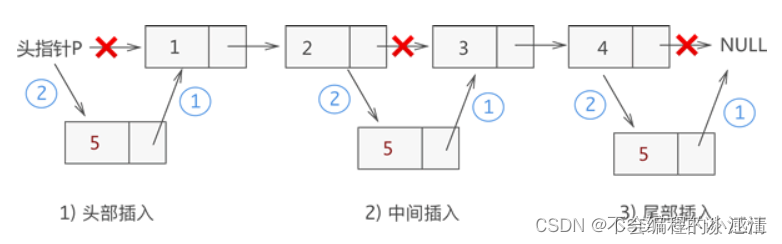
头插法程序设计:
- 功能:链表头插法插入数据
- 参数:para1:链表头 para2:插入的数据
- 返回值:成功返回0; 失败返回-1
/* 功能:链表头插法插入数据 参数:para1: 链表头 para2: 插入的数据 返回值:成功返回0; 失败返回-1 */ int link_push_front(listNode* head, data_t value) { //入口参数检查 if(head == NULL) return -1; //封装节点 listNode* node = (listNode *)malloc(sizeof(listNode)); if(node == NULL){ printf("link_push_front malloc error\n"); return -1; } //头插法 node->data = value; //插入行节点数据 node->next = head->next; //将新节点连接到原来的头 head->next = node; //更新链表头 return 0; }
任意位置插入元素程序设计:
- 功能:在链表特定位置插入一个元素
- 参数: para1:链表头 para2:插入的元素值 para3:特定位置的索引
- 返回值: 失败返回-1 成功返回0
/* 功能:在链表特定位置插入一个元素 参数: para1:链表头 para2:插入的元素值 para3:特定位置的索引 返回值: 失败返回-1 成功返回0 */ int list_insert(listNode* head, data_t value, int index) { //入口参数检查 if(head == NULL || index < 0){ printf("list_insert: para error\n"); return -1; } //封装节点 listNode* node = (listNode *)malloc(sizeof(listNode)); if(node == NULL){ printf("link_push_front malloc error\n"); return -1; } node->data = value; //遍历到目标索引处 int pos = 0; while(pos < index && head->next != NULL) { pos++; head = head->next; } //索引过大 if(head->next == NULL && index - pos > 0){ printf("index invalid\n"); return -1; } //插入数据 node->next = head->next; head->next = node; return 0; }
尾插法程序设计:
- 功能:链表尾插法插入数据
- 参数:para1: 链表头 para2:插入的数据
- 返回值:成功返回0; 失败返回-1
/* 功能:链表尾插法插入数据 参数:para1: 链表头 para2: 插入的数据 返回值:成功返回0; 失败返回-1 */ int link_push_back(listNode* head, data_t value) { //入口参数检查 if(head == NULL) return -1; //封装节点 listNode *node = (listNode *)malloc(sizeof(listNode)); if(node == NULL){ printf("link_push_back malloc error\n"); return -1; } //新节点赋值 node->data = value; node->next = NULL; //遍历链表 while(head->next != NULL) { head = head->next; } //尾插入节点 head->next = node; return 0; }
链表删除节点
从链表中删除指定数据元素时,实则就是将存有该数据元素的节点从链表中摘除,但作为一名合格的程序员,要对存储空间负责,对不再利用的存储空间要及时释放。因此,从链表中删除数据元素需要进行以下 2 步操作:
- 将结点从链表中摘下来;
- 手动释放掉结点,回收被结点占用的存储空间;
其中,从链表上摘除某节点的实现非常简单,只需找到该节点的直接前驱节点 temp,执行一行程序:
temp->next = temp->next->next;

根据数据值删除某个节点
- 功能:根据数据值 删除某个节点
- 参数: para1:链表头 para2:删除数值
- 返回值: 失败返回-1 成功返回0
/* 功能:根据数据值 删除某个节点 参数: para1:链表头 para2:删除数值 返回值: 失败返回-1 成功返回0 */ int list_delete_val(listNode* head, int val) { //入口参数检查 if(head == NULL){ printf("list_insert: para error\n"); return -1; } //遍历链表 while(head->next != NULL && head->next->data != val) { head = head->next; } //链表中无该数据 if(head->next == NULL && head->data != val){ printf("no such value\n"); return -1; } listNode *temp = head->next; //暂存需释放空间的节点 head->next = head->next->next; //跳跃拉链,即删除了中间节点 free(temp); //释放节点 temp = NULL; //避免野指针 return 0; }
根据索引删除某个节点
- 功能:根据索引 删除某个节点 (链表其实没有所谓的索引,即第几个节点-1)
- 参数: para1:链表头 para2:删除的索引
- 返回值: 失败返回-1 返回 0
/* 功能:根据索引 删除某个节点 (链表其实没有所谓的索引,即第几个节点-1) 参数: para1:链表头 para2:删除的索引 返回值: 失败返回-1 成功返回0 */ int link_delete_index(listNode* head, int index) { //入口参数检查 if(head == NULL || index < 0){ printf("link_delete_index: para error\n"); return -1; } //遍历链表 int pos = 0; while(pos < index && head != NULL) { //节点遍历完了 if(head->next == NULL){ printf("index error\n"); return -1; } pos++; //索引 head = head->next; //指针偏移 } //printf("data: %d\n", head->data); //判断后一个元素是否为空 if(head->next == NULL) { printf("index error\n"); return -1; } listNode *temp = head->next; //暂存需释放空间的节点 head->next = head->next->next; //跳跃拉链,即删除了中间节点 free(temp); //释放节点 temp = NULL; //避免野指针 return 0; }
链表查找节点
按数值查找:
查找数据value在单链表link中的节点索引。
算法思想:从单链表的第一个结点开始,依次比较表中各个结点的数据域的值,若某结点数据域的值等于value,则返回该节点的索引;若整个单链表中没有这样的结点,则返回-1。
- 功能:查找某个元素的下标索引
- 参数:para1:链表头 para2:查找的某个元素值
- 返回值: 失败返回-1 成功返回元素的下标索引
/*
功能:查找某个元素的下标索引
参数:para1:链表头 para2:查找的某个元素值
返回值: 失败返回-1 成功返回元素的下标索引
*/
int list_search(listNode* head, data_t val)
{
//入口参数检查
if(head == NULL){
printf("list_insert: para error\n");
return -1;
}
//pos 记录下标位置
int pos = -1;
while(head->next != NULL)
{
pos++;
if(head->next->data == val) //判断是否存在val
return pos;
head = head->next;
}
return -1;
}
增删改查测试程序
//-------------测试程序-------------
void link_test()
{
listNode *head = link_create();
int data1[] = {-3, 2, 9, 5, 101};
int data2[] = {4, 100, 0};
//尾插法插入数据
for( int i = 0; i < 5; i++)
link_push_back(head, data1[i]);
//头插法插入数据
for( int i = 0; i < 3; i++)
link_push_front(head, data2[i]);
//特定位置插入数据
link_insert(head,66,1);
//显示原链表
printf("src link:");
link_show(head);
link_delete_index(head, 2); //删除下标为2的节点
link_delete_val(head, 66); //删除数据为66的节点
printf("delete: ");
link_show(head);
//查找
int ret = link_getVal( head, 2);
int idx = link_search( head, 101);
printf("data[2]: %d\n", ret);
printf("101's index: %d\n", idx);
head = link_free(head);
}
链表的复杂操作程序设计
单链表的反转
算法思路: 依次取原链表中各结点,将其作为新链表首结点插入head结点
即获取原链表的每个节点,在新链表进行头插法插入:
- 判断是否为空 / 是否只有1个节点
- 断开链表,一分为二,分为第一个节点和后面链表
- 遍历从第二个后面起的节点,头插法循环插入
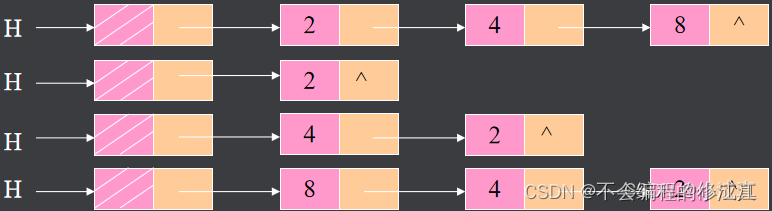
- 功能:单链表的反转
- 参数: para: 链表头
- 返回值: 失败返回-1 成功返回0
int link_reverse(listNode* head)
{
//入口参数检查
if(head == NULL ){
printf("head is NULL.\n");
return -1;
}
//只有一个节点
if(head->next == NULL || head -> next ->next == NULL ){
return 0;
}
//p指向待操作的节点
listNode *p = head->next->next; //新链表头
head->next->next = NULL; //链表一分为二
listNode *q = p;
//遍历后续节点,以尾插法插入新的链表
while(p != NULL)
{
q = p;
p = p->next;
//头插法 插入q
q->next = head->next;
head->next = q;
}
return 0;
}
测试程序:
void link_reverse_test()
{
listNode *head = link_create();
int data1[] = {-3, 2, 9, 5, 3};
for(int i = 0; i < 5; i++)
link_push_back(head, data1[i]);
//打印原链表
printf("link: ");
link_show(head);
//翻转链表
link_reverse(head);
//打印翻转后的链表
printf("reverse: ");
link_show(head);
//释放内存空间
head = link_free(head);
}
相邻节点最大值
算法思路: 设q,p分别为链表中相邻两结点指针,其中p在前,q在后,求q->data + q->data为最大的那一组值,返回其相应的指针q即可:
- 节点个数 <= 2,退出
- 初始化辅助变量(遍历节点指针p,q(p在前,q在后),两数之和sum,新节点指针ret指向head,并以头节点一分为二)
- 遍历p和q,以及sum
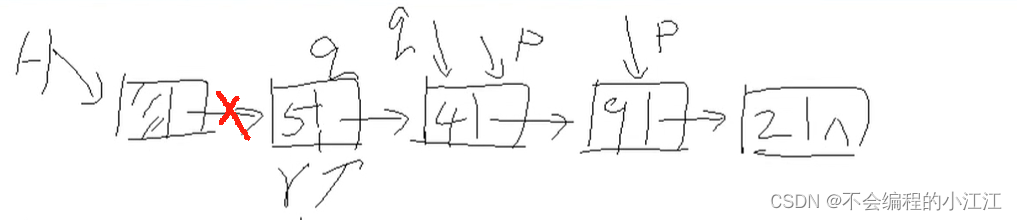
- 功能:求相邻节点最大值,返回最大值第一个节点地址,最大值通过参数传递
- 参数: para1:链表头 para2:最大和的值的地址
- 返回值: 失败返回NULL 成功返回第一个节点指针
//求链表中相邻两节点data值之和为最大的第一节点的指针
/*
功能:求相邻节点最大值,返回最大值第一个节点地址
最大值通过参数传递
参数: para1:链表头 para2:最大和的值的地址
返回值: 失败返回NULL 成功返回第一个节点指针
*/
listNode *list_adjmax(listNode *head, data_t *value)
{
if(head == NULL)
{
printf("head is NULL\n");
return NULL;
}
if(head->next == NULL || head->next->next == NULL || head->next->next->next == NULL)
return head;
//构造辅助变量
listNode *ret = head->next; //结果链表尾指针
listNode *p = head->next->next; //遍历链表的指针, p在前面
listNode *q = head->next; //遍历链表的指针, q在后
data_t max = q->data + p->data ; //初始化两数之和
while(p->next != NULL)
{
//p q更新
p = p->next;
q = q->next;
//比较最大值
if(q->data + p->data > max)
{
max = q->data + p->data; //更新最大值
ret = q; //更新最大值第一个节点
}
}
//返回相邻最大值的第一个节点指针,并通过参数传回最大值
*value = max;
return ret;
}
测试程序:
void list_adjmax_test()
{
listNode *head = link_create();
int data1[] = {-3, 2, 9, 5, 3};
for(int i = 0; i < 5; i++)
link_push_back(head, data1[i]);
//打印原链表
printf("link: ");
link_show(head);
//计算最大两数之和及第一个节点
int sum;
listNode *ret = list_adjmax(head, &sum);
//打印新节点数及其两数最大之和
printf("data: %d\nsum: %d", ret->data, sum);
//释放内存空间
head = link_free(head);
}
有序链表的合并
算法思想: 设指针p、q分别指向表A和B中的结点,若p -> data <= q -> data,则p进入结果表,否则q结点进入结果表。
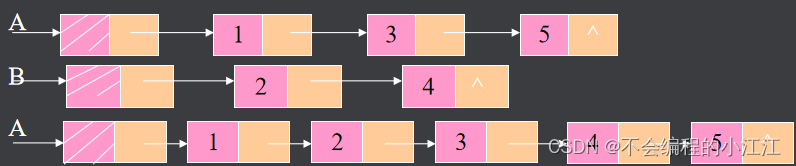
- 参数判断(链表是否为空)
- 分别将链表一分为二,p,q分别指向两个链表的新的头,结果存放在以ret为尾节点的链表中
- 通过p,q指针遍历两个链表,将小的数值插入到ret结果链表中形成新的合并链表
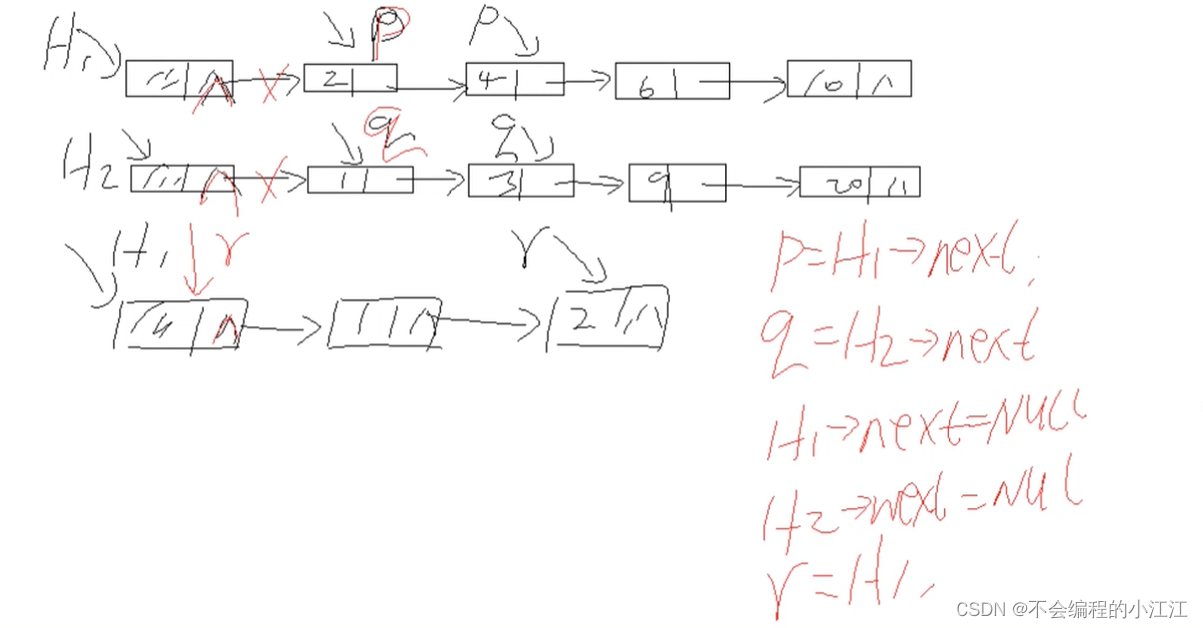
- 功能:合并两个链表,合并至head1
- 参数: para1: 链表1头节点 para2: 链表2头节点
- 返回值: 失败返回 -1 成功返回 0
//合并两个有序链表
/*
功能:合并两个链表,合并至head1
参数: para1:链表1头节点 para2:链表2头节点
返回值: 失败返回-1 成功返回0
*/
int link_merge(listNode *head1, listNode *head2)
{
//入口参数检查
if( head1 == NULL || head2 == NULL){
printf("head1 || head2 error\n");
return -1;
}
//变量初始化
listNode *p = head1->next;
listNode *q = head2->next;
listNode *ret = head1;
head1->next = NULL;
head2->next = NULL;
while(p != NULL && q != NULL)
{
if(p->data <= q->data)
{
ret->next = p; //p接入ret链表
p = p->next; //更新p
ret = ret->next; //更新新表尾
ret->next = NULL; //置空新表尾
}
else
{
ret->next = q; //q接入ret链表
q = q->next; //更新q
ret = ret->next; //更新新表尾
ret->next = NULL; //置空新表尾
}
}
//把多的p或q接入到ret链表
if( p != NULL)
ret->next = p;
if( q != NULL)
ret->next = q;
return 0;
}
测试程序:
void link_merge_test()
{
listNode *head1 = link_create();
listNode *head2 = link_create();
int data1[] = {1, 2, 4, 6, 8};
int data2[] = {2, 5, 6, 22, 96, 128};
//插入数据
for(int i = 0; i < 5; i++)
link_push_back(head1, data1[i]);
for(int i = 0; i < 6; i++)
link_push_back(head2, data2[i]);
//打印原有序链表
printf("link1: ");
link_show(head1);
printf("link2: ");
link_show(head2);
//合并
printf("merge: ");
link_merge(head1, head2);
link_show(head1);
//去重
printf("purge: ");
link_purge(head1);
link_show(head1);
head1 = link_free(head1);
head2 = link_free(head2);
}
链表的排序
- 如果链表为空或只有一个结点,不需要排序
- 先将第一个结点与后面所有的结点依次对比数据域,只要有比第一个结点数据域小的,则交换位置 ,交换之后,拿新的第一个结点的数据域与下一个结点再次对比,如果比他小,再次交换,以此类推
- 第一个结点确定完毕之后,接下来再将第二个结点与后面所有的结点对比,直到最后一个结点也对比完毕为止
int link_sort(listNode *head )
{
//头节点为空
if (head == NULL){
printf("head is NULL\n");
return -1;
}
//只有1个节点
if (head->next == NULL){
printf("only one node\n");
return 0;
}
listNode *q, *p, temp;
p = head->next; //从第一个节点开始
while (p->next != NULL)
{
q = p->next; //q从基准元素的下个元素开始
while (q != NULL)
{
if (p->data > q->data) //后面的元素小
{
//交换值
temp = *q;
*q = *p;
*p = temp;
//交换地址
temp.next = q->next;
q->next = p->next;
p->next = temp.next;
}
q = q->next;
}
p = p->next;
}
return 0;
}