目录
1 使用docker安装ELK
1.1 安装Elasticsearch
1.2 安装Kibana
1.3 安装Logstash
2 数据同步
2.1 准备MySQL表和数据
2.2 运行Logstash
2.3 测试
3 Logstash报错(踩坑)记录
3.1 记录一
3.1.1 报错信息
3.1.2 报错原因
3.1.3 解决方案
3.2 记录二
3.2.1 报错信息
3.2.2 报错原因
3.3.3 解决方案
1 使用docker安装ELK
ELK是指Elasticsearch、Logstash、Kibana。
1.1 安装Elasticsearch
# 拉取es镜像
docker pull elasticsearch:7.4.2
mkdir -p /root/docker/elasticsearch/config
mkdir -p /root/docker/elasticsearch/data
# 任何ip都能访问
echo "http.host: 0.0.0.0" >> /root/docker/elasticsearch/config/elasticsearch.yml
# 运行elasticsearch REST API端口9200 集群端口9300
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
--restart=always \
--privileged=true \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /root/docker/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /root/docker/elasticsearch/data:/usr/share/elasticsearch/data \
-v /root/docker/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 保证权限 任何人任何组都可以读写操作执行,可以进入elasticsearch使用ll命令查看权限
chmod -R 777 /root/docker/elasticsearch/ 测试是否安装成功:
# 查看elasticsearch是否运行
docker ps -a在浏览器输入虚拟机的ip和elasticsearch的REST API端口http://172.1.11.10:9200/ ,如果出现以下内容,说明安装成功。
{
"name": "7876d2859af8",
"cluster_name": "elasticsearch",
"cluster_uuid": "i46io2YkTY6pXr8IQ9qmXA",
"version": {
"number": "7.4.2",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date": "2019-10-28T20:40:44.881551Z",
"build_snapshot": false,
"lucene_version": "8.2.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}1.2 安装Kibana
# 拉取镜像,可视化检索数据
docker pull kibana:7.4.2
# 运行Kibana
docker run --name kibana --restart=always --privileged=true \
-e ELASTICSEARCH_HOSTS=http://172.xx.xx.xx:9200 \
-p 5601:5601 -d kibana:7.4.2说明:
(1)-e ELASTICSEARCH_HOSTS=http://172.xx.xx.xx:9200 :Elasticsearch地址。
(2)-d:后端运行。
(3)--restart=always:开机启动。
(4)--name kibana :容器名称。
(6)privileged=true :权限。
1.3 安装Logstash
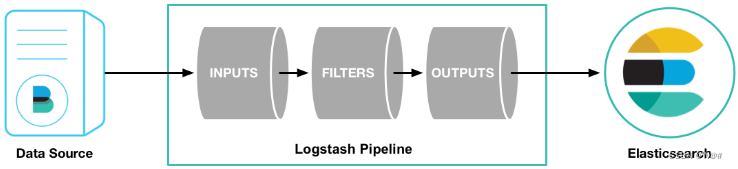
- Logstash是具有实时流水线能力的开源的数据收集引擎。Logstash可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出。它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。
- 管道(Logstash Pipeline)是Logstash中独立的运行单元,每个管道都包含两个必须的元素输入(input)和输出(output),和一个可选的元素过滤器(filter),事件处理管道负责协调它们的执行。 输入和输出支持编解码器,使您可以在数据进入或退出管道时对其进行编码或解码,而不必使用单独的过滤器。
- Logstash官方插件 logstash-input-jdbc集成在Logstash(5.x之后)的版本,可以通过配置实现mysql和es全量与增量数据的定时同步。
# 拉取logstash
docker pull logstash:7.4.22 数据同步
2.1 准备MySQL表和数据
create table pms_spu_info
(
id bigint not null auto_increment comment '商品id',
spu_name varchar(200) comment '商品名称',
spu_description varchar(1000) comment '商品描述',
catalog_id bigint comment '所属分类id',
brand_id bigint comment '品牌id',
weight decimal(18,4),
publish_status tinyint comment '上架状态[0 - 下架,1 - 上架]',
create_time datetime,
update_time datetime,
primary key (id)
);2.2 运行Logstash
# 运行logstash
docker run -d --name logstash logstash:7.4.2
mkdir -p /root/docker/logstash/config
mkdir -p /root/docker/logstash/data
mkdir -p /root/docker/logstash/pipeline
mkdir -p /root/docker/logstash/jars
# 上传mysql驱动mysql-connector-java-5.1.47.jar到/root/docker/logstash/jars
#拷贝已启动的容器中的文件到宿主机,用于重启挂载
docker cp logstash2:/usr/share/logstash/config /root/docker/logstash/
docker cp logstash2:/usr/share/logstash/data /root/docker/logstash/
docker cp logstash2:/usr/share/logstash/pipeline /root/docker/logstash/
# 保证权限 任何人任何组都可以读写操作执行
chmod -R 777 /root/docker/logstash
# 删除logstash容器
docker rm -f logstash
# 配置连接es
cd /root/docker/logstash/config
vi logstash.yml- logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://172.xx.xx.6:9200" ]- 创建mysql.conf,编写mysql数据同步至es相关配置
# 创建mysql.conf
cd /root/docker/logstash2/pipeline/
vi mysql.conf1)mysql.conf内容如下:
input {
jdbc {
type => "jdbc"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://172.xx.xx.xx:9906/gulimall_pms?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
# 数据库连接账号和密码
jdbc_user => "root"
jdbc_password => "root"
# MySQL驱动架包
jdbc_driver_library => "/usr/share/logstash/mysql/mysql-connector-java-8.0.17.jar"
# MySQL驱动
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认是false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600秒
jdbc_validation_timeout => "3600"
# 开启分页查询,默认false不开启
jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值)
jdbc_page_size => "500"
# 查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径
statement => "SELECT id,spu_name spuName,spu_description spuDescription,catalog_id catalogId,brand_id brandId,weight,publish_status publishStatus,DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') createTime,DATE_FORMAT(update_time,'%Y-%m-%d %H:%i:%s') updateTime FROM pms_spu_info WHERE update_time > :sql_last_value"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "updateTime"
# 轨迹字段类型Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => timestamp
# record_last_run上次数据存放位置
last_run_metadata_path => "/usr/share/logstash/config/logstash_metadata"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run => false
# 同步频率(分 时 天 月 年),默认每分钟同步一次
schedule => "* * * * *"
}
}
output {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
hosts => ["172.xx.xx.xx:9200"]
# 索引名字,必须小写
index => "spu"
# 文档id,数据唯一索引(建议使用表的主键)
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}2)查询sql如下:
SELECT
id,spu_name spuName,spu_description spuDescription,catalog_id catalogId,
brand_id brandId,weight,publish_status publishStatus,
DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') createTime,
DATE_FORMAT(update_time,'%Y-%m-%d %H:%i:%s') updateTime
FROM pms_spu_info WHERE update_time > :sql_last_value日期通过DATE_FORMAT(date,"输出格式")进行格式化,数据库与es日期格式保持一致。
- 重新运行logstash容器
docker run --name logstash --restart=always -d -p 5044:5044 -p 9600:9600 \
--privileged=true \
-v /root/docker/logstash/config:/usr/share/logstash/config \
-v /root/docker/logstash/jars/mysql-connector-java-5.1.47.jar:/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.47.jar \
-v /root/docker/logstash/pipeline:/usr/share/logstash/pipeline \
logstash:7.4.2 -f /usr/share/logstash/pipeline/mysql.conf说明:
(1)-f 是一个非常有用的选项,可以使用户使用指定的文件来指定一些Docker镜像的构建和配置信息。
(2)-f 也可以用于强制删除容器。
2.3 测试
- mysql表中数据,如下

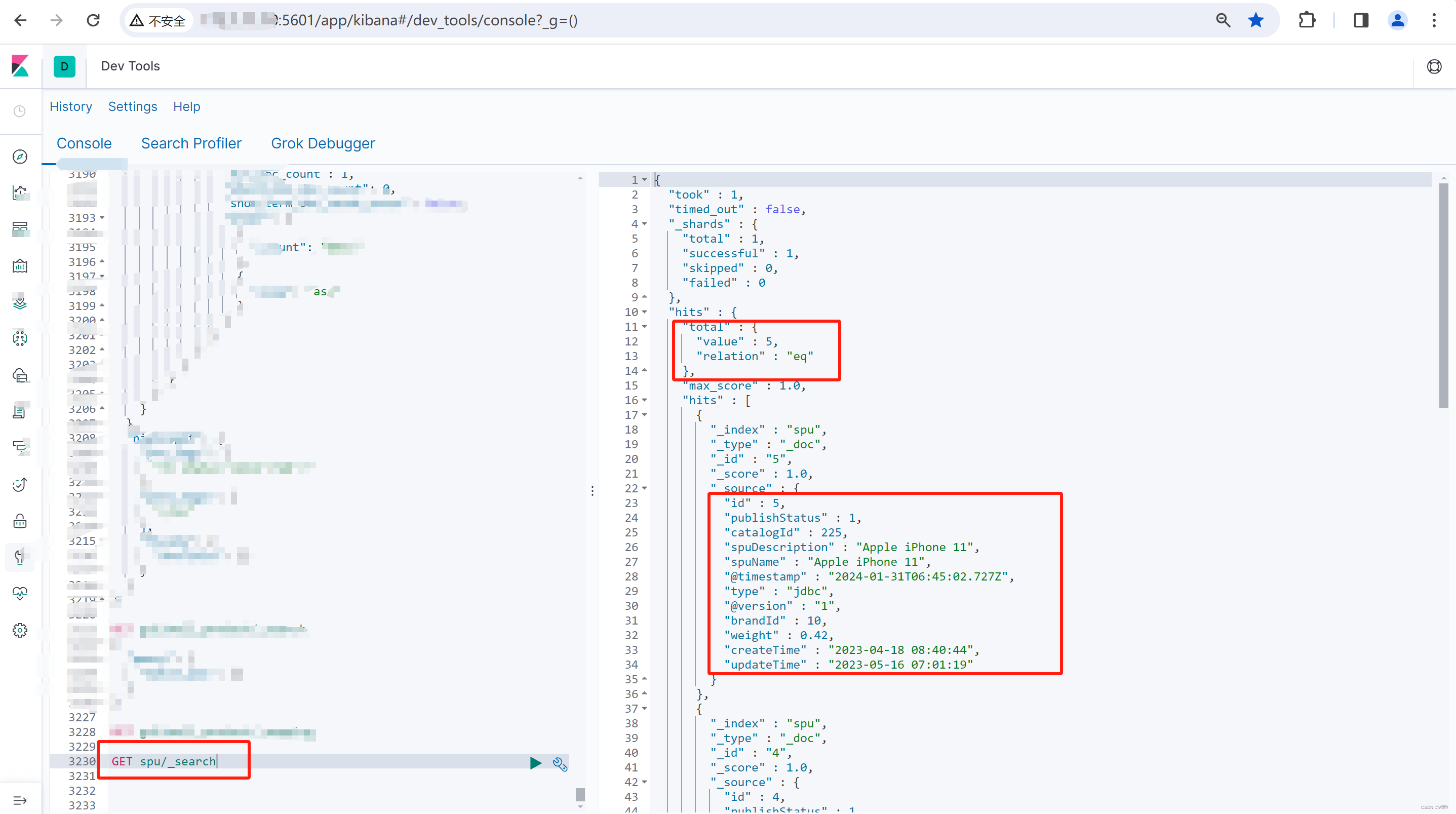
- 通过Kibana进行查询,如下:
3 Logstash报错(踩坑)记录
3.1 记录一
3.1.1 报错信息
LogStash::PluginLoadingError Unable to find driver class via URLClassLoader in given driver jars : com.mysql.jdbc.Driver and com.mysql.jdbc.Driver

3.1.2 报错原因
Logstashd的logstash-input-jdbc插件在调用数据库驱动jar包时,默认会去logstash/logstash-core/lib/jars/目录下去找。
3.1.3 解决方案
将数据库驱动(例如:mysql-connector-java-5.1.47.jar)放到/usr/share/logstash/logstash-core/lib/jars/下面。
3.2 记录二
3.2.1 报错信息
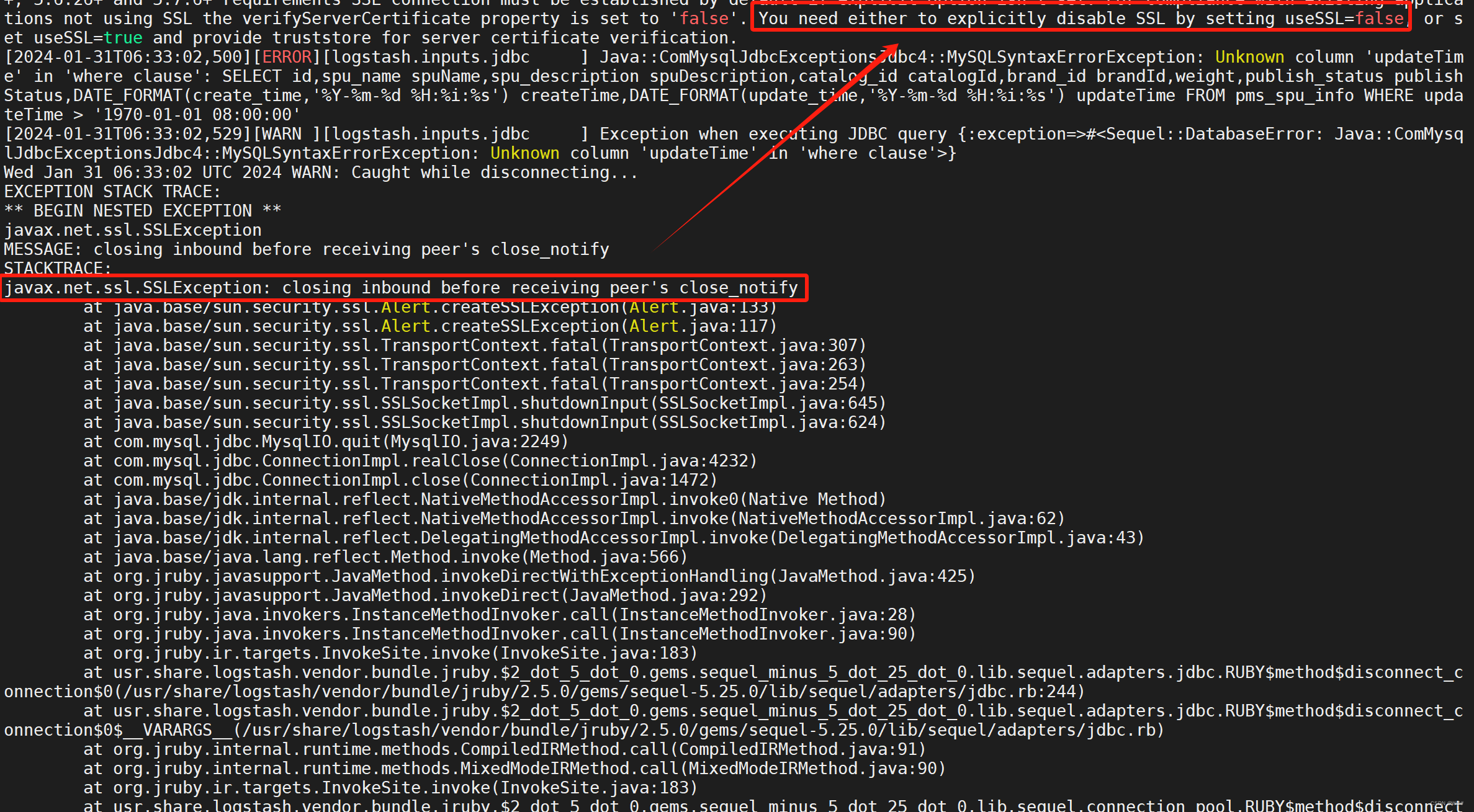
javax.net.ssl.SSLException: closing inbound before receiving peer's close _notify
3.2.2 报错原因
安装的是mysql8.x的版本,远程连接发现需要做ssl身份验证,本机连接不需要,取消掉其ssl身份验证需要调整配置。
3.3.3 解决方案
数据库连接地址上添加useSSL=false,如下:
"jdbc:mysql://172.xx.xx.xx:9906/gulimall_pms?useUnicode=true&characterEncoding=UTF-8&useSSL=false"


![[Java面试]JavaSE知识回顾](https://img-blog.csdnimg.cn/direct/3a48b143c7104bceabf36edad9a309a0.png)