🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
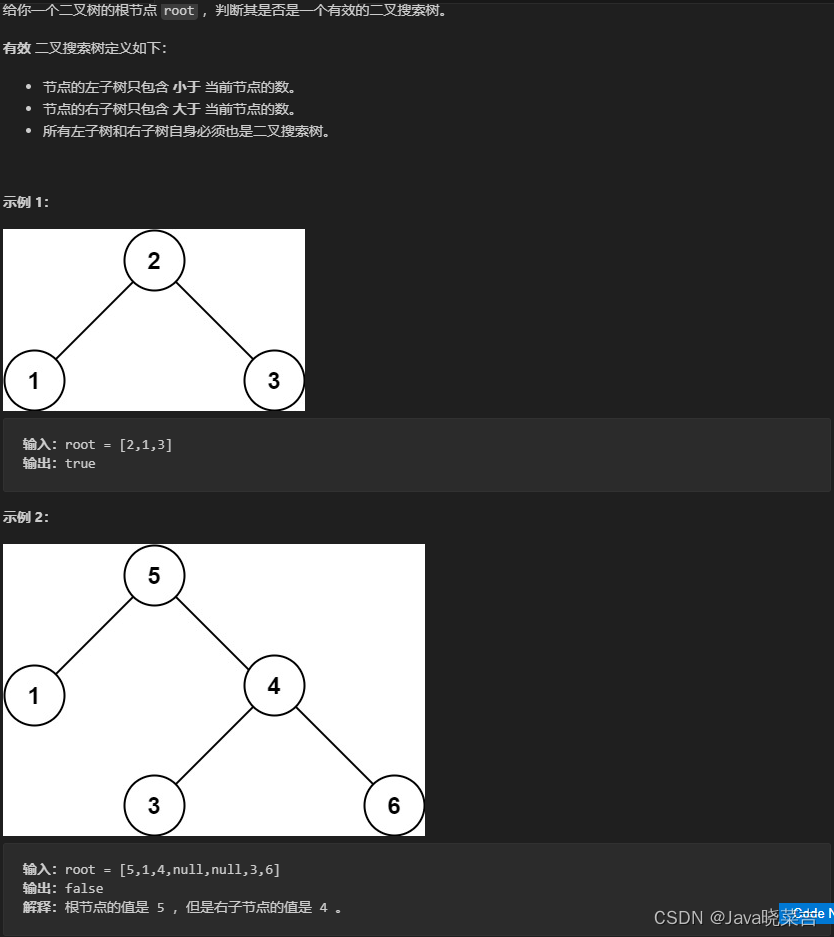
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.4特征工程
4.5模型构建
4.6模型评估
5.实验总结
源代码
1.项目背景
电影票房预测一直是电影产业中的一个重要问题,对于制片方、发行方和影院等利益相关者而言,准确地预测电影票房可以帮助他们做出更明智的决策。在电影产业中,投资决策、市场营销策略、排片安排等方面的决策都受到电影票房预测的影响。因此,构建一种准确可靠的电影票房预测模型对于电影产业的发展具有重要意义。
研究背景主要包括以下几个方面:
-
市场竞争激烈: 电影市场竞争激烈,每年推出大量新片。在这种竞争环境下,能够提前了解一部电影可能取得的票房情况,对于选择上映时机、进行市场宣传、确定投资规模等方面至关重要。
-
复杂多变的影响因素: 影响电影票房的因素众多,包括但不限于演员阵容、导演水平、电影类型、上映时间、市场宣传、观众口碑等。这些因素之间存在复杂的相互关系,传统的分析方法难以全面考虑这些因素的综合影响。
-
数据科学的应用需求: 随着数据科学和机器学习技术的发展,利用大量的电影数据进行建模和预测成为可能。随机森林算法是一种集成学习方法,具有高准确性和强大的泛化能力,特别适用于处理大规模、高维度的数据,因此成为构建电影票房预测模型的理想选择。
2.项目简介
2.1项目说明
本研究旨在利用随机森林算法构建一种高效的电影票房预测模型,通过综合考虑各种影响因素,提高预测准确性,为电影产业相关方提供科学的决策依据。通过该研究,可以更好地理解影响电影票房的关键因素,为电影从业者提供更全面的市场分析和预测服务。
2.2数据说明
该数据集来源于kaggle,该数据集包含1995年至2018年上映的电影类型统计数据,原始数据集共有300条,9个变量,各变量含义解释如下:
Genre:电影的类别或类型。(分类)
Year:电影发行的年份。(数字)
Movies Released :特定类型和年份发行的电影数量。(数字)
Gross:该类型和年份的电影产生的总收入。(数字)
Tickets Sold:该类型和年份的电影售出门票总数。(数字)
Inflation-Adjusted Gross:考虑到货币价值随时间的变化,根据通货膨胀进行调整的总收入。(数字)
Top Movie:该类型和年份中票房最高的电影的标题。(文本)
Top Movie Gross (That Year):该类型和年份中票房最高的电影产生的总收入。(数字)
Top Movie Inflation-Adjusted Gross (That Year):根据该类型和年份的通货膨胀调整后票房最高的电影的总收入。(数字)
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
随机森林是一种有监督学习算法。就像它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。bagging 方法,即 bootstrapaggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。简而言之,随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测。其一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。
随机森林分类器使用所有的决策树分类器以及 bagging 分类器的超参数来控制整体结构。与其先构建 bagging分类器,并将其传递给决策树分类器,我们可以直接使用随机森林分类器类,这样对于决策树而言,更加方便和优化。要注意的是,回归问题同样有一个随机森林回归器与之相对应。
随机森林算法中树的增长会给模型带来额外的随机性。与决策树不同的是,每个节点被分割成最小化误差的最佳指标,在随机森林中我们选择随机选择的指标来构建最佳分割。因此,在随机森林中,仅考虑用于分割节点的随机子集,甚至可以通过在每个指标上使用随机阈值来使树更加随机,而不是如正常的决策树一样搜索最佳阈值。这个过程产生了广泛的多样性,通常可以得到更好的模型。
4.项目实施步骤
4.1理解数据
导入数据分析常用的第三方库并加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.subplots as sp
df = pd.read_csv("movies_data.csv")
df.head()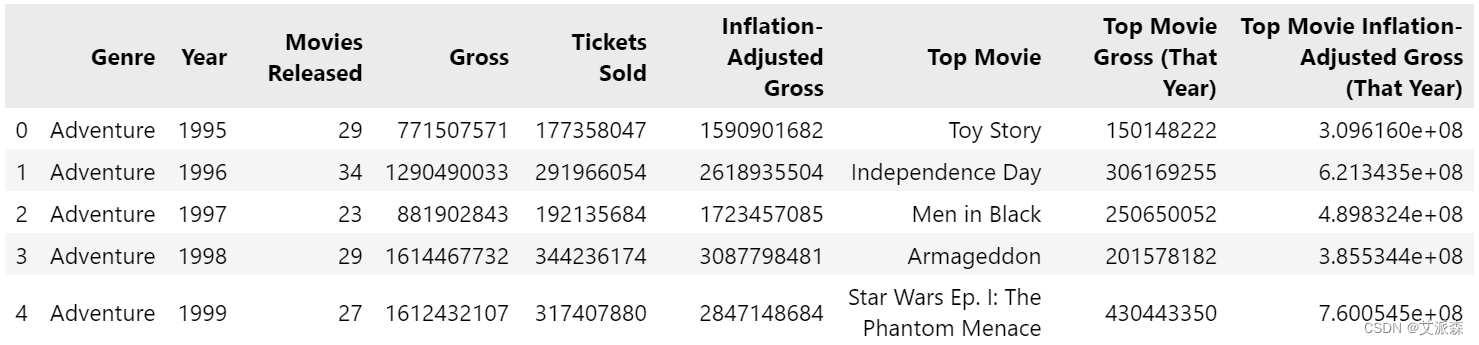
查看数据大小

查看数据基本信息

查看数值型变量的描述性统计
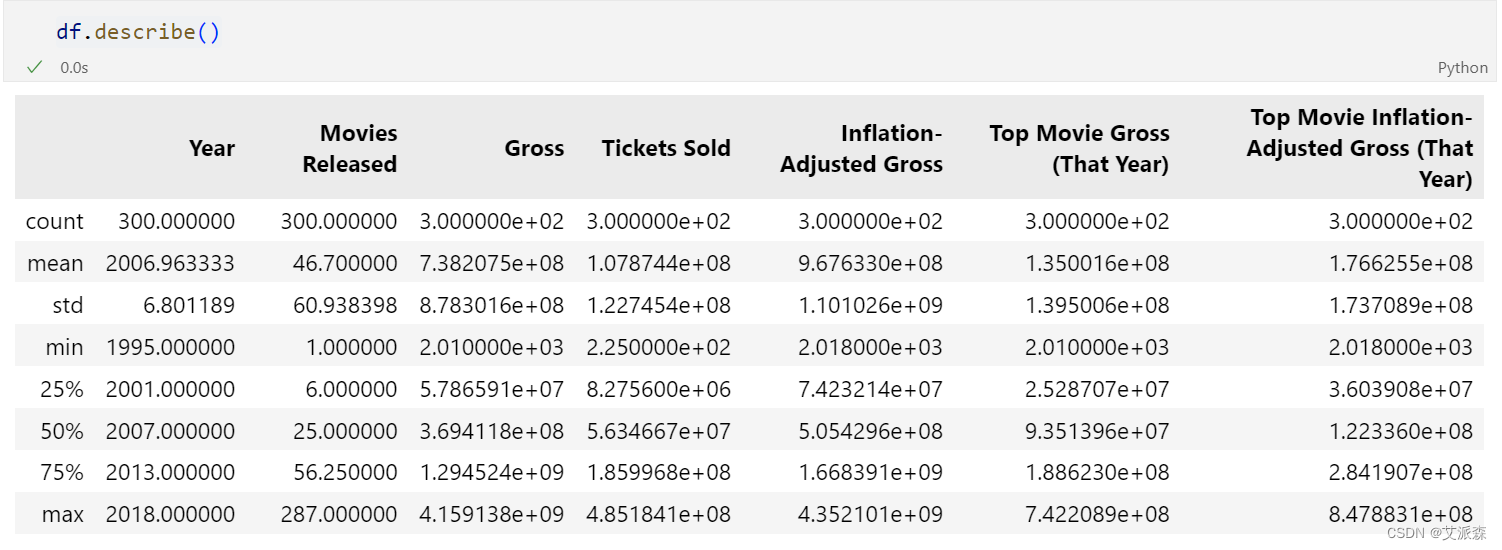
查看非数值型变量的描述性统计

4.2数据预处理
统计缺失值情况

从结果来看,不存在缺失值
检测是否存在重复值

结果为False,说明不存在
4.3探索性数据分析
基于门票销售和发行数量的流行类型
# 基于门票销售和发行数量的流行类型
# 根据上映的电影数量找到受欢迎的类型
genre_movies_released = df.groupby('Genre')['Movies Released'].sum().sort_values(ascending=False)
print("Popular genres based on Movies Released:")
print(genre_movies_released.head())
# 根据售出的门票总数来查找受欢迎的类型
genre_tickets_sold = df.groupby('Genre')['Tickets Sold'].sum().sort_values(ascending=False)
print("\nPopular genres based on Tickets Sold:")
print(genre_tickets_sold.head())
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
genre_movies_released.head().plot(kind='bar', ax=axes[0], color='skyblue')
axes[0].set_title('Top Genres by Movies Released')
axes[0].set_ylabel('Total Movies Released')
genre_tickets_sold.head().plot(kind='bar', ax=axes[1], color='lightcoral')
axes[1].set_title('Top Genres by Tickets Sold')
axes[1].set_ylabel('Total Tickets Sold')
plt.tight_layout()
plt.show()

类型和收益分析
# 类型和收益分析
genre_gross = df.groupby('Genre')['Gross'].sum().sort_values(ascending=False).head()
genre_inflation_adjusted_gross = df.groupby('Genre')['Inflation-Adjusted Gross'].sum().sort_values(ascending=False).head()
genre_top_movie_gross = df.groupby('Genre')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head()
fig = make_subplots(rows=3, cols=1, subplot_titles=['Top Genres by Gross Revenue', 'Top Genres by Inflation-Adjusted Gross Revenue', 'Top Genres by Top Movie Gross (That Year)'])
fig.add_trace(go.Bar(x=genre_gross.index, y=genre_gross.values, name='Gross Revenue', marker_color='skyblue'), row=1, col=1)
fig.add_trace(go.Bar(x=genre_inflation_adjusted_gross.index, y=genre_inflation_adjusted_gross.values, name='Inflation-Adjusted Gross Revenue', marker_color='lightcoral'), row=2, col=1)
fig.add_trace(go.Bar(x=genre_top_movie_gross.index, y=genre_top_movie_gross.values, name='Top Movie Gross (That Year)', marker_color='lightgreen'), row=3, col=1)
fig.update_layout(height=900, showlegend=False, title_text="Financial Success of Genres")
fig.update_xaxes(title_text="Genres", row=3, col=1)
fig.update_yaxes(title_text="Total Gross Revenue", row=1, col=1)
fig.update_yaxes(title_text="Total Inflation-Adjusted Gross Revenue", row=2, col=1)
fig.update_yaxes(title_text="Top Movie Gross (That Year)", row=3, col=1)
fig.show()
多年来的类型趋势和分析
# 多年来的类型趋势和分析
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
fig = px.line(filtered_df, x='Year', y='Movies Released', color='Genre',
title='Movie Releases Over Time for Selected Genres',
labels={'Movies Released': 'Number of Movies Released'},
line_shape='linear')
fig.show()
# 为不同年份的总收入创建一个交互式折线图
fig = px.line(filtered_df, x='Year', y='Gross', color='Genre',
title='Gross Revenue Over Time for Selected Genres',
labels={'Gross': 'Total Gross Revenue'},
line_shape='linear')
fig.show()
一段时间内选定类型中票房最高的电影
# 一段时间内选定类型中票房最高的电影
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
# 创建一个交互式条形图来显示每种类型和年份中票房最高的电影
fig = px.bar(filtered_df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Highest-Grossing Movies in Selected Genres Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
text='Top Movie', height=500)
fig.update_traces(textposition='outside')
fig.show()
多年来的类型分布
# 多年来的类型分布
# 多年来类型分布的堆叠区域图
fig = px.area(df, x='Year', y='Movies Released', color='Genre',
title='Genre Distribution Over the Years',
labels={'Movies Released': 'Number of Movies Released'},
height=500)
fig.show()
受众参与分析
# 受众参与分析
# 观众参与的散点图
fig = px.scatter(df, x='Tickets Sold', y='Gross', color='Genre',
title='Audience Engagement by Genre',
labels={'Tickets Sold': 'Number of Tickets Sold', 'Gross': 'Total Gross Revenue'},
height=500)
fig.show()
历年最佳电影表现
# 历年最佳电影表现
# 随时间变化的顶级电影表现的折线图
fig = px.line(df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Top Movie Performance Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
height=500)
fig.show()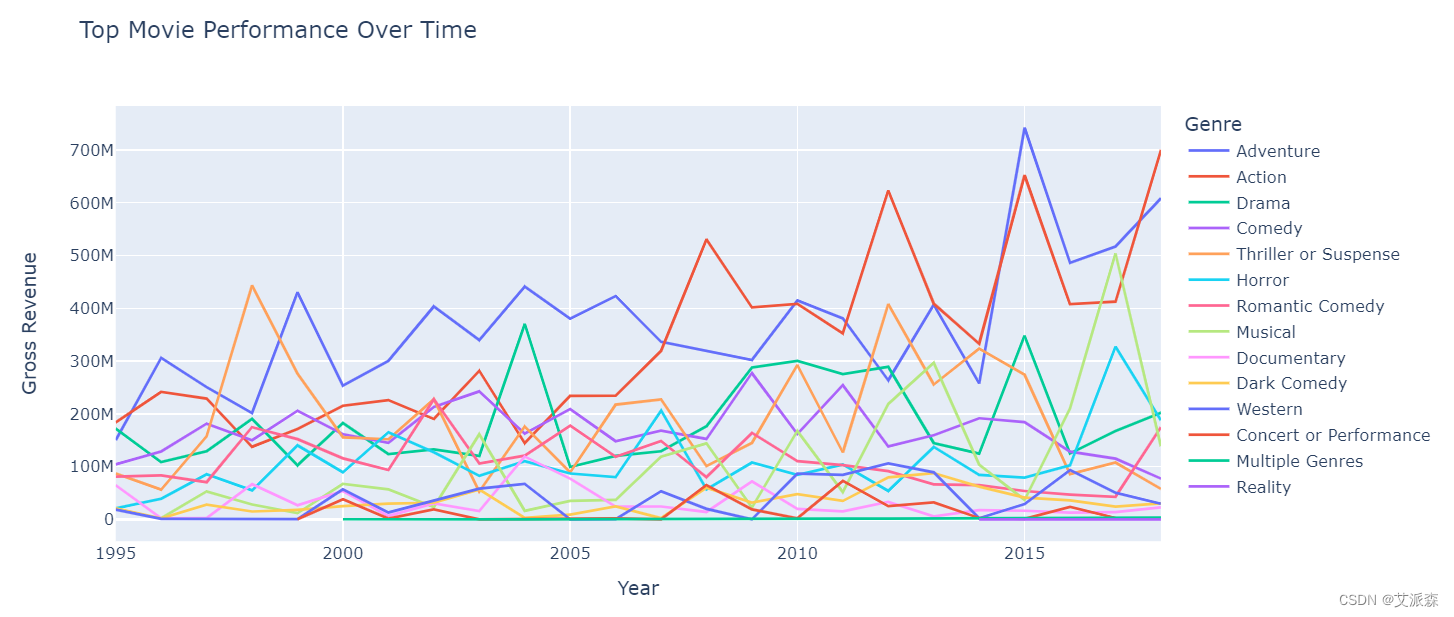
按类型划分的每部电影平均收入
# 按类型划分的每部电影平均收入
# 按类型计算每部电影的平均收入
df['Average Revenue per Movie'] = df['Gross'] / df['Movies Released']
# 按类型划分的每部电影平均收入柱状图
fig = px.bar(df, x='Genre', y='Average Revenue per Movie',
title='Average Revenue per Movie by Genre',
labels={'Average Revenue per Movie': 'Average Revenue per Movie'},
height=500)
fig.show()
不同类型的门票销售和发行
# 不同类型的门票销售和发行
fig = px.violin(df, x='Genre', y='Tickets Sold',
title='Genre-wise Ticket Sales Distribution',
labels={'Tickets Sold': 'Number of Tickets Sold'},
height=500)
fig.show()
通货膨胀调整后总收益的类型趋势
# 通货膨胀调整后总收益的类型趋势
fig = px.line(df, x='Year', y='Inflation-Adjusted Gross', color='Genre',
title='Genre Trends in Inflation-Adjusted Gross Revenue',
labels={'Inflation-Adjusted Gross': 'Inflation-Adjusted Gross Revenue'},
height=500)
fig.show()
每个类型和收入的顶级电影
# 每个类型和收入的顶级电影
unique_top_movies_count = df.groupby('Genre')['Top Movie'].nunique().sort_values(ascending=False)
top_movies_gross = df.groupby('Top Movie')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head(10)
fig = sp.make_subplots(rows=3, cols=1, subplot_titles=['Count of Unique Top Movies per Genre', 'Top Movies with the Highest Gross Revenue', 'Distribution of Gross Revenue for Top Movies'])
fig.add_trace(go.Bar(x=unique_top_movies_count.index, y=unique_top_movies_count.values),
row=1, col=1)
fig.add_trace(go.Bar(x=top_movies_gross.index, y=top_movies_gross.values),
row=2, col=1)
fig.add_trace(go.Box(x=df['Top Movie'], y=df['Top Movie Gross (That Year)']),
row=3, col=1)
fig.update_layout(height=1000, showlegend=False, title_text="Top Movie Analysis")
fig.show()
4.4特征工程
导入第三方库并准备建模需要的数据
from sklearn.model_selection import KFold, cross_val_predict
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
dff = df.copy()
categorical_features = ['Genre'] # 假设“类型”是一个分类变量
numerical_features = ['Year', 'Movies Released']
target_variable = 'Tickets Sold'
# 筛选DataFrame以仅包含相关列
data = df[['Year', 'Movies Released', 'Genre', 'Tickets Sold', 'Gross']]
# 将数据拆分为特征和目标变量
X = data[['Year', 'Movies Released', 'Genre', 'Gross']]
y = data[target_variable]4.5模型构建
初始化模型,创建管道
# 定义分类编码的预处理器
preprocessor = ColumnTransformer(
transformers=[
('cat', OneHotEncoder(), categorical_features),
],
remainder='passthrough'
)
# 初始化随机森林回归模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 创建带有预处理和模型的管道
pipeline = Pipeline([
('preprocessor', preprocessor),
('model', model)
])交叉验证
# 初始化KFold以进行交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 进行k-fold交叉验证并进行预测
predictions = cross_val_predict(pipeline, X, y, cv=kf)
# 评估模型性能
mse = mean_squared_error(y, predictions)
print(f'Mean Squared Error: {mse}') 
4.6模型评估
# 可视化实际值和预测值
plt.scatter(y, predictions)
plt.xlabel('Actual Tickets Sold')
plt.ylabel('Predicted Tickets Sold')
plt.title('Actual vs. Predicted Tickets Sold')
plt.show()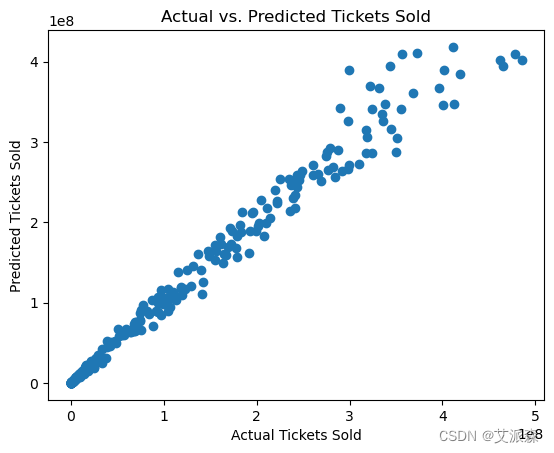
5.实验总结
本实验通过对电影数据进行数据可视化、特征工程、建模分析,使用随机森林算法构建预测模型。总的来说,基于随机森林算法构建的电影票房预测模型为电影产业提供了一种强大的工具。然而,对于实际应用,还需要综合考虑业务背景、市场趋势等因素,将模型预测结果与实际情况相结合,形成更全面的决策依据。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.subplots as sp
df = pd.read_csv("movies_data.csv")
df.head()
df.shape
df.info()
df.describe()
df.describe(include='O')
df.isnull().sum()
any(df.duplicated())
# 基于门票销售和发行数量的流行类型
# 根据上映的电影数量找到受欢迎的类型
genre_movies_released = df.groupby('Genre')['Movies Released'].sum().sort_values(ascending=False)
print("Popular genres based on Movies Released:")
print(genre_movies_released.head())
# 根据售出的门票总数来查找受欢迎的类型
genre_tickets_sold = df.groupby('Genre')['Tickets Sold'].sum().sort_values(ascending=False)
print("\nPopular genres based on Tickets Sold:")
print(genre_tickets_sold.head())
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
genre_movies_released.head().plot(kind='bar', ax=axes[0], color='skyblue')
axes[0].set_title('Top Genres by Movies Released')
axes[0].set_ylabel('Total Movies Released')
genre_tickets_sold.head().plot(kind='bar', ax=axes[1], color='lightcoral')
axes[1].set_title('Top Genres by Tickets Sold')
axes[1].set_ylabel('Total Tickets Sold')
plt.tight_layout()
plt.show()
# 类型和收益分析
genre_gross = df.groupby('Genre')['Gross'].sum().sort_values(ascending=False).head()
genre_inflation_adjusted_gross = df.groupby('Genre')['Inflation-Adjusted Gross'].sum().sort_values(ascending=False).head()
genre_top_movie_gross = df.groupby('Genre')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head()
fig = make_subplots(rows=3, cols=1, subplot_titles=['Top Genres by Gross Revenue', 'Top Genres by Inflation-Adjusted Gross Revenue', 'Top Genres by Top Movie Gross (That Year)'])
fig.add_trace(go.Bar(x=genre_gross.index, y=genre_gross.values, name='Gross Revenue', marker_color='skyblue'), row=1, col=1)
fig.add_trace(go.Bar(x=genre_inflation_adjusted_gross.index, y=genre_inflation_adjusted_gross.values, name='Inflation-Adjusted Gross Revenue', marker_color='lightcoral'), row=2, col=1)
fig.add_trace(go.Bar(x=genre_top_movie_gross.index, y=genre_top_movie_gross.values, name='Top Movie Gross (That Year)', marker_color='lightgreen'), row=3, col=1)
fig.update_layout(height=900, showlegend=False, title_text="Financial Success of Genres")
fig.update_xaxes(title_text="Genres", row=3, col=1)
fig.update_yaxes(title_text="Total Gross Revenue", row=1, col=1)
fig.update_yaxes(title_text="Total Inflation-Adjusted Gross Revenue", row=2, col=1)
fig.update_yaxes(title_text="Top Movie Gross (That Year)", row=3, col=1)
fig.show()
# 多年来的类型趋势和分析
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
fig = px.line(filtered_df, x='Year', y='Movies Released', color='Genre',
title='Movie Releases Over Time for Selected Genres',
labels={'Movies Released': 'Number of Movies Released'},
line_shape='linear')
fig.show()
# 为不同年份的总收入创建一个交互式折线图
fig = px.line(filtered_df, x='Year', y='Gross', color='Genre',
title='Gross Revenue Over Time for Selected Genres',
labels={'Gross': 'Total Gross Revenue'},
line_shape='linear')
fig.show()
# 一段时间内选定类型中票房最高的电影
selected_genres = ['Action', 'Comedy', 'Drama', 'Adventure']
filtered_df = df[df['Genre'].isin(selected_genres)]
# 创建一个交互式条形图来显示每种类型和年份中票房最高的电影
fig = px.bar(filtered_df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Highest-Grossing Movies in Selected Genres Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
text='Top Movie', height=500)
fig.update_traces(textposition='outside')
fig.show()
# 多年来的类型分布
# 多年来类型分布的堆叠区域图
fig = px.area(df, x='Year', y='Movies Released', color='Genre',
title='Genre Distribution Over the Years',
labels={'Movies Released': 'Number of Movies Released'},
height=500)
fig.show()
# 受众参与分析
# 观众参与的散点图
fig = px.scatter(df, x='Tickets Sold', y='Gross', color='Genre',
title='Audience Engagement by Genre',
labels={'Tickets Sold': 'Number of Tickets Sold', 'Gross': 'Total Gross Revenue'},
height=500)
fig.show()
# 历年最佳电影表现
# 随时间变化的顶级电影表现的折线图
fig = px.line(df, x='Year', y='Top Movie Gross (That Year)', color='Genre',
title='Top Movie Performance Over Time',
labels={'Top Movie Gross (That Year)': 'Gross Revenue'},
height=500)
fig.show()
# 按类型划分的每部电影平均收入
# 按类型计算每部电影的平均收入
df['Average Revenue per Movie'] = df['Gross'] / df['Movies Released']
# 按类型划分的每部电影平均收入柱状图
fig = px.bar(df, x='Genre', y='Average Revenue per Movie',
title='Average Revenue per Movie by Genre',
labels={'Average Revenue per Movie': 'Average Revenue per Movie'},
height=500)
fig.show()
# 不同类型的门票销售和发行
fig = px.violin(df, x='Genre', y='Tickets Sold',
title='Genre-wise Ticket Sales Distribution',
labels={'Tickets Sold': 'Number of Tickets Sold'},
height=500)
fig.show()
# 通货膨胀调整后总收益的类型趋势
fig = px.line(df, x='Year', y='Inflation-Adjusted Gross', color='Genre',
title='Genre Trends in Inflation-Adjusted Gross Revenue',
labels={'Inflation-Adjusted Gross': 'Inflation-Adjusted Gross Revenue'},
height=500)
fig.show()
# 每个类型和收入的顶级电影
unique_top_movies_count = df.groupby('Genre')['Top Movie'].nunique().sort_values(ascending=False)
top_movies_gross = df.groupby('Top Movie')['Top Movie Gross (That Year)'].max().sort_values(ascending=False).head(10)
fig = sp.make_subplots(rows=3, cols=1, subplot_titles=['Count of Unique Top Movies per Genre', 'Top Movies with the Highest Gross Revenue', 'Distribution of Gross Revenue for Top Movies'])
fig.add_trace(go.Bar(x=unique_top_movies_count.index, y=unique_top_movies_count.values),
row=1, col=1)
fig.add_trace(go.Bar(x=top_movies_gross.index, y=top_movies_gross.values),
row=2, col=1)
fig.add_trace(go.Box(x=df['Top Movie'], y=df['Top Movie Gross (That Year)']),
row=3, col=1)
fig.update_layout(height=1000, showlegend=False, title_text="Top Movie Analysis")
fig.show()
from sklearn.model_selection import KFold, cross_val_predict
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
dff = df.copy()
categorical_features = ['Genre'] # 假设“类型”是一个分类变量
numerical_features = ['Year', 'Movies Released']
target_variable = 'Tickets Sold'
# 筛选DataFrame以仅包含相关列
data = df[['Year', 'Movies Released', 'Genre', 'Tickets Sold', 'Gross']]
# 将数据拆分为特征和目标变量
X = data[['Year', 'Movies Released', 'Genre', 'Gross']]
y = data[target_variable]
# 定义分类编码的预处理器
preprocessor = ColumnTransformer(
transformers=[
('cat', OneHotEncoder(), categorical_features),
],
remainder='passthrough'
)
# 初始化随机森林回归模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 创建带有预处理和模型的管道
pipeline = Pipeline([
('preprocessor', preprocessor),
('model', model)
])
# 初始化KFold以进行交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 进行k-fold交叉验证并进行预测
predictions = cross_val_predict(pipeline, X, y, cv=kf)
# 评估模型性能
mse = mean_squared_error(y, predictions)
print(f'Mean Squared Error: {mse}')
# 可视化实际值和预测值
plt.scatter(y, predictions)
plt.xlabel('Actual Tickets Sold')
plt.ylabel('Predicted Tickets Sold')
plt.title('Actual vs. Predicted Tickets Sold')
plt.show()