单机可以搭建伪分布式hadoop环境,用来测试和开发使用,hadoop包括:
hdfs服务器
yarn服务器,yarn的前提是hdfs服务器,
在前面两个的基础上,课可以搭建hive服务器,不过hive不属于hadoop的必须部分。
过程不要想的太复杂,其实挺简单,这里用最糙最快最直接的方法,在我的单节点虚拟机上,搭建一个hdfs+yarn+hive:
首先,要配置好Java的JAVA_HOME和PATH(etc/hadoop/hadoop-env.sh里的JAVA_HOME要改为本机的JAVA_HOME),还是有ssh本机的免密码登录。
然后,下载hadoop安装包,这个包就包括了hdfs服务器和yarn服务器的执行文件和配置脚本。解压后,先配置 hdfs 服务器端,主要是两个配置文件:core-site.xml 和 hdfs-site.xml 这个site我估计就是服务器端配置的意思。我是用root用户配置和执行的:

etc/hadoop/core-site.xml (这里9000是hfds服务器,监听端口号,这里要用自己的IP地址,如果用127.0.0.1,远程集群连不进来)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.32.155.57:9000</value>
</property>
</configuration>etc/hadoop/hdfs-site.xml (dfs.namenode.name.dir 和 dfs.namenode.data.dir)是服务器上存储元数据和数据的目录。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/disk01/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/disk01/hadoop/dfs/data</value>
</property>
</configuration>
对上面配置的目录进行初始化/格式化:
$ bin/hdfs namenode -format执行sbin里的start-dfs.sh就可以启动hdfs文件系统服务器了,可以jps查看一下有哪些java进程:
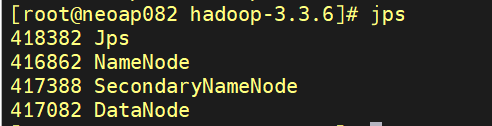
如果在本地(服务器上),执行
hdfs dfs -ls /就可以查看hdfs上的文件了,还可以用其它命令操作hdfs:
hdfs dfs -mkdir /user/root
hdfs dfs -mkdir input上面只是配置了hdfs服务器,要想跑hive或mapreduce,还需要配置和启动调度器:yarn
etcd/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etcd/hadoop/yarn-site.xml (这里 yarn.resourcemanager.hostname 要写自己的IP,yarn.nodemanager.env-whitelist 设置Container的能继承NodeManager的哪些环境变量)
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.32.155.57</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
MapReducer执行时,会在NodeManager上创建Container,在Container上执行Task(JAVA程序),该程序需要环境变量(如:JDK、HADOOP_MAPRED_HOME…),该参数就是 设置Container的能继承NodeManager的哪些环境变量。
-- 引自
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}-CSDN博客
启动yarn
start-yarn.sh
[root@neoap082 hadoop-3.3.6]# jps
430131 Jps
422691 ResourceManager
416862 NameNode
417388 SecondaryNameNode
422874 NodeManager
417082 DataNode
执行 mapreduce 任务(java程序)
$ bin/hdfs dfs -mkdir -p /user/root
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+'
$ bin/hdfs dfs -cat output/*安装hive:
hive的元数据一般使用mysql存储,也可以使用hive自带的数据库derby,如果使用derby,那么hive的安装、配置、启动非常简单:
先要单独下载hive:

不需要修改任何hive的配置文件,就是最简情况下,只要配置好hdfs和yarn,不需要配置hive。
但是,第一次使用以前,需要初始化 hive:
hdfs dfs -mkdir -p /user/hive/warehouse bin/schematool -dbType derby -initSchema
然后直接执行 bin目录下的hive,这样就进入了hive命令行,也启动了hive服务器,这种只能用来学习测试,不过也足够了。
CREATE TABLE basic_data_textfile
(
k00 INT,
k01 DATE,
k02 BOOLEAN,
k03 TINYINT,
k04 SMALLINT,
k05 INT ,
k06 BIGINT ,
k07 BIGINT,
k08 FLOAT ,
k09 DOUBLE ,
k10 DECIMAL(9,1) ,
k11 DECIMAL(9,1) ,
k12 TIMESTAMP,
k13 DATE ,
k14 TIMESTAMP,
k15 CHAR(2),
k16 STRING,
k17 STRING ,
k18 STRING
)
row format delimited fields terminated by '\|' ;# 从本地文件加载
load data local inpath '/opt/doris_2.0/basic_data.csv' into table basic_data;
# 从hdfs路径加载
load data inpath '/user/root/basic_data.csv' into table basic_data_lzo;
hive表数据是一个hdfs目录下的文件,可以设置这些文件存储时的格式和压缩算法,例如,下面的basic_data_lzop表一lzo压缩,压缩文件格式为lzop:
set hive.exec.compress.output=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec;
set io.compression.codecs=com.hadoop.compression.lzo.LzopCodec;CREATE TABLE basic_data_lzop
(
k00 INT,
k01 DATE,
k02 BOOLEAN,
k03 TINYINT,
k04 SMALLINT,
k05 INT ,
k06 BIGINT ,
k07 BIGINT,
k08 FLOAT ,
k09 DOUBLE ,
k10 DECIMAL(9,1) ,
k11 DECIMAL(9,1) ,
k12 TIMESTAMP,
k13 DATE ,
k14 TIMESTAMP,
k15 CHAR(2),
k16 STRING,
k17 STRING ,
k18 STRING
)
row format delimited fields terminated by '\|' ;insert into basic_data_lzop select * from basic_data;
basic_data_orc_snappy 表以orc格式存储,数据块以snappy压缩:
CREATE TABLE basic_data_orc_snappy
(
k00 INT,
k01 DATE,
k02 BOOLEAN,
k03 TINYINT,
k04 SMALLINT,
k05 INT ,
k06 BIGINT ,
k07 BIGINT,
k08 FLOAT ,
k09 DOUBLE ,
k10 DECIMAL(9,1) ,
k11 DECIMAL(9,1) ,
k12 TIMESTAMP,
k13 DATE ,
k14 TIMESTAMP,
k15 CHAR(2),
k16 STRING,
k17 STRING ,
k18 STRING
)
row format delimited fields terminated by '\|'
stored as orc tblproperties ("orc.compress"="SNAPPY");insert into basic_data_orc_snappy select * from basic_data_textfile;