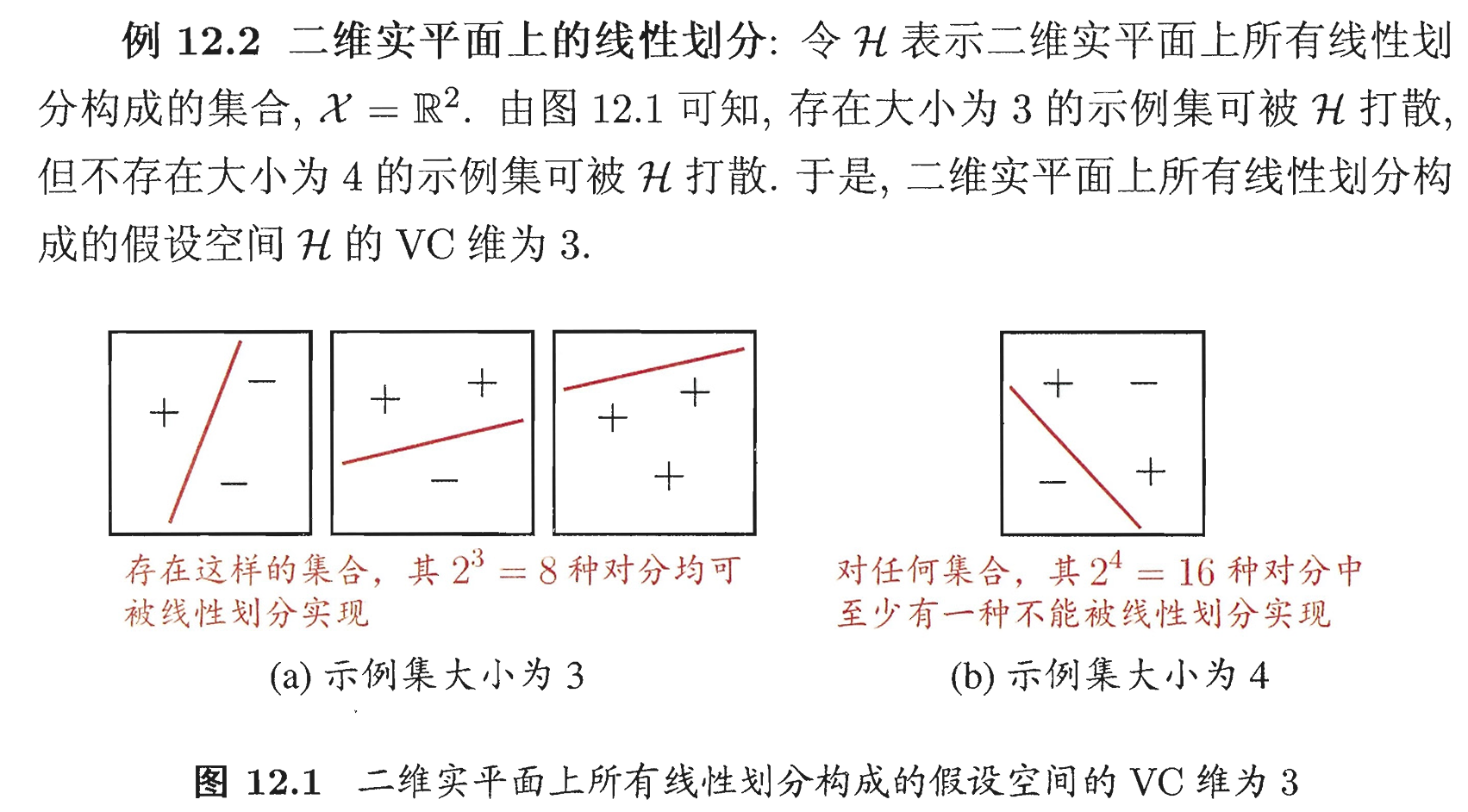
哈希算法
哈希,是一种算法思想吗,它的核心是映射,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
在STL 中,提供了两个使用哈希底层实现的容器 unordered_set 和 unordered_map,unordered是无序的意思。它们存储数据的方式类似于 set 和 map,但缺少了排序的功能。在性能测试中,debug 环境下,unordered_set 和 unordered_map性能都是优于set和map 的,只有在 release 环境并且插入数据有序的情况下,set和map的性能才略微更优一点。
因为map和set的底层是红黑树,如果数据有序,那么红黑树就会一直往左边或右边插入节点,反复旋转(旋转被release 给优化了),导致红黑树建立后变得相对均衡了很多。查找、删除就变得更高效了。
总体来说,在不排序的情况下,unordered_map和unordered_set对于普通数存储数据处理的效率较好一些。

直接定址法
- hashi = key % len
每个数据的 key 与位置之间建立一个关系,通过除留余数法计算出每个 key 对应得 hashi,这个方法也是计数排序的思想。

但直接定址法会有问题,可能会出现一些问题:不同的值映射到相同的位置上去。这种现象叫哈希冲突或哈希碰撞
开放定址法
开放定址法也叫闭散列,适用于当前位置被占用,开放空间里面按照某种规则,找一个没被占用的位置存储。
一般有线性探测和二次探测这两种
- 线性探测:hashi + i (i >= 0)
- 二次探测:hashi + i ^ 2 (i >= 0)
负载因子(空间占有率)= 存储数据的个数 / 空间大小,闭散列的负载因子一般是小于等于 0.7。负载因子太大会导致冲突增加;太小虽然会减少冲突,但会导致空间利用率降低。
使用开放定址法实现哈希表
使用 vector 来建立哈希表,每个位置中存储一个类对象。这个类对象中包含两个变量参数,一个是哈希表中需要存储的数据类型,另一个是这个位置的状态:EMPTY(空)、EXIST(有数据)、DELETE(删除过的),为什么还要设置一个删除状态呢?
有可能删除后,在 find 的时候,之前插入位置的数据已经被删除了,但有些冲突的数据被调到了其他位置,因此遇到 DELETE 状态要继续寻找。
类的定义
定义三个模板参数,K 和 V分别做 pair的参数,再定义一个带缺省参数的仿函数,这个仿函数主要是为了计算 hashi 而准备的。
仿函数分为两个,一个针对整形类型;一个针对字符串类型。
其实并不是针对整形。这种定义方法,是在使用者没有自己定义仿函数的情况下使用的,如果第一个参数 K 传的是除 string 外其他类型,而也没有传仿函数时,就会默认去调用第一个仿函数。
而当第一个参数 K 传的是 string 类型时,就会调用针对 string 的模板特化(特化不能单独存在),这样,当用户传string 类型的参数时,也不用自己显示传仿函数,只需要传 Key 和 Value 即可。当用户需要给 Key 传其他类型的时候,就需要自己调用写函数并调用了。
接口定义
- 插入:先算 hashi,利用除留余数法,如果位置重复就使用线性探测或二次探测来解决问题,状态需要变为 EXIST。当负载因子等于 0.7 的时候,就要进行扩容。
- 扩容:只能进行异地扩容!异地扩容,建立一个新哈希表将原来空间中已经存在数据的位置再在新空间中重新插入,然后将两个哈希表交换即可。新哈希表的空间会在函数结束后自动释放。
- 删除:使用伪删除法。将数据个数减1,将状态变为 DELETE。
- 查找:先使用查找值计算 hashi,然后根据与 hashi 位置的数据与查找值进行比对,判断是否相等,如果不相等,根据线性探测或者二次探测往后依次找。找到了返回存储数据类型的指针,找不到返回空指针。
代码实现
#pragma once
#include<vector>
#include<string>
#include<iostream>
using namespace std;
namespace zyb
{
enum States
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
States _s = EMPTY;
};
template<class K>
struct KeyOfi
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct KeyOfi<string>
{
size_t operator()(const string& key)
{
size_t hashi = 0;
for (size_t i = 0; i < key.size(); i++)
{
hashi *= 31;
hashi += key[i];
}
return hashi;
}
};
template<class K, class V, class Hash= KeyOfi<K>>
class HashTable
{
public:
Hash ky;
HashTable()
{
_tables.resize(10);
}
HashData<K, V>* find(const K& key)
{
size_t hashi = ky(key) % _tables.size();
while (_tables[hashi]._s != EMPTY)
{
if (_tables[hashi]._s == EXIST && _tables[hashi]._kv.first == key)
{
return &_tables[hashi];
}
++hashi;
hashi %= _tables.size();
}
return nullptr;
}
bool erase(const K& key)
{
HashData<K, V>* ret = find(key);
if (ret)
{
ret->_s = DELETE;
_n--;
return true;
}
return false;
}
bool insert(const pair<K, V>& kv)
{
if (find(kv.first))
{
return false;
}
// 平衡因子设置为 0.7
if (_n * 10 / _tables.size() == 7)
{
// 扩容
HashTable<K, V> newht;
newht._tables.resize(2 * _tables.size());
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]._s == EXIST)
{
newht.insert(_tables[i]._kv);
}
}
_tables.swap(newht._tables);
}
size_t hashi = ky(kv.first) % _tables.size();
while (_tables[hashi]._s == EXIST)
{
++hashi;
hashi %= _tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._s = EXIST;
_n++;
return true;
}
void Print()
{
for (int i = 0; i < _tables.size(); i++)
{
if (_tables[i]._s == EXIST)
{
//printf("[%d]->%d\n", i, _tables[i]._kv.first);
cout << "[" << i << "]->" << _tables[i]._kv.first << ":" << _tables[i]._kv.second << endl;
}
else if (_tables[i]._s == EMPTY)
{
printf("[%d]->\n", i);
}
else
{
printf("[%d]->D\n", i);
}
}
cout << endl;
}
private:
vector<HashData<K, V>> _tables;
size_t _n = 0;
};
}