一、线程之间是并发执行的,是抢占式随机调度的。
多个线程之间是并发执行的,是随机调度的。我们只能确保同一个线程中代码是按顺序从上到下执行的,无法知道不同线程中的代码谁先执行谁后执行。
比如下面这两个代码:
代码一:
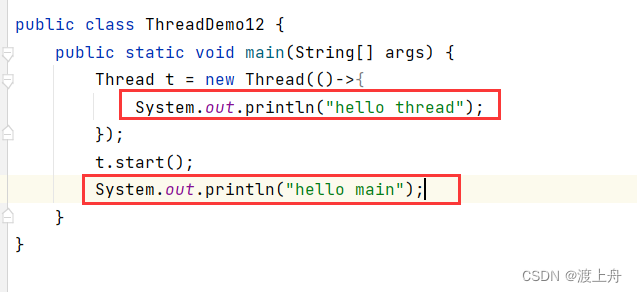
这俩红框框打印的顺序是随机的。
主线程调用start,创建一个线程,是主线程先接着往下执行代码,还是线程先执行run中的代码,这是随机的,看哪行代码先在CPU上调度,就先执行哪行代码。
代码二:

运行结果:
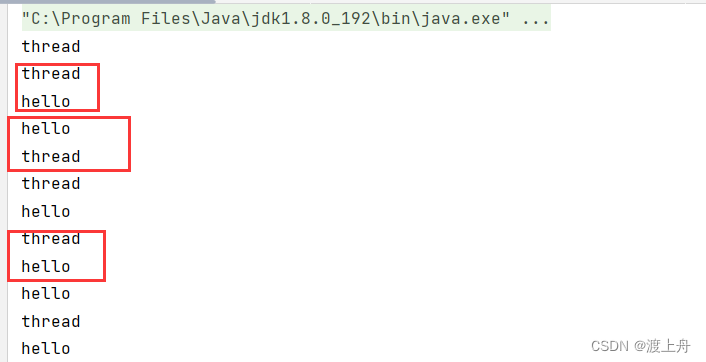
主线程先sleep休眠1秒,这时线程趁着主线程休眠,打印thread,然后也进入sleep休眠1秒
主线程和线程谁会先从sleep中醒过来是不确定的。醒来后会回到就绪队列,等待CPU调度。CPU调度是随机的,谁先被调度谁先执行下一行代码。也就是说,控制台输出的结果,是hello在前,还是thread在前,是不确定的。完全看调度器的调度结果。哪行代码先被调度执行先输出哪个结果。
观察运行结果我们发现,有时是thread hello,有时是 hello thread,谁先打印很随机,不可预期。
二、一段出现线程安全问题的代码
什么样的代码会产生线程安全问题呢?
我们来看一下。
创建两个线程,分别对同一个对象(new Counter())的属性(count)进行5w次的自增,打印这个属性的值。我们的预期结果是:属性的值是10_0000
代码如下:
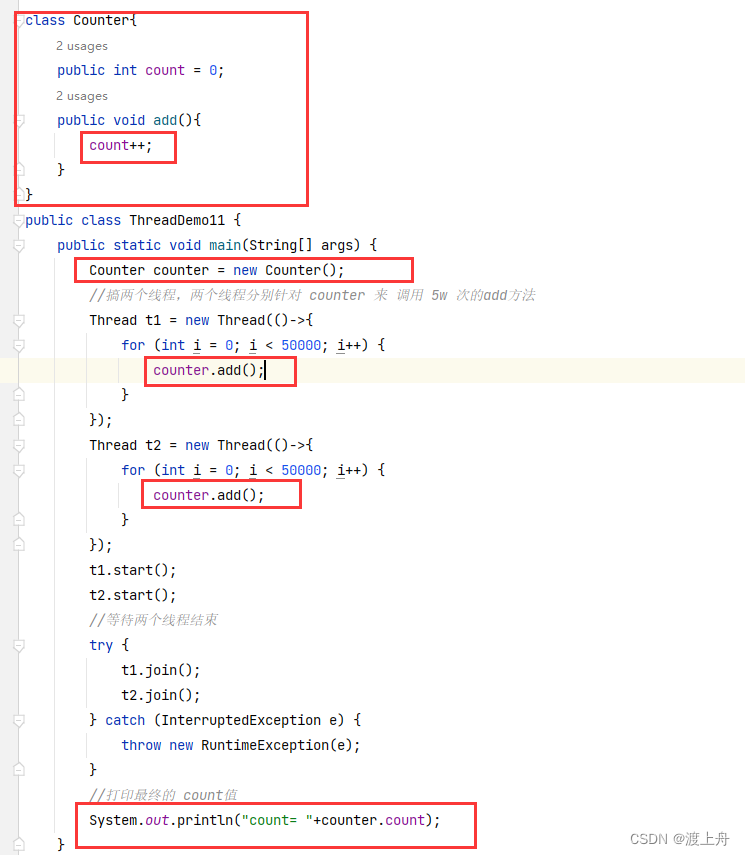
运行结果如下:
![]()
![]()
![]()
我们发现,
结果很随机,每次都不同,但不是10_0000,说明代码出现了bug,出现了线程安全问题。
 这段代码为什么会出现线程安全问题呢?
这段代码为什么会出现线程安全问题呢?
问题就出现在 count++ 这个代码上。
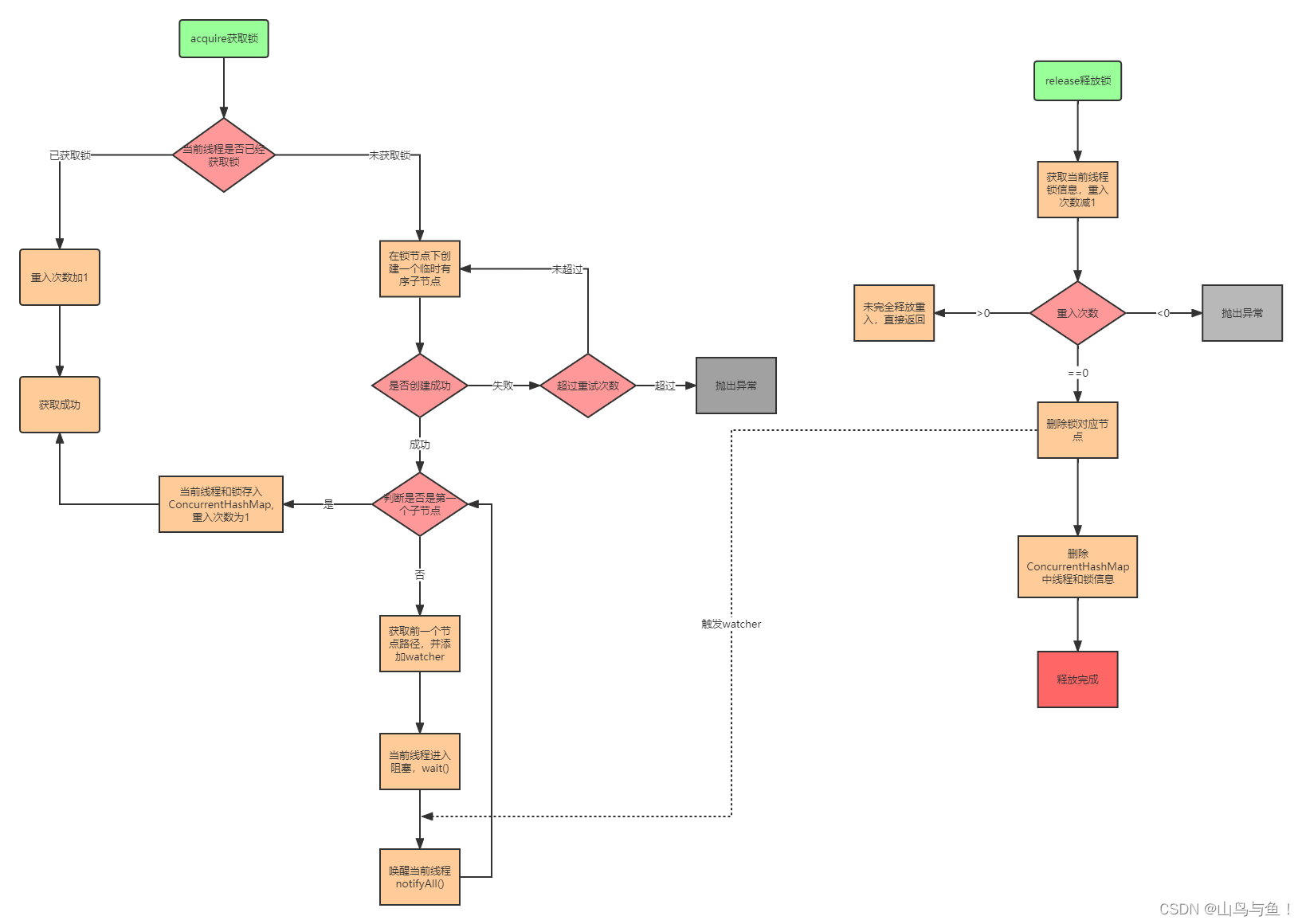
一个线程具体要执行,需要先编译成很多的CPU指令。可以这样理解,一个线程是完成某个任务,这个任务可以拆分成一个一个的小步骤,每个小步骤就是一个指令。CPU调度时只认得指令,它不认识count++这个操作。(指令:可以视为机器语言,由0和1组成。 load,add,save这些相当于汇编指令,比机器指令好记,和机器指令是一一对应的,通过编译器可以将汇编指令转换成机器指令。不同的CPU会支持不同的机器指令,load,add,save这三个操作是CPU中已经支持的指令)
count++操作本质上要分成3步:
1、先把内存中的值,读取到CPU的寄存器中(load)
2、把CPU寄存器里的数值进行 +1 运算(add)
3、把得到的结果写回内存中(save)
load,add,save这三个操作,就是CPU上执行的3条指令。
就拿我们写的其中的一部分代码举例,
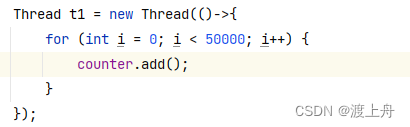
上面这个代码要执行就需要编译成很多CPU指令:
 本质上是 cmp指令
本质上是 cmp指令
![]() 方法调用,是 call指令
方法调用,是 call指令
 load、add、save这三条指令
load、add、save这三条指令
![]() 针对 i 的load、add、save这三条指令
针对 i 的load、add、save这三条指令
那为什么说count++操作本质上要分成三条指令,就导致了线程安全问题呢?
我们已经知道,count++最终落实到CPU上执行,会分成这三个指令来去执行(load、add、save),那么,如果是两个线程并发的执行count++,此时就相当于两组 load add save 进行执行。由于线程的抢占式执行,导致当前执行到任意一个指令的时候,线程都有可能被调度走,CPU让别的线程来执行,正是这样的切换,导致会出现不同的线程调度顺序,出现线程安全问题。(哪个线程中的count++先执行是随机的。调度一次执行到了这个count++哪个指令也是随机的。)
调度顺序会出现无数种可能性,下面列出几种:
(1)load、add、save 是一起的,都执行完才被调度走
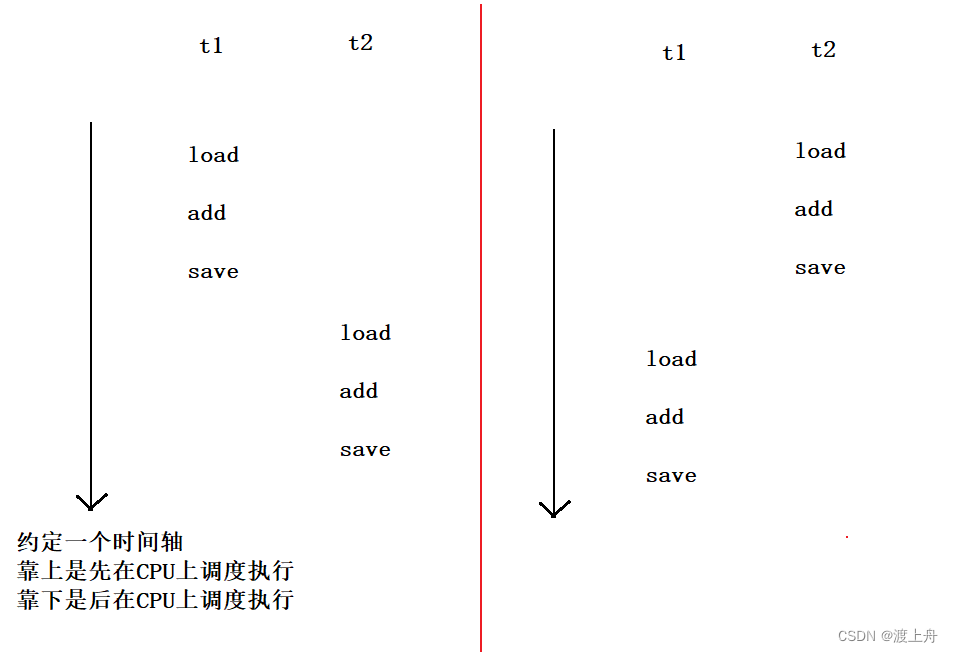
(2)执行到任意一个指令,线程都有可能被调度走,CPU去执行别的线程,过一会又回来接着执行这个线程了

(3)左:两个CPU某一时刻同时调度到了两个线程的相同指令;右:一个线程才执行完load,另一个线程已经执行好几轮load、add、save操作了
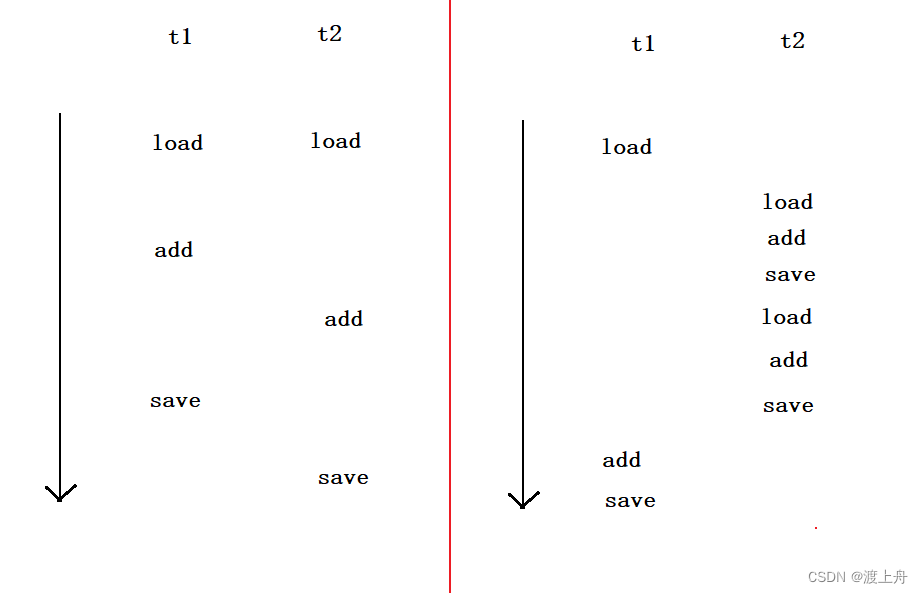
这些不同的调度顺序,产生了不同的结果。

比如说,  ,如果是这个顺序,我们来分析一下是怎么执行的。
,如果是这个顺序,我们来分析一下是怎么执行的。
为了方便画图,我们假设线程t1 只会被左边那个CPU调度,线程t2 只会被右边那个CPU调度(真正在你的电脑上跑这串代码,肯定是可以被你电脑上任意CPU调度的。)

第一步:load —— 把内存中的值加载到CPU的寄存器中(CPU里有个重要的组成部分,寄存器。CPU里进行的运算都是针对寄存器里的数据进行的,也就是说,CPU不能直接操作内存)
于是,第一个CPU寄存器中存了个 0
第二步:add —— CPU寄存器里的数值进行+1运算
于是,第一个CPU寄存器里的值变为1
第三步:save —— 得到的结果写回内存中
于是,内存中的值变为1
第四步:load —— 把内存中的值加载到CPU的寄存器中
于是,第二个CPU寄存器中存了个1
第五步:add —— CPU寄存器里的数值进行+1运算
于是,第二个CPU寄存器里的值变为2
第六步:save —— 得到的结果写回内存中
于是,内存中的值变为2
count自增2次,结果为2,符合预期。
我们再来看另一种可能的调度顺序, ,如果是这个顺序,我们来分析一下是怎么执行的。
,如果是这个顺序,我们来分析一下是怎么执行的。
第一步:load —— 把内存中的值加载到CPU的寄存器中
于是,第二个CPU寄存器中存了个0
第二步:load —— 把内存中的值加载到CPU的寄存器中
于是,第一个CPU寄存器中也存了个 0
第三步:add —— CPU寄存器里的数值进行+1运算
于是,第二个CPU寄存器里的值变为1
第四步:save —— 得到的结果写回内存中
于是,内存中的值变为1
第五步:add —— CPU寄存器里的数值进行+1运算
于是,第一个CPU寄存器里的值变为1
第六步:save —— 得到的结果写回内存中
于是,内存中的值变为1
count自增2次,结果为1,不符合预期。 线程t1 load的值,是线程t2修改之前的值,t1 读到了 t2 还没save 的数据。于是出现问题。
也就是说,只要其中一个线程读到了另一个线程还没save 的数据,结果就会出问题。
这么多种调度顺序,,只有这两种情况是满足不会读到还没save 的数据的。所以,只有两个线程每次的调度顺序都是这两种,才会打印10_0000。这种概率非常非常小。输出结果基本上都是小于10_0000。
那么结果一定会大于5_0000吗?
不一定。也有可能出现 ,一个线程才执行完load,另一个线程已经执行好几轮load、add、save操作了 这种情况。这就是,count自增好几次,结果为1了。
,一个线程才执行完load,另一个线程已经执行好几轮load、add、save操作了 这种情况。这就是,count自增好几次,结果为1了。
所以,这段代码一定会出现线程安全问题,且结果很随机。
三、出现线程安全问题的原因
为什么会产生线程安全问题呢?
1、根本原因:操作系统是抢占式执行,随机调度的。
2、代码结构:多个线程同时修改同一个变量。(上述代码中,两个线程修改同一个变量count。出现线程安全问题的概率非常大。)
- 一个线程,修改一个变量,没事
- 多个线程,同时读取同一个变量,没事
- 多个线程,同时修改不同的变量,也没事
3、原子性:修改操作不是原子性的。如果修改的操作是原子的,出现线程安全问题的概率比较小。如果是非原子的,出现线程安全问题的概率就非常大了。(原子:不可拆分的基本单位。单个指令就是原子的。上述代码中,count++可以拆分成load、add、save这三个指令,所以count++不是原子的,出现线程安全问题的概率非常大。)
4、内存可见性问题:如果是一个线程读取,一个线程修改,也可能出现线程安全问题,读取的结果不符合预期。
5、指令重排序:编译器对你写的代码进行优化,保证逻辑不变的情况下,进行调整,来加快程序的执行效率。调整时,可能会调整代码的执行顺序,从而可能会出现线程安全问题。
上述是5个典型的线程安全问题的原因,但并不是全部。
一个代码究竟线程安全不安全,要具体问题具体分析。如果一个代码踩中了上面的原因,也可能线程安全。如果一个代码没踩中上面的原因,也可能线程不安全。
要结合原因,结合需求,具体问题具体分析。多线程运行代码,只要不出bug,就是线程安全的。
四、如何解决线程安全问题?
根据 出现线程安全问题的原因,从中入手解决线程安全问题。
我们可以通过调节代码结构来规避线程安全问题。
但是代码结构也是来源于需求的,不一定就能调整。是方案没错,但普适性不是特别强。
最主要的解决线程安全问题的方法就是从原子性入手。把非原子的操作变成 “原子” 的。
就比如上面那段出现线程安全问题的代码,
正是因为 count++操作不是原子的,本质上要分成load、add、save这三条指令,当两个线程并发的执行count++时,就相当于两组 load add save 进行执行。由于线程的抢占式执行,导致当前执行到任意一个指令的时候,线程都有可能被调度走,CPU让别的线程来执行,正是这样的切换,导致会出现不同的线程调度顺序,后一个线程 读到了 还没save 的数据,出现线程安全问题。
我们从原子性入手,就非常好解决了。只要 把count++这个非原子操作,变成 “原子” 的,保证线程的load、add、save 3个操作都执行完才会被调度走,让后一个线程读到的是 save过 的数据,问题就解决了。
如何把非原子的操作变成 “原子” 的呢?
通过 synchronized关键字 加锁。
synchronized
synchronized 是一个关键字,表示加锁。要明确锁对象,是对 对象进行加锁!!!
synchronized 的使用方法:
1、修饰方法:(1)修饰普通方法(2)修饰静态方法
2、修饰代码块
虽然 synchronized 修饰方法和代码块,但锁不是加到方法或其他上面,是线程对对象加锁,加锁是给对象加锁,一定要明确锁对象是哪个!!!
- 修饰普通方法:锁对象是this
- 修饰静态方法:锁对象是类对象(Counter.class)
- 修饰代码块:手动指定锁对象
加锁的规则: (就3条,很简单,不要自己加戏)
1、如果两个线程针对同一个对象加锁,会出现锁冲突/锁竞争,一个线程能够获取到锁(先到先得),另一个线程只能阻塞等待(BLOCKED),一直阻塞到上一个线程释放锁(解锁),它才能获取锁(加锁)成功。【注:另一个线程对这个对象加锁不成功,线程阻塞。但不代表这个锁对象不能用,还是可以获取锁对象的属性,调用锁对象的没加锁的方法的。只能说线程阻塞了,不能说对象不能用了。这两个概念不一样。】
2、如果两个线程针对不同的对象加锁,不会出现锁冲突/锁竞争。这俩线程都能获取到各自的锁,不会有阻塞等待了。
3、如果两个线程,一个线程加锁,一个线程不加锁,也不会出现锁冲突/锁竞争。
对 synchronized 的使用方法进行分别介绍
1、修饰普通方法
进入方法就加锁,出了方法就解锁。锁对象是this,谁调用这个方法谁就是this
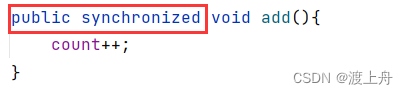
比如通过 synchronized关键字 修饰 add方法,进入add方法就加锁,出了add方法就解锁。以此来把 方法中count++变成 “原子的” 。
synchronized关键字 可以放在public前,也可以放在public后,下面两种都可以。

加了 synchronized关键字 后,我们再来看一下这个调度顺序,,会不会发生改变呢?
肯定会的。


如上,
(1)首先,加了 synchronized关键字 后,load前面和save后面会多个lock(加锁) 和 unlock(解锁)操作。
(2)线程t2 进入add方法,对counter 进行加锁(counter调用add方法,counter就是this,就是锁对象),接着往下执行load,此时 t1也想去加锁,不好意思,加锁不能成功,只能阻塞等待。
(3)一直等到 t2 unlock 之后,t1才可能lock成功。
t1 加锁的阻塞等待,就把 t1的load 推迟到 t2的save之后,t1读到的就是t2 save过 的数据。这就避免了线程安全问题,输出的结果就是符合预期的 10_0000啦。
加锁,保证了 “原子性” ,避免了线程安全问题。当然,这不是说,load、add、save这三个操作就必须一次性完成。执行到任意一个指令的时候,线程都有可能被调度走,过一会再被调度回来继续往下执行。虽然线程这会儿没在CPU上执行,但只要这个线程没有释放锁,其他线程想要获取锁就只能阻塞等待。
加锁之后,代码的执行速度会变慢,(因为多了加锁和解锁的操作),但还是要比单线程要快的。比如,上述代码,线程t1和线程t2 只有调用add方法时,才会加锁,只能串行。其余for循环这里的比较和自增操作,又不需要加锁,是可以并发执行的。一个任务中,一部分并发,一部分串行,仍然比所有代码都串行要快。
为啥红框框部分可以并发执行,没有线程安全问题?
因为这里的 i 是局部变量,t1 和 t2线程中各自都有,t1 和 t2线程各自修改各自的局部变量,完全不会出现问题。
2、修饰静态方法
进入方法就加锁,出了方法就解锁。锁对象是类对象


上述例子的锁对象是 Counter.class
3、修饰代码块
进入代码块就加锁,出了代码块就解锁。手动指定锁对象。
用修饰代码块这个使用方法,来举个
如果两个线程,一个线程加锁,一个线程不加锁,也不会出现锁冲突/锁竞争
的例子:


synchronized(this){ } 在小括号里 手动指定锁对象
这里指定的锁对象是this。 t1线程对 counter 加锁,t2线程 没对 counter 加锁。就不会出现锁竞争,不会阻塞等待。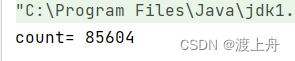 运行结果不符合预期。
运行结果不符合预期。
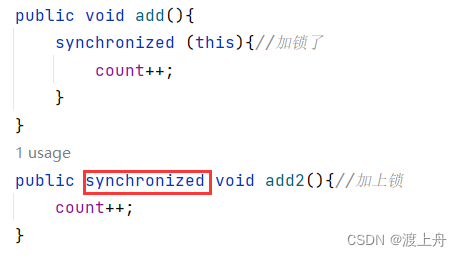
如果给 t2线程也给 counter加锁,那么就属于两个线程针对同一个对象counter加锁,就会出现锁竞争,只有一个线程能获取到锁,另一个线程只能阻塞等待(BLOCKED)。 运行结果符合预期。
运行结果符合预期。
synchronized是可重入锁
一个线程针对同一个对象连续加锁多次,没问题就是可重入的。有问题,就是不可重入。
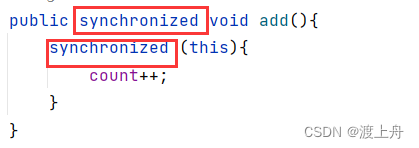

如上代码,可以看出 synchronized是可重入的。
具体的解释:
锁对象是this,只要有线程调用add,进入add方法的时候,就会先加锁,假如此时能够加锁成功,接着代码往下执行,会遇到代码块,再次尝试加锁。
站在锁对象的视角,它认为自己已经被线程给占用了。那会不会让第二个线程阻塞等待呢?
synchronized 能检查出两个线程是同一个,允许加锁。可重入。
如果不允许加锁,会阻塞等待,那就是不可重入。
总结:
无论这个对象是个啥样的对象,原则就一条,看锁对象相不相同。
锁对象相同,就会产生锁竞争(产生阻塞等待);
锁对象不同,就不会产生锁竞争(不会产生阻塞等待);