目录
简介
数组与集合的区别如下:
介绍
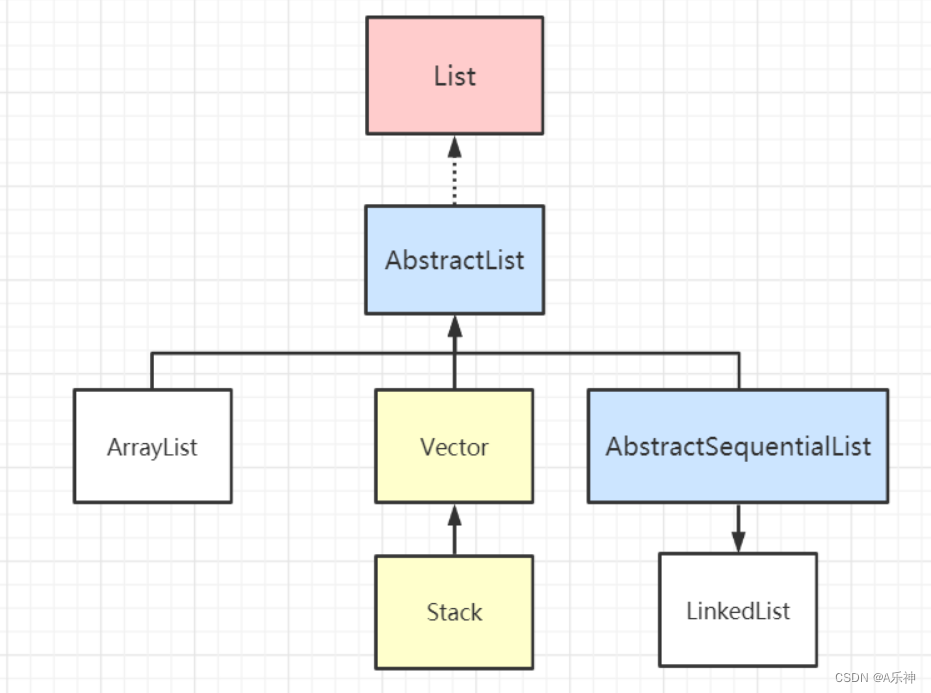
AbstractList 和 AbstractSequentialList
Vector
替代方案
Stack
ArrayList
LinkedList
前言-与正文无关
生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中,我们往往容易陷入工作的漩涡,忘记了停下脚步,感受周围的世界。让我们一起提醒自己,要适时放慢脚步,欣赏生活中的每一道风景,享受与家人朋友的温馨时光,发现那些平凡日子里隐藏的幸福时刻。因为,这些点点滴滴汇聚起来的,才是构成我们丰富多彩生活的本质。希望每个人都能在繁忙的生活中找到自己的快乐之源,不仅仅为了生存而工作,更为了更好的生活而生活。
送你张美图!希望你开心!

简介
集合可以看作是一种容器,用来存储对象信息。所有集合类都位于java.util包下,值得一提的是支持多线程的集合类位于java.util.concurrent包下。
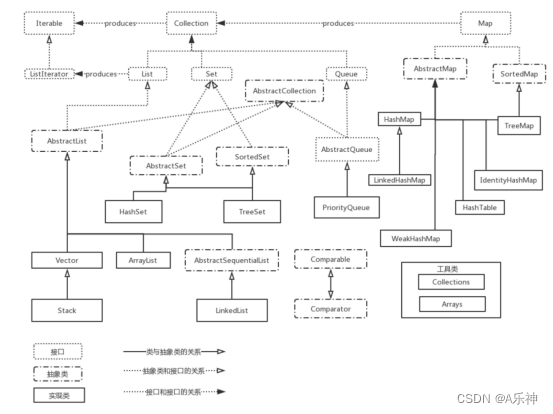
List 接口直接继承 Collection 接口,它定义为可以存储重复元素的集合,并且元素按照插入顺序有序排列,且可以通过索引访问指定位置的元素。常见的实现有:ArrayList、LinkedList、Vector和Stack
数组与集合的区别如下:
1)数组长度不可变化而且无法保存具有映射关系的数据;集合类用于保存数量不确定的数据,以及保存具有映射关系的数据。
2)数组元素既可以是基本类型的值,也可以是对象;集合只能保存对象。
介绍
AbstractList 和 AbstractSequentialList
AbstractList 抽象类实现了 List 接口,其内部实现了所有的 List 都需具备的功能,子类可以专注于实现自己具体的操作逻辑。
// 查找元素 o 第一次出现的索引位置
public int indexOf(Object o)
// 查找元素 o 最后一次出现的索引位置
public int lastIndexOf(Object o)
//···AbstractSequentialList 抽象类继承了 AbstractList,在原基础上限制了访问元素的顺序只能够按照顺序访问,而不支持随机访问,如果需要满足随机访问的特性,出现了LinkedList,继承 AbstractList,子类 LinkedList 使用链表实现,所以仅能支持顺序访问。
LinkedList
LinkedList 底层采用双向链表数据结构存储元素,由于链表的内存地址非连续,所以它不具备随机访问的特点,但由于它利用指针连接各个元素,所以插入、删除元素只需要操作指针,不需要移动元素,故具有增删快、查询慢的特点。它也是一个非线程安全的集合。
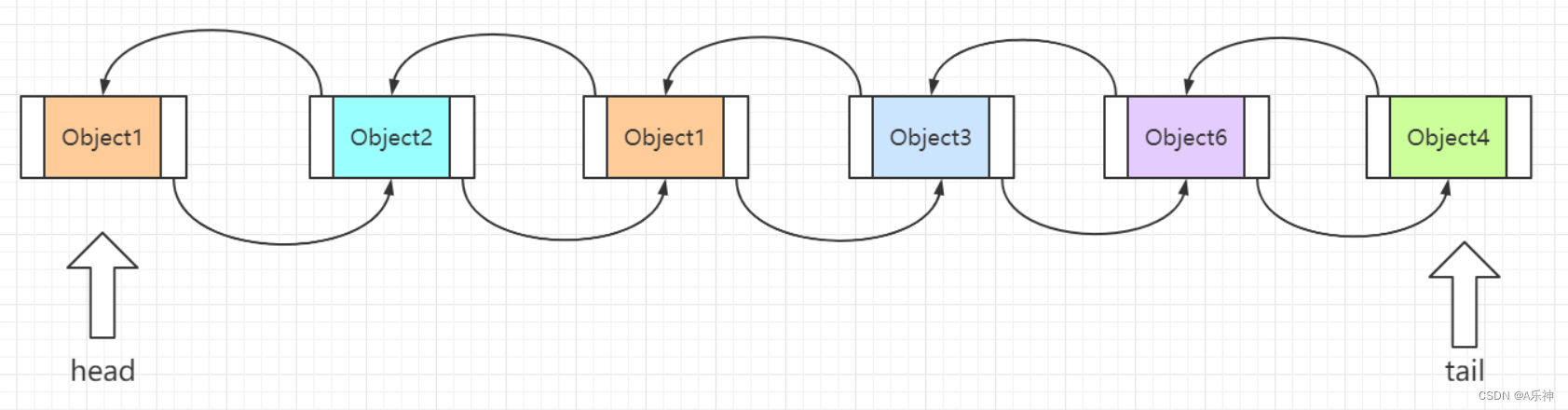
由于以双向链表作为数据结构,它是线程不安全的集合;存储的每个节点称为一个Node(上图object加前后空白区域),下图可以看到 Node 中保存了next和prev指针(上图object的前后的空白区域),item是该节点的值(上图object的不加前后空白区域)。在插入和删除时,时间复杂度都保持为 O(1)

关于 LinkedList,除了它是以链表实现的集合外,还有一些特殊的特性需要注意的。
- 优势:LinkedList 底层没有
扩容机制,使用双向链表存储元素,所以插入和删除元素效率较高,适用于频繁操作元素的场景 - 劣势:LinkedList 不具备
随机访问的特点,查找某个元素只能从head或tail指针一个一个比较,所以查找中间的元素时效率很低 - 底层查找优化:LinkedList 查找某个下标
index的元素时做了优化,if (index < this.size >> 1):这个条件检查要查找的索引是否在链表的前半部分。this.size >> 1是位移操作,等效于this.size / 2,即链表长度的一半。如果索引在前半部分,方法从链表的第一个节点(this.first)开始,通过循环遍历,每次通过x = x.next移动到下一个节点,直到到达指定索引处的节点。反之亦然。
// 遍历元素数量, 获取到指定索引位置的值
LinkedList.Node<E> node(int index) {
// 注意***:判断index在总数量的前半部分还是后半部分,这样仅需要遍历一半的数据量就能找到具体的值, 有种取半操作的含义
if (index < (size >> 1)) {
//如果在前半部分,就从0开始正序遍历, 直到找到元素
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果在后半部分, 就从最后开始倒序遍历, 直到找到元素
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}- 双端队列:使用双端链表实现,并且实现了
Deque接口,使得 LinkedList 可以用作双端队列。下图可以看到 Node 是集合中的元素,提供了前驱指针和后继指针,还提供了一系列操作头结点和尾结点的方法,具有双端队列的特性。
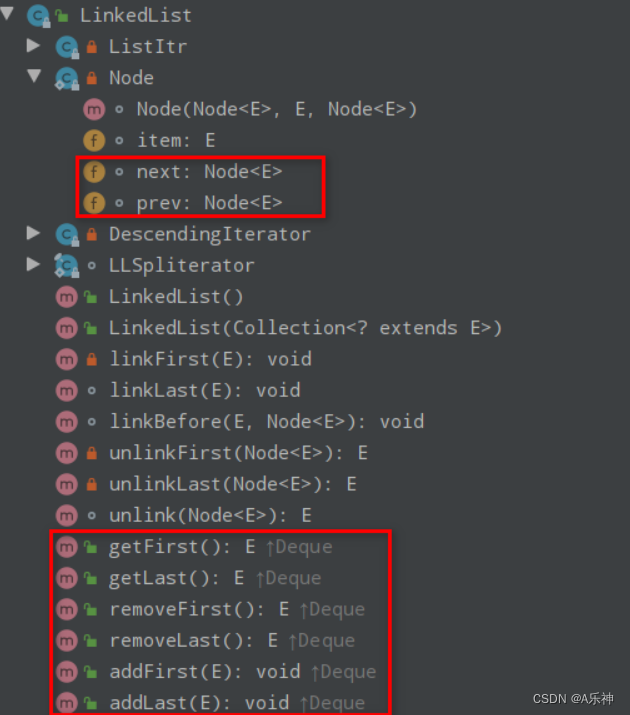
LinkedList 集合最让人熟知的是它的链表结构,但是我们同时也要注意它是一个双端队列型的集合。
Deque<Object> deque = new LinkedList<>();
Vector(了解即可)
Vector 同 ArrayList一样,都是基于数组实现的,只不过 Vector 是一个线程安全的容器,它对内部的每个方法都简单粗暴的上锁,但是通常这种同步方式需要的开销比较大, 因此,访问元素的效率要远远低于 ArrayList。还有一点在于扩容上,ArrayList 扩容后的数组长度会增加 50%,而 Vector 的扩容长度后数组会增加一倍。
Vector 在现在已经是一种过时的集合了,包括继承它的 Stack 集合也如此,它们被淘汰的原因都是因为性能低下。
原因是JDK 1.0 时代,ArrayList 还没诞生,大家都是使用 Vector 集合,但由于 Vector 的每个操作都被 synchronized 关键字修饰,即使在线程安全的情况下,仍然进行无意义的加锁与释放锁,造成额外的性能开销,做了无用功。 在 JDK 1.2 时,Collection 家族出现了,它提供了大量高性能、适用于不同场合的集合,而 Vector 也是其中一员,但由于 Vector 在每个方法上都加了锁,由于需要兼容许多老的项目,很难在此基础上优化Vector了,所以渐渐地也就被历史淘汰了。
替代方案:
现在,在线程安全的情况下,不需要选用 Vector 集合,取而代之的是 ArrayList 集合;在并发环境下,出现了 CopyOnWriteArrayList,Vector 完全被弃用了。
Stack(了解即可)

Stack是一种后入先出(LIFO)型的集合容器,如图中所示,大雄是最后一个进入容器的,top指针指向大雄,那么弹出元素时,大雄也是第一个被弹出去的。
Stack 继承了 Vector 类,常用方法如下:
- Push: 向栈顶添加一个元素。
- Pop: 移除并返回栈顶元素。
- Peek (或 Top): 查看栈顶元素,但不从栈中移除它。
- isEmpty: 检查栈是否为空。
但由于继承了 Vector,正所谓跟错老大没福报,而 Vector 的所有操作都是同步的,Stack 也渐渐被淘汰了。
取而代之的是后起之秀 Deque接口,其实现有 ArrayDeque,该数据结构更加完善、可靠性更好,依靠队列也可以实现LIFO的栈操作,所以优先选择 ArrayDeque 实现栈。
Deque<Integer> stack = new ArrayDeque<>();
// 压栈操作
stack.push(1);
stack.push(2);
// 查看栈顶元素
int top = stack.peek(); // 返回 2,但不移除
// 弹栈操作
int popped = stack.pop(); // 返回并移除 2
ArrayList
ArrayList 以数组作为存储结构,它是线程不安全的集合;具有查询快、在数组中间或头部增删慢的特点,所以它除了线程不安全这一点,其余可以替代Vector,而且线程安全的 ArrayList 可以使用 CopyOnWriteArrayList代替 Vector。
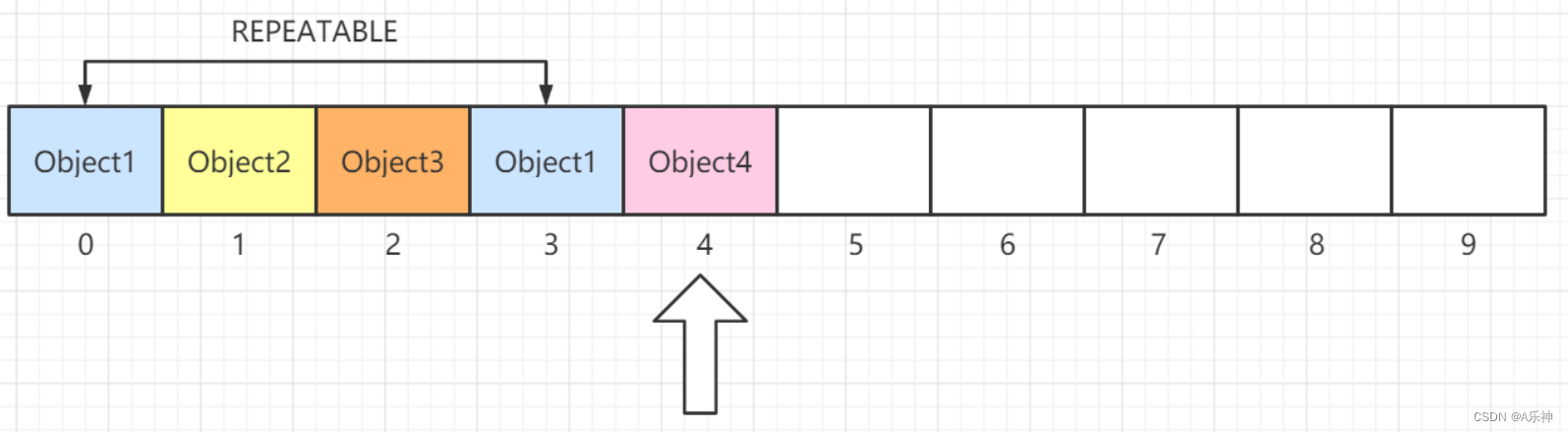
关于 ArrayList 有几个重要的点需要注意的:
-
具备随机访问特点,访问元素的效率较高,ArrayList 在频繁插入、删除集合元素的场景下效率较
低。 -
底层数据结构:ArrayList 底层使用数组作为存储结构,具备查找快、增删慢的特点
-
线程安全性:ArrayList 是线程不安全的集合
-
ArrayList 首次扩容后的长度为
10,调用add()时需要计算容器的最小容量。可以看到如果数组elementData为空数组,会将最小容量设置为10,之后会将数组长度完成首次扩容到 10。
// new ArrayList 时的默认空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 默认容量
private static final int DEFAULT_CAPACITY = 10;
// 计算该容器应该满足的最小容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
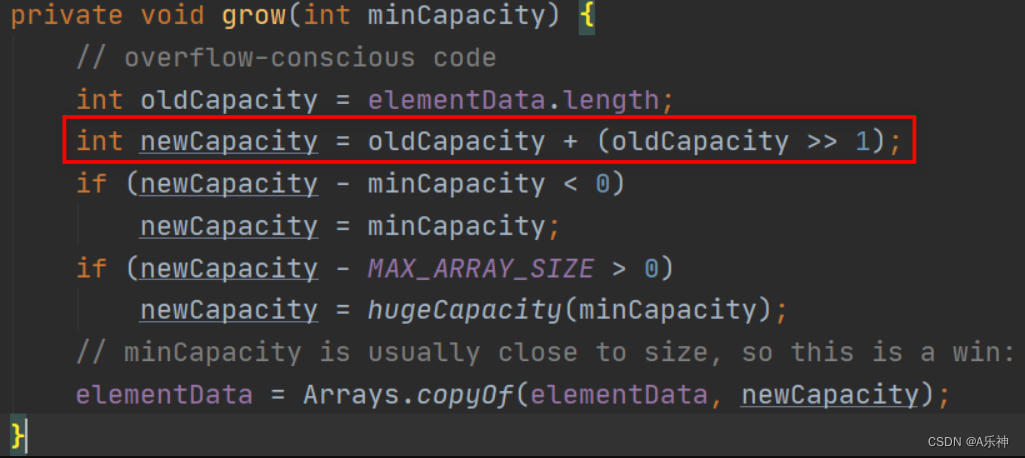
}- ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。集合从第二次扩容开始,数组长度将扩容为原来的
1.5倍,即:newLength = oldLength * 1.5
------------------------------------------与正文内容无关------------------------------------
如果觉的文章写对各位读者老爷们有帮助的话,麻烦点赞加关注呗!作者在这拜谢了!
混口饭吃了!如果你需要Java 、Python毕设、商务合作、技术交流、就业指导、技术支持度过试用期。请在关注私信我,本人看到一定马上回复!
这是我全部文章所在目录,看看是否有你需要的,如果遇到觉得不对地方请留言,看到后我会查阅进行改正。
A乐神-CSDN博客