1、写作动机:
最近的研究提出了基于大型语言模型的方法,以统一地建模不同的信息提取任务。然而,这些现有方法在处理英语以外的中文语言的信息提取能力方面存在不足。
2、主要贡献:
提出了YAYI-UIE,一个端到端的聊天增强指令调优框架,用于通用信息提取,支持中文和英文。
3、主要方法:
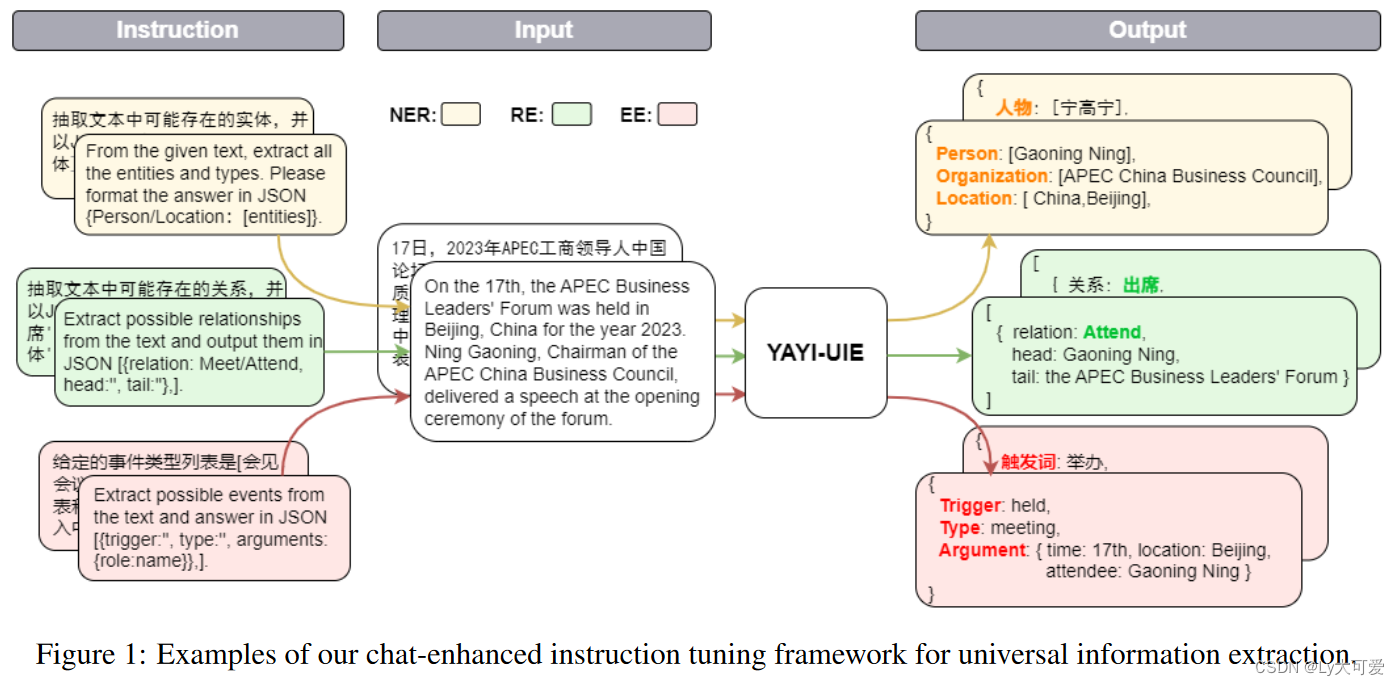

两步指令微调:
第一步:
在构建的对话语料库上对基础LLM进行微调,以获得可以聊天的LLM:
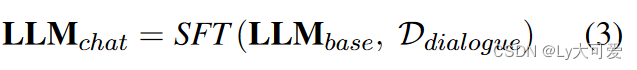
Ddialogue= instruction + input +output
第二步:
从不同领域收集了16个中文数据集,用于NER、RE和EE任务,构建了一个全面的中文指令基准,并将其与现有的英文基准IE INSTRUCTIONS相结合。
4、实验:
4.1监督实验
模型:baichuan
数据集:事件抽取方面用的是DUEE(中文)、DuEE-1.0(中文)、ACE2005等
baseline:
- UIE是一个统一的文本到结构生成框架,通过基于模式的提示生成目标提取。
- USM是一个统一的IE任务框架,将IE任务转换为语义匹配问题。
- InstructUIE是一个基于多任务指令微调的统一信息提取框架。(复旦提出,基于LLM,InstructUIE只具有英文能力)
- BERT-base(Kenton和Toutanova,2019)指的是基于预训练语言模型BERT的具有最先进结果的任务特定监督模型,已广泛应用于各种任务作为文本编码器。
结果:
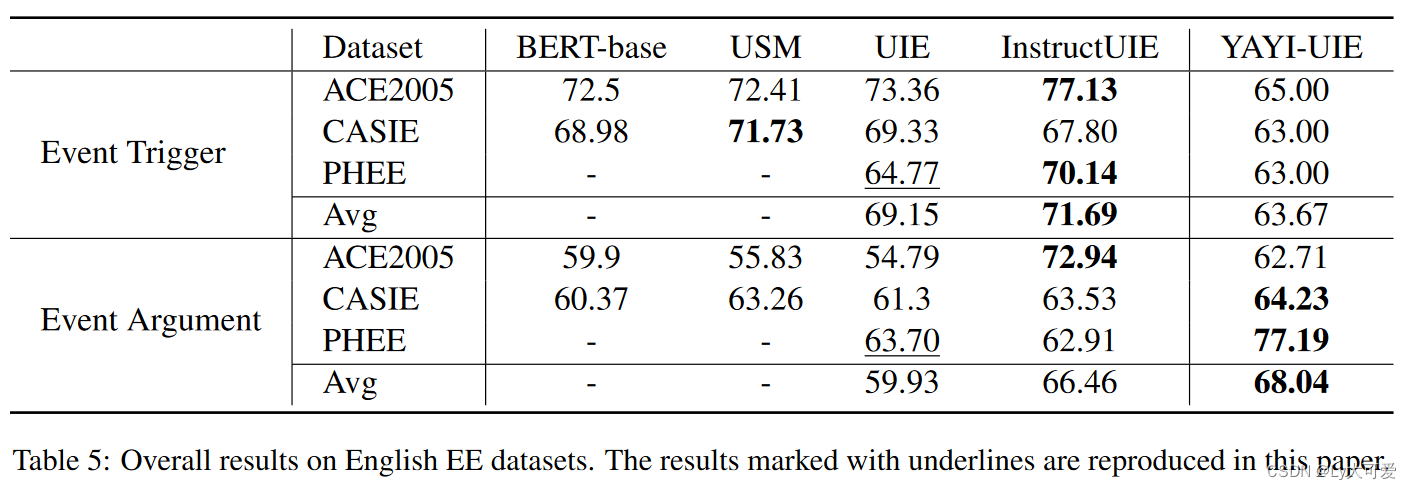

4.2零样本实验
数据集:Commodity News Corpus、FewFC、CCF law 4
baseline:
- ZETT是一个从非结构化文本中提取关系三元组的新型框架。ZETT在零样本任务中尤其高效,因为该框架将三元组提取简化为一个模板填充任务,然后基于模板生成既适用于已见数据又适用于未见数据的三元组。
- ChatGPT
- ChatGLM是一个开源的、中英文双语的对话语言模型,基于通用语言模型(GLM)的架构。
- KnowLM一个开源且可扩展的知识图谱抽取工具,可以实现命名实体识别和关系抽取等任务,并支持指令遵循以及自定义类型和格式。
实验结果: