简介
书生·浦语2.0是一个大语言模型,是商汤科技与上海 AI 实验室联合香港中文大学和复旦大学发布的新一代大语言模型。‘
具体特性
- 有效支持20万字超长上下文:模型在 20 万字长输入中几乎完美地实现长文“大海捞针”,而且在 LongBench 和 L-Eval 等长文任务中的表现也达到开源模型中的领先水平。 可以通过 LMDeploy 尝试20万字超长上下文推理。
- 综合性能全面提升:各能力维度相比上一代模型全面进步,在推理、数学、代码、对话体验、指令遵循和创意写作等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上 InternLM2-Chat-20B 能比肩甚至超越 ChatGPT (GPT-3.5)。
- 代码解释器与数据分析:在配合代码解释器(code-interpreter)的条件下,InternLM2-Chat-20B 在 GSM8K 和 MATH 上可以达到和 GPT-4 相仿的水平。基于在数理和工具方面强大的基础能力,InternLM2-Chat 提供了实用的数据分析能力。
- 工具调用能力整体升级:基于更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,新版模型可以更可靠地支持复杂智能体的搭建,支持对工具进行有效的多轮调用,完成较复杂的任务。
1月23日官方更新发布了InternLM2-Math-7B 和 InternLM2-Math-20B 以及相关的对话模型。在此次发布中,InternLM2 包含两种模型规格:7B 和 20B。7B 为轻量级的研究和应用提供了一个轻便但性能不俗的模型,20B 模型的综合性能更为强劲,可以有效支持更加复杂的实用场景。每个规格不同模型关系如下图所示: 项目实操
项目实操
依赖环境:
·Python >= 3.8·PyTorch >= 1.12.0 (推荐 2.0.0 和更高版本)·Transformers >= 4.34
通过 Transformers 加载:
通过以下的代码从 Transformers 加载 InternLM2-7B-Chat 模型 (可修改模型名称替换不同的模型)import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("internlm/internlm2-chat-7b", trust_remote_code=True)# 设置`torch_dtype=torch.float16`来将模型精度指定为torch.float16,否则可能会因为您的硬件原因造成显存不足的问题。model = AutoModelForCausalLM.from_pretrained("internlm/internlm2-chat-7b", device_map="auto",trust_remote_code=True, torch_dtype=torch.float16)# (可选) 如果在低资源设备上,可以通过bitsandbytes加载4-bit或8-bit量化的模型,进一步节省GPU显存.# 4-bit 量化的 InternLM 7B 大约会消耗 8GB 显存.# pip install -U bitsandbytes# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)model = model.eval()response, history = model.chat(tokenizer, "你好", history=[])print(response)# 模型输出:你好!有什么我可以帮助你的吗?response, history = model.chat(tokenizer, "请提供三个管理时间的建议。", history=history)print(response)
通过前端网页对话:
pip install streamlitpip install transformers>=4.34streamlit run ./chat/web_demo.py
界面展示:
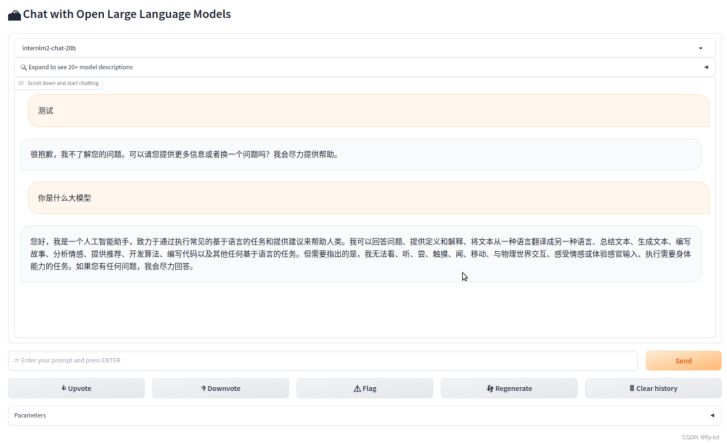
微调:
官方推荐使用XTuner微调.XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)
详情可参考官方文档:https://github.com/InternLM/InternLM/blob/main/finetune/README_zh-CN.md
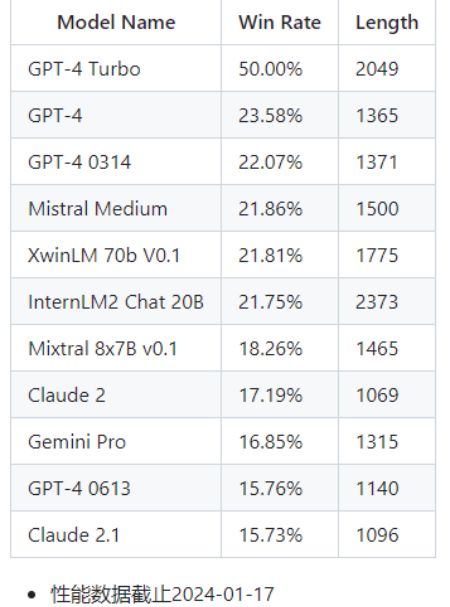
性能评分:
InternLM2-Chat在AlpacaEval 2.0 上的性能,结果表明InternLM2-Chat在AlpacaEval上已经超过了 Claude 2, GPT-4(0613) 和 Gemini Pro.