Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、Flink CDC Connectors介绍
- 1、CDC Connectors介绍及架构图
- 2、支持的连接
- 3、Flink CDC与 Flink 版本关系
- 4、特性介绍
- 5、flink sql client集成flink cdc
- 1)、集成步骤
- 2)、示例:捕获mysql的user表数据变化情况
- 6、flink datastream API集成flink cdc
- 1)、maven依赖
- 2)、代码实现
- 3)、验证
- 4)、debezium数据格式介绍
- 二、Flink CDC Streaming ELT介绍
- 1、介绍及架构图
- 2、核心概念及流程图
- 1)、Data Source Connector
- 2)、Data Sink connector
- 3)、Table ID
- 4)、Data Source
- 5)、Data Sink
- 6)、Route
- 7)、Data Pipeline
- 3、示例:将MySQL的user表数据同步至Elasticsearch表
- 1)、整体架构
- 2)、环境准备
- 3)、创建 docker-compose.yml
- 4)、下载 Flink 和所需要的依赖包
- 1、部署flink 1.18版本
- 2、下载本示例需要用到的connector
- 5)、启动flink
- 6)、准备mysql数据
- 7)、在sql client中的操作
- 8)、Elasticsearch中查看同步的数据情况
- 9)、CUD(create、update和delete)操作演示
- 10)、环境清理
本文详细的介绍了Flink CDC的应用,并且提供三个示例进行说明如何使用,即使用Flink sql client的观察数据同步的情况、通过DataStream API 捕获数据变化情况以及通过完整示例应用Flink CDC的ELT操作步骤及验证。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,本文依赖Flink 集群环境、可选的docker环境、Elasticsearch、Kibana、mysql。
本专题分为以下几篇文章:
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-CDC Connector介绍及示例 (1)
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-Streaming ELT介绍及示例(2)
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-完整版
一、Flink CDC Connectors介绍
本文介绍的CDC是基于2.4版本,当前版本已经发布至3.0,本Flink 专栏介绍是基于Flink 1.17版本,CDC 2.4版本支持到1.17版本。
1、CDC Connectors介绍及架构图
Apache Flink®的CDC连接器是用于Apache Flnk®的一组源连接器,使用更改数据捕获(CDC)接收来自不同数据库的更改。Apache Flink®的CDC连接器将Debezium集成为捕获数据更改的引擎。因此,它可以充分利用Debezium的能力。
了解更多关于Debezium的信息。
或者参考:37、Flink 的CDC 格式:debezium部署以及mysql示例

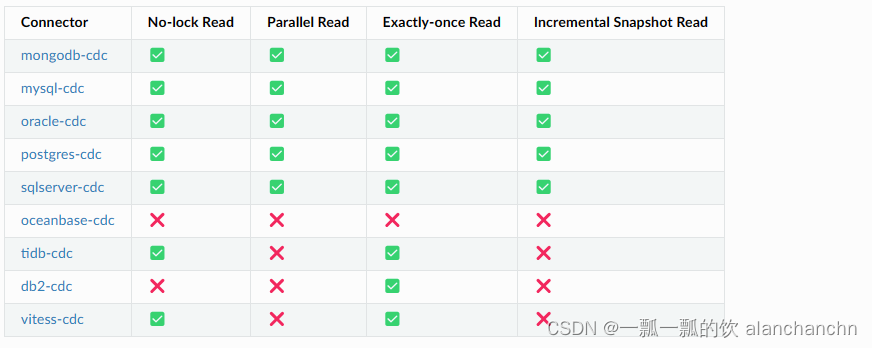
2、支持的连接

3、Flink CDC与 Flink 版本关系

4、特性介绍
- 支持读取数据库快照,并在处理失败后立即继续读取binlog。
- CDC连接器用于DataStream API,用户可以在一个作业中使用多个数据库和表的更改,而无需部署Debezium和Kafka。
- 用于Table/SQL API的CDC连接器,用户可以使用SQL DDL创建CDC源以监视单个表上的更改。
下表显示了连接器的当前功能:
5、flink sql client集成flink cdc
1)、集成步骤
1、需要有一个flink的集群环境
具体搭建参考:2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
2、下载flink cdc的jar并放在FLINK_HOME/lib/目录下面
下载地址:https://github.com/ververica/flink-cdc-connectors/releases
3、重启flink集群
2)、示例:捕获mysql的user表数据变化情况
本示例的前提是设置好了binlog,具体设置方式可以参考文章:
37、Flink 的CDC 格式:debezium部署以及mysql示例
Flink SQL> CREATE TABLE mysql_binlog_user (
> id INT NOT NULL,
> name STRING,
> age INT,
> PRIMARY KEY(id) NOT ENFORCED
> ) WITH (
> 'connector' = 'mysql-cdc',
> 'hostname' = '192.168.10.44',
> 'port' = '3306',
> 'username' = 'root',
> 'password' = '123456',
> 'database-name' = 'cdctest',
> 'table-name' = 'user'
> );
[INFO] Execute statement succeed.
Flink SQL> select * from mysql_binlog_user;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 4 | test456 | 8888 |
| +I | 2 | alanchan | 20 |
| +I | 3 | alanchanchn | 33 |
| +I | 1 | alan | 18 |
| -U | 4 | test456 | 8888 |
| +U | 4 | test123 | 8888 |
| -U | 4 | test123 | 8888 |
| +U | 4 | test123 | 66666 |
| -D | 4 | test123 | 66666 |
| +I | 4 | alanchanchn2 | 100 |
Flink SQL> select name ,sum(age) from mysql_binlog_user group by name;
+----+--------------------------------+-------------+
| op | name | EXPR$1 |
+----+--------------------------------+-------------+
| +I | alanchanchn2 | 100 |
| +I | alanchan | 20 |
| +I | alanchanchn | 33 |
| +I | alan | 18 |
6、flink datastream API集成flink cdc
本示例是捕获mysql cdctest库的user表数据变化情况。
1)、maven依赖
使用flink cdc添加如下依赖即可,但flink本身的运行环境相关依赖需要添加。
<!-- https://mvnrepository.com/artifact/com.ververica/flink-sql-connector-mysql-cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.4.0</version>
<scope>provided</scope>
</dependency>
2)、代码实现
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import lombok.extern.slf4j.Slf4j;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
@Slf4j
public class TestFlinkCDCFromMysqlDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(3000);
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("192.168.10.44")
.port(3306)
.databaseList("cdctest") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*".
.tableList("cdctest.user") // 设置捕获的表
.username("root")
.password("123456")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
DataStream<String> result = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source");
log.info(result.toString());
result.map(new MapFunction<String,String>() {
@Override
public String map(String value) throws Exception {
log.info("value ======={}",value);
return value;
}
});
env.execute();
}
}
3)、验证
在程序运行起来后,对cdctest.user表的数据进行添加、修改、删除操作,观察程序控制台日志输出情况
08:50:26.819 [Source: MySQL Source -> Map (4/16)#0] INFO com.win.TestFlinkCDCFromMysqlDemo - value ======={"before":null,"after":{"id":2,"name":"alanchan","age":20},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"cdctest","sequence":null,"table":"user","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1705884626222,"transaction":null}
08:50:26.821 [Source: MySQL Source -> Map (4/16)#0] INFO com.win.TestFlinkCDCFromMysqlDemo - value ======={"before":null,"after":{"id":3,"name":"alanchanchn","age":33},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"cdctest","sequence":null,"table":"user","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1705884626223,"transaction":null}
08:50:26.821 [Source: MySQL Source -> Map (4/16)#0] INFO com.win.TestFlinkCDCFromMysqlDemo - value ======={"before":null,"after":{"id":1,"name":"alan","age":18},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"cdctest","sequence":null,"table":"user","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1705884626221,"transaction":null}
08:50:26.822 [Source: MySQL Source -> Map (4/16)#0] INFO com.win.TestFlinkCDCFromMysqlDemo - value ======={"before":null,"after":{"id":4,"name":"test456","age":999000},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"cdctest","sequence":null,"table":"user","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1705884626223,"transaction":null}
一月 22, 2024 8:50:27 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect信息:
Connected to 192.168.10.44:3306 at alan_master_logbin.000004/10816 (sid:6116, cid:565)
08:50:56.030 [Source: MySQL Source -> Map (1/16)#0] INFO com.win.TestFlinkCDCFromMysqlDemo - value ======={"before":{"id":4,"name":"test456","age":999000},"after":{"id":4,"name":"test456","age":8888},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1705884032000,"snapshot":"false","db":"cdctest","sequence":null,"table":"user","server_id":1,"gtid":null,"file":"alan_master_logbin.000004","pos":11010,"row":0,"thread":557,"query":null},"op":"u","ts_ms":1705884655747,"transaction":null}
4)、debezium数据格式介绍
关于debezium更多的信息可以参考:37、Flink 的CDC 格式:debezium部署以及mysql示例
在flink cdc的版本中,不需要特别对debezium数据格式进行处理,默认的形如下面的内容,也即不带schema的,解析方式参考上例。
{
"before": {
"name": "alan_test",
"scores": 666.0
},
"after": {
"name": "alan_test",
"scores": 888.0
},
"source": {
"version": "1.7.2.Final",
"connector": "mysql",
"name": "ALAN",
"ts_ms": 1705717298000,
"snapshot": "false",
"db": "cdctest",
"sequence": null,
"table": "userscoressink",
"server_id": 1,
"gtid": null,
"file": "alan_master_logbin.000004",
"pos": 4931,
"row": 0,
"thread": null,
"query": null
},
"op": "u",
"ts_ms": 1705717772785,
"transaction": null
}
在某些情况下可能需要带schema的,形如下例,
如果需要解析则需要将JsonDebeziumDeserializationSchema()改成JsonDebeziumDeserializationSchema(true)
一般推荐使用系统默认的,不带schema的数据格式。
{
"schema": {
"type": "struct",
"fields": [{
"type": "struct",
"fields": [{
"type": "string",
"optional": true,
"field": "name"
}, {
"type": "double",
"optional": true,
"field": "scores"
}],
"optional": true,
"name": "ALAN.cdctest.userscoressink.Value",
"field": "before"
}, {
"type": "struct",
"fields": [{
"type": "string",
"optional": true,
"field": "name"
}, {
"type": "double",
"optional": true,
"field": "scores"
}],
"optional": true,
"name": "ALAN.cdctest.userscoressink.Value",
"field": "after"
}, {
"type": "struct",
"fields": [{
"type": "string",
"optional": false,
"field": "version"
}, {
"type": "string",
"optional": false,
"field": "connector"
}, {
"type": "string",
"optional": false,
"field": "name"
}, {
"type": "int64",
"optional": false,
"field": "ts_ms"
}, {
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false"
},
"default": "false",
"field": "snapshot"
}, {
"type": "string",
"optional": false,
"field": "db"
}, {
"type": "string",
"optional": true,
"field": "sequence"
}, {
"type": "string",
"optional": true,
"field": "table"
}, {
"type": "int64",
"optional": false,
"field": "server_id"
}, {
"type": "string",
"optional": true,
"field": "gtid"
}, {
"type": "string",
"optional": false,
"field": "file"
}, {
"type": "int64",
"optional": false,
"field": "pos"
}, {
"type": "int32",
"optional": false,
"field": "row"
}, {
"type": "int64",
"optional": true,
"field": "thread"
}, {
"type": "string",
"optional": true,
"field": "query"
}],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
}, {
"type": "string",
"optional": false,
"field": "op"
}, {
"type": "int64",
"optional": true,
"field": "ts_ms"
}, {
"type": "struct",
"fields": [{
"type": "string",
"optional": false,
"field": "id"
}, {
"type": "int64",
"optional": false,
"field": "total_order"
}, {
"type": "int64",
"optional": false,
"field": "data_collection_order"
}],
"optional": true,
"field": "transaction"
}],
"optional": false,
"name": "ALAN.cdctest.userscoressink.Envelope"
},
"payload": {
"before": {
"name": "alan_test",
"scores": 666.0
},
"after": {
"name": "alan_test",
"scores": 888.0
},
"source": {
"version": "1.7.2.Final",
"connector": "mysql",
"name": "ALAN",
"ts_ms": 1705717298000,
"snapshot": "false",
"db": "cdctest",
"sequence": null,
"table": "userscoressink",
"server_id": 1,
"gtid": null,
"file": "alan_master_logbin.000004",
"pos": 4931,
"row": 0,
"thread": null,
"query": null
},
"op": "u",
"ts_ms": 1705717772785,
"transaction": null
}
}
二、Flink CDC Streaming ELT介绍
1、介绍及架构图
CDC流式ELT框架是一个流数据集成框架,旨在为用户提供更强大的API。它允许用户通过自定义的Flink操作符和作业提交工具来配置他们的数据同步逻辑。该框架优先优化任务提交过程,并提供增强的功能,如整个数据库同步、分片和模式更改同步。

✅端到端数据集成框架
✅ API,用于数据集成用户轻松构建作业
✅ 源/接收器中的多表支持
✅ 同步整个数据库
✅ 模式进化能力
2、核心概念及流程图
Flink CDC 3.0框架中流动的数据类型被称为Event,表示外部系统生成的更改事件。每个事件都标有发生更改的表ID。事件分为SchemaChangeEvent和DataChangeEvent,分别表示表结构和数据的变化。

1)、Data Source Connector
Data Source Connector捕获外部系统中的更改,并将其转换为事件作为同步任务的输出。它还为框架提供了一个MetadataAccessor ,用于读取外部系统的元数据。
2)、Data Sink connector
Data Sink connector连接器接收来自Data Source的更改事件,并将其应用于外部系统。此外,MetadataApplier用于将元数据更改从源系统应用到目标系统。
由于事件以流水线方式从上游流向下游,因此数据同步任务被称为数据流水线。数据管道由数据源、路由、转换和数据接收器组成。转换可以向事件添加额外的内容,路由器可以重新映射与事件相对应的表ID。
3)、Table ID
连接到外部系统时,需要与外部系统的存储对象建立映射关系。这就是Table ID所指的内容。
为了与大多数外部系统兼容,表ID由三元组表示:(namespace,schemaName,Table)。连接器需要在Table ID 和外部系统中的存储对象之间建立映射。
例如,MySQL/Doris中的表被映射到(null,database,table),而消息队列系统(如Kafka)中的主题被映射到了(null,null,topic)
4)、Data Source
Data Source用于访问元数据并从外部系统读取更改后的数据。数据源可以同时从多个表中读取数据。
Data Source属性:
类型:源的类型,例如MySQL、Postgres。
名称:源的名称,用户定义(可选,提供默认值)。
源的其他自定义配置。
例如,使用yaml文件来定义mysql源
source:
type: mysql
name: mysql-source #optional,description information
host: localhost
port: 3306
username: admin
password: pass
tables: adb.*, bdb.user_table_[0-9]+, [app|web]_order_\.*
5)、Data Sink
Data Sink用于应用架构更改并将更改数据写入外部系统。一个数据接收器可以同时写入多个表。
Data Sink的属性:
类型:接收器的类型,例如MySQL或PostgreSQL。
名称:接收器的名称,用户定义(可选,提供默认值)。
接收器的其他自定义配置。
例如,使用这个yaml文件来定义kafka接收器:
sink:
type: kafka
name: mysink-queue # Optional parameter for description purpose
bootstrap-servers: localhost:9092
auto-create-table: true # Optional parameter for advanced functionalities
6)、Route
Route指定每个事件的table ID。最典型的场景是子数据库和子表的合并,将多个上游源表路由到同一个汇点表。
Route,需要以下内容:
source table:源表id,支持正则表达式
sink-table:sink-table id,支持正则表达式
说明:路由规则说明(可选,提供默认值)
例如,如果将数据库“mydb”中的表“web_order”同步到Kafka主题“ods_web.order”,使用此yaml文件来定义此路由:
route:
source-table: mydb.default.web_order
sink-table: ods_web_order
description: sync table to one destination table with given prefix ods_
7)、Data Pipeline
由于事件以流水线方式从上游流向下游,因此数据同步任务也称为数据流水线。
Data Pipeline 属性:
名称:管道的名称,将作为作业名称提交到Flink集群。
将实现其他高级功能,如自动表创建、模式演化等。
例如,使用这个yaml文件来定义管道:
pipeline:
name: mysql-to-kafka-pipeline
parallelism: 1
3、示例:将MySQL的user表数据同步至Elasticsearch表
本示例使用的是Flink 1.18版本。
其安装及验证参考文章:1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
基于 Flink CDC 快速构建 MySQL 流式 ETL。本示例演示都将在 Flink SQL CLI 中进行,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE。
本示例的实现内容是将mysql中cdctest的user表数据不变化的同步至Elasticsearch的e_f_user表中
验证user表的历史数据、新增、修改和删除数据后Elasticsearch的e_f_user表的变化情况
如果需要进行计算则在提交flink任务的时候修改其sql即可,该部分在提交任务处会有说明。
1)、整体架构
本图为盗图,并且本示例不包含postgres数据库。
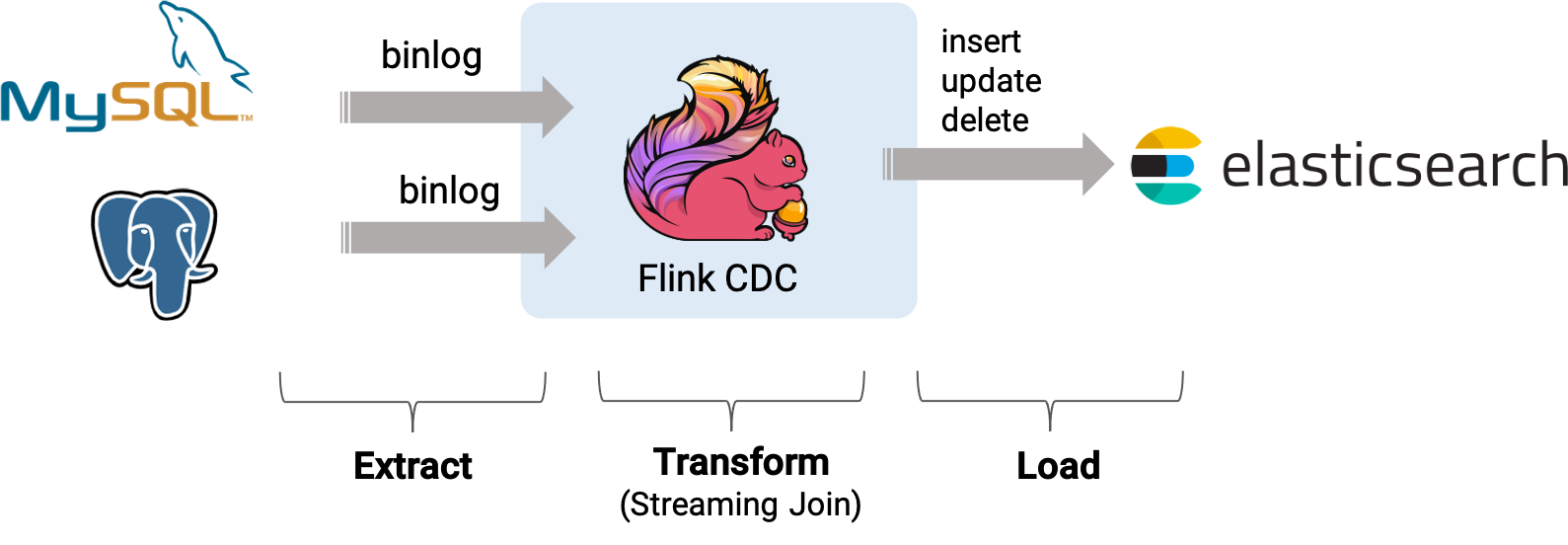
以下为实现本示例的具体步骤。
2)、环境准备
本文只是为了简单起见,尽可能的减少外部环境的依赖,所以使用了docker的环境,在实际工作中以实际的环境而定。
在使用flink cdc时可以不需要使用docker和docker-compose。
需要具备的环境是Flink 集群、flink cdc相应的jar包、数据源和数据目标相关的集群或单机。
如果不是用docker环境,本示例的步骤可以跳过环境准备、创建 docker-compose.yml即可。
需要安装docker、docker-compose,不再赘述。
验证环境是否安装成功通过查看其版本号。
[root@server5 ~]# docker --version
Docker version 25.0.0, build e758fe5
[root@server5 ~]# docker-compose --version
docker-compose version 1.29.2, build unknown
3)、创建 docker-compose.yml
version: '2.1'
services:
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=root
- MYSQL_PASSWORD=123456
elasticsearch:
image: elastic/elasticsearch:7.6.0
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
kibana:
image: elastic/kibana:7.6.0
ports:
- "5601:5601"
该 Docker Compose 中包含的容器有:
- MySQL: user表 将存储在该数据库中
- Elasticsearch: 将表user数据 写到 Elasticsearch
- Kibana: 用来可视化 ElasticSearch 的数据
在 docker-compose.yml 所在目录下执行下面的命令来启动本示例需要的组件:
docker-compose up -d
该命令将以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。
可以通过 docker ps 来观察上述的容器是否正常启动了,
[root@server5 docker-compose]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
161f678695ee elastic/elasticsearch:7.6.0 "/usr/local/bin/dock…" 10 minutes ago Up 10 minutes 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp docker-compose_elasticsearch_1
49ceac9a6237 elastic/kibana:7.6.0 "/usr/local/bin/dumb…" 10 minutes ago Up 10 minutes 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp
也可以通过访问 http://server5:5601/ 来查看 Kibana 是否运行正常。

以上,则完成了docker组件的启动。
4)、下载 Flink 和所需要的依赖包
1、部署flink 1.18版本
不再赘述
2、下载本示例需要用到的connector
本示例需要用到2个jar包,具体如下
- flink-cdc-pipeline-connector-mysql-3.0.0.jar
- flink-sql-connector-elasticsearch7-3.0.1-1.17.jar
[root@server5 bin]# pwd
/usr/local/bigdata/flink-1.18.0/lib
[root@server5 lib]# ll
总用量 254792
-rw-r--r-- 1 root root 23763584 1月 24 16:11 flink-cdc-pipeline-connector-mysql-3.0.0.jar
-rw-r--r-- 1 501 games 196577 10月 19 07:34 flink-cep-1.18.0.jar
-rw-r--r-- 1 501 games 554410 10月 19 07:36 flink-connector-files-1.18.0.jar
-rw-r--r-- 1 501 games 102375 10月 19 07:39 flink-csv-1.18.0.jar
-rw-r--r-- 1 501 games 127071526 10月 19 07:44 flink-dist-1.18.0.jar
-rw-r--r-- 1 501 games 202901 10月 19 07:38 flink-json-1.18.0.jar
-rw-r--r-- 1 501 games 21058483 10月 19 07:43 flink-scala_2.12-1.18.0.jar
-rw-r--r-- 1 root root 28440546 1月 24 16:11 flink-sql-connector-elasticsearch7-3.0.1-1.17.jar
-rw-r--r-- 1 501 games 15527413 10月 19 07:44 flink-table-api-java-uber-1.18.0.jar
-rw-r--r-- 1 501 games 38202299 10月 19 07:43 flink-table-planner-loader-1.18.0.jar
-rw-r--r-- 1 501 games 3437154 10月 19 07:34 flink-table-runtime-1.18.0.jar
-rw-r--r-- 1 501 games 208006 9月 23 2022 log4j-1.2-api-2.17.1.jar
-rw-r--r-- 1 501 games 301872 9月 23 2022 log4j-api-2.17.1.jar
-rw-r--r-- 1 501 games 1790452 9月 23 2022 log4j-core-2.17.1.jar
-rw-r--r-- 1 501 games 24279 9月 23 2022 log4j-slf4j-impl-2.17.1.jar
5)、启动flink
[root@server5 bin]# pwd
/usr/local/bigdata/flink-1.18.0/bin
[root@server5 bin]# ll
总用量 2356
-rw-r--r-- 1 501 games 2290658 10月 19 07:44 bash-java-utils.jar
-rwxr-xr-x 1 501 games 23051 10月 19 04:07 config.sh
-rwxr-xr-x 1 501 games 1318 10月 19 04:07 find-flink-home.sh
-rwxr-xr-x 1 501 games 2381 10月 19 04:07 flink
-rwxr-xr-x 1 501 games 4722 10月 19 04:07 flink-console.sh
-rwxr-xr-x 1 501 games 6783 10月 19 04:07 flink-daemon.sh
-rwxr-xr-x 1 501 games 1564 10月 19 04:07 historyserver.sh
-rwxr-xr-x 1 501 games 2498 10月 19 04:07 jobmanager.sh
-rwxr-xr-x 1 501 games 1650 10月 19 04:07 kubernetes-jobmanager.sh
-rwxr-xr-x 1 501 games 1717 10月 19 04:07 kubernetes-session.sh
-rwxr-xr-x 1 501 games 1770 10月 19 04:07 kubernetes-taskmanager.sh
-rwxr-xr-x 1 501 games 2994 10月 19 04:07 pyflink-shell.sh
-rwxr-xr-x 1 501 games 4166 10月 19 04:07 sql-client.sh
-rwxr-xr-x 1 501 games 3299 10月 19 04:07 sql-gateway.sh
-rwxr-xr-x 1 501 games 2006 10月 19 04:07 standalone-job.sh
-rwxr-xr-x 1 501 games 1837 10月 19 04:07 start-cluster.sh
-rwxr-xr-x 1 501 games 1854 10月 19 04:07 start-zookeeper-quorum.sh
-rwxr-xr-x 1 501 games 1617 10月 19 04:07 stop-cluster.sh
-rwxr-xr-x 1 501 games 1845 10月 19 04:07 stop-zookeeper-quorum.sh
-rwxr-xr-x 1 501 games 2960 10月 19 04:07 taskmanager.sh
-rwxr-xr-x 1 501 games 1725 10月 19 04:07 yarn-session.sh
-rwxr-xr-x 1 501 games 2405 10月 19 04:07 zookeeper.sh
[root@server5 bin]# ./start-cluster.sh
[root@server5 bin]# jps
10130 Jps
26884 TaskManagerRunner
26537 StandaloneSessionClusterEntrypoint
6)、准备mysql数据
本示例使用的数据库是192.168.10.44上cdctest的user表,创建完成后添加几条数据,具体sql如下
SET NAMES utf8mb4;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, 'alan', 18);
INSERT INTO `user` VALUES (2, 'alanchan', 20);
INSERT INTO `user` VALUES (3, 'alanchanchn', 33);
INSERT INTO `user` VALUES (4, 'alanchanchn2', 100);
7)、在sql client中的操作
下面的步骤均是在Flink sql client中操作的。
- 启动sql client
sql-client.sh
- 设置sql client
SET sql-client.execution.result-mode = tableau;
SET execution.checkpointing.interval = 3s;
Flink SQL> SET sql-client.execution.result-mode = tableau;
[INFO] Execute statement succeed.
Flink SQL> SET execution.checkpointing.interval = 3s;
[INFO] Execute statement succeed.
- 创建cdc表
Flink SQL> CREATE TABLE f_user (
> id INT,
> name STRING,
> age INT,
> PRIMARY KEY (id) NOT ENFORCED
> ) WITH (
> 'connector' = 'mysql-cdc',
> 'hostname' = '192.168.10.44',
> 'port' = '3306',
> 'username' = 'root',
> 'password' = '123456',
> 'database-name' = 'cdctest',
> 'table-name' = 'user'
> );
[INFO] Execute statement succeed.
Flink SQL> select * from f_user;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 2 | alanchan | 20 |
| +I | 1 | alan | 18 |
| +I | 4 | alanchanchn2 | 100 |
| +I | 3 | alanchanchn | 33 |
Flink SQL> CREATE TABLE e_f_user (
> id INT,
> name STRING,
> age INT,
> PRIMARY KEY (id) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://server5:9200',
> 'index' = 'e_f_user'
> );
[INFO] Execute statement succeed.
说明:
本示例使用的是本机的elasticsearch,也可以使用外部的elasticsearch,操作方式一样,不再赘述。
示例如下
# 创建外部elasticsearch的cdc表
Flink SQL> CREATE TABLE e_f_user2 (
> id INT,
> name STRING,
> age INT,
> PRIMARY KEY (id) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://server1:9200',
> 'index' = 'e_f_user'
> );
[INFO] Execute statement succeed.
# 提交flink 任务
Flink SQL> insert into e_f_user2 select * from f_user;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 95d884058ad293bb2c567619348c02cd
- 将f_user数据写入到elasticsearch的e_f_user表中
本处仅仅是简单的把数据写进去即可,实际上可以做一些复杂的计算操作后再写进去,不再赘述
Flink SQL> insert into e_f_user select * from f_user;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: fadea2443e580767903428d061db955d
此时通过flink的web 界面可以看到Flink 已经有任务在运行了,如下图
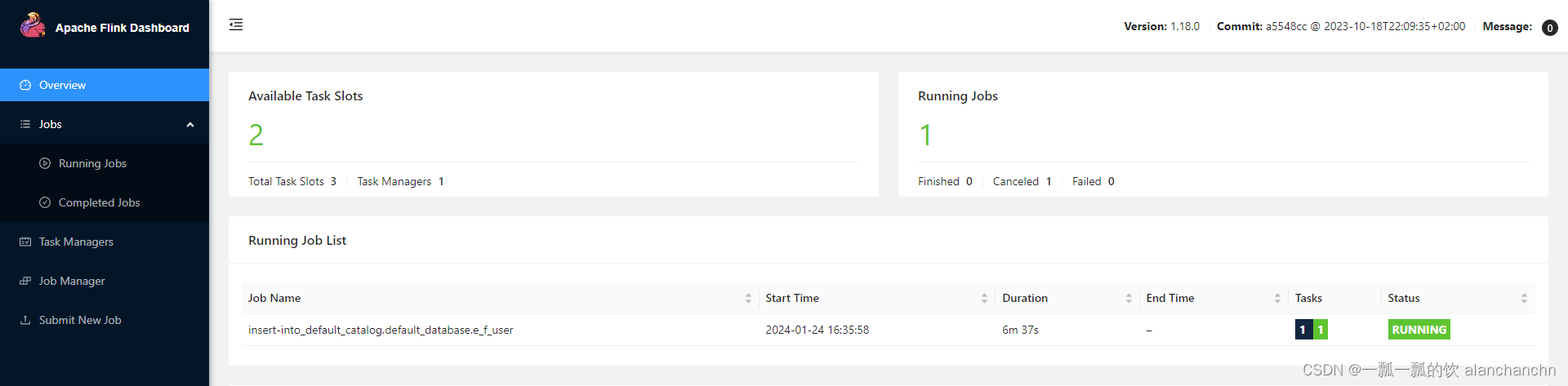
8)、Elasticsearch中查看同步的数据情况
下面是通过kibana中查看写入elasticsearch中的数据,具体操作详细内容可以参看文章:
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
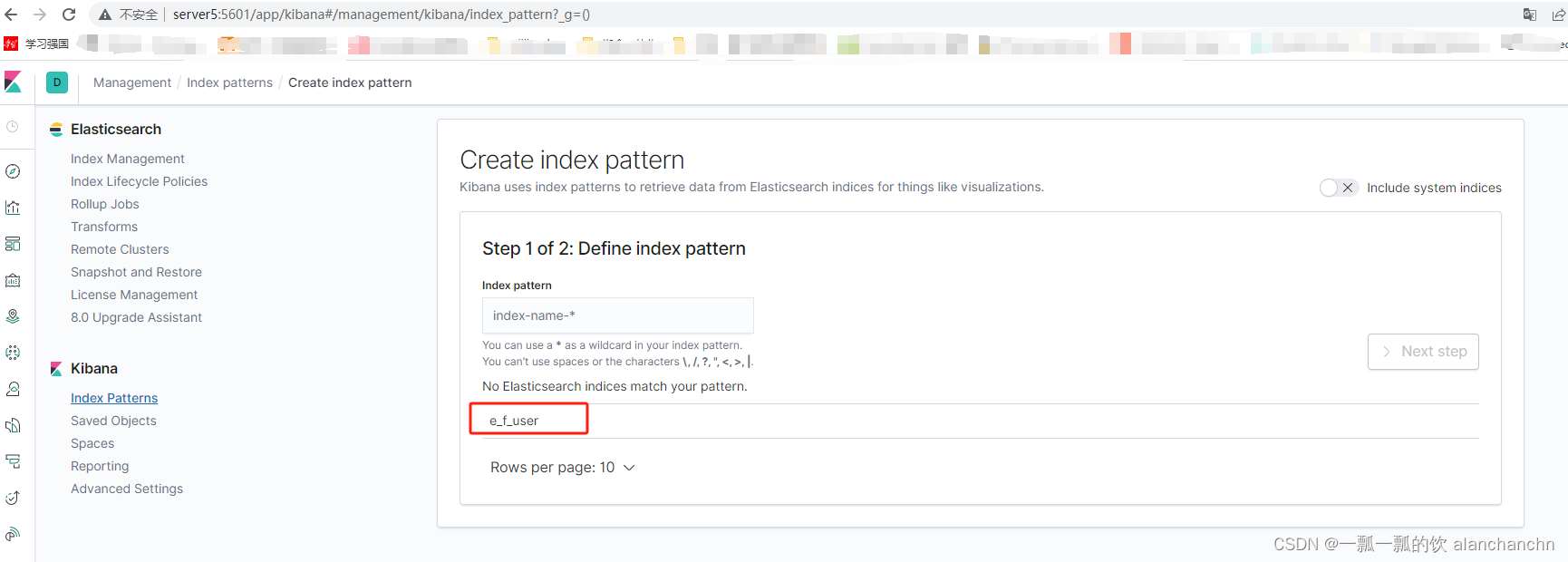


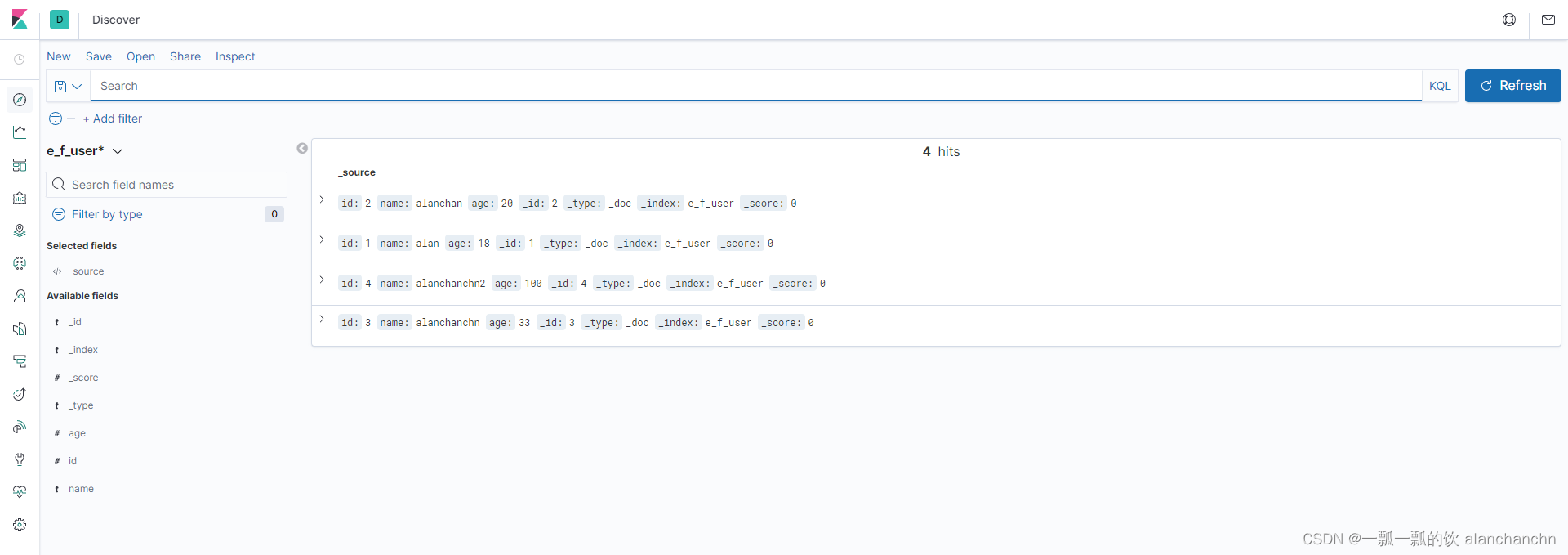
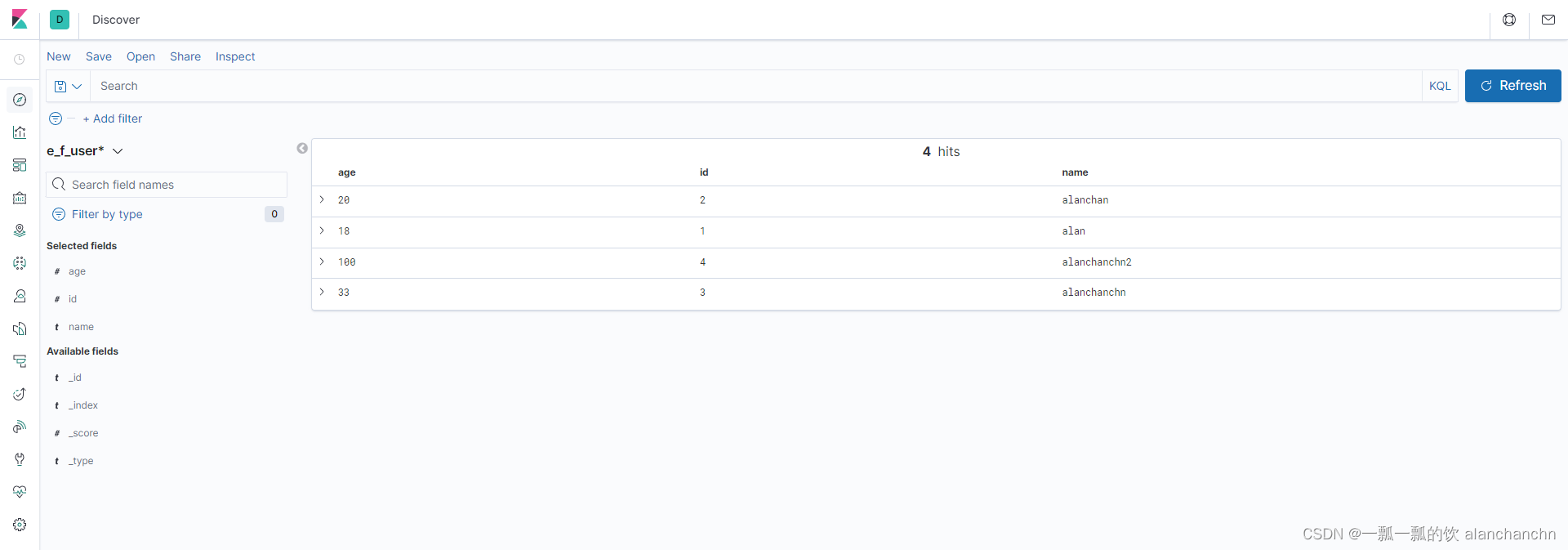
9)、CUD(create、update和delete)操作演示
下面是演示在mysql中操作数据,在elasticsearch中的变化情况。
- 新增一条数据
mysql中插入一条数据
INSERT INTO `user` VALUES (5000, 'testname', 8888888);
Elasticsearch的kibana刷新后的变化,红框内是刷新后的数据
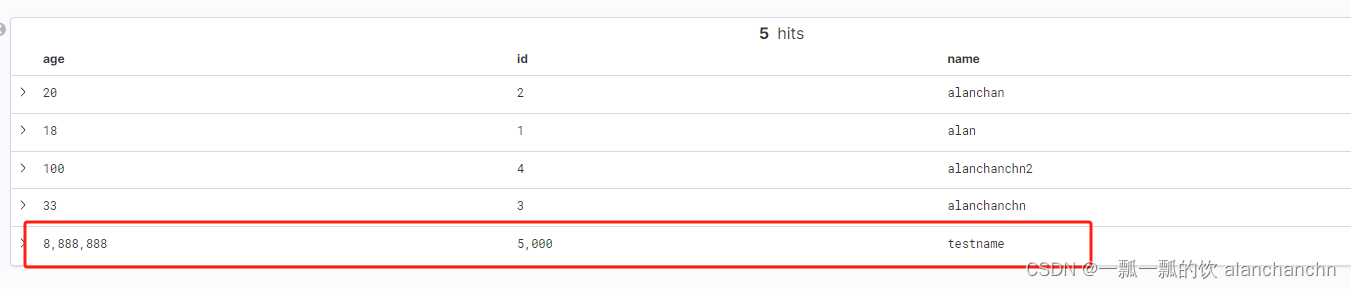
- 修改一条数据
mysql中针对ID=5000的数据,将name修改成testname5000,age修改成6666
update user set name = 'testname5000',age=6666 where id =5000
Elasticsearch的kibana刷新后的变化,红框内是刷新后的数据

- 删除数据
在mysql中将id=5000的数据删除掉
Elasticsearch的kibana刷新后的变化

10)、环境清理
在 docker-compose.yml 文件所在的目录下执行如下命令停止所有容器:
docker-compose down
以上,本文详细的介绍了Flink CDC的应用,并且提供三个示例进行说明如何使用,即使用Flink sql client的观察数据同步的情况、通过DataStream API 捕获数据变化情况以及通过完整示例应用Flink CDC的ELT操作步骤及验证。
本专题分为以下几篇文章:
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-CDC Connector介绍及示例 (1)
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-Streaming ELT介绍及示例(2)
60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-完整版



![[力扣 Hot100]Day18 矩阵置零](https://img-blog.csdnimg.cn/direct/815679871f0649c181a6f2e040df7f70.png)