什么是集成算法?
集成算法是一种机器学习方法,它将多个基本的学习算法(也称为弱学习器)组合在一起,形成一个更强大的预测模型。集成算法通过对基本模型的预测进行加权平均或多数投票等方式,来产生最终的预测结果。
集成算法的核心思想是通过结合多个弱学习器的预测结果,可以提高预测的准确性和鲁棒性。弱学习器通常是指单一的学习算法,它们可能在某些情况下预测准确率较低,但通过集成可以弥补其不足。
集成算法主要分为两类:bagging和boosting。bagging的思想是通过训练多个基学习器,每个基学习器使用从原始训练数据中有放回地进行采样得到的不同子集,然后将它们的预测结果进行平均。boosting的思想是通过逐步调整样本权重,让每个基学习器针对前一个学习器的错误进行训练,从而逐步提高预测的准确性。
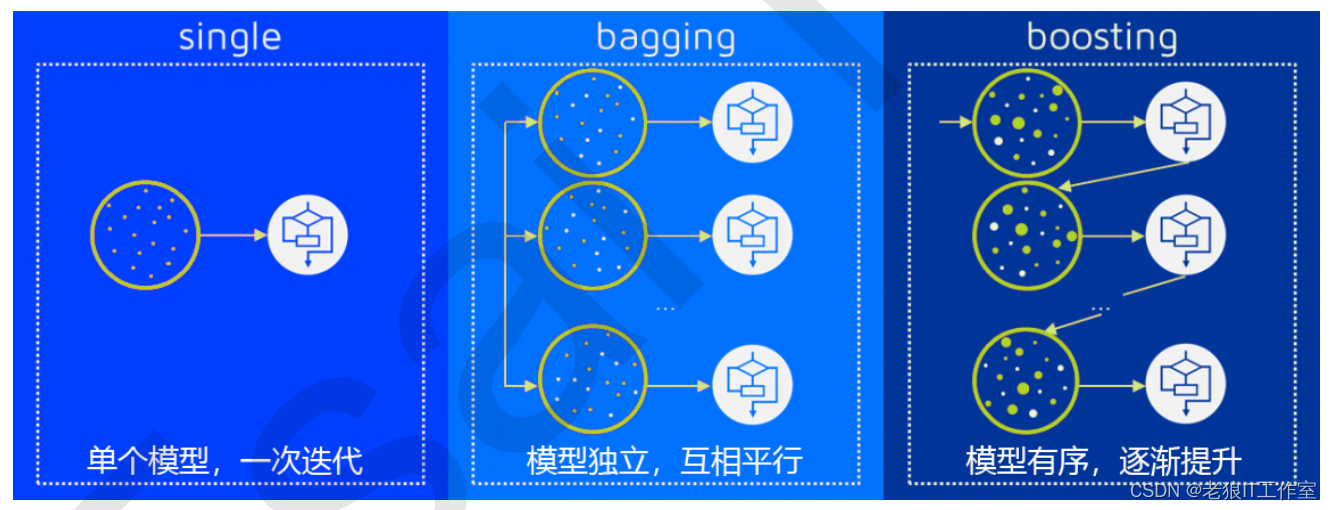
常见的集成算法有随机森林(Random Forest)、Adaboost、Gradient Boosting等。这些算法在各种机器学习任务中都有广泛的应用,并取得了令人满意的效果。
什么是随机森林?
随机森林(Random Forest)是一种基于集成学习的机器学习算法,其目的是通过组合多个决策树模型来进行预测。随机森林通过对训练数据进行随机采样,以及在构建每个决策树节点时对特征进行随机选择,来增加模型的多样性和鲁棒性。
随机森林的训练过程可以分为以下几个步骤:
- 随机采样:从原始训练数据中有放回地进行随机采样,形成多个不同的训练子集。
- 构建决策树:对于每个采样子集,使用决策树算法构建一个决策树模型。
- 随机选择特征:在构建每个决策树节点时,随机选择一部分特征进行评估,选择最佳的特征来进行分割。
- 集成模型:将所有构建的决策树组合成随机森林模型。在进行预测时,每个决策树对样本进行预测,最终的预测结果通过多数投票或平均值来确定。
随机森林具有以下特点:
- 可以处理高维数据和大规模数据集,适用于各种机器学习任务。
- 随机森林能够减少过拟合的风险,通过随机采样和特征选择来增加模型的多样性。
- 随机森林能够估计变量的重要性,根据特征在决策树中的使用情况来评估其对预测的贡献程度。
随机森林在各种实际应用中都取得了很好的效果,如分类、回归、特征选择等任务。它具有较高的准确性、鲁棒性和可解释性,是常用的机器学习算法之一。
scikit-learn中的集成算法
API Reference — scikit-learn 1.4.0 documentation

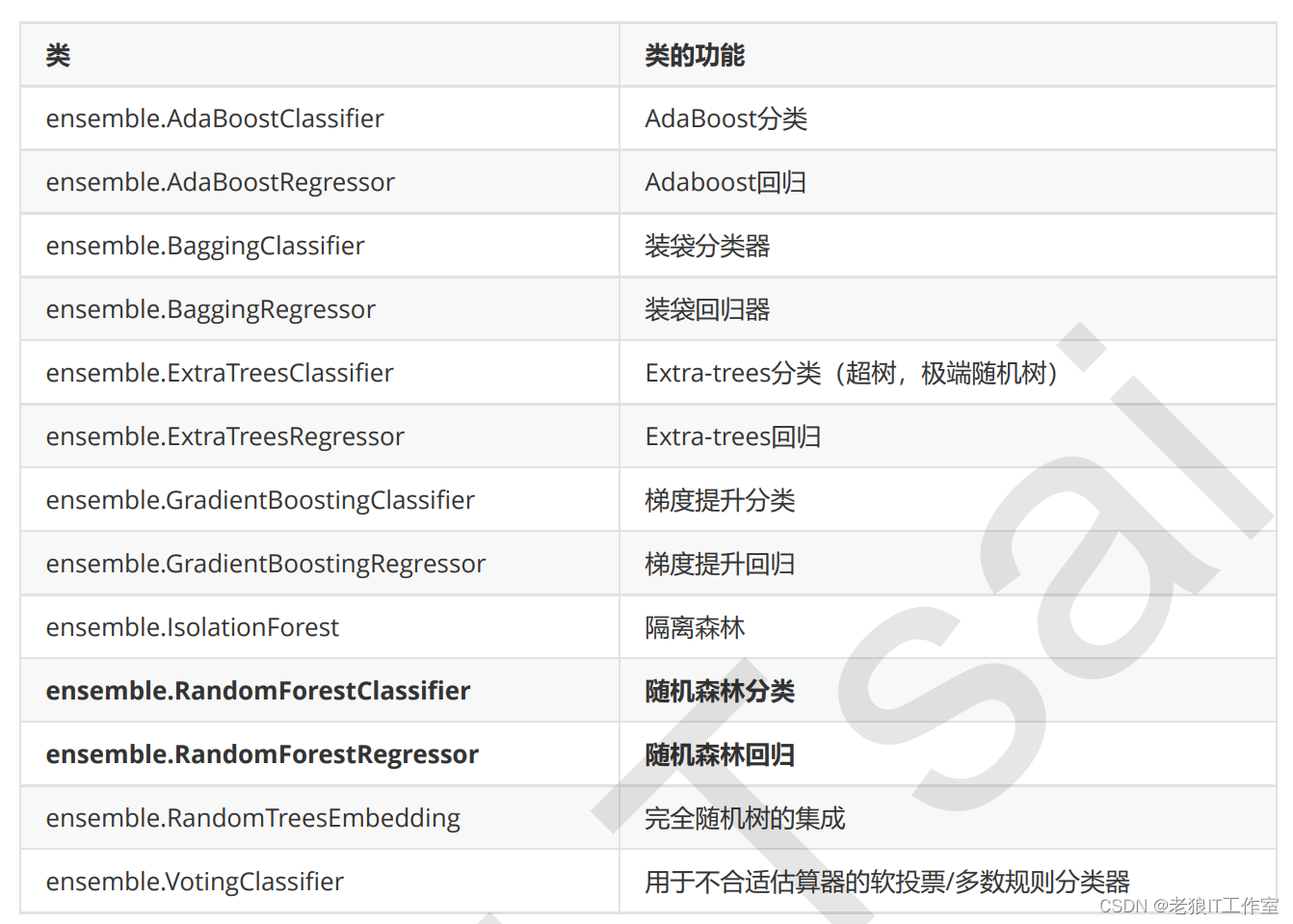
scikit-learn中的RandomForestClassifier类
sklearn.ensemble.RandomForestClassifier — scikit-learn 1.4.0 documentation sklearn.ensemble.RandomForestClassifier — scikit-learn 1.4.0 documentation
sklearn.ensemble.RandomForestClassifier — scikit-learn 1.4.0 documentation
该类的参数和决策树分类器的参数基本一样,参数的含义可以阅读:
[Python] scikit-learn - 葡萄酒(wine)数据集和决策树分类器的使用-CSDN博客
RandomForestClassifier类重要属性和接口
sklearn.ensemble.RandomForestClassifier — scikit-learn 1.4.0 documentation

随机森林中有三个非常重要的属性:.estimators_,.oob_score_以及.feature_importances_。
.estimators_
是用来查看随机森林中所有树的列表的。
.oob_score_
指的是袋外得分。随机森林为了确保林中的每棵树都不尽相同,所以采用了对训练集进行有放回抽样的方式来不断组成信的训练集,在这个过程中,会有一些数据从来没有被随机挑选到,他们就被叫做“袋外数据”。这些袋外数据,没有被模型用来进行训练,sklearn可以帮助我们用他们来测试模型,测试的结果就由这个属性 oob_score_来导出,本质还是模型的精确度。
.feature_importances_
和决策树中的.feature_importances_用法和含义都一致,是返回特征的重要性。
随机森林的接口
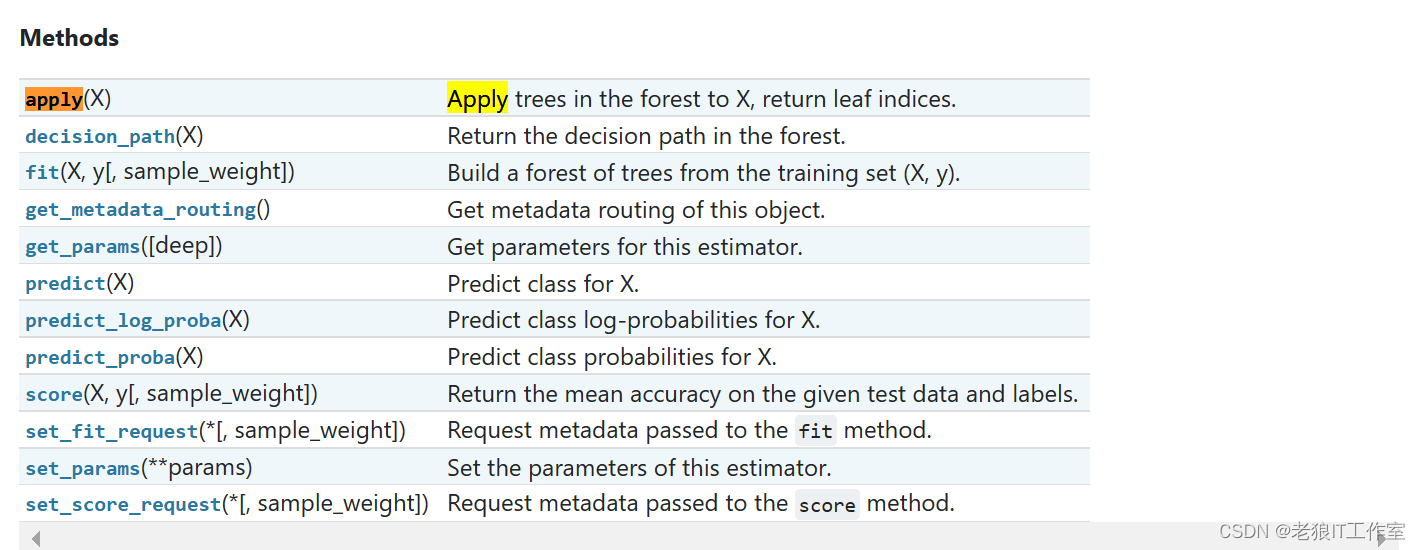
与决策树完全一致,因此依然有四个常用接口:apply, fit, predict和score。
除此之外,还需要注意随机森林的predict_proba接口,
这个接口返回每个测试样本对应的被分到每一类标签的概率,标签有几个分类就返回几个概率。如果是二分类问题,则predict_proba返回的数值大于0.5的,被分为1,小于0.5的,被分为0。
传统的随机森林是利用袋装法中的规则,平均或少数服从多数来决定集成的结果,而sklearn中的随机森林是平均每个样本对应的predict_proba返回的概率,得到一个平均概率,从而决定测试样本的分类。
RandomForestClassifier使用案例
# 导入依赖模块
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score# 导入葡萄酒数据集
wine = load_wine()
print(wine.data.shape)
print(wine.target.shape)
# 建模
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:",score_c)
print("Random Tree", score_r)
# 交叉验证:数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
# 画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11), rfc_l,label = "Random Forest")
plt.plot(range(1,11), clf_l,label = "Decision Tree")
plt.legend()
plt.show()
# n_estimators的学习曲线
superpa = []
for i in range(50):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,51),superpa)
plt.show()
# 常用的属性和接口
rfc = RandomForestClassifier(n_estimators=25)
rfc = rfc.fit(Xtrain, Ytrain)
print('feature_importances_:', rfc.feature_importances_, '\n')
print('estimators_:', rfc.estimators_, '\n')
print('oob_score:', rfc.oob_score, '\n' )
if rfc.oob_score :
print('oob_score_:', rfc.oob_score_ , '\n')
print('score:', rfc.score(Xtest,Ytest), '\n')
print('apply:', rfc.apply(Xtest), '\n')
print('predict:', rfc.predict(Xtest), '\n')
print('predict_proba:', rfc.predict_proba(Xtest))
参考资料
菜菜的机器学习sklearn