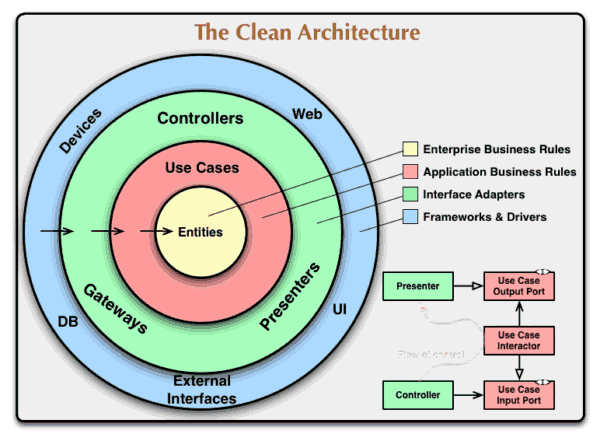
目录
1、209. 长度最小的子数组
2、3. 无重复字符的最长子串
3、1004. 最大连续1的个数 III
4、1658. 将 x 减到 0 的最小操作数
5、904. 水果成篮
6、438. 找到字符串中所有字母异位词
7、30. 串联所有单词的子串
8、76. 最小覆盖子串
1、209. 长度最小的子数组

思路:使用双指针技巧和滑动窗口的思想,通过不断调整左右指针的位置来找到和大于等于目标值的最短子数组的长度。
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size(), sum = 0, len = INT_MAX;
for (int left = 0, right = 0; right < n; right++) {
sum += nums[right];
while (sum >= target) {
len = min(len, right - left + 1);
sum -= nums[left++];
}
}
return len == INT_MAX ? 0 : len;
}
};- 初始化变量
n为数组nums的长度,sum为0(用于记录当前子数组的和),len为INT_MAX(用于记录最短子数组的长度)。 - 使用双指针技巧,初始化左指针
left和右指针right都指向数组的起始位置。 - 进入循环,循环条件是右指针
right小于数组长度。 - 在循环中,将当前元素
nums[right]加到sum中,表示扩展当前子数组。 - 如果
sum大于等于目标值target,则进入内部循环。 - 在内部循环中,更新最短子数组的长度
len,取当前长度right - left + 1和之前的最短长度len的较小值。 - 然后,从当前子数组中减去左指针所指向的元素,并将左指针向右移动一位。
- 重复步骤6和7,直到
sum小于目标值target。 - 返回最短子数组的长度
len,如果len仍然是INT_MAX,则说明没有找到符合条件的子数组,返回0。

2、3. 无重复字符的最长子串

思路:通过数组模拟哈希表,每次遍历到字母时,其ASCII码值对应数组的位置加一,如果right位置出现次数大于一,则left和right对应字母相等,只需减少数组left位置减一然后left加一即可。每次遍历结束都计算与上次相比的最大长度。
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int hash[128] = {0}, n = s.size(), len = 0;
for (int left = 0, right = 0; right < n; right++) {
hash[s[right]]++;
while (hash[s[right]] > 1) {
hash[s[left++]]--;
}
len = max(len, right - left + 1);
}
return len;
}
};
3、1004. 最大连续1的个数 III

思路:每次首先统计零出现次数,如果出现次数大于k,也就是超过可翻转0的个数时,通过while循环更新left位置。每次遍历最后计算长度。
class Solution {
public:
int longestOnes(vector<int>& nums, int k) {
int zero = 0, len = 0;
for (int left = 0, right = 0; right < nums.size(); right++) {
if (nums[right] == 0) {
zero++;
}
while (zero > k) {
if (nums[left++] == 0)
zero--;
}
len = max(len, right - left + 1);
}
return len;
}
};
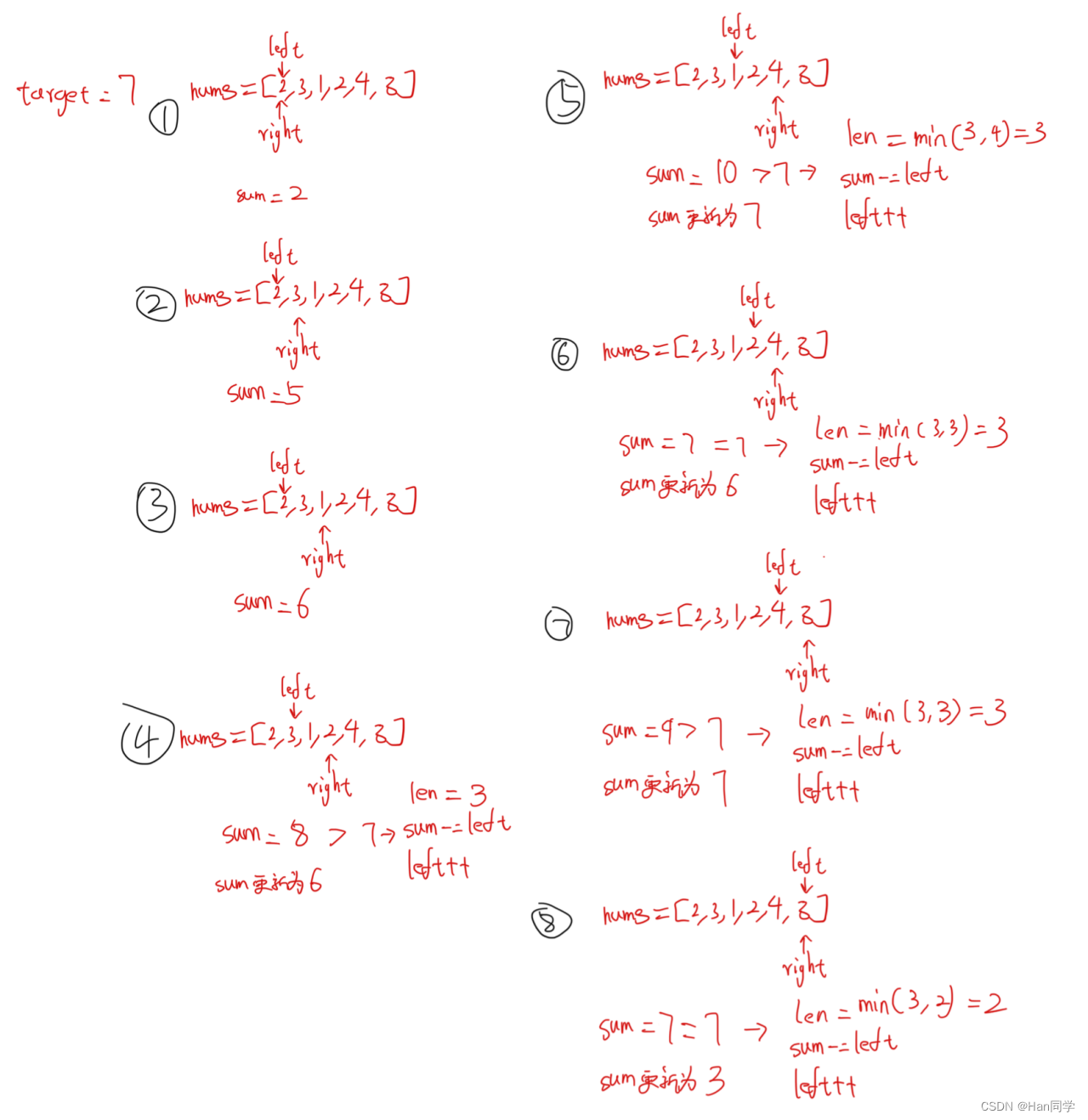
4、1658. 将 x 减到 0 的最小操作数

思路:寻找和等于<数组之和减x>的连续元素代替两端找元素,总长度减去其长度即为所求。
class Solution {
public:
int minOperations(vector<int>& nums, int x) {
int n = nums.size(), sum = 0;
for (auto a : nums)
sum += a;
int target = sum - x, tmp = 0;
if (target < 0)//处理sum小于x的情况
return -1;
int ret = -1;
for (int left = 0, right = 0; right < n; right++) {
tmp += nums[right];
while (tmp > target)
tmp -= nums[left++];
if (tmp == target)
ret = max(ret, right - left + 1);
}
if (ret == -1)//没有符合的返回-1
return ret;
else
return n - ret;
}
};
5、904. 水果成篮

思路:哈希表+滑动窗口
class Solution {
public:
int totalFruit(vector<int>& fruits) {
unordered_map<int, int> hash;
int ret = 0, n = fruits.size();
for (int left = 0, right = 0; right < n; right++) {
hash[fruits[right]]++;
while (hash.size() > 2) {
hash[fruits[left]]--;
if (hash[fruits[left]] == 0)
hash.erase(fruits[left]);
left++;
}
ret = max(ret, right - left + 1);
}
return ret;
}
};- 首先,使用一个unordered_map hash来记录当前窗口中每种水果的数量。
- 定义一个变量ret来记录最长的连续子数组的长度,初始值为0。
- 使用两个指针left和right来表示窗口的左右边界,初始时两个指针都指向数组的第一个元素。
- 在循环中,右指针right向右移动,将当前水果加入到hash中,并增加其数量。
- 如果hash中不同水果的种类数大于2,说明窗口中包含了超过两种不同类型的水果,需要移动左指针left来缩小窗口。
- 移动左指针时,将左边界对应的水果数量减少1,并判断减少后的数量是否为0,如果为0,则从hash中删除该水果。
- 不断移动左指针,直到窗口中不再包含超过两种不同类型的水果。
- 在每次移动左指针后,更新ret的值,即为当前窗口的长度。
- 最后返回ret,即为最长的连续子数组的长度。

6、438. 找到字符串中所有字母异位词

思路: 滑动窗口+哈希表
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
vector<int> ret;
int hash1[26] = {0};
for (auto a : p) {
hash1[a - 'a']++;
}
int hash2[26] = {0};
int count = 0;
for (int left = 0, right = 0; right < s.size(); right++) {
char in = s[right];
if (++hash2[in - 'a'] <= hash1[in - 'a'])
count++;
if (right - left + 1 > p.size()) {
char out = s[left++];
if (hash2[out - 'a']-- <= hash1[out - 'a'])
count--;
}
if (count == p.size())
ret.push_back(left);
}
return ret;
}
};- 首先,定义一个vector ret来存储结果,即符合条件的字母异位词的起始索引。
- 使用一个大小为26的数组hash1来记录字符串p中每个字符出现的次数。
- 使用两个大小为26的数组hash2和count来记录当前窗口中每个字符出现的次数和符合条件的字符个数。
- 使用两个指针left和right来表示窗口的左右边界,初始时两个指针都指向字符串s的第一个字符。
- 在循环中,右指针right向右移动,将当前字符加入到hash2中,并增加其出现次数。
- 如果hash2中当前字符的出现次数不超过hash1中的出现次数,说明当前字符是符合条件的字符,将count加1。
- 如果窗口的长度超过了字符串p的长度,需要移动左指针left来缩小窗口。
- 移动左指针时,将左边界对应的字符从hash2中减少出现次数,并判断减少后的次数是否小于等于hash1中的次数,如果小于等于,则说明减少后的字符不再符合条件,将count减1。
- 不断移动左指针,直到窗口的长度等于字符串p的长度。
- 在每次移动左指针后,判断count是否等于字符串p的长度,如果等于,则说明窗口中包含了一个字母异位词,将左指针的索引加入到结果数组ret中。
- 最后返回ret,即为所有符合条件的字母异位词的起始索引。

7、30. 串联所有单词的子串

思路:滑动窗口+哈希表
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
unordered_map<string, int> hash1;
vector<int> ret;
for (auto& s : words) {
hash1[s]++;
}
int len = words[0].size(), slen = words.size();
for (int i = 0; i < len; i++) {
unordered_map<string, int> hash2;
for (int left = i, right = i, count = 0; right + len <= s.size();
right += len) {
string in = s.substr(right, len);
hash2[in]++;
if (hash1.count(in) && hash2[in] <= hash1[in]) {
count++;
}
if (right - left + 1 > len * slen) {
string out = s.substr(left, len);
if (hash1.count(out) && hash2[out] <= hash1[out]) {
count--;
}
hash2[out]--;
left += len;
}
if (count == slen) {
ret.push_back(left);
}
}
}
return ret;
}
};- 首先,使用一个unordered_map(哈希表)hash1来记录words中每个字符串出现的次数。
- 然后,定义一个vector ret来存储结果,即符合条件的子串的起始索引。
- 接下来,通过两层循环来遍历s中的所有可能的子串。外层循环是根据words中字符串的长度来确定的,内层循环是遍历s中的每个字符。
- 在内层循环中,首先使用substr函数从s中截取长度为len的子串in,并将其加入到另一个unordered_map(哈希表)hash2中,并增加其出现次数。
- 然后,判断in是否在hash1中出现,并且hash2中的出现次数不超过hash1中的出现次数,如果满足条件,则将count加1。
- 接着,判断当前子串的长度是否超过了words中所有字符串的总长度,如果超过了,则需要移动左边界,即将左边界对应的子串从hash2中移除,并更新count的值。
- 最后,判断count是否等于words中字符串的个数,如果等于,则说明当前子串包含了words中所有字符串,将左边界的索引加入到ret中。
- 最后返回ret,即为所有符合条件的子串的起始索引。

8、76. 最小覆盖子串

思路:滑动窗口+哈希表
class Solution {
public:
string minWindow(string s, string t) {
int hash1[128] = {0}, kinds = 0;
for (auto s : t) {
if (hash1[s]++ == 0) {
kinds++;
}
}
int hash2[128] = {0}, count = 0, minlen = INT_MAX, begin = -1;
for (int left = 0, right = 0; right < s.size(); right++) {
char in = s[right];
if (++hash2[in] == hash1[in]) {
count++;
}
while (count == kinds) {
if (right - left + 1 < minlen) {
minlen = right - left + 1;
begin = left;
}
char out = s[left++];
if (hash2[out]-- == hash1[out]) {
count--;
}
}
}
if (begin == -1) {
return "";
} else {
return s.substr(begin, minlen);
}
}
};- 首先,使用一个大小为128的数组hash1来记录字符串t中每个字符出现的次数,并使用一个变量kinds来记录不同字符的种类数。
- 使用两个大小为128的数组hash2和count来记录当前窗口中每个字符出现的次数和符合条件的字符种类数。
- 使用两个指针left和right来表示窗口的左右边界,初始时两个指针都指向字符串s的第一个字符。
- 在循环中,右指针right向右移动,将当前字符加入到hash2中,并增加其出现次数。
- 如果hash2中当前字符的出现次数等于hash1中的出现次数,说明当前字符是符合条件的字符,将count加1。
- 如果窗口中包含了字符串t中的所有字符,即count等于kinds,进入内层循环。
- 在内层循环中,首先判断当前窗口的长度是否小于最小窗口长度minlen,如果是,则更新minlen和begin的值。
- 然后,移动左指针left来缩小窗口,将左边界对应的字符从hash2中减少出现次数,并判断减少后的次数是否等于hash1中的次数,如果是,则说明减少后的字符不再符合条件,将count减1。
- 不断移动左指针,直到窗口中不再包含字符串t中的所有字符。
- 在每次移动左指针后,继续移动右指针来扩大窗口,重复步骤4-9,直到右指针到达字符串s的末尾。
- 最后,判断begin的值是否为初始值-1,如果是,则说明没有找到符合条件的窗口,返回空字符串;否则,根据begin和minlen截取最小窗口子串,并返回。