第 1 章:实时数仓同步数据
实时数仓由flink源源不断从kafka当中读数据计算,所以不需要手动同步数据到实时数仓。
第 2 章:离线数仓同步数据
2.1 用户行为数据同步
2.1.1 数据通道
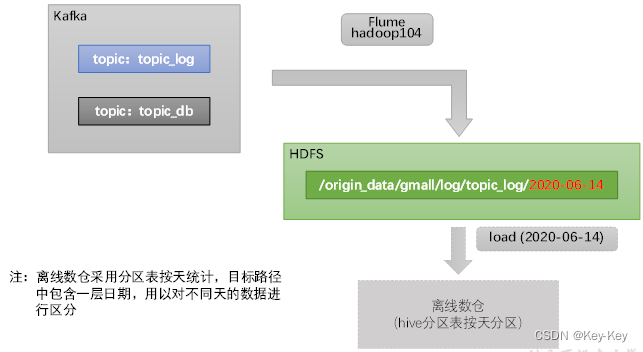
用户行为数据由flume从kafka直接同步到hdfs,由于离线数仓采用hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
2.1.2 日志消费flume配置概述
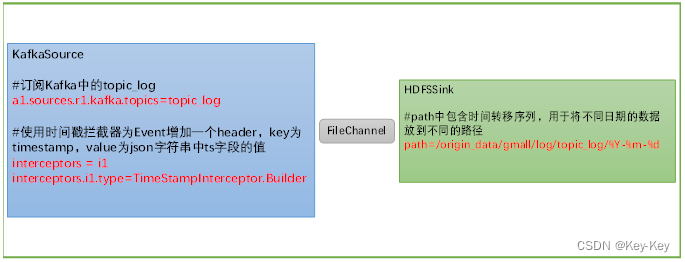
按照规划,该flume需将kafka中topic_log的数据发往hdfs。并且对每天产生的用户行为日志进行区分,将不同天的数据发往hdfs不同天的路径。
此处选择kafkasource、filechannel、hdfssink。
关键配置如下:
2.1.3 日志消费flume配置实操
1、创建flume配置文件
在104节点的flume的job目录下创建kafka_to_hdfs_log.conf
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_log.conf
2、配置文件内容如下
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
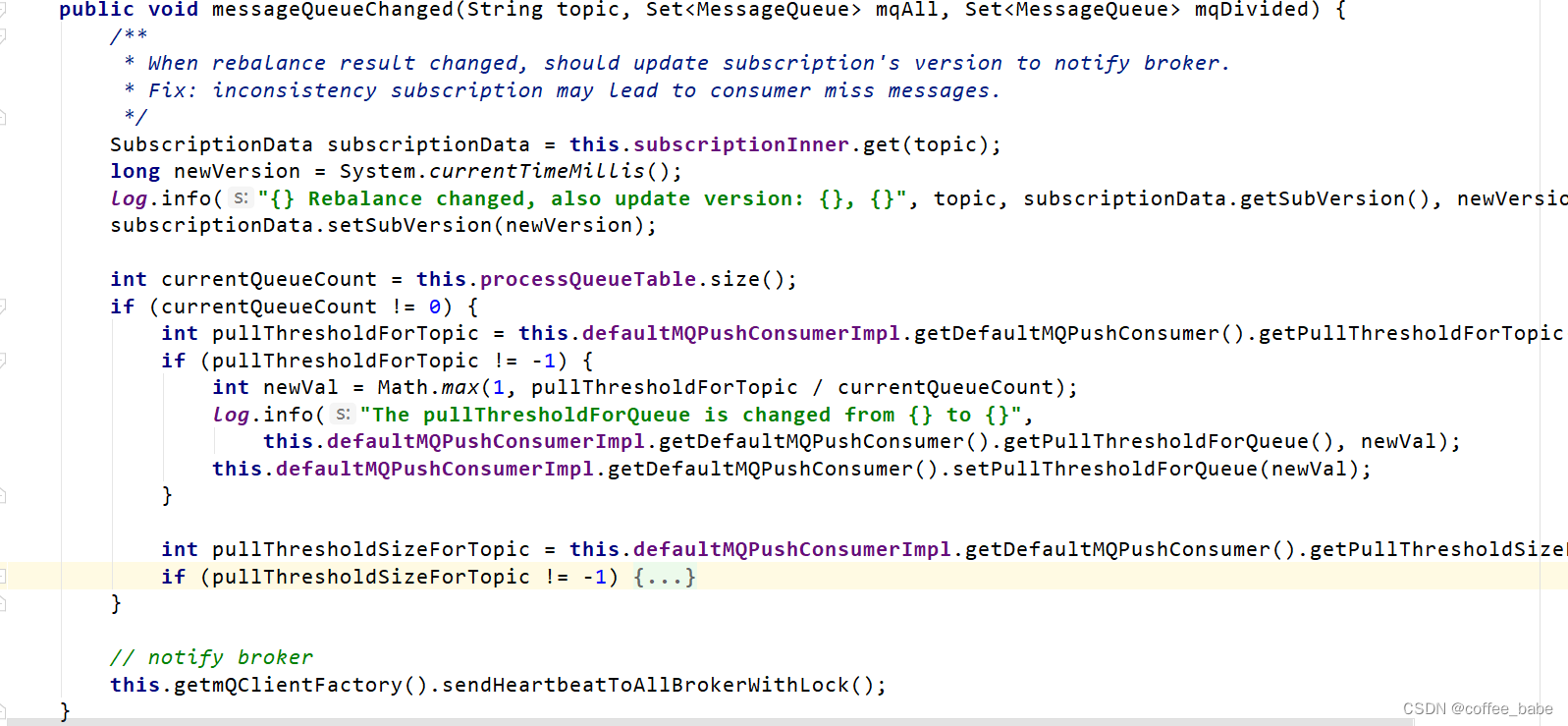
这段配置的作用是从Kafka的topic_log主题中读取数据,通过Flume的TimestampInterceptor进行预处理,然后通过文件类型的channel临时存储,最终将处理过的数据以gzip压缩格式存储到HDFS的指定路径下,路径中包含日期,用于区分不同天的数据。
注:配置优化
1)filechannel优化
通过配置datadirs执行多个路径,每个路径对应不同的硬盘,增大flume吞吐量。
checkpointdir和backupcheckpointdir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupcheckpointdir恢复数据。
3)编写flume拦截器
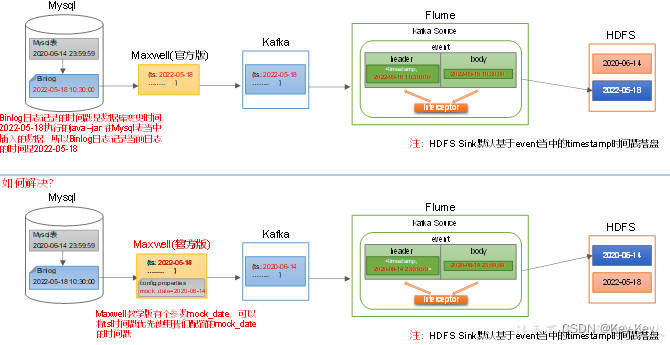
(1)数据漂移问题
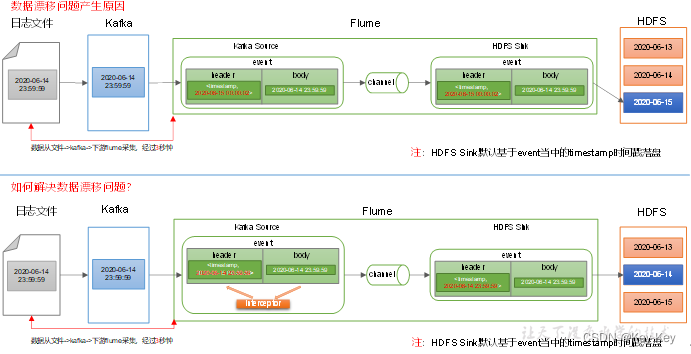
图中有两个几乎相同的流程,区别在于处理机制的细节。
上半部分的流程说明了以下几个步骤:
数据从Kafka传输到Flume。
在Flume中,数据通过一个source被接收,并且随后被放入一个channel中。
从channel中,数据被传输到一个sink,最终数据被写入HDFS。
该流程中有一个特殊的细节,在Flume的sink阶段,它会将event的timestamp作为目标文件路径的一部分。
下半部分的流程与上半部分相似,但有一个关键的差别:在Flume的source和channel之间有一个“interceptor”,这是一个处理数据的中间件。interceptor可以用来修改、过滤数据等等。图中的注释可能说明了interceptor在处理数据时的某些规则或者操作,但由于注释是中文且部分被遮挡,具体内容需要进一步的上下文信息来确定。
(2)TimestampInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取header和body的数据
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
//2、将body的数据类型转成jsonObject类型(方便获取数据)
JSONObject jsonObject = JSONObject.parseObject(log);
//3、header中timestamp时间字段替换成日志生成的时间戳(解决数据漂移问题)
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
这个拦截器的主要目的是在数据采集过程中保证每个事件的时间戳准确无误,特别是在跨系统或跨时区传输数据时,防止因系统时间差异导致的时间错乱问题。
(3)打包

(4)把打包好的文件放入到hadoop104的/opt/module/flume/lib文件夹下面
2.1.4 日志消费flume测试
1、启动zookeeper、kafka集群
2、启动日志采集flume
[atguigu@hadoop102 ~]$ f1.sh start
3、启动104的日志消费flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
4、生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
5、观察hdfs是否出现数据
2.1.5 日志消费flume启停脚本
若上述测试通过,为方便,此处创建一个flume的启停脚本
1、在hadoop102节点的/home/atguigu/bin目录下创建脚本f2.sh
[atguigu@hadoop102 bin]$ vim f2.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f2.sh
3、f2启动
[atguigu@hadoop102 module]$ f2.sh start
4、f2停止
[atguigu@hadoop102 module]$ f2.sh stop
2.2 业务数据同步
2.2.1 数据同步策略概述
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。
为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。
数据的同步策略由全量同步和增量同步。
全量同步,就是每天都将业务数据库中的全部数据同步到数据仓库,这是保证两侧数据同步的最简单的方式。
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
业务表数据量比较大,优先考虑增量,数据量比较小,优先考虑全量。
各表同步策略
2.2.3 数据同步工具概述
在本项目中,全量同步采用datax,增量同步采用maxwell。
2.2.5 全量表数据同步
2.2.5.1 数据同步工具datax部署
参考之前文章
2.2.5.2 数据通道
全量表数据由datax从mysql业务数据库直接同步到hdfs,具体数据流向如下图所示。
注:
1、目标路径中表名需要包含后缀full,表示该表为全量同步
2、目标路径中包含一层日期,用以对不同天的数据进行区分
2.2.5.3 datax配置文件
我们需要为每张全量表编写一个datax的json配置文件,此处以activity_info为例,配置文件内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"table": [
"activity_info"
]
}
],
"password": "000000",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "activity_name",
"type": "string"
},
{
"name": "activity_type",
"type": "string"
},
{
"name": "activity_desc",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "create_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "activity_info",
"fileType": "text",
"path": "${targetdir}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
注:由于目标路径包含一层日期,用以对不同天的数据加以区分,故path参数并未写死,需在提交任务时通过参数动态传入,参数名称为targetdir。
2.2.5.4 datax配置文件生成脚本
方便起见,为此提供了datax配置文件批量生成脚本,脚本内容及使用方式如下。
1、在~/bin目录下创建gen_import_config.py脚本
[atguigu@hadoop102 bin]$ vim ~/bin/gen_import_config.py
脚本内容如下
# coding=utf-8
import json
import getopt
import os
import sys
import MySQLdb
#MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "000000"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/module/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])
注:
1)安装python mysql驱动
由于需要使用python访问mysql数据库,故需安装驱动,命令如下
[atguigu@hadoop102 bin]$ sudo yum install -y MySQL-python
2)脚本使用说明
python gen_import_config.py -d database -t table
生成该表的datax同步配置文件
2、在~/bin目录下创建gen_import_config.sh脚本
[atguigu@hadoop102 bin]$ vim ~/bin/gen_import_config.sh
脚本内容如下
3、为gen_import_config.sh脚本增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/gen_import_config.sh
4、执行gen_import_config.sh脚本,生成配置文件
[atguigu@hadoop102 bin]$ gen_import_config.sh
5、观察生成的配置文件
[atguigu@hadoop102 bin]$ ll /opt/module/datax/job/import/
总用量 60
-rw-rw-r-- 1 atguigu atguigu 957 10月 15 22:17 gmall.activity_info.json
-rw-rw-r-- 1 atguigu atguigu 1049 10月 15 22:17 gmall.activity_rule.json
-rw-rw-r-- 1 atguigu atguigu 651 10月 15 22:17 gmall.base_category1.json
-rw-rw-r-- 1 atguigu atguigu 711 10月 15 22:17 gmall.base_category2.json
-rw-rw-r-- 1 atguigu atguigu 711 10月 15 22:17 gmall.base_category3.json
-rw-rw-r-- 1 atguigu atguigu 835 10月 15 22:17 gmall.base_dic.json
-rw-rw-r-- 1 atguigu atguigu 865 10月 15 22:17 gmall.base_province.json
-rw-rw-r-- 1 atguigu atguigu 659 10月 15 22:17 gmall.base_region.json
-rw-rw-r-- 1 atguigu atguigu 709 10月 15 22:17 gmall.base_trademark.json
-rw-rw-r-- 1 atguigu atguigu 1301 10月 15 22:17 gmall.cart_info.json
-rw-rw-r-- 1 atguigu atguigu 1545 10月 15 22:17 gmall.coupon_info.json
-rw-rw-r-- 1 atguigu atguigu 867 10月 15 22:17 gmall.sku_attr_value.json
-rw-rw-r-- 1 atguigu atguigu 1121 10月 15 22:17 gmall.sku_info.json
-rw-rw-r-- 1 atguigu atguigu 985 10月 15 22:17 gmall.sku_sale_attr_value.json
-rw-rw-r-- 1 atguigu atguigu 811 10月 15 22:17 gmall.spu_info.json
2.2.5.5 测试生成的datax配置文件
以activity_info为例,测试用脚本生成的配置文件是否可用
1、创建目标路径
[atguigu@hadoop102 bin]$ hadoop fs -mkdir /origin_data/gmall/db/activity_info_full/2020-06-14
2、执行datax同步命令
[atguigu@hadoop102 bin]$ python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/gmall/db/activity_info_full/2020-06-14" /opt/module/datax/job/import/gmall.activity_info.json
3、观察同步结果
2.2.5.6 全量表数据同步脚本
为方便使用以及后续的任务调度,此外编写一个全量表数据同步脚本。
1、在~/bin目录创建mysql_to_hdfs_full.sh
[atguigu@hadoop102 bin]$ vim ~/bin/mysql_to_hdfs_full.sh
脚本内容如下
#!/bin/bash
DATAX_HOME=/opt/module/datax
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {
hadoop fs -test -e $1
if [[ $? -eq 1 ]]; then
echo "路径$1不存在,正在创建......"
hadoop fs -mkdir -p $1
else
echo "路径$1已经存在"
fs_count=$(hadoop fs -count $1)
content_size=$(echo $fs_count | awk '{print $3}')
if [[ $content_size -eq 0 ]]; then
echo "路径$1为空"
else
echo "路径$1不为空,正在清空......"
hadoop fs -rm -r -f $1/*
fi
fi
}
#数据同步
import_data() {
datax_config=$1
target_dir=$2
handle_targetdir $target_dir
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}
case $1 in
"activity_info")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
;;
"activity_rule")
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
;;
"base_category1")
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
;;
"base_category2")
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
;;
"base_category3")
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
;;
"base_dic")
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
;;
"base_province")
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
;;
"base_region")
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
;;
"base_trademark")
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
;;
"cart_info")
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
;;
"coupon_info")
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
;;
"sku_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
;;
"sku_info")
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
;;
"sku_sale_attr_value")
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
;;
"spu_info")
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
"all")
import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date
import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date
import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date
import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date
import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date
;;
esac
2、为mysql_to_hdfs_full.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_hdfs_full.sh
3、测试同步脚本
[atguigu@hadoop102 bin]$ mysql_to_hdfs_full.sh all 2020-06-14
4、检查同步结果
2.2.6 增量表数据同步
2.2.6.1 数据通道
注:
1、目标路径中表名需包含后缀inc,表示该表为增量同步。
2、目标路径中包含一层日期,用以对不同天的数据进行区分。
2.2.6.2 flume配置
1、flume配置概述
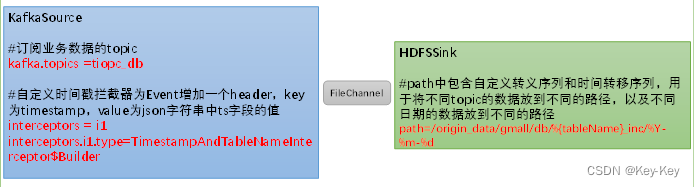
flume需要将kafka中topic_db主题的数据传输到hdfs,故其需选用kafkasource以及hdfssink,channel选用filechannel。
需要注意的是,hdfssink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下
flume配置重点
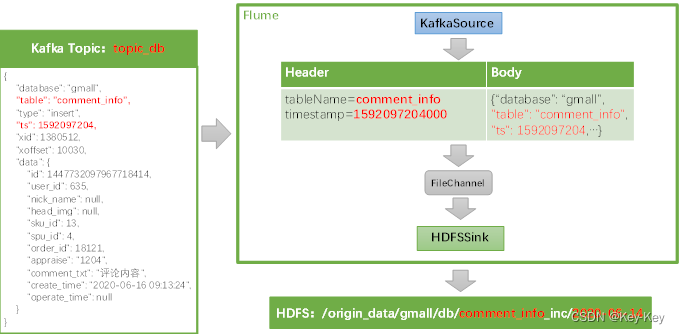
具体数据示例如下
flume数据示例
2、flume配置实操
1)创建flume配置文件
在104节点的flume的job目录下创建kafka_to_hdfs_db.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_db.conf
2)配置文件内容如下
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
3)编写flume拦截器
(1)新建一个maven项目,并在pom.xml文件中加入如下配置
具体来说,这段配置似乎是为 Maxwell,一个数据库变更数据捕获(CDC)工具,以及 Apache Kafka,一个分布式事件流平台,设置的。下面是各个部分的作用说明:
log_level=info: 设置日志级别为信息(info),这意味着应用程序会记录一般信息消息,包括错误、警告和其他关键事件信息,但不会记录更详细的调试消息。
producer=kafka: 指定消息生产者为 Kafka。这表明 Maxwell 将使用 Kafka 作为输出目标,将捕获的数据库变更事件发送到 Kafka 主题中。
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092: 指定 Kafka 集群的引导服务器地址和端口,这里有两个服务器(hadoop102 和 hadoop103),分别监听 9092 端口。Maxwell 将连接到这些服务器以发送消息。
kafka_topic=topic_db: 指定 Maxwell 将消息发送到的 Kafka 主题名称,这里的主题名称为 topic_db。
mock_date=2020-06-14: 特定于 Maxwell 教学版的配置,用于模拟一个特定日期的数据,这对于测试或演示某些基于时间的功能非常有用。它要求在修改后重启 Maxwell 才能生效。
MySQL 登录信息:
host=hadoop102: MySQL 服务器的主机名或 IP 地址。
user=maxwell: 用于连接 MySQL 的用户名。
password=maxwell: 连接 MySQL 的密码。
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai: JDBC 连接选项,这里指定了不使用 SSL 连接(useSSL=false)并设置了服务器时区为 Asia/Shanghai。
(2)在com.atguigu.gmall.flume.interceptor包下创建timestampandtablenameinterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
Long ts = jsonObject.getLong("ts");
//Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒
String timeMills = String.valueOf(ts * 1000);
String tableName = jsonObject.getString("table");
headers.put("timestamp", timeMills);
headers.put("tableName", tableName);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampAndTableNameInterceptor ();
}
@Override
public void configure(Context context) {
}
}
}
(3)重新打包

(4)将打包好的文件放到104的/opt/module/flume/lib文件下
3、通道测试
1)启动zookeeper、kafka集群
2)启动104的flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf -Dflume.root.logger=info,console
3)生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
4)观察hdfs上的目标路径是否有数据出现
5)数据目标路径的日期说明
仔细观察,会发现目标路径中的日期,并非模拟数据的业务日期,而是当前日期。这是由于maxwell输出的json字符串中的ts字段的值,是数据的变动日期。而真实场景下,数据的业务日期与变动日期应当是一致的。
4、编写flume启停脚本
1、在102节点的/home/atguigu/bin目录下创建脚本f3.sh
[atguigu@hadoop102 bin]$ vim f3.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 业务数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 业务数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f3.sh
3、f3启动
[atguigu@hadoop102 module]$ f3.sh start
4、f3停止
[atguigu@hadoop102 module]$ f3.sh stop
2.2.6.3 maxwell配置
1、maxwell时间戳问题
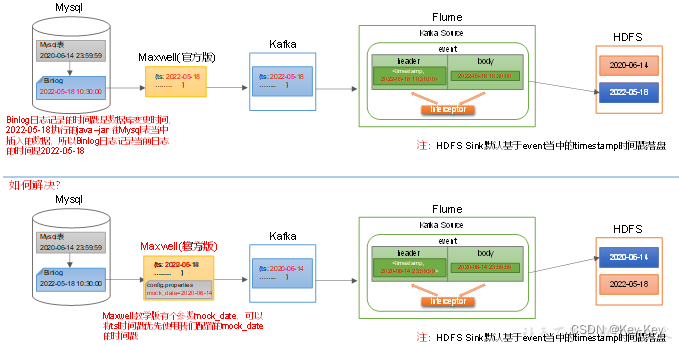
此处为了模拟真实环境,对maxwell源码进行了改动,增加了一个参数mock_date,该参数的作用就是指定maxwell输出json字符串的ts时间戳的日期。
1)修改maxwell配置文件config.properties,增加mock_date参数,如下
log_level=info
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092
#kafka topic配置
kafka_topic=topic_db
#注:该参数仅在maxwell教学版中存在,修改该参数后重启Maxwell才可生效
mock_date=2020-06-14
# mysql login info
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
2)重启maxwell
[atguigu@hadoop102 bin]$ mxw.sh restart
3)重新生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
4)观察hdfs目标路径日期是否正常
2.2.6.4 增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用maxwell的bootstrap功能,下面编写一个增量表首日全量同步脚本。
1、在~/bin目录创建mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_inc_init.sh
脚本内容如下
#!/bin/bash
# 该脚本的作用是初始化所有的增量表,只需执行一次
MAXWELL_HOME=/opt/module/maxwell
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"cart_info")
import_data cart_info
;;
"comment_info")
import_data comment_info
;;
"coupon_use")
import_data coupon_use
;;
"favor_info")
import_data favor_info
;;
"order_detail")
import_data order_detail
;;
"order_detail_activity")
import_data order_detail_activity
;;
"order_detail_coupon")
import_data order_detail_coupon
;;
"order_info")
import_data order_info
;;
"order_refund_info")
import_data order_refund_info
;;
"order_status_log")
import_data order_status_log
;;
"payment_info")
import_data payment_info
;;
"refund_payment")
import_data refund_payment
;;
"user_info")
import_data user_info
;;
"all")
import_data cart_info
import_data comment_info
import_data coupon_use
import_data favor_info
import_data order_detail
import_data order_detail_activity
import_data order_detail_coupon
import_data order_info
import_data order_refund_info
import_data order_status_log
import_data payment_info
import_data refund_payment
import_data user_info
;;
esac
2、为mysql_to_kafka_inc_init.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_kafka_inc_init.sh
3、测试同步脚本
1)清理历史数据
为方便查看结果,现将hdfs上之前同步的增量表数据删除
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print $8}' | xargs hadoop fs -rm -r -f
2)执行同步脚本
[atguigu@hadoop102 bin]$ mysql_to_kafka_inc_init.sh all
4、检查同步结果
2.3 采集通道启动/停止脚本
1、在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim cluster.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动采集 Flume
f1.sh start
#启动日志消费 Flume
f2.sh start
#启动业务消费 Flume
f3.sh start
#启动 maxwell
mxw.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Maxwell
mxw.sh stop
#停止 业务消费Flume
f3.sh stop
#停止 日志消费Flume
f2.sh stop
#停止 日志采集Flume
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
2、增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 cluster.sh
3、cluster集群启动脚本
[atguigu@hadoop102 module]$ cluster.sh start
4、cluster集群停止脚本
第 3 章:数仓环境准备
3.1 hive安装部署
1、在apache-hive.tar.gz上传到linux的/opt/software目录下
2、解压apache-hive.tar.gz到/opt/module/目录下面
[atguigu@hadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3、修改apache-hive.tar.gz的名称为hive
[atguigu@hadoop102 software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
4、修改/etc/profile.d/my_env.sh,添加环境变量
[atguigu@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
重启xshell对话框或者source以下/etc/profile.d/my_env.sh文件,使环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
5、解决日志jar包冲突,进入/opt/module/hive/lib目录
[atguigu@hadoop102 lib]$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
4.2 hive元数据配置到mysql
4.2.1 拷贝驱动
将MySQL的jdbc驱动拷贝到hive的lib目录下
[atguigu@hadoop102 lib]$ cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
4.2.2 配置metastore到mysql
在$hive_home/conf目录下新建hive-site.xml文件
[atguigu@hadoop102 conf]$ vim hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
4.3 启动hive
4.3.1 初始化元数据库
1、登录mysql
[atguigu@hadoop102 conf]$ mysql -uroot -p000000
2、新建hive元数据库
mysql> create database metastore;
3、修改元数据库字符集
hive元数据库的字符集默认为latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需解决乱码问题,需做以下修改。
修改hive元数据库中存储注释的字段的字符集为utf-8
1)字段注释
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2)表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
4、退出mysql
mysql> quit;
4.3.2 启动hive客户端
1、启动hive客户端
[atguigu@hadoop102 hive]$ bin/hive
2、查看一下数据库
hive (default)> show databases;
OK
database_name
default


![基于SpringBoot开发的JavaWeb智能家电商城[附源码]](https://img-blog.csdnimg.cn/direct/3687e39bc7de4a3eaedcd91efb097a0d.png)