目录
Zookeeper分布式队列
普通方式实现
设计思路
具体实现
使用Curator实现
具体实现
注意事项
Zookeeper分布式队列
常见的消息队列有:RabbitMQ,RocketMQ,Kafka等。Zookeeper作为一个分布式的小文件管理系统,同样能实现简单的队列功能。Zookeeper不适合大数据量存储,官方并不推荐作为队列使用,但由于实现简单,集群搭建较为便利,因此在一些吞吐量不高的小型系统中是比较好用的。
普通方式实现
设计思路
1.创建队列根节点
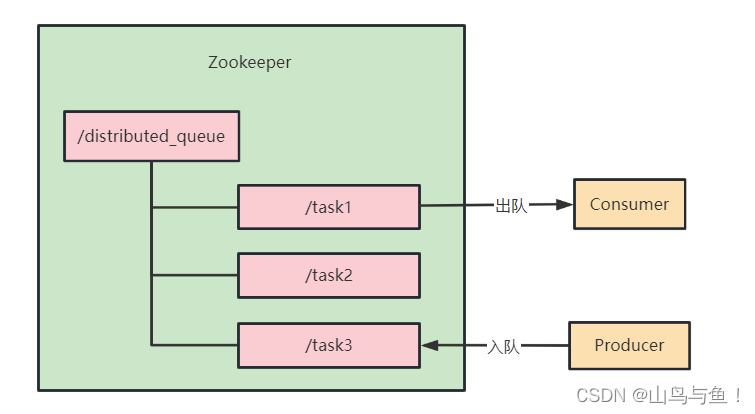
在Zookeeper中创建一个持久节点,用作队列的根节点。所有队列元素的节点将放在这个根节点下。
2.实现入队操作
当需要将一个元素添加到队列时,可以在队列的根节点下创建一个临时有序节点。节点的数据可以包含队列元素的信息。
3.实现出队操作
当需要从队列中取出一个元素时,先获取根节点下的所有子节点。再找到具有最小序号的子节点,获取该节点的数据,删除该节点,然后返回节点的数据。
具体实现
/**
* 入队
* @param data
* @throws Exception
*/
public void enqueue(String data) throws Exception {
// 创建临时有序子节点
zk.create(QUEUE_ROOT + "/queue-", data.getBytes(StandardCharsets.UTF_8),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
/**
* 出队
* @return
* @throws Exception
*/
public String dequeue() throws Exception {
while (true) {
List<String> children = zk.getChildren(QUEUE_ROOT, false);
if (children.isEmpty()) {
return null;
}
Collections.sort(children);
for (String child : children) {
String childPath = QUEUE_ROOT + "/" + child;
try {
byte[] data = zk.getData(childPath, false, null);
zk.delete(childPath, -1);
return new String(data, StandardCharsets.UTF_8);
} catch (KeeperException.NoNodeException e) {
// 节点已被其他消费者删除,尝试下一个节点
}
}
}
}使用Curator实现
Curator是一个ZooKeeper客户端的封装库,提供了许多高级功能,包括分布式队列。
具体实现
public class CuratorDistributedQueueDemo {
private static final String QUEUE_ROOT = "/curator_distributed_queue";
public static void main(String[] args) throws Exception {
CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181",
new ExponentialBackoffRetry(1000, 3));
client.start();
// 定义队列序列化和反序列化
QueueSerializer<String> serializer = new QueueSerializer<String>() {
@Override
public byte[] serialize(String item) {
return item.getBytes();
}
@Override
public String deserialize(byte[] bytes) {
return new String(bytes);
}
};
// 定义队列消费者
QueueConsumer<String> consumer = new QueueConsumer<String>() {
@Override
public void consumeMessage(String message) throws Exception {
System.out.println("消费消息: " + message);
}
@Override
public void stateChanged(CuratorFramework curatorFramework, ConnectionState connectionState) {
}
};
// 创建分布式队列
DistributedQueue<String> queue = QueueBuilder.builder(client, consumer, serializer, QUEUE_ROOT)
.buildQueue();
queue.start();
// 生产消息
for (int i = 0; i < 5; i++) {
String message = "Task-" + i;
System.out.println("生产消息: " + message);
queue.put(message);
Thread.sleep(1000);
}
Thread.sleep(10000);
queue.close();
client.close();
}
}注意事项
使用Curator的DistributedQueue时,默认情况下不使用锁。当调用QueueBuilder的lockPath()方法并指定一个锁节点路径时,才会启用锁。如果不指定锁节点路径,那么队列操作可能会受到并发问题的影响。
在创建分布式队列时,指定一个锁节点路径可以帮助确保队列操作的原子性和顺序性。分布式环境中,多个消费者可能同时尝试消费队列中的消息。如果不使用锁来同步这些操作,可能会导致消息被多次处理或者处理顺序出现混乱。如果应用场景允许消息被多次处理,或者处理顺序不是关键问题,那么可以不使用锁。这样可以提高队列操作的性能,因为不再需要等待获取锁。
// 创建分布式队列
QueueBuilder<String> builder = QueueBuilder.builder(client, consumer, serializer, "/order");
//指定了一个锁节点路径/orderlock,用于实现分布式锁,以保证队列操作的原子性和顺序性。
queue = builder.lockPath("/orderlock").buildQueue();
//启动队列,这时队列开始监听ZooKeeper中/order节点下的消息。
queue.start();