今天我为大家介绍飞桨大模型分布式训练技术,内容分为以下几个部分:
首先,我会介绍大模型训练面临的重点难题;然后,为大家介绍飞桨在大模型训练领域的特色分布式训练技术和优化方案;最后,伴随着代码示例和大模型套件,为大家展示如何使用飞桨框架训练大模型。
1. 背景与挑战
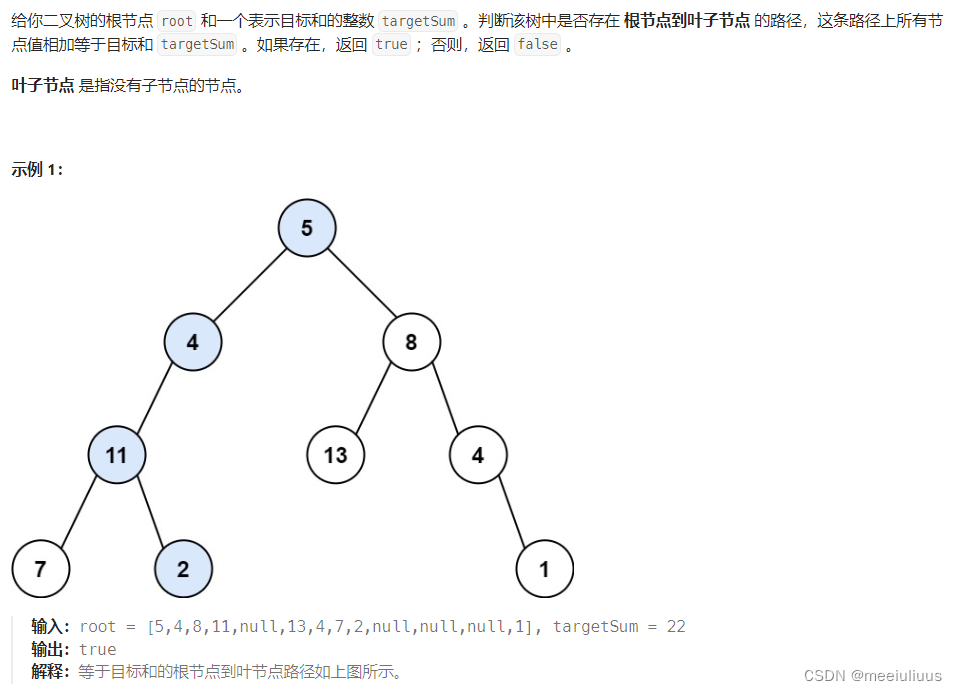
近年来,大模型由于良好的模型效果和广阔的应用前景,逐渐受到业界的广泛重视。主流的 AI 科技公司也站在了大模型研究的前沿,模型参数量的规模呈现快速增长的趋势。从 2018 年 1 亿参数规模的模型增长至今已达千亿参数量规模。
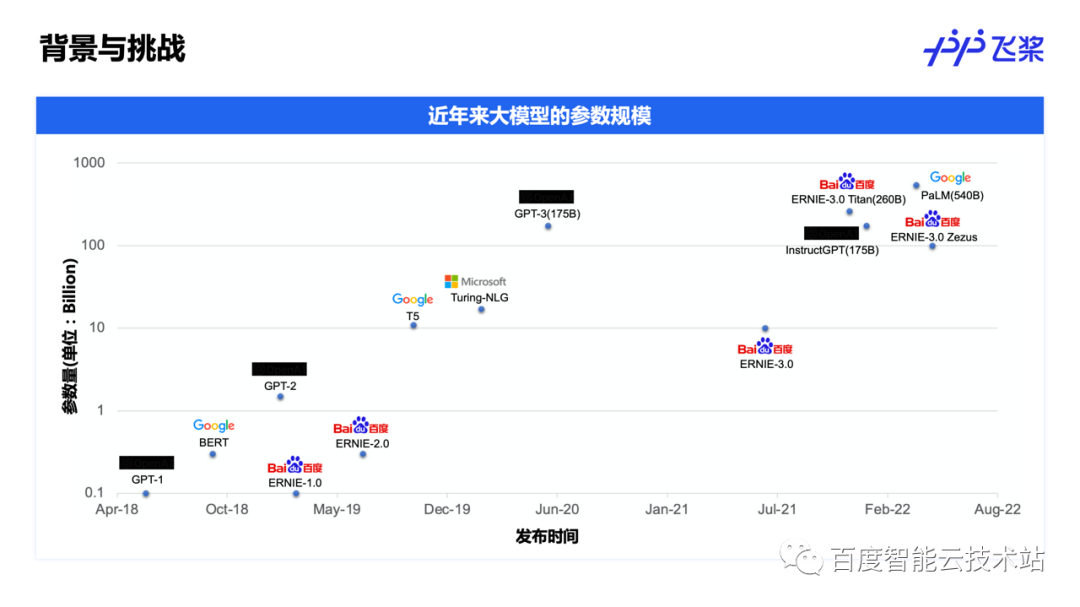
大模型的出现给模型训练带来极大的挑战。即使使用 A800、H800 这样的 GPU,单张 GPU 的算力和显存都是远远无法满足大模型训练需求的。为了保证大模型可训练,并提高整体训练吞吐,需要用到模型并行 + 数据并行等技术。
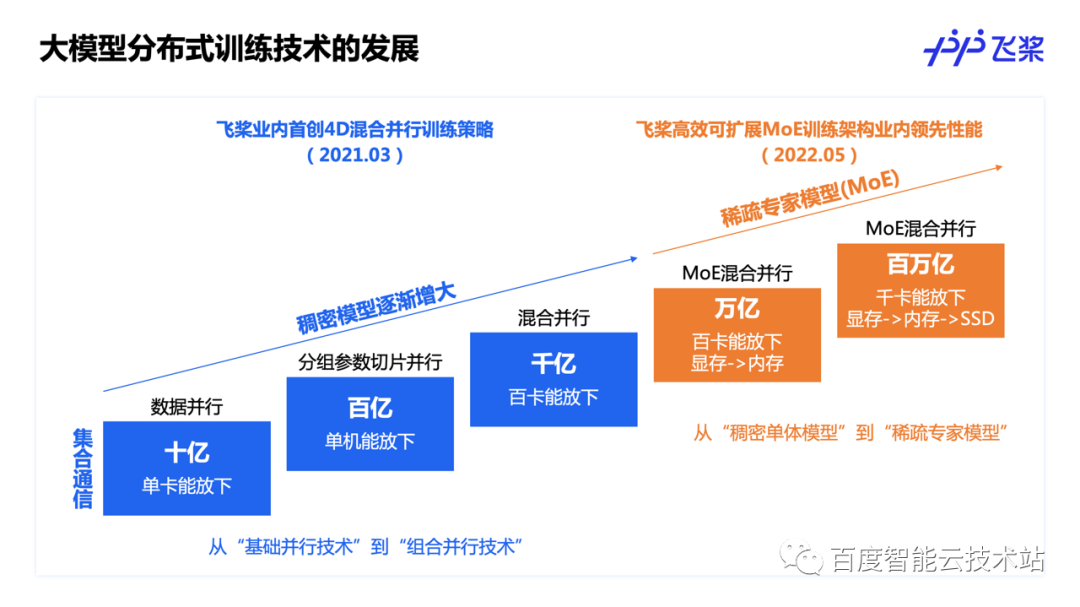
这张图展示的是大模型分布式训练技术的发展历程。
对于十亿及以下的模型,单卡往往就能放下全量模型参数和梯度,传统的数据并行即可即可覆盖其应用场景。当模型规模到了百亿量级以后,需要使用分组参数切片的方式将模型参数、梯度和优化器状态切分到各个卡上,保证单机可放下。当模型规模到了千亿以后,则需要同时使用模型并行、数据并行等多种并行技术混合进行高效训练。在这个阶段里,分布式并行技术从单一的基础并行策略演进为多种并行策略的组合。
当模型规模到了万亿级别以后,稠密模型已经难以高效训练,从而衍生出稀疏专家模型,也伴随着 MoE 等并行策略的演进与迭代。
下面,我将为大家介绍飞桨在大模型训练领域的特色分布式训练技术。
2. 飞桨大模型特色分布式训练技术
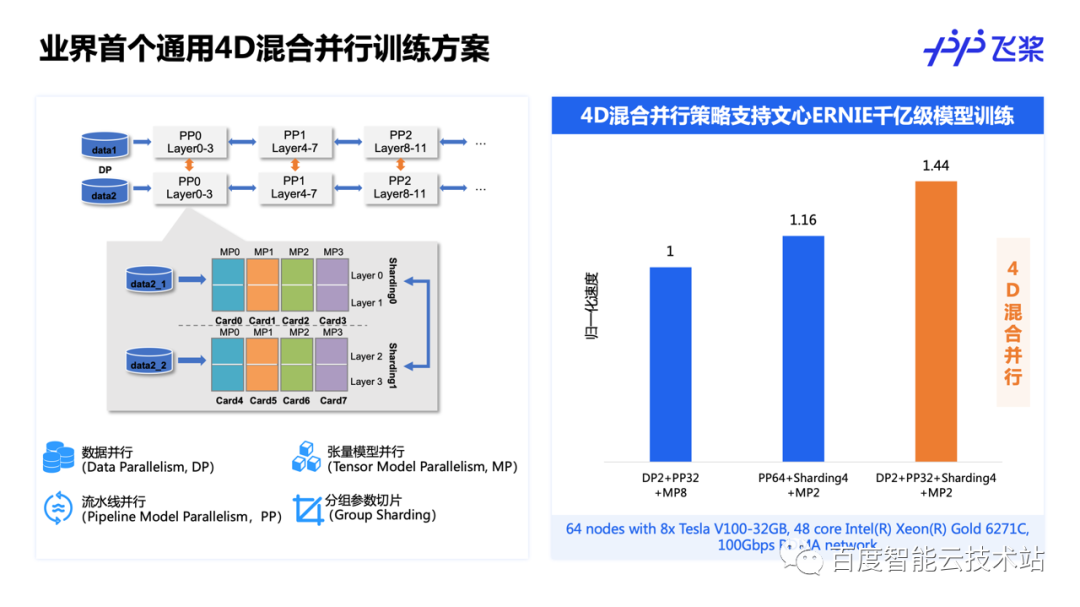
飞桨在 2021 年提出了业界首个 4D 混合并行训练方案,将数据并行、张量模型并行、流水线并行、分组参数切片并行有机结合起来,实现百亿、千亿参数稠密大模型的高效训练。
在最内层,我们进行张量模型并行以及 Sharding 的参数的切分,并使用流水线并行将张量模型并行和 Sharding 并行串联起来。在最外层,使用数据并行技术来提高整体训练吞吐。这种技术应用在了文心 ERNIE 千亿模型训练上,相较于 3D 混合并行方案获得了 24%~44% 的提速效果。
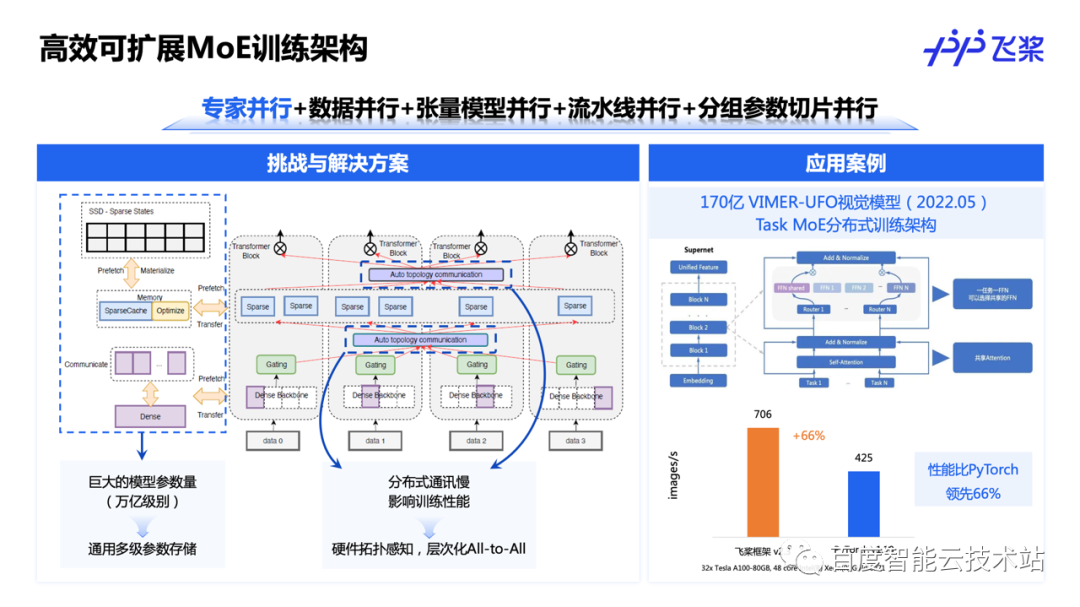
而在稀疏专家模型领域,飞桨在 2022 年提出了高效可扩展的 MoE 训练架构,并结合 4D 混合并行技术,解决稀疏专家模型训练效率低下的难题。
首先,MoE 训练面临的一个重要问题是巨大的参数量,参数量达到万亿级别,但是这些参数是高度稀疏的,MoE 的路由模块每次只会激活部分参数。针对这个问题,飞桨提出了通用多级参数存储的方案,将短期不使用到的参数先 offload 到 CPU 内存、甚至 offload 到 SSD 中去;当即将需要使用时,再从 CPU 内存或 SSD 中预先加载到显存中,保证模型训练和参数预加载 overlap 起来。
其次,MoE 训练面临的另一个重要问题是分布式通信慢,在 MoE 的路由模块里存在 All-to-All 通信,严重影响模型训练效率。飞桨提出了硬件拓扑自动感知技术,感知当前集群的拓扑信息,对 All-to-All 通信进行分层处理,提高分布式通信效率。这些技术最终应用在了百度在 2022 年发布的 VIMER-UFO 视觉大模型中,性能较 PyTorch 有 66% 的提升,达到业内领先水平。
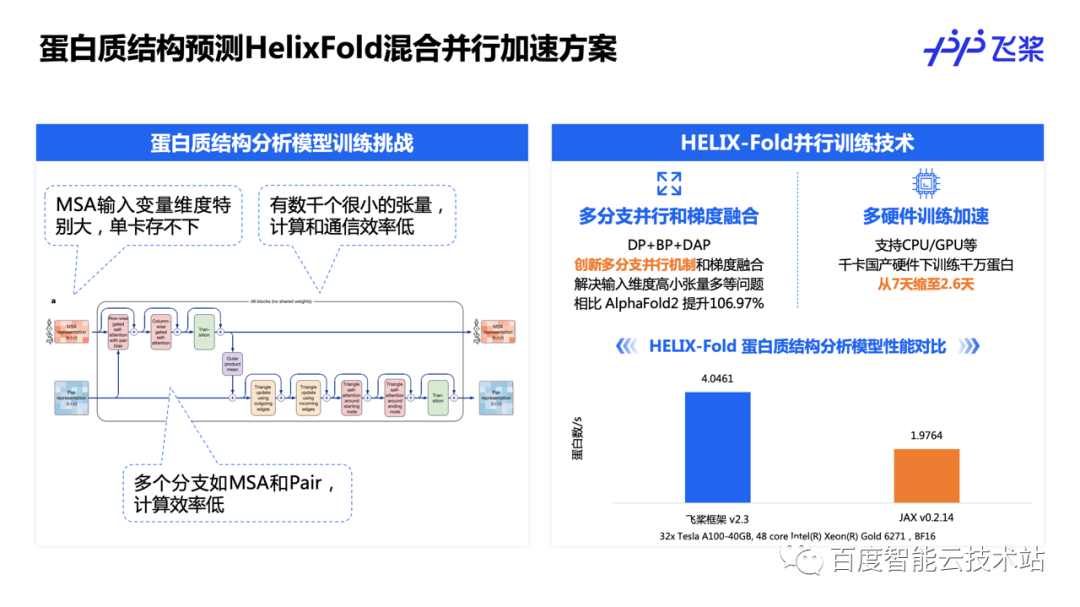
这页 PPT 展示的是蛋白质结构预测领域飞桨的混合并行加速方案。蛋白质结构预测模型中存在以下几个重点难题。其一,蛋白质结构预测中往往会引入 MSA 的维度,MSA 维度往往会特别大,导致单卡无法放下全量模型。其二,在模型训练过程中,模型中有多个分支结构,在传统的方案里这几个分支结构是串行执行的,计算效率较低。其三,模型训练过程中会产生许多很小的张量,数千个小张量的计算和通信都会造成较大的性能瓶颈。
为了解决这些问题,飞桨创新提出了分支并行方案,让模型中的多个分支结构运行在不同设备上,并在必要时候进行聚合。与此同时,我们融合了分支并行、数据并行和动态轴并行形成了 3D 混合并行方案,并使用梯度融合的方式解决数千个小张量计算和通信慢的问题,相比于 AlphaFold 2 获得了 106% 的性能提升。同时,我们使用该方案在千卡国产硬件上训练蛋白质预测模型,整体训练时长从 7 天缩短到了 2.6 天,极大提高了训练效率。
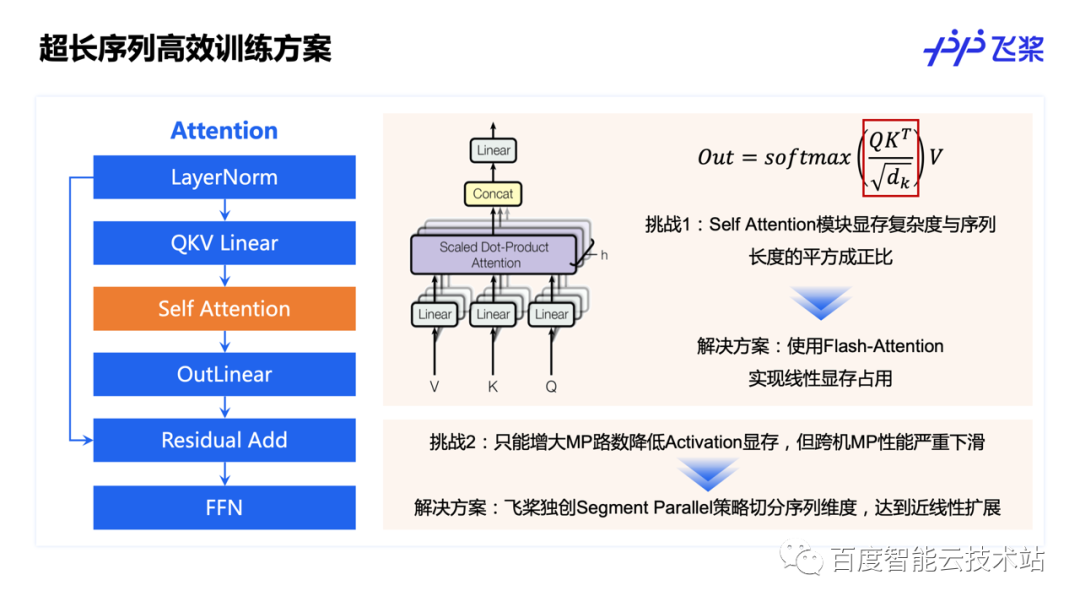
这页 PPT 展示的是飞桨在超长序列训练领域的解决方案。目前许多大模型采用的是 Transformer 的结构,Transformer 结构里的 Self Attention 模块的显存占用是与序列长度的平方成正比的,这给超长序列训练带来极大的挑战。针对这个问题,飞桨集合了 FlashAttention 方案,可将 Attention 模块的显存占用从平方复杂度降低到线性复杂度。
但是,即使将 Attention 模块的显存占用从平方复杂度降低到线性复杂度,整个网络里 Activation 的显存占用仍然与序列长度成正比,当序列长度达到 16K、32K 时会面临巨大的显存压力。而在多种并行策略中,基本只有张量模型并行才能节省 Activation 的显存占用,但当张量模型并行大约 8 后,就会面临跨机的问题,跨机张量模型并行会造成性能的严重下滑。
针对这个问题,飞桨独创了 Segment Parallel 的策略切分序列维度,且可以与数据并行、张量模型并行、序列并行、流水线并行等方案自由组合,达到近线性扩展。
以上介绍的是在某些特定场景下的分布式并行策略。
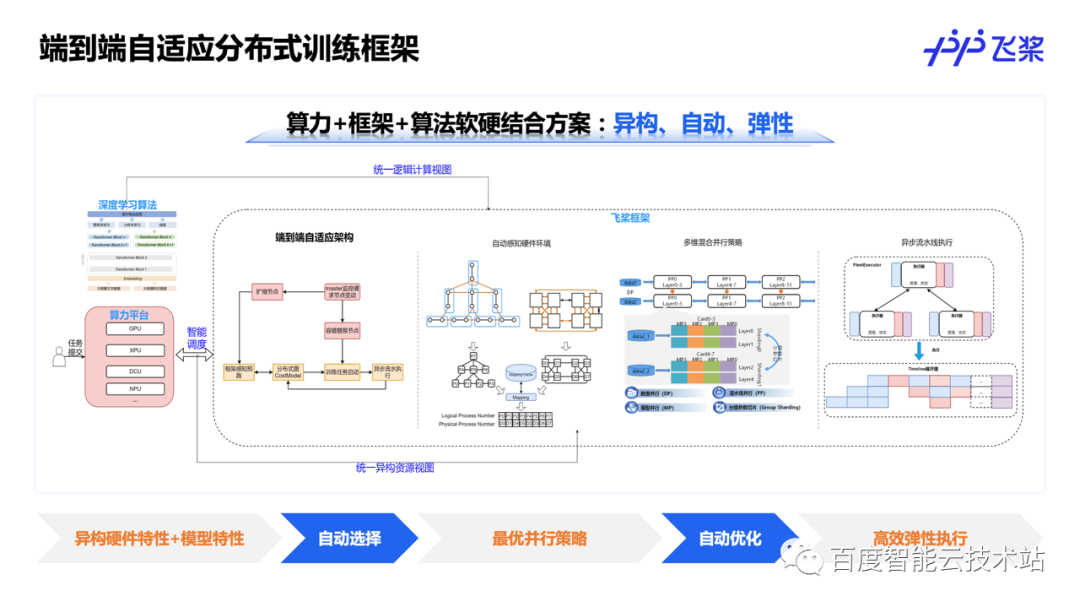
但是,实际大模型训练过程是非常复杂的,如何根据当前模型结构和集群环境找出最佳的分布式并行策略是十分困难的。针对这个问题,飞桨提出了端到端自适应分布式训练框架,我们通过建立统一的逻辑计算视图表征大模型的模型结构和算力要求,建立统一的异构资源视图表征算力环境和网络环境,结合分布式代价模型,自动搜索出适合当前模型和资源状况的最优并行策略,并进行资源的弹性调度。
以上介绍的是飞桨特色大模型分布式并行策略,下面我为大家介绍飞桨的大模型端到端性能优化方案。
3. 飞桨大模型端到端性能优化方案
下图展示的是飞桨的大模型端到端性能优化方案,涵盖数据读取、模型实现、高性能算子实现和分布式策略优化等模型训练全链条。
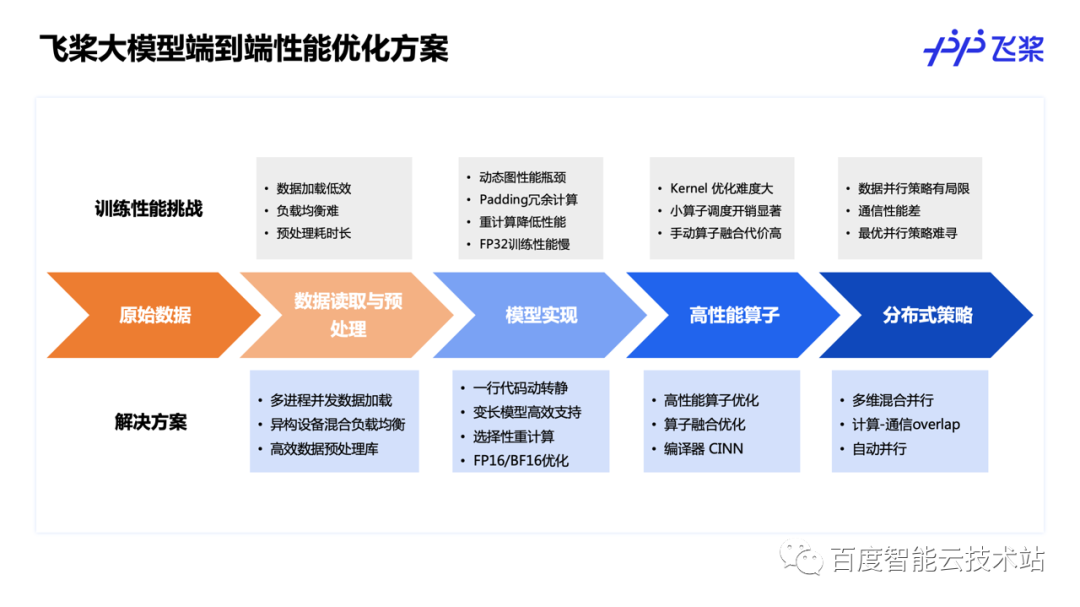
在原始数据读取方面,飞桨提供了多进程数据读取 + 每个进程独享数据队列的方式加速数据读取过程,防止 Python 端 GIL 锁以及队列资源抢占导致数据加载低效等问题。
在模型训练过程中,往往还需要对原始数据进程预处理。飞桨在 CV 领域提供了 FlyCV 库,提供高效的图像预处理能力;在 NLP 领域提供了 FastTokenizer,性能达到业内领先水平。
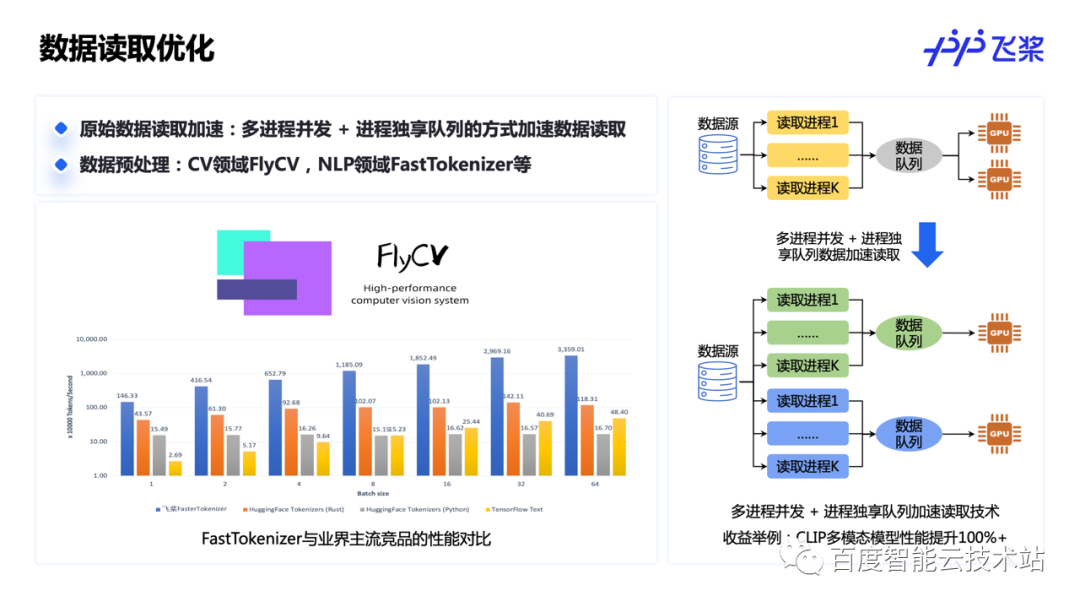
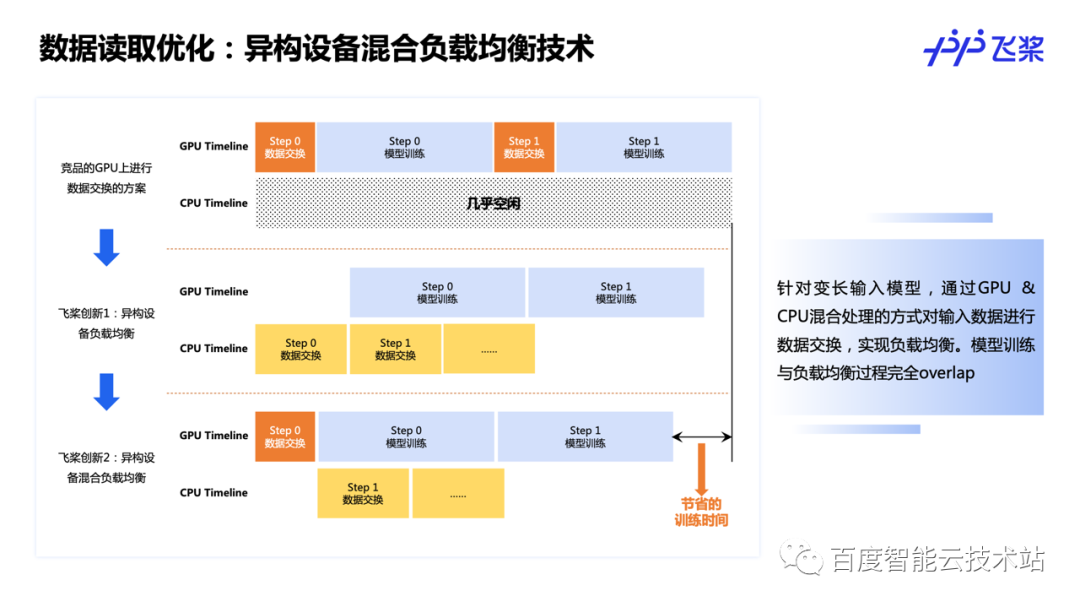
这里是我们针对变长输入模型数据预处理的优化技术。在变长输入下,各设备间的计算负载是不均等的,需要对输入数据进行负载均衡处理保证计算的均衡性。飞桨提出了 GPU + CPU 混合处理的方式对输入数据进行数据交换,实现负载均衡,且让负载均衡过程与模型训练过程完全 overlap,提高大模型整体训练速度。
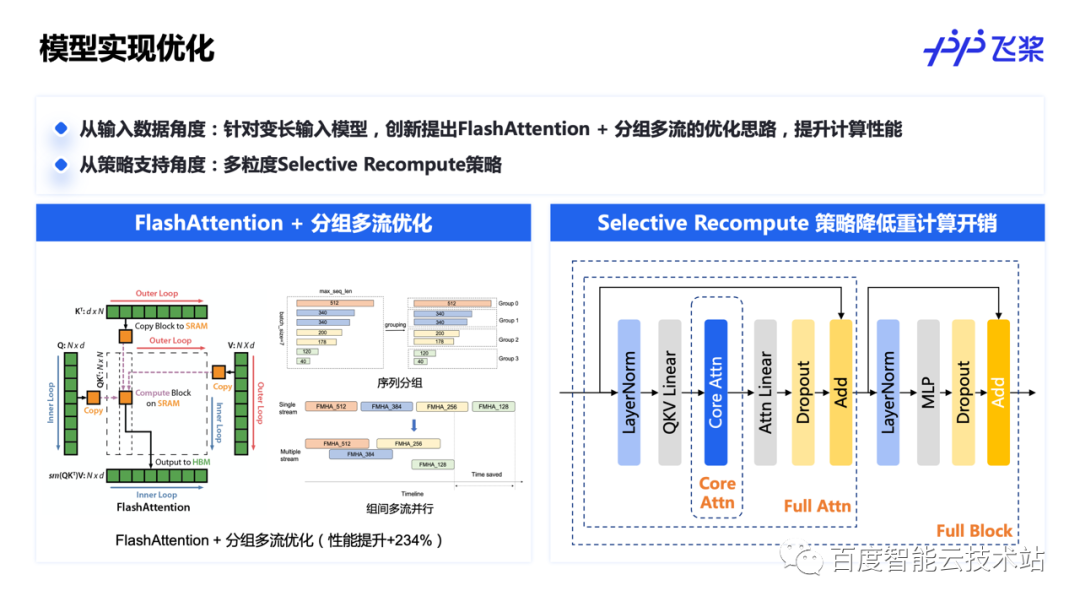
在模型实现层面,飞桨也做了许多优化工作。例如,针对变长输入模型,飞桨提出了 FlashAttention + 分组多流的优化思路,在 FlashAttention 的基础上对变长输入进行分组并发计算,提高整体训练吞吐。除此以外,我们还针对 Transformer 类模型进行了多粒度的选择性重计算策略,用户可以根据当前显存占用情况选取最佳的重计算策略,达到计算性能和显存占用之间的平衡。
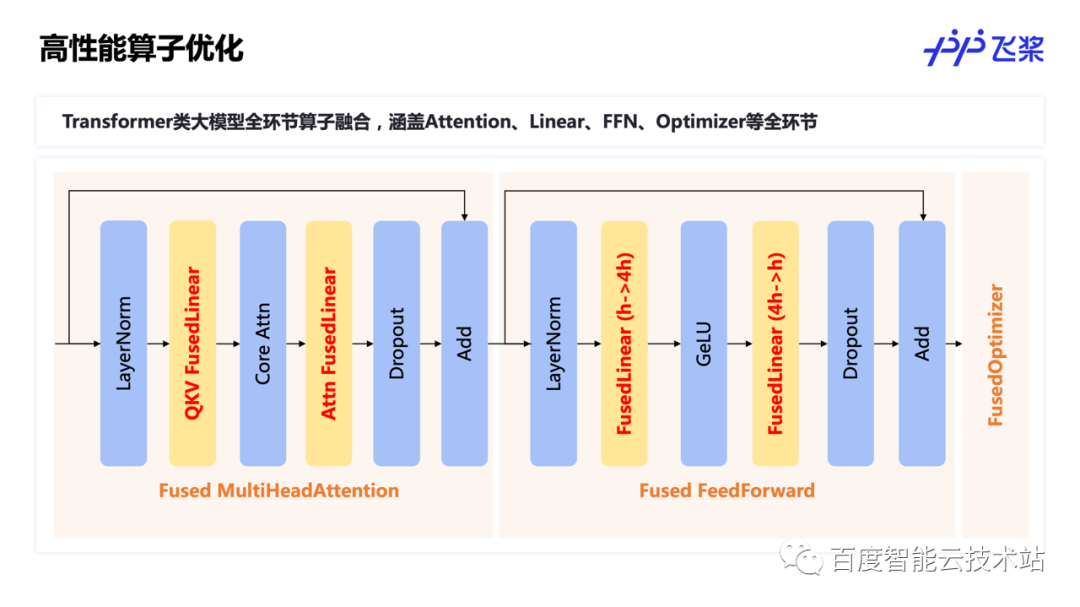
在高性能算子优化方面,针对 Transformer 类大模型,飞桨实现了全环节的算子融合策略,涵盖 Attention、Linear、FFN、Optimizer 等模型的每一个环节,发挥极致的硬件性能。
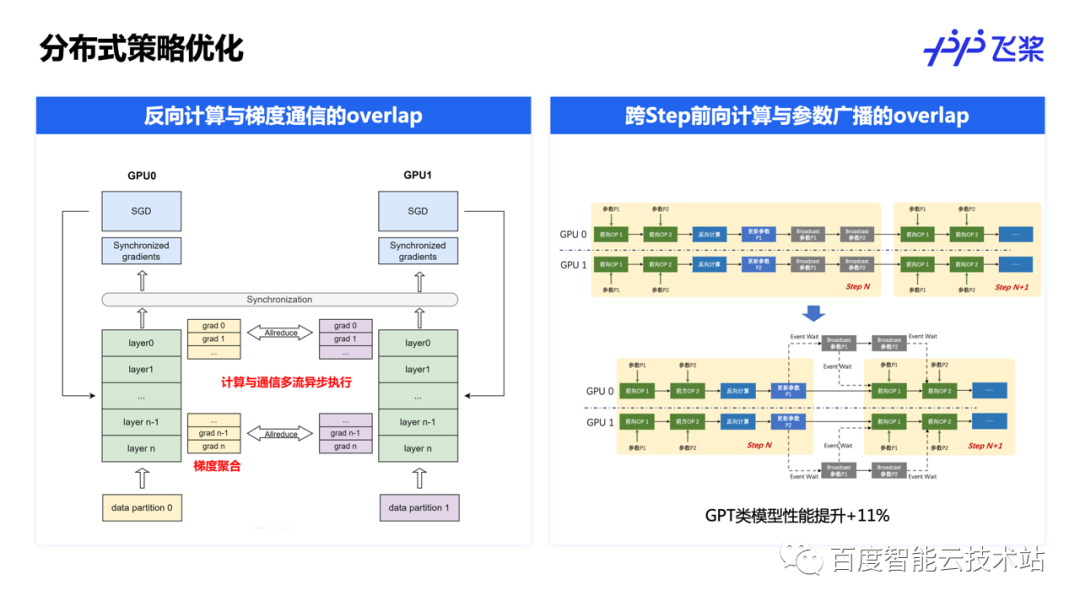
在分布式策略优化方面,除了常规的反向计算与梯度通信的 overlap 外,飞桨还创新提出了跨 step 的前向计算与参数广播的 overlap,让上一个 step 的参数广播与下一个 step 的前向计算并发执行,在 GPT 类大模型上可获得 11% 左右的提速。
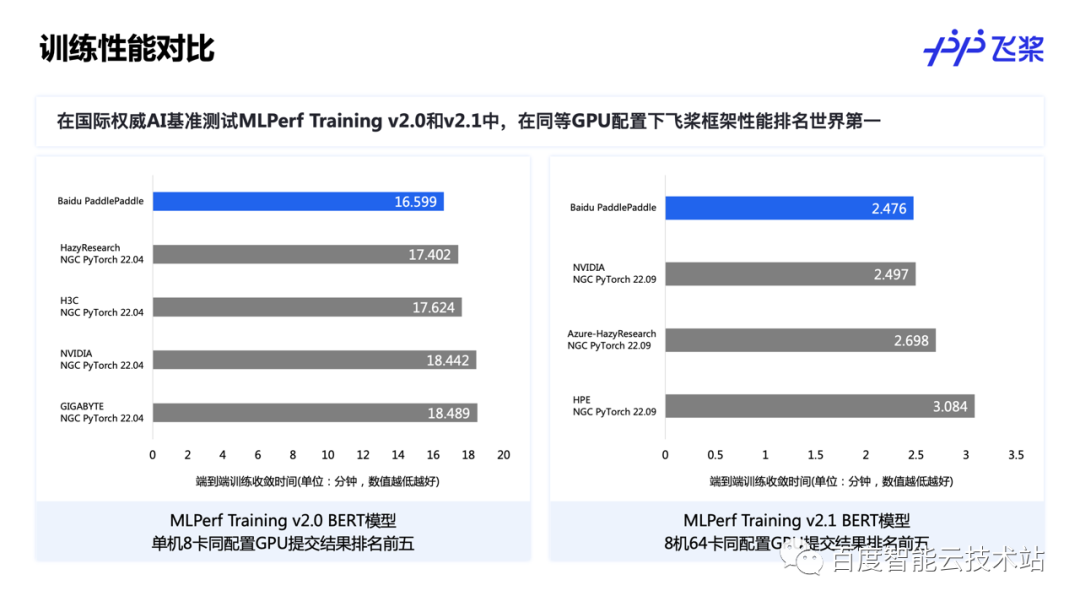
结合上述在大模型上的性能优化工作,我们使用飞桨框架在国际权威 AI 基准测试 MLPerf Training v2.0 和 MLPerf Training v2.1 上提交了 BERT 模型的单机和多机性能数据。在同等 GPU 配置下,飞桨框架性能排名世界第一。
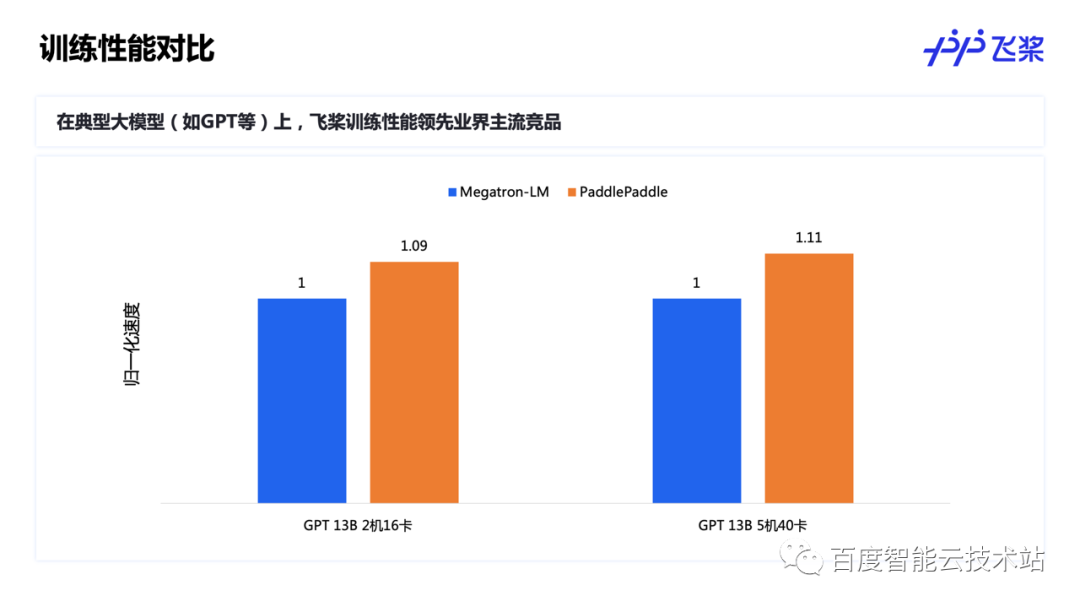
同样地,我们在 GPT 等典型大模型上也是达到了业内领先的效果。下图展示的 GPT 百亿模型 Megatron-LM 和飞桨的性能对比结果。飞桨相较 Megatron-LM 有 9%~11% 的提速。
以上介绍的是飞桨在大模型分布式训练上的特色技术。下面我将用几个实践案例,为大家介绍如何使用飞桨框架来训练大模型。
4. 飞桨大模型应用实践
首先介绍的是飞桨的大模型套件 PaddleFleetX。PaddleFleetX 的定位是端到端大模型套件,它打通了大模型预训练-有监督精调-压缩-推理等开发部署全流程,降低大模型的入门门槛。这里贴的是 PaddleFleetX 的 github 地址,感兴趣的听众可以尝试使用。(https://github.com/PaddlePaddle/PaddleFleetX)

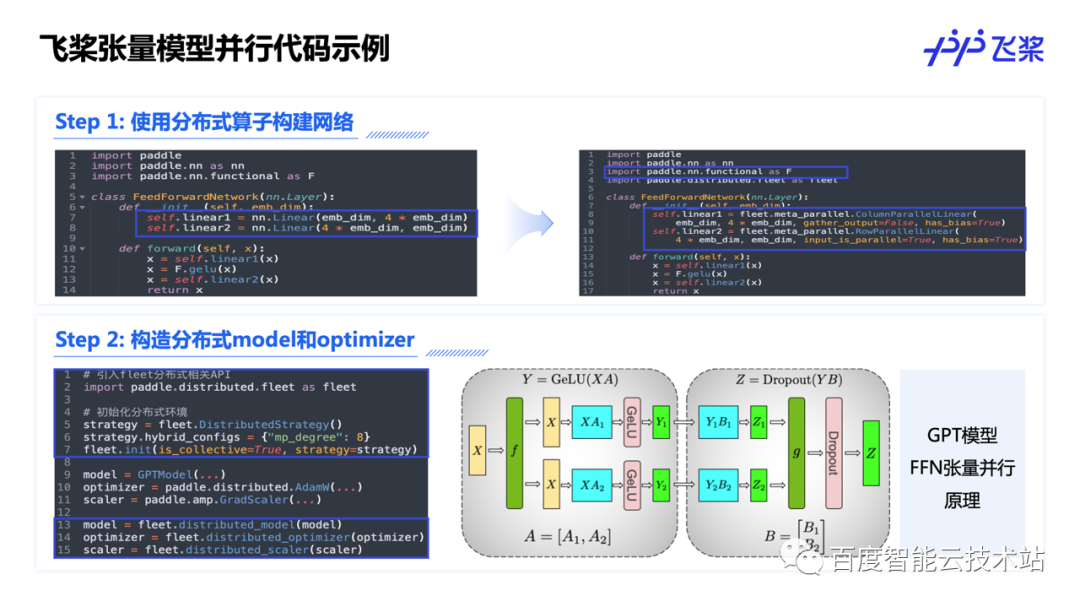
下面我首先介绍下如何使用飞桨实现混合并行的模型。首先介绍的是张量模型并行的例子。在 GPT 的 FFN 结构里有 2 个 Linear 层。变成张量模型并行的代码,只需要把这两个 Linear 层对应地替换成飞桨的张量模型并行 API 即可。与此同时,在模型组网结束后,调用 distributed_model、distributed_optimizer 等 API 将单机模型转换为分布式模型即可。
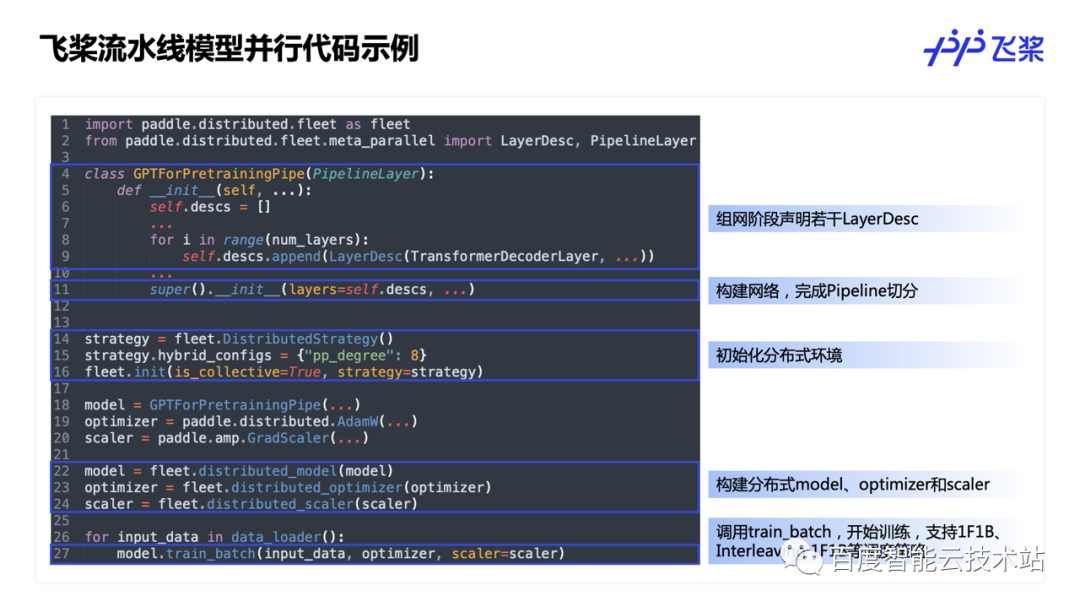
这里介绍的是一个流水线模型并行的代码例子。与其他并行方式不同,流水线是做的层间的切分,不同设备分到不同的层,因此组网写法上会有一定的特殊性。首先,我们需要定义若干的 LayerDesc,每个 LayerDesc 对应网络中的每一层。然后,同样地,将由 LayerDesc 组出来的网络调用 distributed_model、distributed_optimizer 等 API 将单机模型转换为分布式模型即可。最后调用 train_batch 这个 API 进行流水线并行调度。
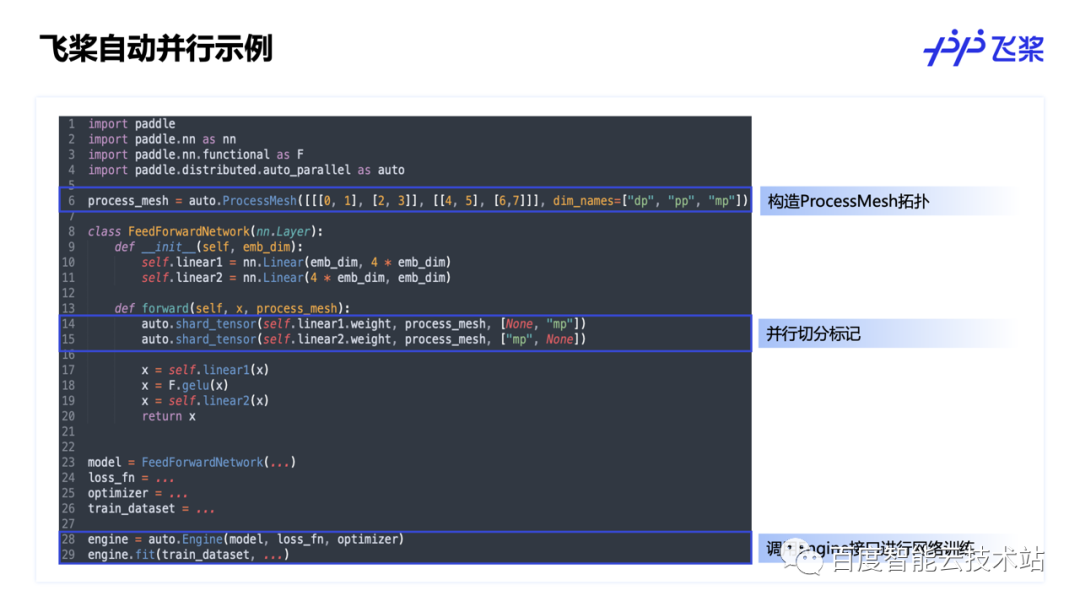
上述讲的 2 个例子偏手动并行,即用户组网的时候需要感知这是个分布式程序。这里给大家展示的是一个单卡组网 + 简单的分布式标记即可自动转换为分布式程序的例子。
这里涉及的是飞桨的自动并行技术。用户在组网的时候写的是单卡的程序,通过调用自动并行的 shard_tensor 等 API 标记部分 tensor 应做什么样的分布式切分。最后调用 Engine 接口,内部会自动将用户的单卡组网转换为分布式组网,并进行训练。
以上是我今天分享的全部内容。


![[Python] 什么是集成算法,什么是随机森林?随机森林分类器(RandomForestClassifier)及其使用案例](https://img-blog.csdnimg.cn/direct/79e713806e64427fb4c30aa40850d423.png)