目录:Mask R-CNN论文解读
- 一、Mask-RCNN流程
- 二、Mask-RCNN结构
- 2.1 ROI Pooling的问题
- 2.2 ROI Align
- 三、ROI处理架构
- 四、损失函数
一、Mask-RCNN流程
Mask R-CNN是一个实例分割(Instance segmentation)算法,通过增加不同的分支,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务,灵活而强大。
Mask R-CNN进行目标检测与实例分割:

Mask R-CNN进行人体姿态识别:

其抽象架构如下:
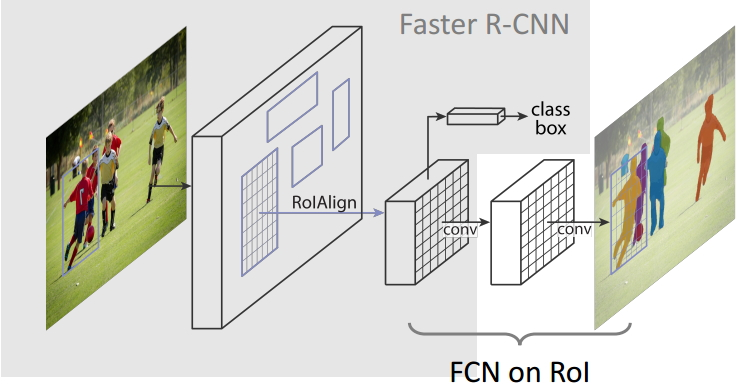
- 首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
- 接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI(截止到目前,Mask和Faster完全相同,其实R-FCN之类的在这之前也没有什么不同);
- 接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来)(ROIAlign为本文创新点1,比ROIPooling有长足进步);
- 最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)(引入FCN生成Mask为本文创新点2,使得本文结构可以进行分割型任务)。
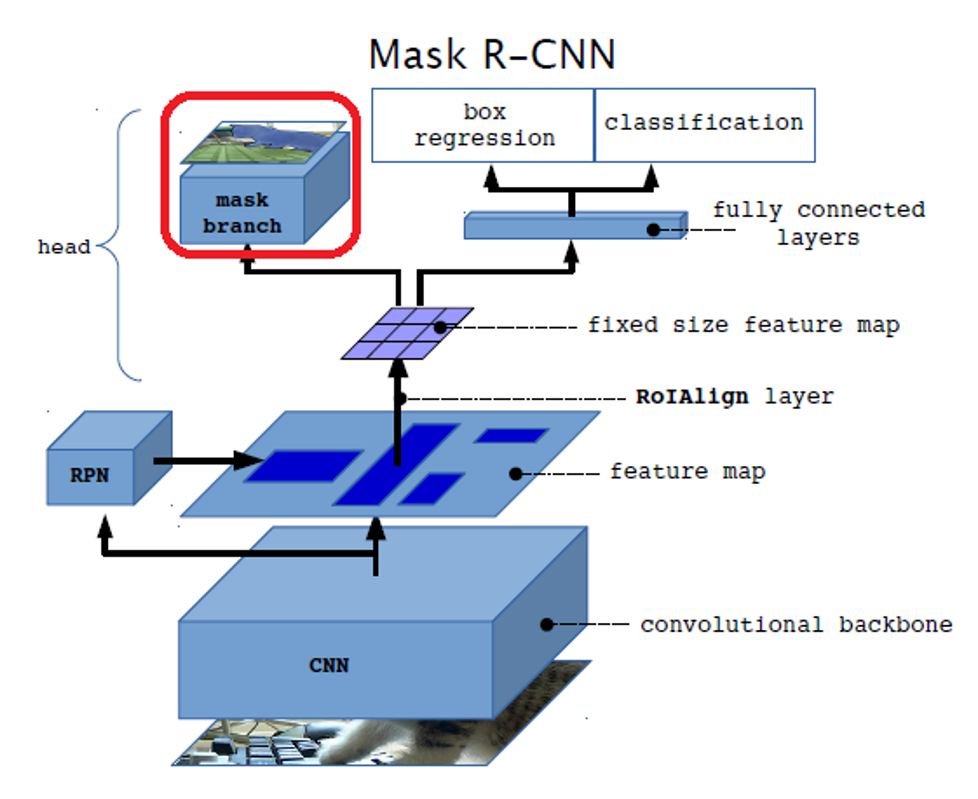
【注】有关MASK部分,还有一处容易忽视的创新点3:损失函数的计算,作者放弃了更广泛的softmax,转而使用了sigmoid,避免了同类竞争,更多的经历放在优化mask像素上。
二、Mask-RCNN结构
2.1 ROI Pooling的问题
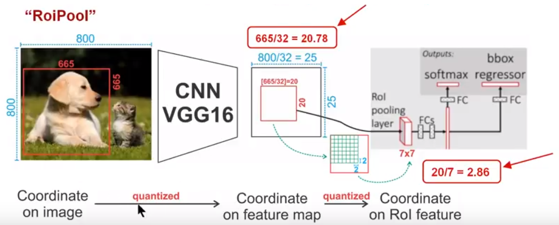
假定我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,获得的feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关:
在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,取整变为20 x 20,在这里引入了第一次的量化误差;
然后我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,同样的取整,在这里引入了第二次量化误差。
这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2,86,我们将其量化为2,这期间引入了0.86的feature空间误差,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52(这仅仅考虑了第二次的量化误差)。
2.2 ROI Align
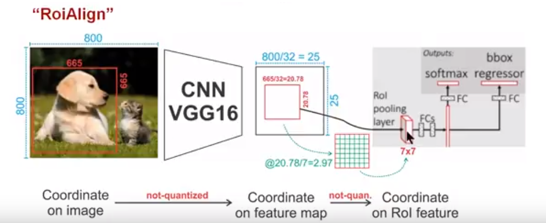
为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,取而代之的使用了双线性插值,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
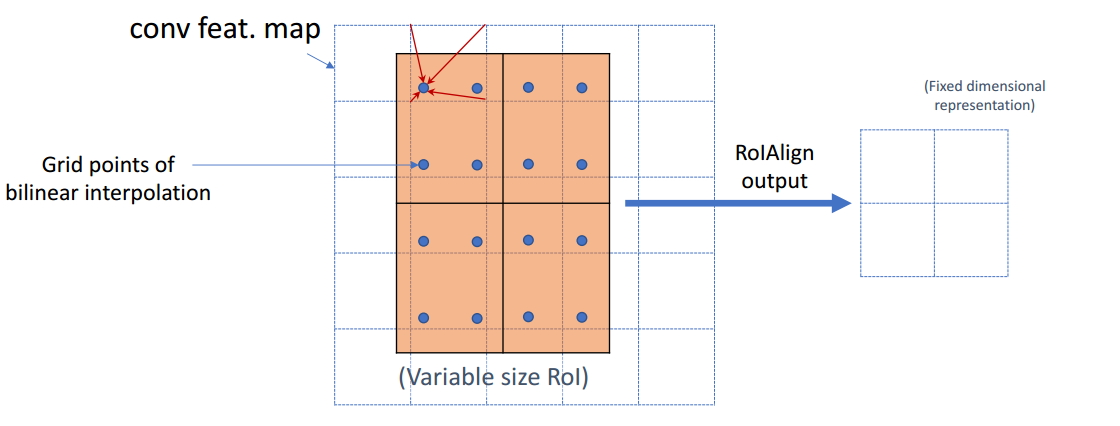
蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。
然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
三、ROI处理架构
为了证明我们方法的通用性,我们构造了多种不同结构的Mask R-CNN。详细的说,我们使用不同的:
(i)用于整个图像上的特征提取的卷积主干架构;
(ii)用于边框识别(分类和回归)和掩模预测的上层网络,分别应用于每个RoI。
我们使用术语“网络深层特征”来命名下层架构。我们评估了深度为50或101层的ResNet [14]和ResNeXt [34] 网络。使用ResNet [14]的Faster R-CNN从第四级的最终卷积层提取特征,我们称之为C4。例如,使用ResNet-50的主干架构由ResNet-50-C4表示。这是[14,7,16,30]中常用的选择。
我们也探索了由Li[21]等人最近提出的另一种更有效主干架构,称为特征金字塔网络(FPN)。FPN使用具有横向连接(lateral connections )的自顶向下架构,从单一规模的输入构建网络功能金字塔。使用FPN的Faster R-CNN根据其尺度提取不同级别的金字塔的RoI特征,不过其他部分和平常的ResNet类似。使用ResNet-FPN主干架构的Mask R-CNN进行特征提取,可以在精度和速度方面获得极大的提升。有关FPN的更多细节,读者可以参考[21]。
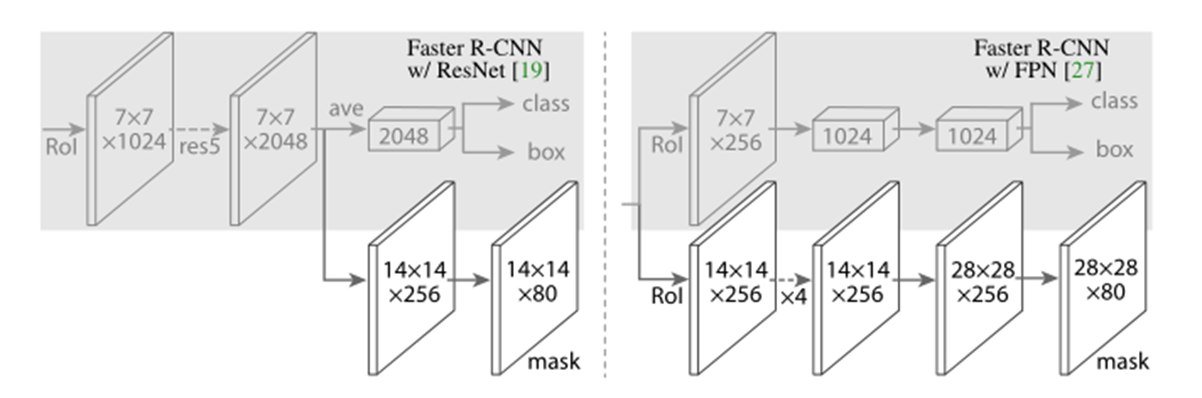
对于上层网络,我们基本遵循了以前论文中提出的架构,我们添加了一个全卷积的掩模预测分支。具体来说,我们扩展了ResNet [14]和FPN[21]中提出的Faster R-CNN的上层网络。详情见下图(图3)所示:(上层架构:我们扩展了两种现有的Faster R-CNN上层架构[14,21],并分别添加了一个掩模分支。左/右面板分别显示了ResNet C4和FPN主干的上层架构。图中数字表示通道数和分辨率,箭头表示卷积、反卷积和全连接层(可以通过上下文推断,卷积减小维度,反卷积增加维度。)所有的卷积都是3×3的,除了输出层是1×1。反卷积是2×2,其步进为2,我们在隐藏层中使用ReLU[24]。在左图中,“res5”表示ResNet的第五级,简单起见,我们修改了第一个卷积操作,使用7×7,步长为1的RoI代替14×14,步长为2的RoI[14]。右图中的“×4 ”表示堆叠的4个连续的卷积。)ResNet-C4主干的上层网络包括ResNet的第5阶段(即9层的’res5’[14]),这是计算密集型的。但对于FPN,其主干已经包含了res5,因此可以使上层网络包含更少的卷积核而变的更加高效。
重点在于:作者把各种网络作为backbone进行对比,发现使用ResNet-FPN作为特征提取的backbone具有更高的精度和更快的运行速度,所以实际工作时大都采用右图的完全并行的mask/分类回归。
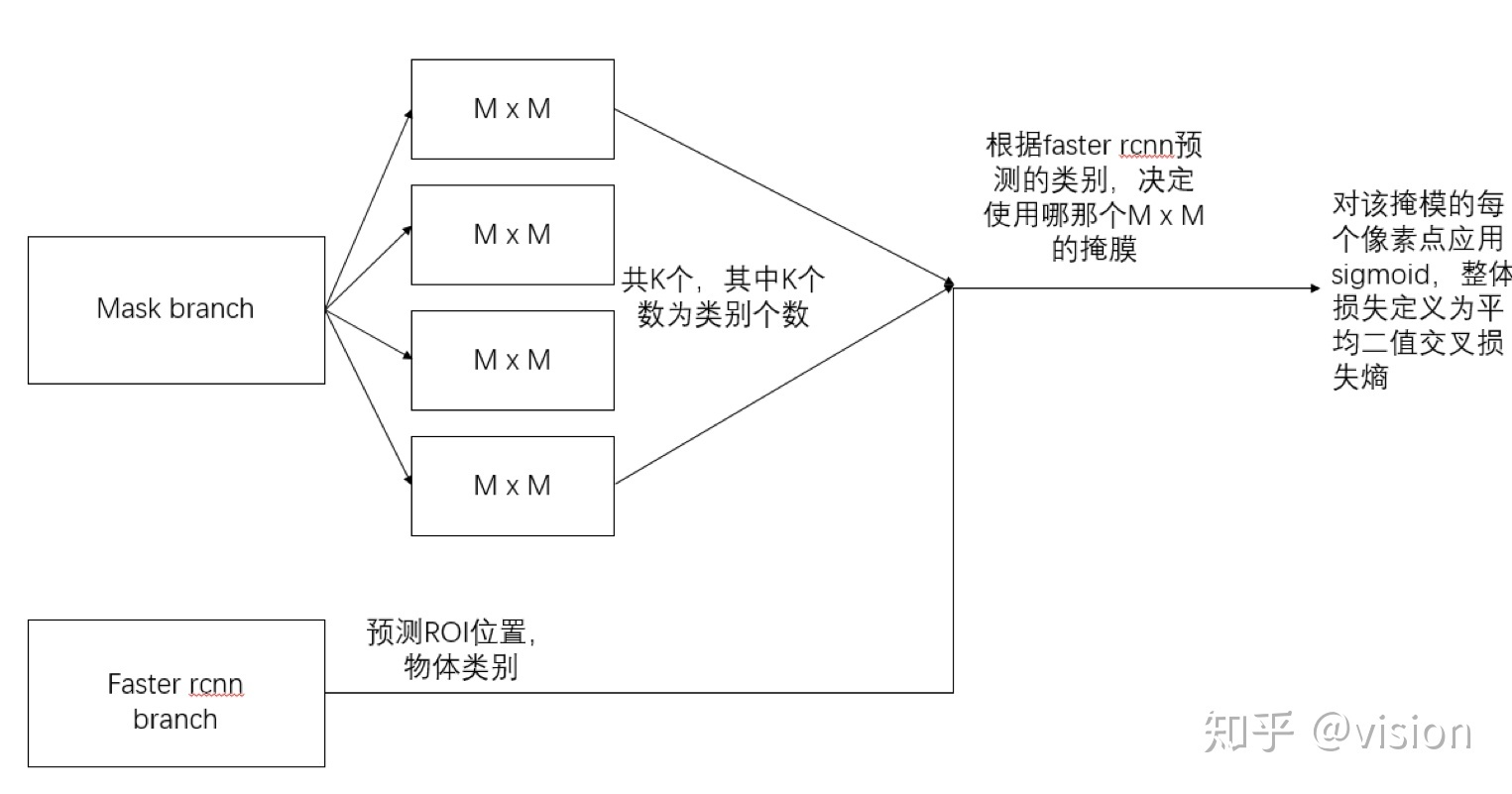
四、损失函数

对于预测的二值掩膜输出,我们对每个像素点应用sigmoid函数,整体损失定义为平均二值交叉损失熵。引入预测K个输出的机制,允许每个类都生成独立的掩膜,避免类间竞争。这样做解耦了掩膜和种类预测。不像FCN的做法,在每个像素点上应用softmax函数,整体采用的多任务交叉熵,这样会导致类间竞争,最终导致分割效果差。