目录
RDD
RDD五大特性
RDD创建
RDD算子
常见的Transformation算子
map
flatMap
mapValues
reduceByKey
groupBy
filter
distinct
union
join
intersection
glom
groupByKey
groupByKey和reduceByKey的区别 ?
sortBy
sortByKey
常见的action算子
countByKey
collect
reduce
fold
first、take、top、count
takeSample
takeOrdered
foreach
saveAsTextFile
分区操作算子
mapPartitions
foreachPartition
partitionBy
repartition、coalesce
RDD
RDD定义 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
RDD五大特性
1、 RDD是有分区的
RDD分区是RDD存储数据的最小单位,一份RDD数据实际上是被分成了很多分区
RDD是逻辑的抽象概念,而分区是真实存在的物理概念
代码演示:
print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3).glom().collect())
print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 6).glom().collect())
# [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# [[1], [2, 3], [4], [5, 6], [7], [8, 9]]2、RDD方法会作用在所有分区之上
例如map算子会作用在所有的分区上面
print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 6).map(lambda x:x*10).glom().collect())
# [[10], [20, 30], [40], [50, 60], [70], [80, 90]]3、RDD之间有依赖关系
以下面的例子为例,rdd是相互依赖的,例如rdd2依赖于rdd1,会行成一个依赖链条
rdd1 -> rdd2 -> rdd3 -> rdd4 -> rdd5
rdd1 = sc.textFile("hdfs://node1:8020/test.txt")
rdd2 = rdd1.flatMap(lambda line: line.split(" "))
rdd3 = rdd2.map(lambda x: (x,1))
rdd4 = rdd3.reduceByKey(lambda a,b:a+b)
rdd5 = rdd4.collect()4、Key-Value型的RDD可以有分区器
5、RDD的分区规划会尽量靠近数据所在的服务器
在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到 存储数据所在的服务器上因为这样可以走本地读取,避免网络读取
本地读取: Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可 无需走网络传输网络读取:读取数据需要经过网络的传输才能读取到
本地读取性能>>>网络读取的
总结,Spark会在确保并行计算能力的前提下,尽量确保本地读取,这里是尽量确保而不是100%确保
RDD创建
有两种创建方式:
• 通过并行化集合创建( 本地对象转分布式RDD )
rdd = sc.parallelize(参数1,参数2)
参数1:可迭代对象,例如list
参数2:分区数量,int ,这个参数可以不设置,会根据CPU设置分区数量,可以通过下面这个语句查看此RDD的分区数量
print(rdd.getNumPartitions())
• 读取外部数据源( 读取文件)
sparkcontext.textFile(参数1,参数2)#参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如S3协议
#参数2,可选,表示最小分区数量
# 注意: 参数2 话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,:参数2失效
wholeTextFile是另外一种读取文件的APl,适合读取一堆小文件
sparkcontext.wholeTextFies(参数1,参数2)# 参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如如S3协议
# 参数2,可选,表示最小分区数量
注意: 参数2 话语权不足,这个API 分区数量最多也只能开到文件数量#
这个API偏向于少量分区读取数据,因为,这个API表明了自己是小文件读取专用,那么文件的数据很小分区很多,导致shuffle的几率更高 所以尽量少分区读取数据
RDD算子
RDD的算子分成2类:Transformation:转换算子、Action:动作(行动)算子
Transformation算子
定义:RDD的算子返回值仍旧是一个RDD的称之为转换算子特性:
这类算子是lazy 懒加载的.如果没有action算子,Transformation算子是不工作的
Action算子
定义:返回值 不是rdd 的就是action算子
对于这两类算子来说Transformation算子,相当于在构建执行计划,action是一个指令让这个执行计划开始工作
说白了,如果没有action算子,则Transformation算子不执行
常见的Transformation算子
map
对每个元素进行一个映射转换,生成新的rdd
可以使用匿名函数或函数名参数的方式调用
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]).map(lambda x:x+10)
print(rdd.collect())
# [11, 12, 13, 14, 15, 16, 17, 18, 19]
def change(data):
return (data+10)*3
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]).map(change)
print(rdd.collect())
# [33, 36, 39, 42, 45, 48, 51, 54, 57]flatMap
transformation类算子,map之后将新的rdd中的元素解除嵌套
rdd = sc.parallelize(['one two three','a b c','1 2 3']).map(lambda x:x.split(' '))
print(rdd.collect())
rdd2 = sc.parallelize(['one two three','a b c','1 2 3']).flatMap(lambda x:x.split(' '))
print(rdd2.collect())
# [['one', 'two', 'three'], ['a', 'b', 'c'], ['1', '2', '3']]
# ['one', 'two', 'three', 'a', 'b', 'c', '1', '2', '3']mapValues
针对二元元祖的value进行map操作:
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])
rdd2 = rdd.mapValues(lambda x:x+10)
print(rdd2.collect())
# [('a', 11), ('b', 12), ('c', 13), ('b', 12), ('b', 12), ('a', 11)]reduceByKey
功能: 针对KV型 RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value) 的聚合操作。
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])
rdd2 = rdd.reduceByKey(lambda a,b :a+b)
print(rdd2.collect())
# [('a', 2), ('b', 6), ('c', 3)]内部逻辑是累加方式实现的,首先其先按照key进行分组,即分成了a , b, c三组,以b组为例,有三个(b,2),则采用累加,先两个相加得到4,再4+2得到6
同理,使用别的逻辑也是累次的形式,也可以使用函数:
def change(a,b):
return (a+b)*3
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])
rdd2 = rdd.reduceByKey(change)
print(rdd2.collect())
# [('a', 6), ('b', 42), ('c', 3)]groupBy
将rdd数据按照提供的依据分组
例如,对元祖的第一个元素进行分组
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])
rdd2 = rdd.groupBy(lambda x:x[0])
print(rdd2.collect())
# [('a', < pyspark.resultiterable.ResultIterable object at 0x7fb2f21219d0 >),
# ('b', < pyspark.resultiterable.ResultIterable object at 0x7fb2f2121be0 >),
# ('c', < pyspark.resultiterable.ResultIterable object at 0x7fb2f2121ca0 >)]可以看到按照第一个元素分成了a,b,c三组,但是其value值变成了一个对象
可以强制转换出value:
print(rdd2.map(lambda x: (x[0], list(x[1]))).collect())
# [('a', [('a', 1), ('a', 1)]), ('b', [('b', 2), ('b', 2), ('b', 2)]), ('c', [('c', 3)])]filter
将数据进行过滤,传入一个函数,其返回值必须为 true 或 false
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
rdd2 = rdd.filter(lambda x:x<6)
print(rdd2.collect())
# [1, 2, 3, 4, 5]distinct
去除
rdd = sc.parallelize([1,1,2,4,5,1,3,8,2])
rdd2 = rdd.distinct()
print(rdd2.collect())
# [1, 2, 4, 5, 3, 8]union
RDD数据合并,但是不去重
rdd = sc.parallelize([1,2,3,3,8,2])
rdd2 = sc.parallelize(['a','v','b'])
rdd3 = rdd.union(rdd2)
print(rdd3.collect())
# [1, 2, 3, 3, 8, 2, 'a', 'v', 'b']join
rdd数据关联,这跟sql语句中的join的原理一样
rdd = sc.parallelize([(1,'a'),(2,'b'),(3,'c'),(4,'d')])
rdd2 = sc.parallelize([(1,100),(2,300)])
rdd3 = rdd.join(rdd2)
print(rdd3.collect())
rdd4 = rdd.leftOuterJoin(rdd2)
print(rdd4.collect())
# [(2, ('b', 300)), (1, ('a', 100))]
# [(2, ('b', 300)), (4, ('d', None)), (1, ('a', 100)), (3, ('c', None))]intersection
取数据的交集
rdd = sc.parallelize([(1,'a'),(2,'b'),(3,'c'),(4,'d')])
rdd2 = sc.parallelize([(1,'a'),(2,'b')])
rdd3 = rdd.intersection(rdd2)
print(rdd3.collect())
# [(1, 'a'), (2, 'b')]glom
将RDD数据按照 分区 进行嵌套
rdd = sc.parallelize([1,2,3,4,5,6,7,8],3)
rdd2 = rdd.glom()
print(rdd2.collect())
# [[1, 2], [3, 4], [5, 6, 7, 8]]groupByKey
对于KV型数据自动对KEY进行分组
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3), ('b', 2), ('b', 2), ('a', 1)])
rdd2 = rdd.groupByKey()
print(rdd2.collect())
# [('a', < pyspark.resultiterable.ResultIterable object at 0x7f27564fc7c0 >),
# ('b', < pyspark.resultiterable.ResultIterable object at 0x7f27564fc9d0 >),
# ('c', < pyspark.resultiterable.ResultIterable object at 0x7f27564fca90 >)]
rdd3 = rdd2.map(lambda x:(x[0],list(x[1])))
print(rdd3.collect())
# [('a', [1, 1]), ('b', [2, 2, 2]), ('c', [3])]groupByKey和reduceByKey的区别 ?
在功能上的区别:
groupByKey仅仅有分组功能而已
reduceByKey除了有ByKey的分组功能外,还有reduce聚合功能.所以是一个分组+聚合一体化的算子.
当面临一个 分组加聚合 的操作时,有两种选择,一是使用 groupByKey后在使用别的算子计算,二是直接使用reduceByKey,其性能上有很大差别。
第一种方法是先分组,然后再计算,那么每个数据都要单独的进行io传输计算,例如下面这个例子,a数据需要传6次到下面,再计算(a,6)
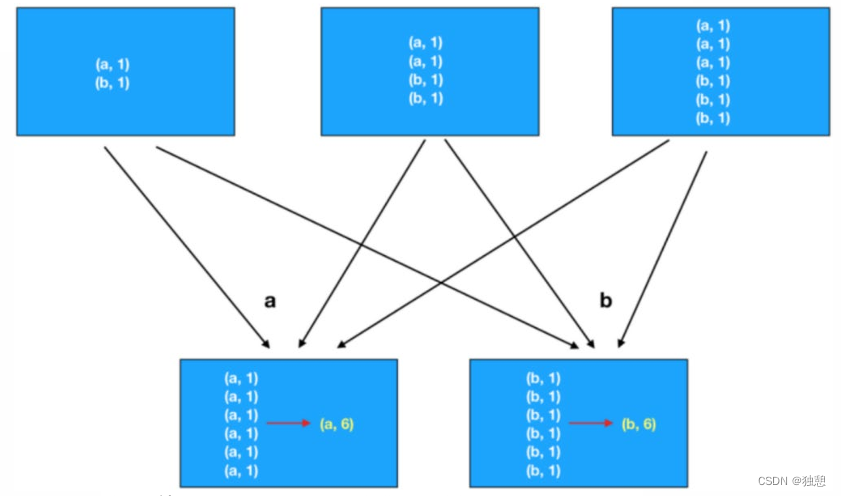
而第二种方式先在分区内做预聚合,然后再走分组流程(shuffle),分组后再做最终聚合,大大提升了性能
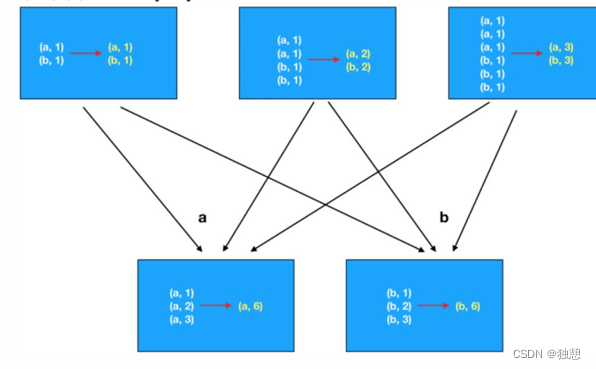
sortBy
按照规定的值排序,第一个参数为排序的根据,第二个值表示升序或降序,第三个值表示排序分区值
如果想要全局排序,最好将第三个值设定为1,否则可能会出现分区内排序,但是组合在一起乱序的可能
rdd = sc.parallelize([('a', 1), ('b',5), ('c', 7), ('b', 2), ('b',9), ('a', 1)])
rdd2 = rdd.sortBy(lambda x:x[1],ascending=True,numPartitions=1)
print(rdd2.collect())
# [('a', 1), ('a', 1), ('b', 2), ('b', 5), ('c', 7), ('b', 9)]sortByKey
针对二元元祖排序,根据为key
有三个参数,前面两个跟上面一样,keyfunc表示对key的处理函数
rdd = sc.parallelize([('a', 1), ('b',5), ('A', 7), ('C', 2), ('b',9), ('a', 1)])
rdd2 = rdd.sortByKey(ascending=True,numPartitions=1, keyfunc=lambda key:str(key).lower())
print(rdd2.collect())
# [('a', 1), ('A', 7), ('a', 1), ('b', 5), ('b', 9), ('C', 2)]常见的action算子
action算子的返回值不是rdd
countByKey
按照key进行计数
rdd = sc.parallelize([('a',1),('a',1),('a',1),('b',1)])
result = rdd.countByKey()
print(result)
print(type(result))
# defaultdict( <class 'int'>, {'a': 3, 'b': 1})
# <class 'collections.defaultdict'>collect
这个算子是将RDD各个分区数据都拉取到Driver
注意的是,RDD是分布式对象,其数据量可以很大,所以用这个算子之前要心知肚明的了解结果数据集不会太大,不然会把Driver内存撑爆
reduce
类似于reduceByKey的逻辑操作,也是以累次的方式实现
rdd = sc.parallelize([1,2,3,4,5,6,7,9])
result = rdd.reduce(lambda a,b :a+b)
print(result)
# 37fold
和reduce一样也是累次的逻辑实现,区别是这个方法带有初始值,且在分区的情况下会多次作用
以下面这个例子为例,分成三个组
那么组内的计算为:1+2+3+10 = 16,4+5+6+10=25,7+9+10+10=36
组件的计算为:16+25+36+10 = 87
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10],3)
print(rdd.glom().collect())
result = rdd.fold(10,lambda a,b :a+b)
print(result)
# [[1, 2, 3], [4, 5, 6], [7, 9, 10]]
# 87first、take、top、count
first:取出rdd的第一个元素
take:取出rdd的前n个元素
top:将rdd降序排列然后取出前n个元素
count:计算rdd有多少个元素
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])
print(rdd.first())
print(rdd.take(5))
print(rdd.top(4))
print(rdd.count())
# 1
# [1, 2, 3, 4, 5]
# [10, 9, 7, 6]
# 9takeSample
takeSample(参数1:True or False,参数2:采样数,参数3:随机数种子)
-参数1:True表示运行取同一个数据,False表示不允许取同一个数据.和数据内容无关,是否重复表示的是同一个位置的数-参数2:抽样数量
-参数3︰随机数种子
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])
print(rdd.takeSample(True, 13))
print(rdd.takeSample(False, 13))
# [7, 2, 7, 4, 6, 4, 1, 6, 6, 7, 7, 7, 3]
# [9, 1, 10, 4, 7, 5, 3, 2, 6]takeOrdered
rdd.take0rdered(参数1,参数2)
-参数1要几个数据
-参数2对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法使用按照元素自然顺序升序排序,如果想玩倒叙,需要用参数2来对排序的数据进行处理
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])
print(rdd.takeOrdered(3))
print(rdd.takeOrdered(3, lambda x:-x))
# [1, 2, 3]
# [10, 9, 7]foreach
跟map类似,对每一个元素做处理,但是没有返回值
值得注意的是,大部分算子都需要将结果返回到driver再输出,而foreach则是直接由executor输出的
rdd = sc.parallelize([1,2,3,4,5])
rdd.foreach(lambda x:print(x+10))
# 11
# 12
# 13
# 14
# 15saveAsTextFile
保存文件为text,n个分区就会生成n个文件
这个也是executor直接生成文件
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd.saveAsTextFile('data/output/out1')分区操作算子
mapPartitions
功能和map一样,但是map是对每一个元素都进行计算和IO,但是mapPartitions是对一个分区计算完之后再整体IO
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
def process(iter):
result = []
for i in iter:
result.append(i+10)
return result
print(rdd.mapPartitions(process).collect())
# [11, 12, 13, 14, 15, 16, 17, 18, 19]foreachPartition
跟foreach类似,区别是整体处理
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
def process(iter):
result = []
for i in iter:
result.append(i+10)
print(result)
rdd.foreachPartition(process)
# [11, 12, 13]
# [14, 15, 16]
# [17, 18, 19]partitionBy
默认的分区方式是根据HASH算子决定的,而这个算子能对分区进行人为规定
例如下面这个例子,我希望key为a的分一组,其他分一组
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)])
def process(k):
if k=='a':
return 0
else:
return 1
print(rdd.partitionBy(2, process).glom().collect())
# [[('a', 1), ('a', 3), ('a', 6)], [('b', 1), ('b', 2), ('c', 1)]]repartition、coalesce
repartition对RDD数据重新分区,仅仅针对分区数量
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)
print(rdd.glom().collect())
print(rdd.repartition(2).glom().collect())
# [[('a', 1), ('a', 3)], [('a', 6), ('b', 1)], [('b', 2), ('c', 1)]]
# [[('b', 2), ('c', 1)], [('a', 1), ('a', 3), ('a', 6), ('b', 1)]]注意:对分区的数量进行操作,一定要慎重
一般情况下,我们写Spark代码除了要求全局排序设置为1个分区外多数时候,所有API中关于分区相关的代码我们都不太理会.
因为,如果你改分区了会影响并行计算(内存迭代的并行管道数量),分区如果增加,极大可能导致shuffle
初次之外,coalesce也可以完成这个功能,但是其多了一个安全机制,如果要增加分区,则必须设置 shuffle= True
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)
print(rdd.coalesce(2).getNumPartitions())
print(rdd.coalesce(4).getNumPartitions())
print(rdd.coalesce(4,shuffle=True).getNumPartitions())
# 2
# 3
# 4