👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:详解SpringCloud微服务技术栈:ElasticSearch实战(旅游类项目)
📚订阅专栏:微服务技术全家桶
希望文章对你们有所帮助
在之前已经了解了ElasticSearch的基本用法(DSL语句以及RestClient实现),并利用ElasticSearch做了一个旅游类项目加以巩固,现在要进行ElasticSearch更深入的内容,内容包括:
数据聚合:来对海量数据做统计和分析,结合kibana还能形成可视化的图形报表
自动补全:根据用户输入的部分关键字信息去补全关键字
数据同步:先分析MySQL与ElasticSearch的双写一致性问题,并给出对应的解决方案
集群:ES的集群和集群中不同角色的作用,并且搭建一个企业级的高可用的集群
深入ElasticSearch——数据聚合
- 数据聚合
- 聚合分类
- DSL实现Bucket聚合
- DSL实现Metrics聚合
- RestClient实现聚合
- 多条件聚合
- 带过滤条件的聚合
数据聚合
聚合分类
聚合可以实现对文档数据的统计、分析和运算。常见聚合有3类:

DSL实现Bucket聚合
现在要统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合。
MySQL里面直接用group by,而这里需要用Bucket聚合,具体来说是用的term聚合:
# 对价格小于200的做聚合,也可以不限定聚合的范围(不写query)
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0, # 设置size=0,表示结果中不包含文档,只包含聚合结果
"aggs": { # 定义聚合
"brandAgg": { # 给聚合起个名字
"terms": { # 聚合的类型,按照品牌,因此选择term
"field": "brand", # 参与聚合的字段
"size": 20 # 希望获取的聚合结果的数量,默认10
}
}
}
}
DSL实现Metrics聚合
获取每个品牌的用户评分的min、max、avg等值,因此要做聚合的嵌套,在每个bucket中做计算:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": { # 做排序,需要指定排序的字段
"scoreAgg.avg": "desc"
}
},
"aggs": { # 品牌聚合的自聚合,对每组分别做计算
"scoreAgg": { # 聚合名称
"stats": { # 聚合类型,stats可以计算min、max、avg
"field": "score" # 聚合字段
}
}
}
}
}
}
RestClient实现聚合
依然是通过DSL语句来写java语句:
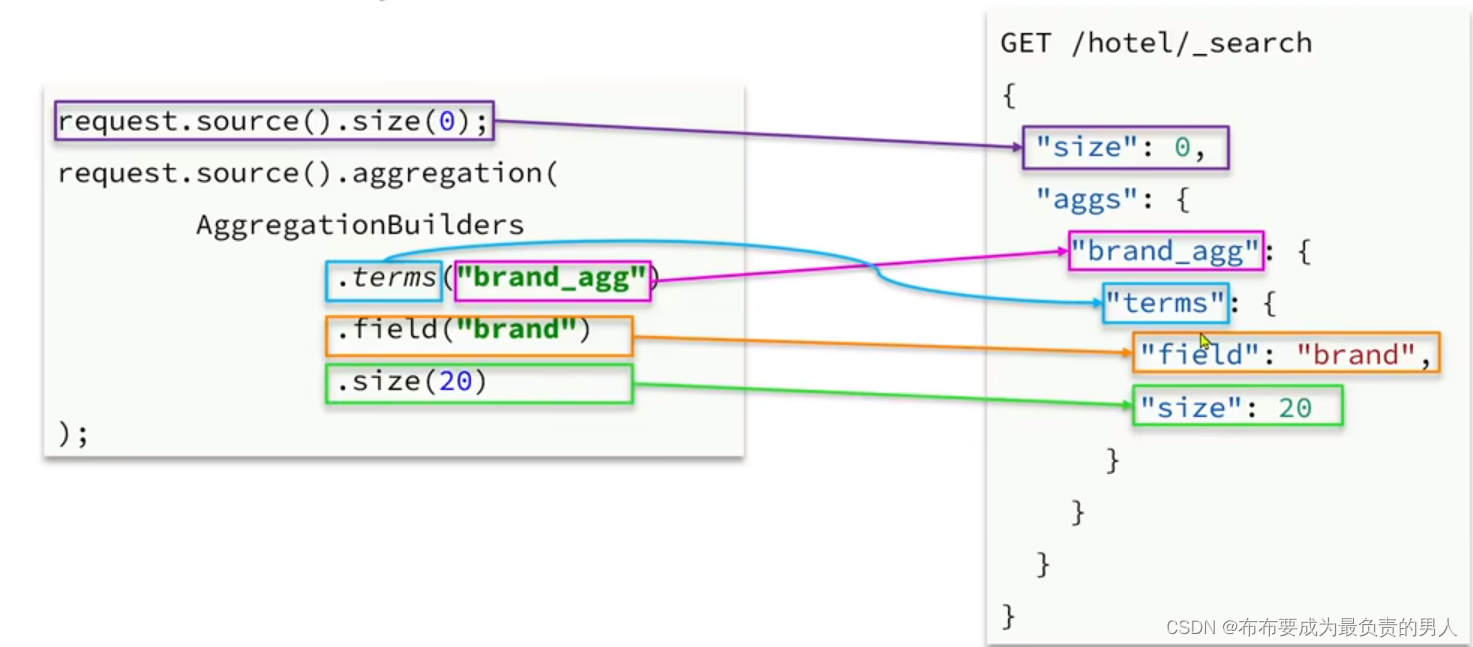
编写测试类:
@Test
void testAggregation() throws IOException {
//1.准备request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1 设置size,不需要查看文档,只要看聚合结果
request.source().size(0);
//2.1 聚合
request.source().aggregation(AggregationBuilders
.terms("brandAgg") //聚合名称"brandAgg",类型terms
.field("brand") //参与聚合的字段
.size(10)
);
//3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//打印即可查看输出的结构,对照结构来做逐层做解析
//System.out.println("response = " + response);
//4.解析结果
//4.1 获取聚合信息
Aggregations aggregations = response.getAggregations();
//4.2根据聚合名称获取聚合结果(之前是term类型这里返回的也是term类型)
Terms brandTerms = aggregations.get("brandAgg");
//4.3获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//4.4遍历buckets,取出每一个桶(分类)
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println("key = " + key);
}
}

多条件聚合
在IUserService接口中定义方法,实现对品牌、城市、星级的聚合(搜索页面的品牌、城市等信息不应该是在页面中写死的,而是通过聚合索引库中的酒店数据得来的)。
例如,我限定了价格的range为100-300,如果杭州不包含这样价位的酒店,那么导航栏上面的城市信息直接就不应该有杭州两个字
IUserService中声明方法:
/**
* 查询城市、星级、品牌的聚合效果
* @return 聚合结果,格式:{"城市": {"上海", "北京"}, "品牌": {"如家", "希尔顿"}}
*/
Map<String, List<String>> filters();
UserService实现方法体:
@Override
public Map<String, List<String>> filters() {
try {
//1.准备request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1设置size
request.source().size(0);
//2.2设置聚合
buildAggregation(request);
//3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
Map<String, List<String>> result = new HashMap<>(); //存放解析后的结果
Aggregations aggregations = response.getAggregations();
result.put("brand", getAggByName(aggregations, "brandAgg"));
result.put("city", getAggByName(aggregations, "cityAgg"));
result.put("starName", getAggByName(aggregations, "starAgg"));
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
List<String> list = new ArrayList<>(); //存放每个桶的value
Terms brandTerms = aggregations.get(aggName); //这里返回值不要默认,自行设置为Terms类型的
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
list.add(key);
}
return list;
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
可以在测试类中注入IUserService,调用方法查看运行结果:
@Resource
private IHotelService hotelService;
@Test
void contextLoads() {
Map<String, List<String>> filters = hotelService.filters();
System.out.println("filters = " + filters);
}

带过滤条件的聚合
聚合已经完成,但是聚合的结果还没有返回到前端,实际上前端页面会向服务端发起请求,查询品牌、城市、星级等字段的聚合结果,我们应当渲染完返还给前端。
查看前端的请求:

可以看到请求的参数和之前的list里面的是一样,这是因为需要限定一下范围,比如限定了城市为北京,搜索条件为“如家”,那么应该对北京的、名字带“如家”的酒店去做聚合,而不是所有的酒店,这样会大大提高效率。
1、编写controller接口,接受该请求
@PostMapping("/filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){
return hotelService.filters(params);
}
2、修改IUserService#getFilter()方法,添加RequestParam参数
Map<String, List<String>> filters(RequestParams params);
3、修改getFilters方法的业务,聚合时添加query条件
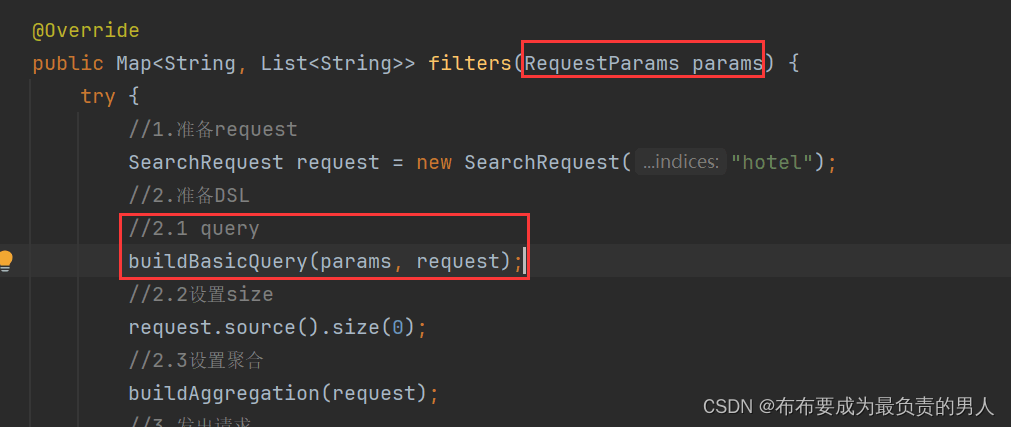
至此,数据聚合的实现已经完成。