1.Redis集群了解吗
前面说到了主从同步存在高可用和分布式问题,哨兵机制解决了高可用问题,而集群就是终极方案,一举解决高可用 和分布式问题。

1.数据分区:数据分区或称数据分片是集群最核心的功能,集群将数据分散到多个节点,一方面突破了redis单机内存限制,存储容量大大提升;另一个方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
2.高可用:集群支持主从复制和主节点的故障转移,当任意节点发生故障时候,集群任可对外提供服务。
.
2.集群中数据如何分区
分布式存储中,要把数据映射到多个节点,常见的数据分区规则有三种
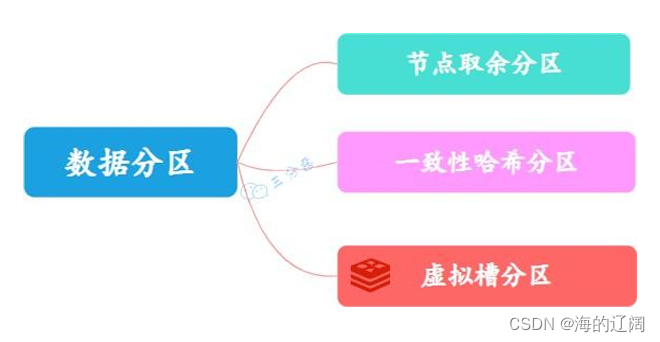
- 方案一:节点取余分区
节点取余分区:使用特定的数据,比如Redis的健或者用户id之类,对应hash值取余,来确定映射到哪一个节点上。不过最大的问题是:当节点数量发生变化时候,如扩容或者收缩节点,数据节点关系需要重新计算,会导致数据的重新迁移。
2.·方案二:一致性哈希分区
将整个Hash值空间组织成一个虚拟的圆环,然后将缓存的节点的IP或者主机名做Hash取值后,房子在圆环上面,当我们需要确定某一个Key需要存取到哪一个节点时候,先对这个Key做同样的Hash取值,确定在圆环上的位置,然后按照顺时针方向在环上行走,遇到的第一个节点就是要访问的节点。这种方式相比节点取余最大的好处就是加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响
问题:
- 缓存节点在圆环上分布不平均,会造成部分缓存节点的压力大
- 当某个节点故障时,这个节点所要承担的所有访问都会顺移到另一个节点,会对后面这个节点造成压力。
3.方案三:虚拟槽分区
这个方案在一致性哈希分区基础上引入 虚拟节点的概念,Redis集群使用的便是该方案,其中虚拟节点称为槽,槽是介于数据和实际节点之间的虚拟概念,每个实际节点包含一定数量的槽,每个槽的包含哈希值在一定范围内的数据。
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽解耦了数据和实际节点 之间的关系,增加
或删除节点对系统的影响很小。
3.说说Redis集群的原理
Redis集群通过数据分区来实现数据的分布式存储,通过自动故障转移实现高可用。
集群创建
数据分区是在集群创建的时候完成的
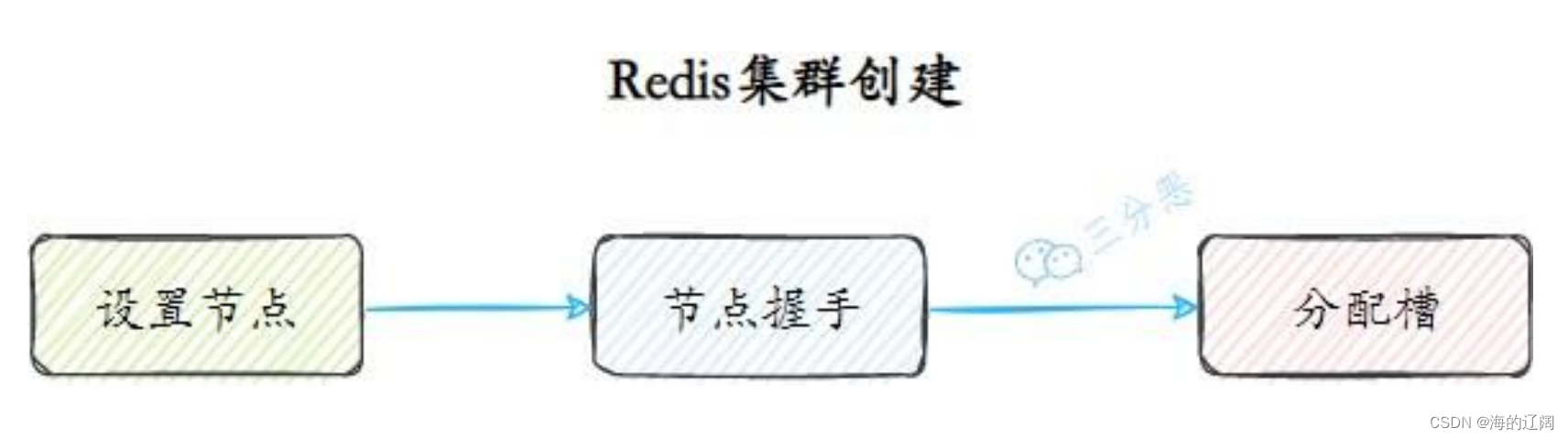
设置节点
Redis集群一般是由多个节点组成,节点数据量至少为6个才能保证组成完成高可用的集群,每个节点需要开启配置cluster-enabled yes
节点握手
节点握手是指一批运行在集群模式下的节点通过Gossip协议彼此通信,达到感知对方的过程。节点握手是集群彼此通信的第一步 ,由客户端发起命令cluster meet{ip}{port}。完成节点握手之后,一个个的Redis节点就组成了一个
多节点的集群。
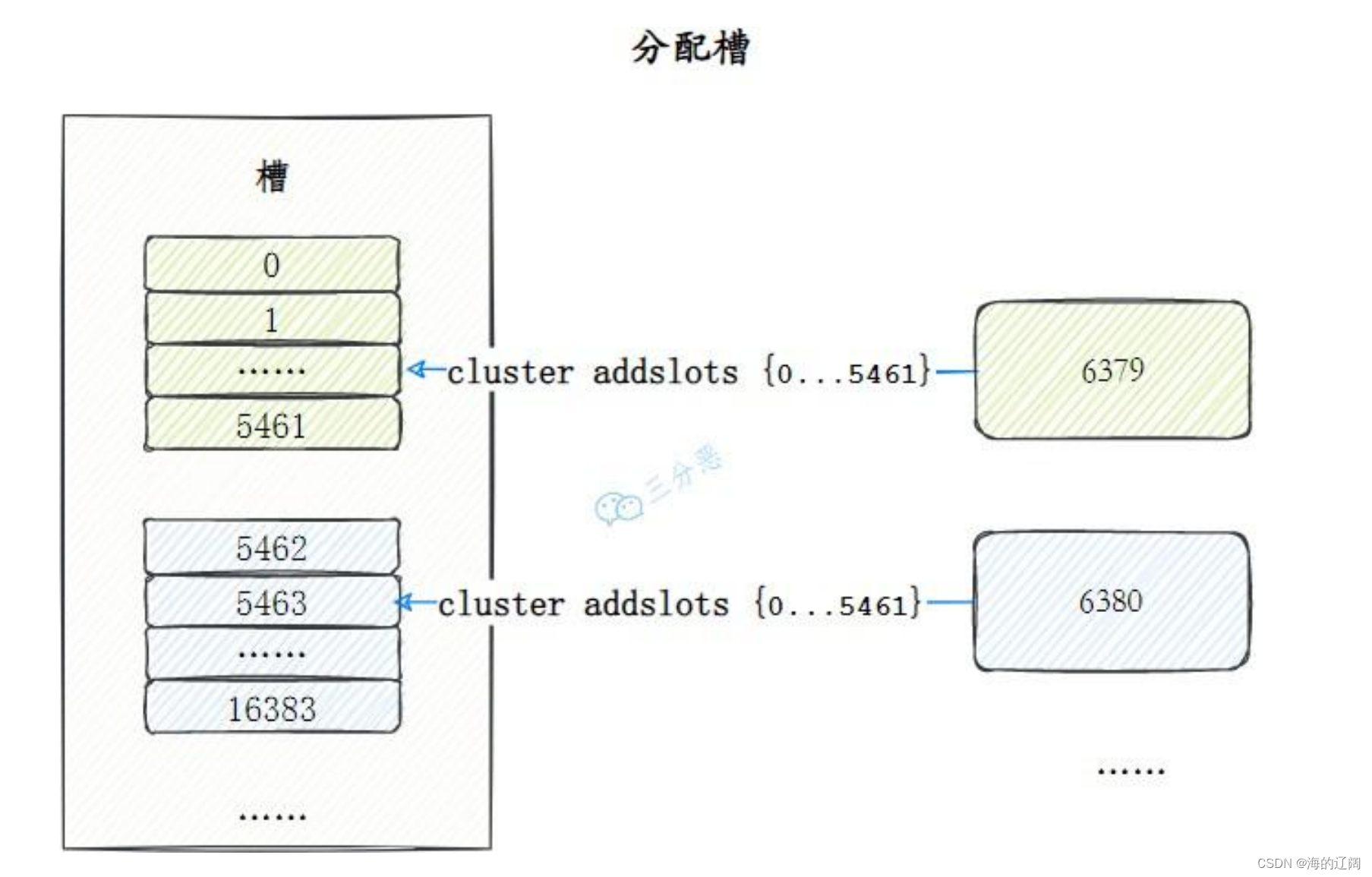
分配槽
Redis集群把所有的数据映射到16384个槽中,每个节点对应若干个槽,只有当节点分配了槽,才能响应和这些槽关键的命令,通过 cluster addslots命令为节点分配槽。
故障转移
Redis集群的故障转移和哨兵的故障转移类似,但是Redis集群中所有的节点都要承担状态维护的任务
故障发现
Redis集群内节点通过ping/pong消息实现节点通信,集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong 消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节 点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。当 半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程。

故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。

- 资格检查:每个从节点都要检查最后与主节点的断线时间,判断是否有资格替换故障的主节点
- 准备选举时间:当从节点符合故障转移资格后,更新触发故障选举时间,只有到达该时间后才能继续执行后续流程
- 发起选举:当从节点定时任务检查到达故障选举时间,发起选举流程
- 选举投票:持有槽的主节点处理故障选举消息。投票过程其实是一个领导者选举的过程,如集群内有N个持有槽的主节点代表有N张选票。由于在每个配置纪元内持有槽的主节点只能投票给一个 从节点,因此只能有一个从节点获得N/2+1的选票,保证能够找出唯一的从节点。
- 替换主节点:当从节点收集到足够的票后,触发替换主节点操作。
部署集群至少需要几个物理节点
在投票选举的环节,故障主节点也算在投票数内,假设集群内节点规模是3主3从,其中有2 个主节点部署在一台机器
上,当这台机器宕机时,由于从节点无法收集到 3/2+1个主节点选票将导致故障转移失败。这个问题也适用于故障发
现环节**。因此部署集群时所有主节点最少需要部署在3台物理机上才能避免单点问题。**
4.集群的伸缩
Redis集群提供了灵活的节点扩容和收缩方案,可以在集群不影响对外服务的情况下,为集群添加节点进行扩容或者也可以下线部分节点进行收缩
群扩容和收缩的关键点就在于槽和节点的对应关系,扩容和收缩就是将一部分槽和数据迁移给新节点
5. 什么是缓存击穿,穿透,雪崩
-
缓存击穿:一个访问量较大的key在某个时间过期,导致大量的请求直接打到db上
解决方案:1.加锁更新,比如请求a发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写入缓存,再返回
给用户,这样后面的请求就可以从缓存中拿到数据了
2.将过期时间写在value中,通过异步不断刷新
3.将过期时间设置永不过期
2.缓存穿透:指每次查询的数据都不在缓存和数据库中,每次请求都直接打到数据库中。原因可能是自身业务代码原因,2.恶意攻击
解决方案
1.缓存空值,null值:存在问题为
- 可能会缓存太多的空值,造成大量的空间浪费,可以设置一个较短的过期时间
- 缓存层和数据层可能会有一段时间的数据不一致,导致业务受到影响,这个时候可以用消息队列或者其他的异步方式进行更新缓存
2.布隆过滤器:除了缓存空对象,我们还可以在存储和缓存之前,加一个布隆过滤器,做一层过滤。布隆过滤器里面不存在肯定就是不存在,可能误报存在。

3.缓存雪崩:某一时刻发生大规模的缓存失效的情况,例如缓存服务宕机、大量key在同一时间过期,这样的后果就是大量的请求进来直接打到DB上,可能导致整个系统的崩溃,称为雪崩。
解决方案:
-
提高缓存可用性
1.集群部署:通过集群来提升缓存的可用性
2.多级缓存,设置多级缓存,第一级缓存失效的情况下,访问第二级,每一级的失效时间不同 -
过期时间
1.均匀过期:为了防止大范围过期,可以将过期时间设置为随机的过期时间
2.热点数据永不过期 -
熔断降级
1.服务熔断:当缓存服务器宕机或者超时响应的时候,为了防止整个系统出现雪崩,暂停业务系统访问缓存系统。
2.服务降级:当出现大量的缓存失效,而且处于高并发的情况下,在业务系统暂时舍弃一下非核心的业务和数据处理,而直接返回一个提前处理好的fallback错误处理信息。
6.如何保证缓存和数据库数据的一致性
根据CAP理论,在保证高可用和分区容错性的前提下,无法保证一致性,只能尽可能保存缓存和数据库的最终一致性。
选择适合的缓存更新策略
- 删除缓存而不是更新缓存
- 先更新数据,在删除缓存
缓存不一致处理
如果不是并发特别高,对缓存依赖性强,一定的程序不一致数据是可以接收的,但如果对一致性要求比较高,就要像办法来保证数据库中的数据一致。
不一致一般两种原因:
- 缓存key删除失败
- 并发导致写入了脏数据

- 消息队列保证key的删除:可以引人消息队列机制,把药删除的key或者删除失败的key放入消息队列,引入重试机制,重试删除对应的key,缺点就是对业务代码有一定的侵入性
- 数据库订阅+消息队列保证保证key被删除:可以用一个服务(比如阿里的canal)去监听数据的binlog,获取操作的数据,然后用一个公共的服务获取订阅程序传来的信息,进行缓存删除操作

这种方式降低了代码的侵入,但是提升了系统的复杂度,适合基建完善的大厂。 - 延时双删防止脏数据:
还有一种情况,是在缓存不存在的时候,写入了脏数据,这种情况在先删缓存,再更数据库的缓存更新策略下发生的
比较多,解决方案是延时双删。
简单说,就是在第一次删除缓存之后,过了一段时间之后,再次删除缓存 - 设置缓存过期时间兜底
给缓存设置一个过期时间,即使发生数据不一致的问题,也不会永远的不一致。
7.如何保证本地缓存和分布式缓存的一致
在日常开发中我们如果采用两级缓存 本地缓存+分布式缓存
所谓本地缓存就是对应服务器的内存缓存比如Caffeine,分布式缓存就是Redis
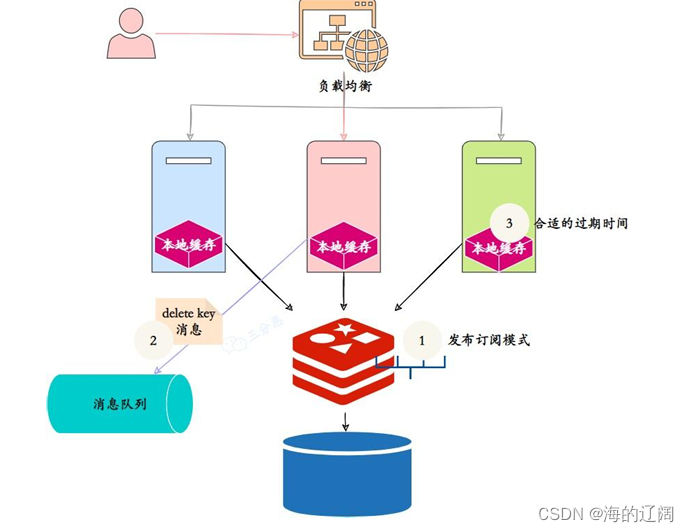
可以采用消息队列的方式:
- 采用Redis本身的Pub/Sub机制,分布式集群的所有节点订阅删除本地缓存频道,删除Redis缓存的节点,同时发布删除本地缓存消息,订阅者们订阅到消息后,删除对应的本地key。但是Redis的发布订阅不是可靠的,不能保证一定删除成功。
- 引入专业的消息队列,比如RocketMQ,保证消息的可靠性,但是增加了系统的复杂度。
- 设置适当的过期时间兜底,本地缓存可以设置相对短一些的过期时间。
8.如何处理热key
1.把热key打散到不同的服务器,降低压力
2.添加二级缓存,提前加载热key到内存中,如果redis宕机走内存查询
9.缓存预热怎么做
所谓缓存预热就是提前把数据库里面的数据刷新到缓存中。
- 直接写个缓存刷新接口或者页面,上线时候手动操作
- 数据量不大可以在项目启动的时候自行加载
- 定时任务刷新
10.热点key重建?问题?解决?
开发基本使用缓存+过期时间的策略,既可以加速数据读写,又保证数据的定时更新,这种模式基本能满足绝大部分的需求。
但是如果两个问题同时出现,可能会出现较大的问题
1.当前的key是一个热点key,并发量特别高
2.重建缓存不能在短时间内完成,在缓存失效的瞬间,有大量的线程来重建缓存,造成后端负载加大,可能会造成应用的崩溃
如何处理呢
解决要点在于
- 减少重建缓存的次数
- 数据尽可能一致
- 较少的潜在风险
所有一般采用如下的模式
- 互斥锁:这种方式永远只允许一个线程进行重建,其他线程等待完成
- 永不过期:
- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
- 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建
缓存。
11.无底洞问题?解决
为了满足业务要求添加大量的新MemCache节点但是发现节点没有好转反而下降,将这种现象称呼为缓存的无底洞现象。
那么为什么会产生这种现象呢?
通常来说添加节点使得Memcache集群 性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将 key
映射到各个节点上,造成key的分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水
平扩容,导致键值分布到更多的 节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不同节点上
获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
如何优化呢
常见优化思路
- 优化命令本身,如优化操作语句
- 减少网络通信次数
- 降低接入成本,例如客户端使用长连接,连接池,NIO等。


![[docker] Docker镜像的创建以及Dockerfile的使用](https://img-blog.csdnimg.cn/direct/dd7fcea794b5400fb642a2abb69101b6.png)