国科大2023模式识别与机器学习实践作业
作业内容
从四类方法中选三类方法,从选定的每类方法中
,各选一种具体的方法,从给定的数据集中选一
个数据集(MNIST,CIFAR-10,电信用户流失数据集 )对这三种方法进行测试比较。
- 第一类方法:: 线性方法:线性SVM、 Logistic Regression
- 第二类方法: 非线性方法:Kernel SVM, 决策树
- 第三类方法: 集成学习:Bagging, Boosting
- 第四类方法: 神经元网络:自选结构
选择数据集
- MNIST
方法
线性SVM
方法介绍
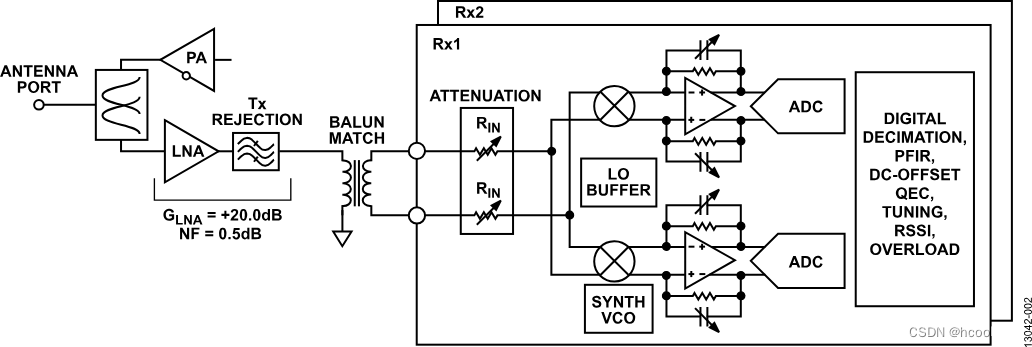
支持向量机(SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,或者求解其对偶问题。

SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如上图所示, w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
实验结果
对于每一个参数设置,做了三次实验,得到的模型准确率分别是ACC_1,ACC_2,ACC_3,平均值是ACC_M。
正则参数是正则项前面的系数。
| 正则参数 | 迭代次数 | ACC_1 | ACC_2 | ACC_3 | ACC_m |
|---|---|---|---|---|---|
| 10 | 1000 | 86.37% | 87.57% | 87.15% | 87.03% |
| 10 | 2000 | 86.9% | 88.45% | 86.4% | 87.25% |
| 50 | 1000 | 87.61% | 86.17% | 87.77% | 87.18% |
| 50 | 2000 | 86.97% | 88.02% | 88.1% | 87.7% |
| 100 | 1000 | 85.67% | 86.99% | 86.58% | 86.41% |
| 100 | 2000 | 86.94% | 86.29% | 86.84% | 86.69% |
结果分析
从结果可以看出,迭代次数一定时,一定范围内,随着正则参数的增大,模型预测的准确率会上升,但是超过一定范围,模型性能会下降,可能是正则参数过大导致模型欠拟合了。
当正则参数一定时,随着迭代次数的增大,模型的性能会逐渐变好。
决策树
方法介绍
决策树是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。具体来说,它是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
构建决策树的基本步骤为:
- 开始将所有记录看作一个节点
- 遍历每个变量的每一种分割方式,找到最好的分割点
- 分割成两个节点N1和N2
- 对N1和N2分别继续执行2-3步,直到每个节点不能再分。
实验结果
对于每一个参数设置,做了三次实验,得到的模型准确率分别是ACC_1,ACC_2,ACC_3,平均值是ACC_M。
| 分割类型 | 损失函数 | ACC_1 | ACC_2 | ACC_3 | ACC_M |
|---|---|---|---|---|---|
| best | gini | 87.61% | 87.87% | 88.03% | 87.84% |
| best | entropy | 88.54% | 88.40% | 88.38% | 88.44% |
| best | log_loss | 88.62% | 88.34% | 88.42% | 88.46% |
| random | gini | 86.61% | 87.09% | 87.01% | 86.90% |
| random | entropy | 87.55% | 87.82% | 88.20% | 87.86% |
| random | log_loss | 87.87% | 87.79% | 88.09% | 87.92% |
结果分析
从结果可以看出,当对节点分割时,选取最好的进行分割比随机分割的性能要好,因为可以获得的信息增益最好,而随机选取没有保障。
使用entropy和log_loss的性能比gini要好,而gini代表基尼系数,entropy代表信息增益,因此选择跟信息增益有关的损失更能提高决策树的性能。
神经元网络,使用简单的卷积神经网络
方法介绍
卷积神经网络(CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积网络是指那些至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
卷积神经网络的基本结构由以下几个部分组成:输入层(input layer),卷积层(convolution layer),池化层(pooling layer),激活函数层和全连接层(full-connection layer)。
- 卷积层:对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作
- 池化层:池化操作将输入矩阵某一位置相邻区域的总体统计特征作为该位置的输出,主要有平均池化(Average Pooling)、最大池化(Max Pooling)等。简单来说池化就是在该区域上指定一个值来代表整个区域。
- 激活函数:激活函数(非线性激活函数,如果激活函数使用线性函数的话,那么它的输出还是一个线性函数。)但使用非线性激活函数可以得到非线性的输出值。
- 全连接层:在全连接层中,每个神经元都与前一层中的所有神经元相连,因此它的输入是一个向量,输出也是一个向量。它对提取的特征进行非线性组合以得到输出。全连接层本身不具有特征提取能力,而是使得目标特征图失去空间拓扑结构,被展开为向量。
实验结果
迭代次数为epoch=10,使用带动量的随机梯度下降(SGD)进行优化,损失函数是交叉熵损失。
使用的卷积神经网络含有两层(含有卷积层,池化层,ReLU激活函数和批归一化层)和一个全连接层,输出的特征维度为10,因为MINIST只有10类。
| 批处理大小 | 学习率 | ACC |
|---|---|---|
| 64 | 0.1 | 99.03% |
| 64 | 0.01 | 98.95% |
| 64 | 0.001 | 98.09% |
| 128 | 0.1 | 99.16% |
| 128 | 0.01 | 98.95% |
| 128 | 0.001 | 97.35% |
| 128 | 0.02 | 99.02% |
| 128 | 0.002 | 98.12% |
结果分析
从结果可以看出,当批处理大小相同时,学习率为0.1时性能最好,之后随着学习率的减小模型的性能逐渐降低。
当学习率一致时,大多数情况下,批处理大小增加模型的性能也会更好,但有些情况不是,如学习率等于0.001时,此时需要将学习率扩大2倍(跟批处理大小增加的倍数一致),模型的性能才会比之前更好。
代码
线性SVM和决策树
# -*- encoding: utf-8 -*-
"""
File machine_learning_methods.py
Created on 2024/1/20 18:55
Copyright (c) 2024/1/20
@author:
"""
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from load_minist import load_minist_data
if __name__ == '__main__':
minist_path = "./datasets/mnist-original.mat"
method_type = "linear_svm"
X_data, Y_data = load_minist_data(minist_path)
# 数据规范化
scaler = StandardScaler()
X = scaler.fit_transform(X_data)
# 分割得到训练和测试数据集
X_train, X_test, Y_train, Y_test = train_test_split(X_data, Y_data, test_size=10000, random_state=42)
print(f"Train data size:{X_train.shape}")
print(f"Test data size:{X_test.shape}")
if method_type == "linear_svm":
print("Start training Linear SVM...")
# 构建linear svm C表示正则项的权重
l_svm = svm.LinearSVC(C = 10, max_iter=2000)
l_svm.fit(X_train, Y_train)
print("Training over!")
print("The function is:")
print(f"w:{l_svm.coef_}")
print(f"b:{l_svm.intercept_}")
print("Start testing...")
# 打印模型的精确度
print(f"{l_svm.score(X_test, Y_test) * 100}%")
elif method_type == "kernel_svm":
print("Start training Kernel SVM...")
# 构建linear svm C表示正则项的权重
k_svm = svm.SVC(C=100, max_iter=1000)
k_svm.fit(X_train, Y_train)
print("Training over!")
print("Start testing...")
# 打印模型的精确度
print(f"{k_svm.score(X_test, Y_test) * 100}%")
elif method_type == "decision_tree":
print("Start training Decision Tree...")
# 构建决策树
d_tree = DecisionTreeClassifier(criterion = "gini", splitter = "best")
d_tree.fit(X_train, Y_train)
print("Training over!")
print("Start testing...")
# 打印模型的精确度
print(f"{d_tree.score(X_test, Y_test) * 100}%")
卷积神经网络
# -*- encoding: utf-8 -*-
"""
File neural_net.py
Created on 2024/1/20 18:55
Copyright (c) 2024/1/20
@author:
"""
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 设计模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(True),
nn.BatchNorm2d(10),
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(True),
nn.BatchNorm2d(20),
)
# 输出10个类别
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=320, out_features=10)
)
def forward(self, x):
# x: B C=10 H=12 W=12
x = self.block1(x)
x = self.block2(x)
x = self.fc(x)
return x
def construct_data_loader(batch_size):
# 数据的归一化
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# 训练集
train_dataset = datasets.MNIST(root='./datasets', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 测试集
test_dataset = datasets.MNIST(root='./datasets', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
def train_model(train_loader):
for (images, target) in train_loader:
# images shape: B C=1 H W
outputs = model(images)
loss = criterion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def test_model(test_loader):
correct, total = 0, 0
with torch.no_grad():
for (images, target) in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('[%d / %d]: %.2f %% ' % (i + 1, epoch, 100 * correct / total))
if __name__ == '__main__':
# 定义超参数
# 批处理大小
batch_size = 128
# 学习率
lr = 0.002
# 动量
momentum = 0.5
# 训练的epoch数
epoch = 10
# 构建模型
model = Net()
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
train_loader, test_loader = construct_data_loader(batch_size)
for i in range(epoch):
# 训练
train_model(train_loader)
# 测试
test_model(test_loader)
参考资料
基于决策树模型和支持向量机模型的手写数字识别_手写数字识别决策树-CSDN博客
ResNet18实现——MNIST手写数字识别(突破0.995)_mnist resnet-CSDN博客