目录
- 更大层面上的Attention
- 在attention中,怎么分区channel-wise还是spatial-wise
- 举一个Spatial-Channel Attention的例子
- 使用广泛的Dot-product Attention
- attention机制中的query,key,value的概念解释
- Attention的一个例子
更大层面上的Attention
在attention中,怎么分区channel-wise还是spatial-wise
为了更好地理解 “wise”,可以将其看作是一种特定维度或方面的强调。例如:
“time-wise” 表示与时间相关的事物。
在这种用法中,“wise” 帮助明确我们正在讨论的是哪一个特定的维度或方面。因此,当我们谈论 “channel-wise” attention 时,我们的焦点是在于如何以通道为基础进行操作;当我们谈论 “spatial-wise” attention 时,我们的焦点是在于空间位置或区域。
在神经网络中,特别是在处理图像或视频数据时,Attention 机制可以以不同的方式集中于输入数据的不同部分。在这些方法中,“channel-wise” 和 “spatial-wise” attention 是两种常见的方式。下面解释这两种方式:
- Channel-wise Attention
- 含义:在 “channel-wise” attention 中,“wise” 指的是关注操作是针对不同的通道进行的。在图像处理中,通道通常指的是颜色通道(如RGB中的红、绿、蓝),或者在深度学习模型中,通道可以是不同的特征表示。
- 例子:如果一个图像处理模型正在处理一个具有多个通道的特征图,“channel-wise” attention 将决定哪些通道更重要,可能会增强一些通道的特征而减弱其他通道的特征。
应用:这种类型的attention在处理那些不同通道具有不同语义信息的数据时特别有用。例如,在卷积神经网络中,不同的卷积层可能会学习到代表不同高级特征的通道(如边缘、纹理等)。
- Spatial-wise Attention
- 含义:在 “spatial-wise” attention 中,“wise” 指的是关注操作是针对图像或特征图的不同空间区域进行的。这种方法关注于图像中的不同位置,而不是整个图像作为一个整体。
- 例子:在对象检测任务中,“spatial-wise” attention 可能会集中于图像中包含重要对象的区域,而忽略其他不相关的区域。
应用:这种类型的attention在图像识别或对象检测等任务中特别有用,因为它可以帮助模型集中于图像中最重要的部分,例如,一个对象可能只占据图像的一小部分。
- 如何选择
选择 channel-wise 还是 spatial-wise attention 取决于具体任务和数据的特点。在某些情况下,甚至可以将两者结合起来,以便同时利用通道和空间信息。例如,一些高级神经网络架构在其attention机制中同时考虑了通道和空间维度,从而提高了模型对图像的理解能力。
举一个Spatial-Channel Attention的例子
例子来自于《Cross-Modal Relation-Aware Networks for Audio-Visual Event Localization》中的AGSCA模块,图片和英文部分均为原文
Given audio features a t ∈ R d a \boldsymbol{a}_t \in \mathbb{R}^{d_a} at∈Rda and visual features v t ∈ R d v × ( H ∗ W ) v_t \in \mathbb{R}^{d_v \times(H * W)} vt∈Rdv×(H∗W) where H H H and W W W are the height and width of feature maps respectively, AGSCA first generates channel-wise attention maps M t c ∈ R d v × 1 \boldsymbol{M}_t^c \in \mathbb{R}^{d_v \times 1} Mtc∈Rdv×1 to adaptively emphasize informative features. It then produces spatial attention maps M t s ∈ R 1 × ( H ∗ W ) \boldsymbol{M}_t^s \in \mathbb{R}^{1 \times(H * W)} Mts∈R1×(H∗W) for the channelattentive features to highlight sounding regions, yielding channelspatial attentive visual features v t c s v_t^{c s} vtcs, as illustrated in Figure 3. The attention process can be summarized as, v t c s = M t s ⊗ ( v t c ) T , v t c = M t c ⊙ v t , \begin{aligned} & v_t^{c s}=\boldsymbol{M}_t^s \otimes\left(v_t^c\right)^T, \\ & v_t^c=\boldsymbol{M}_t^c \odot v_t, \end{aligned} vtcs=Mts⊗(vtc)T,vtc=Mtc⊙vt,where ⊗ \otimes ⊗ denotes matrix multiplication, and ⊙ \odot ⊙ means element-wise multiplication. We next separately introduce the channel-wise attention that generates attention maps M t c \boldsymbol{M}_t^c Mtc and spatial attention that produces attention maps M t s \boldsymbol{M}_t^s Mts.

- 我们先来看如何得到channel-wise attention maps M t c \boldsymbol{M}_t^c Mtc:
Channel-Wise Attention. We explicitly model the dependencies between channels of features with the guidance of audio signals. Specifically, we first project audio and visual features to the same dimension d v d_v dv using fully-connected layers with non-linearity, resulting in audio guidance maps a t m ∈ R d v \boldsymbol{a}_t^m \in \mathbb{R}^{d_v} atm∈Rdv and projected visual features with dimensions of d v × ( H ∗ W ) d_v \times(H * W) dv×(H∗W). We then leverage the guidance information of a t m \boldsymbol{a}_t^m atm by fusing visual features with a t m \boldsymbol{a}_t^m atm via element-wise multiplication. Following [17], we spatially squeeze the fused features by global average pooling. Last, we forward the fused feature vector through two fully-connected layers with nonlinearity to model the relationships between channels, yielding channel attention maps M t c \boldsymbol{M}_t^c Mtc. We give the details as follows:
M t c = σ ( W 1 U 1 c ( δ a ( U a c a t ⊙ U v c v t ) ) ) , \boldsymbol{M}_{\boldsymbol{t}}^{\boldsymbol{c}}=\sigma\left(\boldsymbol{W}_1 \boldsymbol{U}_1^c\left(\delta_a\left(\boldsymbol{U}_a^c \boldsymbol{a}_t \odot \boldsymbol{U}_v^c \boldsymbol{v}_t\right)\right)\right), Mtc=σ(W1U1c(δa(Uacat⊙Uvcvt))),
where U a c ∈ R d v × d a , U v c ∈ R d v × d v \boldsymbol{U}_a^c \in \mathbb{R}^{d_v \times d_a}, \boldsymbol{U}_v^c \in \mathbb{R}^{d_v \times d_v} Uac∈Rdv×da,Uvc∈Rdv×dv, and U 1 c ∈ R d × d v \boldsymbol{U}_1^c \in \mathbb{R}^{d \times d_v} U1c∈Rd×dv are fullyconnected layers with ReLU as an activation function, W 1 ∈ R d v × d \boldsymbol{W}_1 \in \mathbb{R}^{d_v \times d} W1∈Rdv×d are learnable parameters with d = 256 d=256 d=256 as a hidden dimension, δ a \delta_a δa indicates global average pooling, and σ \sigma σ denotes the sigmoid function. We add a residual connection by adding one to each element of M t c \boldsymbol{M}_t^c Mtc to obtain the final channel attention maps.
代码如下:
# ============================== Channel Attention ====================================
audio_query_1 = self.relu(self.affine_audio_1(audio_feature)).unsqueeze(-2)
video_query_1 = self.relu(self.affine_video_1(visual_feature)).reshape(batch*t_size, h*w, -1)
audio_video_query_raw = (audio_query_1 * video_query_1).mean(-2)
audio_video_query = self.relu(self.affine_bottleneck(audio_video_query_raw))
channel_att_maps = self.affine_v_c_att(audio_video_query).sigmoid().reshape(batch, t_size, -1, v_dim)
c_att_visual_feat = (raw_visual_feature * (channel_att_maps + 1))
就是说利用音频特征,和视觉特征中的特征图进行相乘,接着对空间特征做一个全局池化,每个通道得到一个值。最终得到 M t c ∈ R d v × 1 \boldsymbol{M}_t^c \in \mathbb{R}^{d_v \times 1} Mtc∈Rdv×1,代表着操作是针对不同的通道,给每个通道一个attention的分数。
- 接着是如何得到Spatial-wise attention maps M t s \boldsymbol{M}_t^s Mts:
Spatial Attention. We also leverage the guidance capability of audio signals to guide visual spatial attention. Spatial attention follows a similar pattern to the aforementioned channel-wise attention. Note that the input visual features v t c v_t^c vtc are channel attentive. We formulate the process of spatial attention as follows:
M t s = Softmax ( x t s ) , x t s = δ ( W 2 ( ( U a s a t ) ⊙ ( U v s v t c ) ) ) , \begin{gathered} \boldsymbol{M}_t^s=\operatorname{Softmax}\left(x_t^s\right), \\ x_t^s=\delta\left(\boldsymbol{W}_2\left(\left(\boldsymbol{U}_a^s \boldsymbol{a}_t\right) \odot\left(\boldsymbol{U}_v^s v_t^c\right)\right)\right), \end{gathered} Mts=Softmax(xts),xts=δ(W2((Uasat)⊙(Uvsvtc))),
where U a s ∈ R d × d a , U v s ∈ R d × d v \boldsymbol{U}_a^s \in \mathbb{R}^{d \times d_a}, \boldsymbol{U}_v^s \in \mathbb{R}^{d \times d_v} Uas∈Rd×da,Uvs∈Rd×dv are fully-connected layers with ReLU as an activation function, W 2 ∈ R 1 × d \boldsymbol{W}_2 \in \mathbb{R}^{1 \times d} W2∈R1×d are learnable parameters with d = 256 d=256 d=256 as a hidden dimension, and δ \delta δ denotes the hyperbolic tangent function. With the spatial attention maps M t s \boldsymbol{M}_t^s Mts at hand, we perform weighted summation over v t c v_t^c vtc according to M t s \boldsymbol{M}_t^s Mts to highlight informative regions and shrink spatial dimensions, yielding a channel-spatial attentive visual feature vector v t c s ∈ R d v v_t^{c s} \in \mathbb{R}^{d_v} vtcs∈Rdv as output.
代码如下:
# ============================== Spatial Attention =====================================
# channel attended visual feature: [batch * 10, 49, v_dim]
c_att_visual_feat = c_att_visual_feat.reshape(batch*t_size, -1, v_dim)
c_att_visual_query = self.relu(self.affine_video_2(c_att_visual_feat))
audio_query_2 = self.relu(self.affine_audio_2(audio_feature)).unsqueeze(-2)
audio_video_query_2 = c_att_visual_query * audio_query_2
spatial_att_maps = self.softmax(self.tanh(self.affine_v_s_att(audio_video_query_2)).transpose(2, 1))
c_s_att_visual_feat = torch.bmm(spatial_att_maps, c_att_visual_feat).squeeze().reshape(batch, t_size, v_dim)
就是说利用音频特征,和视觉特征中的特征图进行相乘,接着对空间特征不做全局池化了,而是做一个softmax,这样遍得到了空间特征的特征图,最终将通道变为1,得到 M t s ∈ R 1 × ( H ∗ W ) \boldsymbol{M}_t^s \in \mathbb{R}^{1 \times(H * W)} Mts∈R1×(H∗W),代表着操作是针对不同的空间,给特征图中每个pixel一个attention的分数,然后每个pixel都乘以这个分数。
使用广泛的Dot-product Attention
第一节介绍了attention的一些理解,事实上,给特征不同的关注度,即通过自己设计的方法,算出attention map再乘到或者作用到特征上,是更早期的attention。目前大家更多的在使用的是dot-product attention.
attention机制中的query,key,value的概念解释
这篇文章给出很好的解释:attention机制中的query,key,value的概念解释,以下直接引用原文
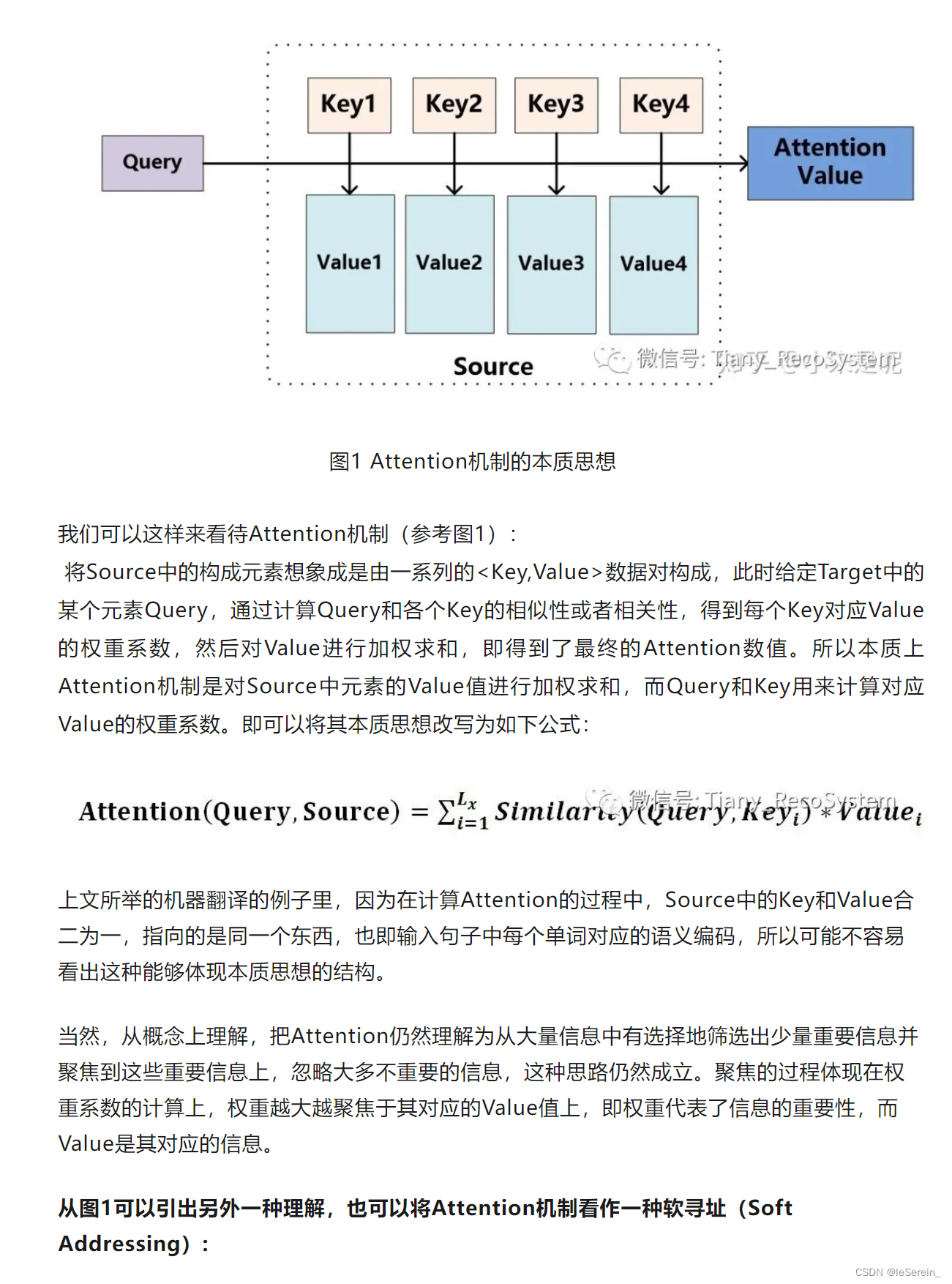
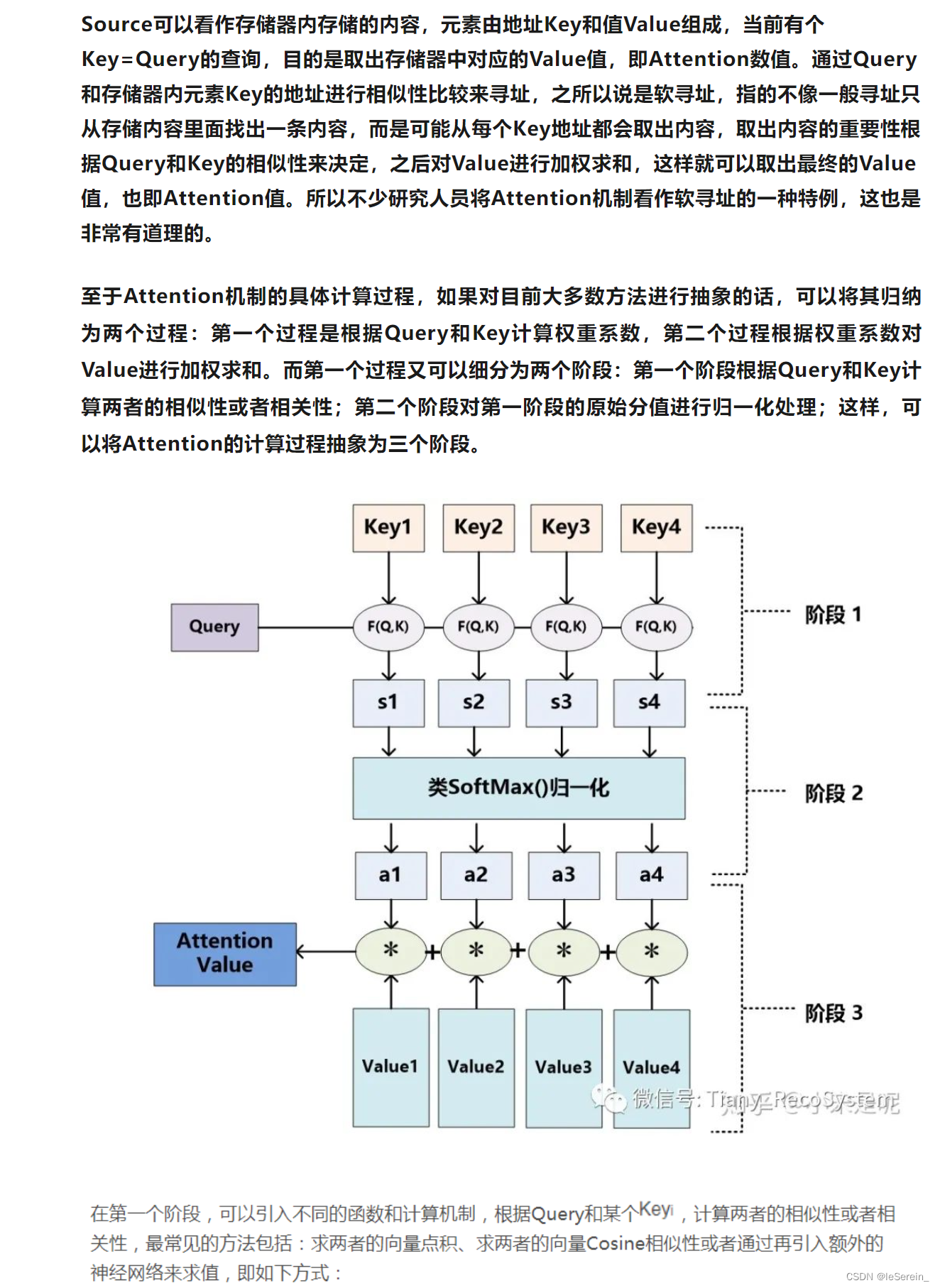
Attention的一个例子
在注意力机制的公式 Attention ( Q , K , V ) = softmax ( Q K T d k ) \operatorname{Attention}(Q, K, V) = \operatorname{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) Attention(Q,K,V)=softmax(dkQKT)中,输出维度之所以是 n × d v n \times d_v n×dv,与注意力机制如何操作有关。这里, Q Q Q、 K K K、 V V V分别代表查询(Query)、键(Key)和值(Value),其中 n n n是查询的数量, m m m是键和值的数量, d k d_k dk是键和查询的维度,而 d v d_v dv是值的维度。
为什么第一维度是
n
n
n
第一维度
n
n
n代表查询的数量。在注意力机制中,每一个查询向量都会独立地与所有键向量进行匹配,计算出一个注意力分布。这个注意力分布然后用来加权对应的值向量,生成一个加权的值向量。因此,每一个查询都会产生一个输出,这就是为什么输出的第一维度是查询的数量
n
n
n。
为什么第二维度是
d
v
d_v
dv
第二维度
d
v
d_v
dv代表值向量的维度。注意力机制的输出是值向量的加权和,因此输出的每个元素都处在值向量所在的空间,即具有相同的维度
d
v
d_v
dv。这表示,尽管注意力分数是基于查询和键的相似度计算的,但最终的输出是对值的加权,反映了值向量的维度而不是查询或键的维度。
物理意义
输出维度的物理意义在于,每个查询都会得到一个对应的输出向量,这个输出向量是基于与该查询相关的所有键的信息加权的值向量。这意味着每个输出向量都是一个上下文化的表示,它综合了所有与该查询相关的值的信息。这使得模型能够根据查询的不同,动态地调整对不同信息的关注程度,从而实现对信息的有效提取和利用。
注意力机制的目的
因此,注意力机制的设计确保了输出不仅仅是简单地复制值向量,而是根据查询和键之间的关系动态生成的上下文化的表示。这种机制使得模型能够在处理复杂的序列或者执行序列到序列的任务时,有效地捕捉和利用输入数据中的复杂关系和模式。
当Q,K,V都是相同内容时,代表着对自己全局特性的信息提取,称为self-attention
以《Cross-Modal Relation-Aware Networks for Audio-Visual Event Localization》 中的cross-modality
relation attention mechanism (CMRA) 模块为例,其目的是利用attention,提高视频和音频处理系统中视觉特征和音频特征之间的相互理解和关联性,以在不同模态(如视觉和音频)之间及其内部探索和利用丰富的关系信息。
# audio query
video_key_value_feature = self.video_encoder(visual_feature)
audio_query_output = self.audio_decoder(audio_feature, video_key_value_feature) # audio作为查询,输出的还是audio中感兴趣的特征
# video query
audio_key_value_feature = self.audio_encoder(audio_feature)
video_query_output = self.video_decoder(visual_feature, audio_key_value_feature)
其中的一个EncoderLayer实现如下:
class EncoderLayer(Module):
r"""EncoderLayer is mainly made up of self-attention.
Args:
d_model: the number of expected features in the input (required).
nhead: the number of heads in the multiheadattention models (required).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of intermediate layer, relu or gelu (default=relu).
"""
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu"):
super(EncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.activation = _get_activation_fn(activation)
def forward(self, src):
r"""Pass the input through the endocder layer.
"""
src2 = self.self_attn(src, src, src)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
if hasattr(self, "activation"):
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
else: # for backward compatibility
src2 = self.linear2(self.dropout(F.relu(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src



![【C++杂货铺】详解类和对象 [下]](https://img-blog.csdnimg.cn/direct/812828ee23dc4d9db0812853ec4aadba.gif)