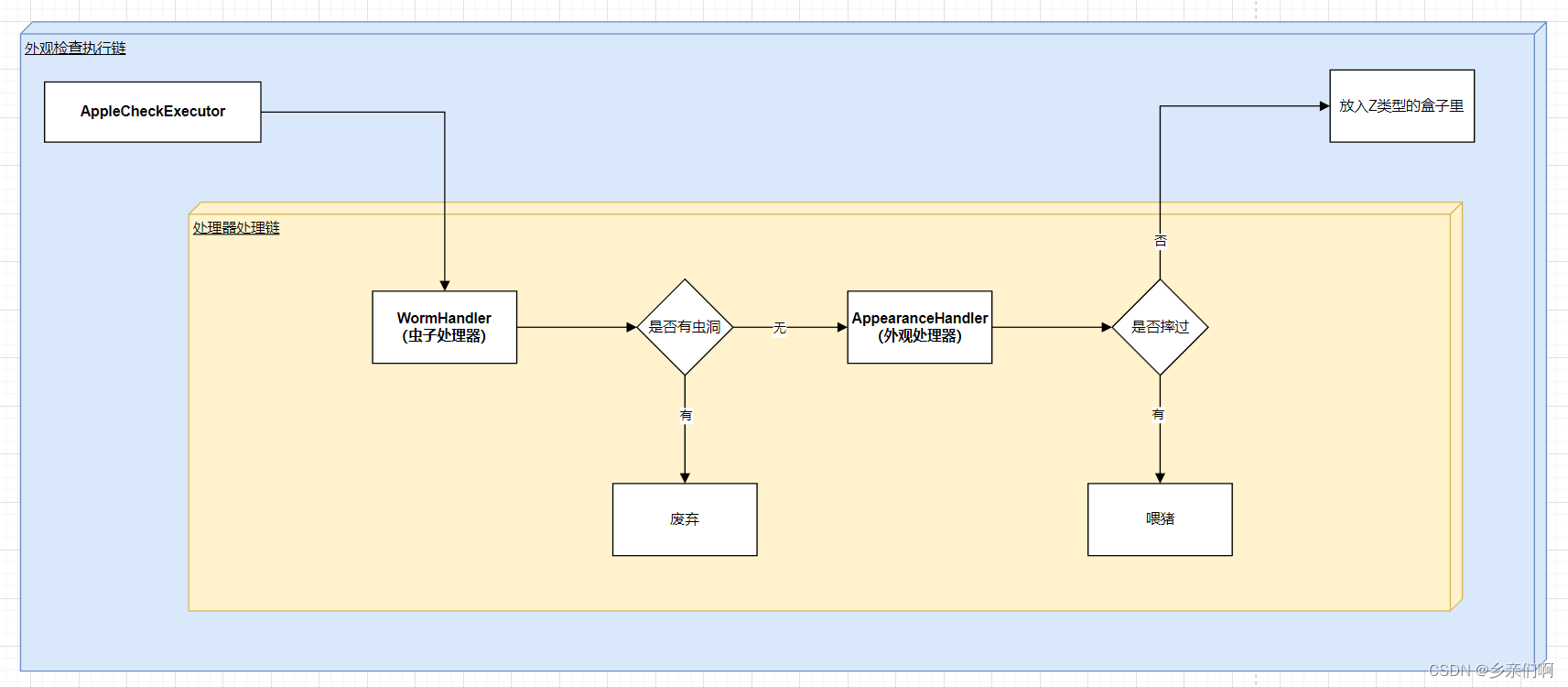
数学公式OCR识别php 对接mathpix api
- 一、注册账号
- 官网网址:https://mathpix.com
- 二、该产品支持多端使用
- 注意说明(每月10次)
- 三、api 对接
- 第一步创建create key
- php对接api
- 这里先封装两个请求函数,get 和post ,通过官方文档我们可以知道,有的api 需要用get 有的需要post .
- 下面我们开始发送请求的封装的一些函数
- 对接图片识别的api
- 对接PDF 识别的api
- 第一步 发送请求
- 第二步骤,获取处理的格式以及处理状态
- 第三步骤,获取处理的结果
- 第四步骤,拿到自己想要的结果进行文件写入。
- 四。其他相关
项目开发中使用公式编译器,也参与开发过公式编译器,国内的巨头,金山,腾讯,这个网页版的编辑器公式这一块就比较糟糕,满足不了试题,公式的情况,后来自己开发的网页版公式编译器,现在对接了ocr 公式识别,国内的ocr 也是很糟糕。只能说针对数学公式这一块比较差,车辆车牌识别,身份证这种就比较简单做的比较好。
一、注册账号
官网网址:https://mathpix.com
如下图所示:
二、该产品支持多端使用
移动端,电脑PC端
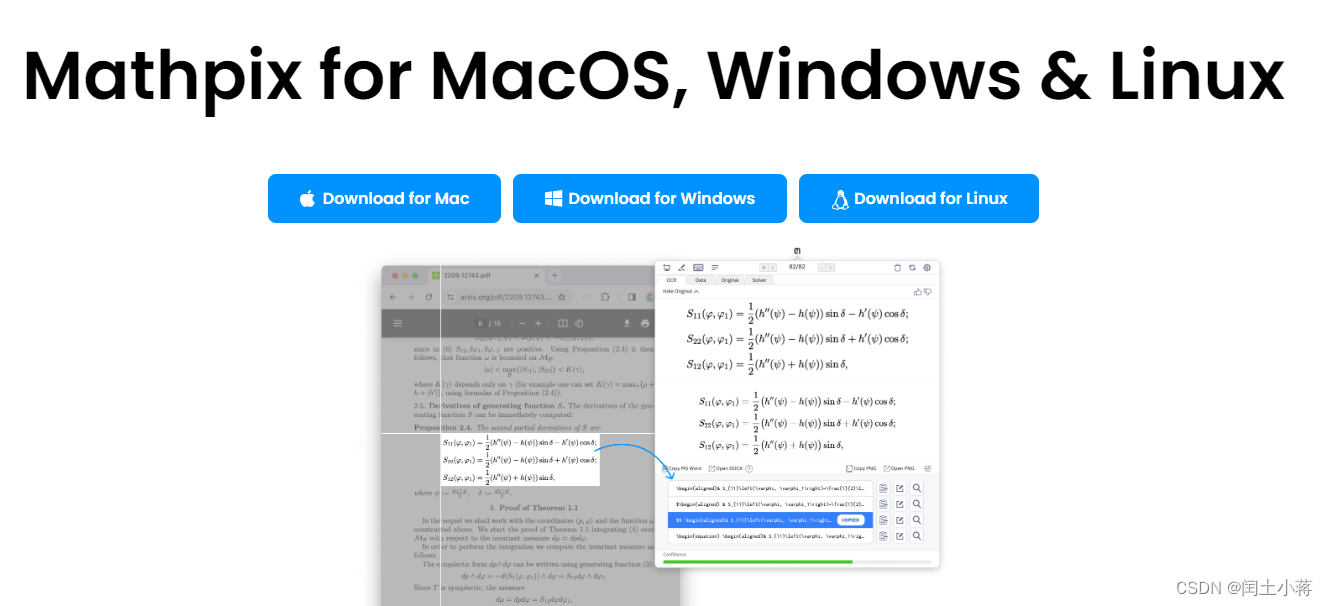
注意说明(每月10次)
下载注册登录既可以使用客户端,新用户账号每月可免费使用10次图片转识别或者pdf识别次数,每月清零。
有其他途径下载的需要支付1美元的可以每个月使用50~1000次,这个我没有用过,看别人说的,1美元应该是激活使用,看了都是19年早起其他博主发的帖子。这个能找到最好。
三、api 对接
我们由于是工具类所以我们自己开发的对接的需要使用api 接口服务对接。下面就简单说明一下api 对接把,登录账号进入个人中心如右侧栏目
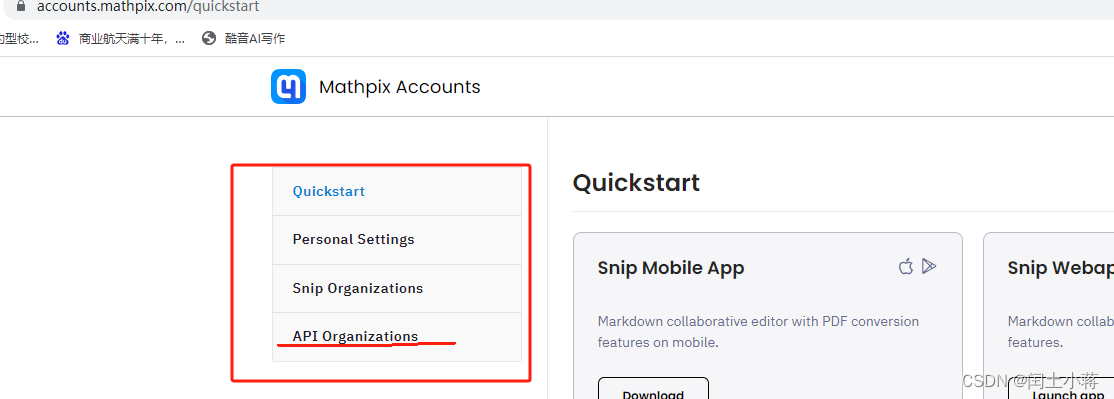
第一步创建create key
。点击选择API 上图红线标注的地方进入即到如下图界面,说明,创建Key 需要绑定一张信用卡。信用卡的用途是用户激活账号和每月用量的一个账单统计计费,直接通过该卡直接扣款。这个也是比较方便的,不向有的平台直接会员或者按年套餐,用量付费这个大家都比较好接受。绑定卡以后会有一个扣款激活,我这里直接扣款是19.9$ 这个目前活动可以不限制类型的api 接口。后期可能会调整。这个19.9 $ 就是一个激活账号作用,激活后会默认创建一个key 如下图,当然你也可以创建多个key 根据不同的产品单独计费使用,多个接口可以用一个key使用。
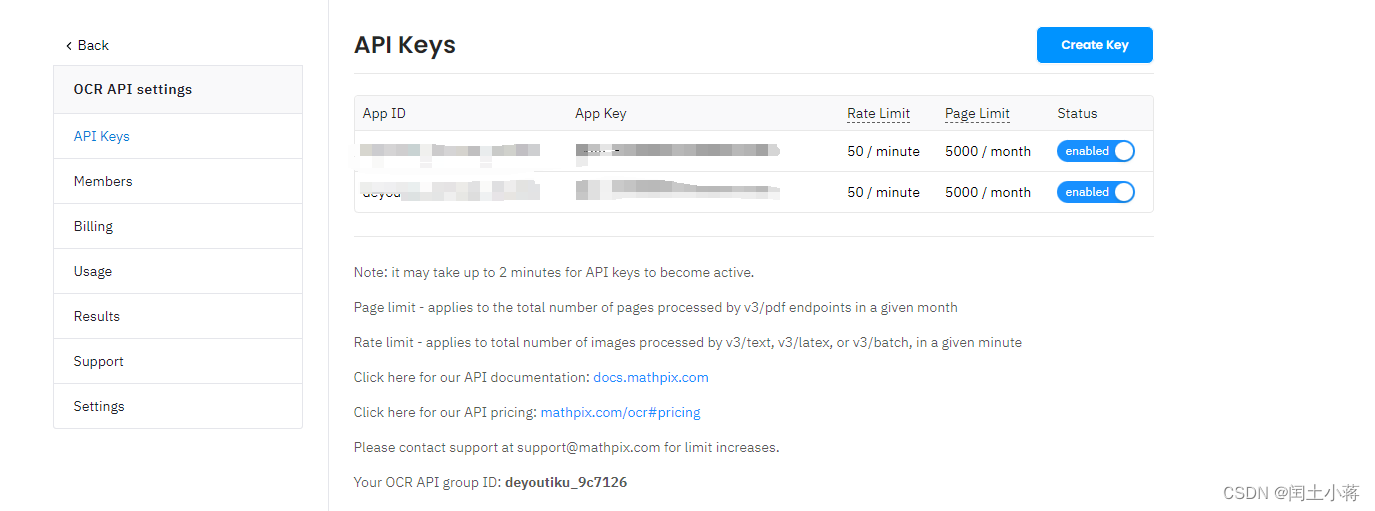
官网api 对接文档链接,点击即可进入
官方啊的api 文档写的也是比较专业的,类死与国内的api 比较分类多,个人感觉基本差不多。
下一步就是我们来使用这个api 对接:
php对接api
个人使用的是php 语言,所以这里代码示例就用thinkphp5+ 演示了。官方gethub 和其他的博主用的都是python 示例。基本差不多。都一样把。语法不同,规则不同而已。
这里先封装两个请求函数,get 和post ,通过官方文档我们可以知道,有的api 需要用get 有的需要post .
封装的两个函数get 和post 代码如下。注意类面用到上面我们注册的app_id 和app_key。这个大家都知道,这个就是用来确定身份呢的。对结果阿里,腾讯,百度,都知道。
app_id 和app_key
function api_request_curl($url, $postData = array()) {
if (empty($url)) return '';
$postData = json_encode($postData);
$curl = curl_init(); //初始化
curl_setopt($curl,CURLOPT_URL,$url); //设置url
curl_setopt($curl,CURLOPT_HTTPAUTH,CURLAUTH_BASIC); //设置http验证方法
curl_setopt($curl, CURLOPT_TIMEOUT,30);
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1); //设置curl_exec获取的信息的返回方式
curl_setopt($curl,CURLOPT_POST,1); //设置发送方式为post请求
curl_setopt($curl,CURLOPT_POSTFIELDS,$postData); //设置post的数据
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
'app_id:**********',
'app_key:**********',
'Content-Type: application/json',
'Content-Length: ' . strlen($postData))
);
$result = curl_exec($curl);
if($result === false){
throw new Exception('Http request message :'.curl_error($curl));
}
$result = json_decode($result,true);
return $result;
}
/**
* get请求
* @param $url
* @param string $msg
* @return mixed
*/
public function api_request_get($url){
if (empty($url)) return '';
$curl = curl_init(); //初始化
curl_setopt($curl,CURLOPT_URL,$url); //设置url
curl_setopt($curl,CURLOPT_HTTPAUTH,CURLAUTH_BASIC); //设置http验证方法
curl_setopt($curl, CURLOPT_TIMEOUT,30);
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1); //设置curl_exec获取的信息的返回方式
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
'app_id:********',
'app_key:**********'
)
);
$result = curl_exec($curl);
if($result === false){
throw new Exception('Http request message :'.curl_error($curl));
}
curl_close($curl);
return $result;
}
下面我们开始发送请求的封装的一些函数
下面是我们用到的api 接口,根据自己的使用场景来选择api 接口即可。
https://api.mathpix.com/v3/app-tokens //token 使用
https://api.mathpix.com/v3/text
https://api.mathpix.com/v3/latex
https://api.mathpix.com/v3/pdf
对接图片识别的api
这里简单说明一下蹄片识别的情况,图片可以直接用图片地址(必须全路径)作为参数来使用。也可以用过file 文件上传来使用,我这里是直接把本都图片上传到服务器,拿到全路径进行一个post请求,请求结果和参数都在下面函数包含,大家可以看看返回的格式,图片识别一般都是快速响应的,一般都会请求后直接返回一个结果如下代码块的内容。
* ocr pdf 识别转docx 处理
* @param $pdfurl
* @return \think\response\Json
*/
public function mathpixphoto($photo_path="https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg")
{
//https://api.mathpix.com/v3/app-tokens
//https://api.mathpix.com/v3/text
//https://api.mathpix.com/v3/latex
//https://api.mathpix.com/v3/pdf
//图形转文本实例1
$url = 'https://api.mathpix.com/v3/text';
$data['src'] = "https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg";
$data['math_inline_delimiters'] = ["$", "$"];
$data['rm_spaces'] = true;
回调参数如下
{"request_id":"2024_01_12_52927e584385e276cc6cg","version":"RSK-M122p1","image_width":850,"image_height":332,"is_printed":false,"is_handwritten":true,"auto_rotate_confidence":1.1920927533992653e-7,"auto_rotate_degrees":0,"confidence":0.9990236759185791,"confidence_rate":0.9990236759185791,"latex_styled":"f(x)=\\left\\{\\begin{array}{ll}\nx^{2} & \\text { if } x<0 \\\\\n2 x & \\text { if } x \\geq 0\n\\end{array}\\right.","text":"$f(x)=\\left\\{\\begin{array}{ll}x^{2} & \\text { if } x<0 \\\\ 2 x & \\text { if } x \\geq 0\\end{array}\\right.$"}
图形转文本实例
$url = 'https://api.mathpix.com/v3/text';
$data['src'] = $path;
$data['formats'] = ["text", "data", "html"];
$data['data_options']=['include_asciimath'=>true,'include_latex'=>true];
回调参数如下(需要转义json) json 解析直接报错,需要转义
{
"confidence": 0.9982182085336344,
"confidence_rate": 0.9982182085336344,
"is_printed": false,
"is_handwritten": true,
"data": [
{
"type": "asciimath",
"value": "lim_(x rarr3)((x^(2)+9)/(x-3))"
},
{
"type": "latex",
"value": "\\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right)"
}
],
"html": "<div><span class=\"math-inline \" >\n<asciimath style=\"display: none;\">lim_(x rarr3)((x^(2)+9)/(x-3))</asciimath><latex style=\"display: none\">\\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right)</latex></span></div>\n",
"text": "\\( \\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right) \\)"
}
$res = $this->api_request_curl($url,$data);
return $res;
}
对接PDF 识别的api
这里主要和大家说一下pdf 的识别,pdf 我的操作流程是,上传pdf 到服务器或者是oss(阿里) ,obs(腾讯)、七牛云等一些第三方存储。这样我们拿到一个文件地址(全路径)然后直接发送请求。
pdf 对接官方文档提供了4个步骤,分几个步骤也可以理解毕竟系统识别处理文件也有一个过程,这个就是智者见智。
第一步 发送请求
把自己想要ocr 识别的pdf 文件发送给mathpix 告诉对方我要ocr 识别这个文件的内容,请求后会给返回一个pdf_id 或者错误提示,这里我们需要将pdf_id 进行存储,方便处理后面的逻辑。
pdf_id
第二步骤,获取处理的格式以及处理状态
获取转化的状态
“status”:“completed”, 代表完成
第三步骤,获取处理的结果
获取自己第一步需要转化的内容,比如我把pdf 文件需要ocr 识别后转化为docx 或者html 或者zip
“status”:“completed”,代表完成
第四步骤,拿到自己想要的结果进行文件写入。
pdf 转化后的内容写入自己的文件,比如我们需要把数学试卷的pdf 通过ocr api 识别成html 网页格式和docx 格式,一个用于网页展示,一个用于本地文件下载。识别的公式都是可编辑的公式。
*注意 这里的返回结果都是已经转化后的内容直接写入就行了。比如html 格式就是html 内容,直接写入即可。docx 格式就是docx 内容直接写入文件就行。(小插曲之前自己搞个phpword 创建写入一直失败,后来写入text 文本发现就是word的源文件格式,真笑了。)
这里我在函数写了一个sleep_pdf_status 意思就是延迟循环查看处理状态可以省掉低二步骤,第三步骤 ,大家也知道php 的请求延迟最长不超过60s 所以我们通过延迟循环来判断结果这样可以直接写入文件。
sleep_pdf_status
pdf 处理也会返回一个pdf_id 我们可以将该参数进行存储,比如第一次延迟循环返回失败后,在次通过pdf_id获取结果,我测试的基本上一个循环都能成功,也有不成功的,不成功的我们直接重新发起获取结果的函数自己写的就可以了 reissue_pdf_math 这个函数,
reissue_pdf_math
file_put_contents php写入就用该函数就行,下面代码块有
/**
* ocr pdf 识别转docx 处理
* @param $pdfurl
* @return \think\response\Json
*/
public function mathpixpdf($pdfurl="")
{
//PDF ocr 识别 第一步 上传
$url = 'https://api.mathpix.com/v3/pdf';
$data['url'] = "".$pdfurl."";//"https://deyouw.oss-cn-beijing.aliyuncs.com/document/20240115/user_125/57522.pdf";
$data['conversion_formats']=['html'=>true,'docx'=>true,'tex.zip'=>true];
$res = $this->api_request_curl($url,$data);
$pdf_id = $res['pdf_id'];
$res = $this->sleep_pdf_status($pdf_id);
return $res;
// var_dump($res);
// exit;
//返回一个pdifid 需要自己记录一下案例如下
// {"pdf_id":"2024_01_12_9536370a2434175d0c6dg"}
//PDF ocr 识别 第二部,获取转化状态
// $url = 'https://api.mathpix.com/v3/pdf/2024_01_15_2cf99221f2144139723fg';
// $res = $this->api_request_get($url);
// var_dump($res);
//返回参数:处理中
// {
// "status": "split",
// "num_pages": 9,
// "percent_done": 11.11111111111111,
// "num_pages_completed": 1
// }
//返回参数:完成
// {
// "status":"completed",
// "version":"RSK-P107",
// "input_file":"https://deyouw.oss-cn-beijing.aliyuncs.com/document/20240112/user_125/83323.pdf",
// "num_pages":2,
// "num_pages_pdf":2,
// "num_pages_completed":2,
// "percent_done":100
// }
//PDF ocr 识别 第三部,获取转化需要的内容
// $url = 'https://api.mathpix.com/v3/converter/2024_01_12_9536370a2434175d0c6dg';
// $res = $this->api_request_get($url);
// 返回相应参数:完成
// {
// "status":"completed",
// "version":"RSK-P107",
// "conversion_status":{
// "tex.zip":{
// "status":"completed"
// },
// "docx":{
// "status":"completed"
// }
// }
// }
// 第四部 -下载所需要的的格式内容html
// $url = 'https://api.mathpix.com/v3/converter/2024_01_15_e8b33807c27cb8bf847ag.html';
// $text = $this->api_request_get($url);
// $filename = "ocr/docx/".time().".html"; // txt文件名
// // 将内容写入到txt文件中
// if (file_put_contents($filename, $text) !== false) {
// return $filename;
// echo "成功将内容写入到html文件中!";
// } else {
// return 202;
// echo "无法将内容写入到html文件中。";
// }
// echo "https://deyouw.com/example.html";
// exit;
// 第四部 -下载所需要的的格式内容 docx
// $time = time().getmyuid();
// $url = 'https://api.mathpix.com/v3/converter/'.$pdf_id.'.html';
// $text = $this->api_request_get($url);
// $filename = "ocr/html/".$time.".html"; // txt文件名
// // 将内容写入到txt文件中
// if (file_put_contents($filename, $text) !== false) {
// $data['html'] = $filename;
// echo "成功将内容写入到html文件中!";
// } else {
// return 202;
// echo "无法将内容写入到html文件中。";
// }
// sleep(3);
// $url = 'https://api.mathpix.com/v3/converter/'.$pdf_id.'.docx';
// $text = $this->api_request_get($url);
// $filename = "ocr/html/".$time.".docx"; // txt文件名
// // 将内容写入到txt文件中
// if (file_put_contents($filename, $text) !== false) {
// $data['doc'] = $filename;
// echo "成功将内容写入到docx文件中!";
// } else {
// return 202;
// echo "无法将内容写入到docx文件中。";
// }
// return $data;
// $this->create_word(file_get_contents($filename));
// $this->create_word($text);
// 返回相应参数:完成
// {
// "status":"completed",
// "version":"RSK-P107",
// "conversion_status":{
// "tex.zip":{
// "status":"completed"
// },
// "docx":{
// "status":"completed"
// }
// }
// }
// $data['formats'] = ["text", "html"]; //text", "html" "latex"
// $data['data_options']=['include_asciimath'=>true,'include_latex'=>true];
//BASE64 格式
// $data['app_id'] = config('mathpix')['app_id'];
// $data['app_key'] = config('mathpix')['app_key'];
// $res = $this->api_request_curl($url,$data);
//r.json()['text']
// return $res;
}
//客户端重新获取
public function reissue_pdf_math($pdf_id){
return $res = $this->sleep_pdf_status($pdf_id);
}
//获取内容
public function pdf_ocr($pdf_id){
$url = 'https://api.mathpix.com/v3/converter/'.$pdf_id;
$res = $this->api_request_get($url);
$res = json_decode($res,true);
return $res;
}
/**
*获取转化的状态返回参数
*PDF ocr 识别 第三部,获取转化需要的内容
*/
public function sleep_pdf_status($pdf_id){
$status = 0;
//循环查找最多响应30秒结束
for ($i=0; $i < 10; $i++) {
$res = $this->pdf_ocr($pdf_id);
if($res == NULL || $res == null || empty($res)){
$status = 2;
}
if(array_key_exists('error', $res)){
$status = 2;
}
if(array_key_exists('status', $res) && $res['status'] == "completed"){ //完成状态
$status = 1;
continue;
}
sleep(3); //秒执行
}
if($status==1){
$url = 'https://api.mathpix.com/v3/converter/'.$pdf_id.'.html';
$text = $this->api_request_get($url);
if(empty($text)){
$res = ['status'=>203,'pdf_id'=>$pdf_id,'msg'=>'相应超时失败,请下次重新请求'];
return $res;
}
$filename = "ocr/html/".time().rand(1111,9999).".html"; // html文件名
// 将内容写入到txt文件中
if (file_put_contents($filename, $text) !== false) {
$data['html'] = $filename;
// echo "成功将内容写入到html文件中!";
} else {
$data['html'] = "html转化成功、写入失败";
// return 202;
// echo "无法将内容写入到html文件中。";
}
$url = 'https://api.mathpix.com/v3/converter/'.$pdf_id.'.docx';
$text2 = $this->api_request_get($url);
if(empty($text2)){
$res = ['status'=>203,'pdf_id'=>$pdf_id,'msg'=>'相应超时失败,请下次重新请求'];
return $res;
}
$filename = "ocr/html/".time().rand(1111,9999).".docx"; // docx文件名
// 将内容写入到txt文件中
if (file_put_contents($filename, $text2) !== false) {
$data['docx'] = $filename;
// echo "成功将内容写入到docx文件中!";
} else {
$data['docx'] = "docx转化成功、写入失败";
// return 202;
// echo "无法将内容写入到docx文件中。";
}
$data['pdf_id']=$pdf_id;
$data['status'] = 200;
return $data;
}else{
$res = ['status'=>203,'pdf_id'=>$pdf_id,'msg'=>'相应超时失败,请下次重新请求'];
return $res;
}
}
四。其他相关
###下面是其他博主的发表的关于mathpix 客户端工具使用,csdn 这个论坛国内比较好,里面的大哥确实挺多的感谢他们的分享
mathpix安装和使用详细教程
使用Mathpix识别和转换富含公式的PDF为Markdown
后面会整合一下markdown 编辑器来实现ocr 识别后,编辑和预览。有兴趣的伙伴可以试着搞个demo
Editor.md
这次就这些内容,不论学习或者工作中遇到问题,想办法解决,都可以发帖,互相学习互相进步。