请先阅读第一篇:【IM】如何保证消息可用性(一)
在第一篇文章中我们了解了保证消息可用性的挑战与目标,现在我们来对于具体的技术方案进行探讨。
1. 上行消息
消息上行过程指的是客户端发送消息给服务端
我们需要先辨析几个概念:
- 局部有序(偏序) vs 全局有序
- 严格递增 vs 趋势递增
1.1 方案一
- clientID严格递增
- clientA创建会话与server建立长连接
- 在发送消息msg时分配clientId,此值会话(session)内严格递增
- 建立连接时client = 0 (TCP四次挥手保证package不会跨连接)
- 服务端将上一次收到的clientId缓存到preClientId,当且仅当clientId == preClientId +1时接受此消息
- 服务端确认接受消息后,回复ACK
- 当client收到ACK时,才停止重发(一般重发次数上限为3)
- 优点
- 消耗服务器资源少,仅存储一个 clientId即可
- seesion内消息id严格递增,以发送方顺序为准
- 实现简单
- 缺点
- 在弱网环境下,消息丢严重时,会造成大规模的消息重发,导致网络瘫痪影响消息及时性(类似于GBN)
- .群聊场景下,难以保证因果顺序
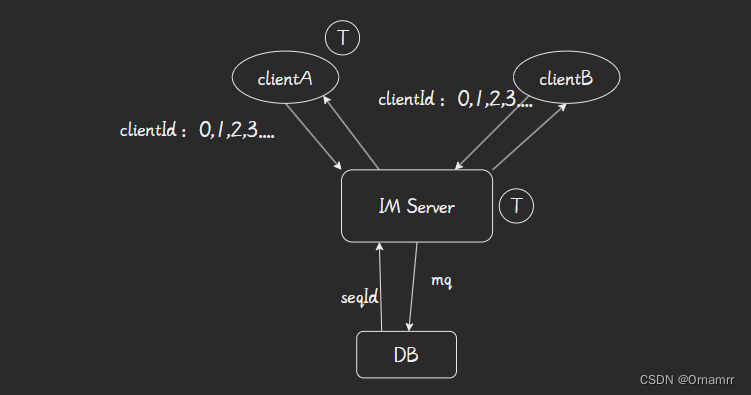
1.2 方案二
- client链表
- clientA使用本地时间戳作为clientId,每次发消息携带clientId,此时clientId只保持趋势递增,所以发送时还需携带preclientId
- server存储上一个msg的clientId作为preClientId,将preClientId和当前消息的preClientId对比,两者相等则接受

- 缺点:
- 协议的消息带宽较高
- 时间回拨问题,指的是系统时钟发生异常导致时间向后调整的情况。这可能会导致各种问题,尤其是在分布式系统中。
1.3 方案三
- clientId List
这种方案可以看做是对方案一弱网环境下的优化:
- server针对多个连接存储多个clientId,形成clientId list,即滑动窗口(飞行队列)
- 使用clientId list作为滑动窗口,保证消息幂等
- 优点
- 减少弱网环境下的消息风暴问题
- 缺点
- 实现更复杂
- 在服务端需要更多的内存维护连接状态 (主要缺点)
- 不太符合端到端的思想,传输层TCP协议已经使用滑动窗口对弱网环境进行优化,应用层重复实现的收益不明显。
2. 消息转发
上行消息成功之后,服务端主要是进行分配seqId,异步存储消息,处理业务逻辑
2.1 分配sequence Id
IM场景下的聊天会话中,至少有两个客户端参与,因此任何一个客户端分配的clientId只是偏序的,不能作为整个会话内的消息Id,clientId只是保证了消息按照client的发送顺序到达了服务端,服务端任然需要在一个session范围内分配一个递增Id,这个Id我们一般叫做sequence id
在对seqId分配时,我们直接想到的就是构建一个全局序号发生器,比如一个单点的redis msgincrby序号发生器, 但此时会存在一个明显的问题,单点下的性能瓶颈无法支持大量的序号生成需求(QBS > 10w)
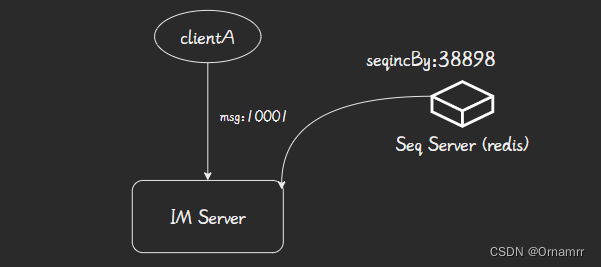
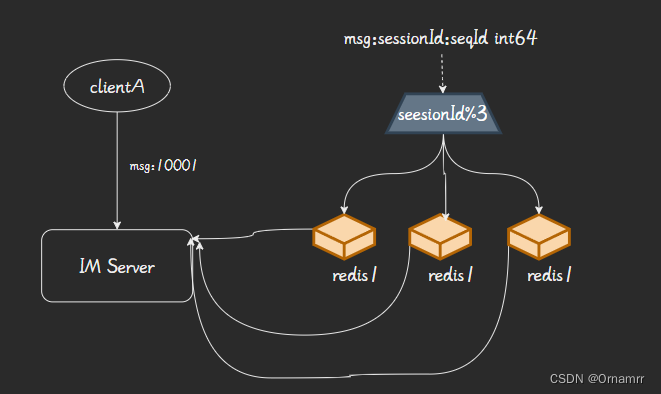
此时,我们发现,对于每一个客户所进行的每一个聊天会话来说,只需要保证每个会话是有序的,不同会话的消息顺序并不存在因果关系,因此我们还可以利用seesionId来进行分片设计:
msg:{sessionID}:{seqId} int64
此时我们可以对所有消息按照sessionID分片到不同的redis中,将redis集群化,进行水平拓展,通过这种方式,可以减少序号生成服务的单点压力:
2.2 消息回退
此时有同学又会提出疑问,集群内的单点redis崩溃后,怎么办,那么此时只能进行垂直拓展,主从热备,不过这样的设计也会给序号生成带来新的问题:消息回退,我们可以来研究一下:
当redis主节点的nextseq(待分配id)为1000时,此时followers进行拉取同步,将自己的nextseq设置为1000,但是在异步拉取的过程中,新的请求到来,seq将1000分配出去,nextseq 变为1001,此时主节点突然宕机,哨兵节点从follower中选取出新的leader,此时nextseq=1000,此时问题就出现了,对于新的连接,1000将再次被分配出去,此时造成了消息的重复,造成逻辑混乱。
分布式场景下,像这种序号不增反减的情况,叫做消息回退。

如何解决回退问题?
-
使用redis Lua脚本
对于lua脚本,在这里的作用,简单来说,就是lua脚本可以保证对于多kv操作的原子性。- 一个简单的lua例子:
/* redis.call('COMMAND', key1, key2, ..., arg1, arg2, ...):调用 Redis 命令。 redis.pcall('COMMAND', key1, key2, ..., arg1, arg2, ...):调用 Redis 命令,返回结果中包含错误信息。 KEYS 和 ARGV:分别用于获取 Lua 脚本中传入的键名和参数 要在 Redis 中运行 Lua 脚本,可以使用 EVAL 或 EVALSHA 命令: 1. EVAL "lua脚本代码" numkeys key [key ...] arg [arg ...] 2. EVALSHA sha1 numkeys key [key ...] arg [arg ...] */ -- 示例1:计算两个数的和 return tonumber(ARGV[1]) + tonumber(ARGV[2]) -- 示例2:将所有的哈希表键名转换为大写 local keys = redis.call('HKEYS', KEYS[1]) for i, key in ipairs(keys) do redis.call('HSET', KEYS[1], string.upper(key), redis.call('HGET', KEYS[1], key)) redis.call('HDEL', KEYS[1], key) end -- 示例3:计算列表中所有元素的总和 local sum = 0 local list = redis.call('LRANGE', KEYS[1], 0, -1) for i, v in ipairs(list) do sum = sum + tonumber(v) end return sum这种方案下,我们要求redis在处理seqId时,在添加一个字段runId,即一个redis实例的nodeId.
- redis收到请求
- 使用lua脚本,先检查当前redis节点的nodeID与存储的runId (即prenodeId)是否相等,相等则表示没有发生主从切换,直接++seqId
- 如果不相等,说明主从发生切换,可能存在回退,则seqId +=当前时间戳,实现一个序号跳变,保证了序号的递增属性。
这种方案,递增性是保证了,但是破坏了严格递增的属性,虽然主从切换的概率很低,万有一失,但是确实已经不是严格的递增了,只能说是趋势递增。
2.3 消息补洞
实际上,我们无法做到一个序号发生器的严格递增,趋势递增是保证性能下的最好收益,那么这样会造成一个问题,当服务器发送msg给client时,client发现msgId跳变了一个值(1->10),不再连续,此时有可能发送了两种事:
- 消息缺失,跳变间的所有消息没有收到
- 消息没缺失,只是序号发生器跳变导致的
此时如何处理?采用消息补漏手段,客户端主动尝试拉取服务端历史消息,如果真的缺失了,服务端会从数据库中发送过来,如果没返回数据,说明是序号跳变而已。
当每一条msg获取到了一个seqId之后,此时我们需要将msg交付给业务层去处理,比如登录,鉴权…,此时需要msgId全局唯一(不需要有序),这个时候我们又该如何处理msg的编号唯一性问题?
- 方案一: 拼接 seesionId + seqId,根据上面的讲解,显然这样的拼接是全局唯一的。不过这种方案不算太好,相对比较麻烦一些。
- 方案二:全局序号发生器,此时我们可以使用时间戳,雪花算法等来保证全局唯一
2.4 消息存储
- 为什么需要存储消息?
以微信为例,我们知道,客户端存储了我们的聊天记录,但是可能很多人不知道,我们发出的消息,在经过其服务器的时候,也被存储了。
从业务上讲,落库的消息数据可以用于进行数据分析和统计,帮助平台了解用户的行为习惯、消息交互情况等,从而优化产品功能、改进用户体验,并为商业决策提供数据支持,直白点说,就是两个方面: 监视你有没有说不该说的话,根据你说的话给你推荐其他相关服务。
我们在这里更关注技术上的作用:
- 消息持久化:将用户消息落库可以确保消息的持久化存储,即使在用户离线或断网时,消息也不会丢失。这样,用户在重新登录或恢复网络连接后,可以获取到之前的消息记录
- 消息同步:在多设备登录的情况下,用户可能在不同的设备上进行消息的发送和接收。通过将消息落库,可以实现消息在不同设备之间的同步,确保用户在任何设备上都能够获取到相同的消息内容。
- 消息推送和通知:通过消息落库,服务器可以实现消息的推送和通知功能,及时将消息推送给在线用户或通过推送通知的方式提醒用户有新消息到达.
同样,之前我们讲到的消息补漏的实现就是以消息落库为前提的。
- 如何存储消息
高并发场景下的落库,我们一般都会采用消息队列的方式进行异步落库,这样保证IO这类慢速操作不会阻塞业务,同时消息队列也可以保证消息不丢失。
消息队列(Message Queue)是一种用于在应用程序之间传递消息的通信机制,通常被用于解耦和异步处理。它基于生产者-消费者模型,生产者负责将消息发送到队列,而消费者则从队列中获取消息并进行处理。
常见的消息队列系统包括 RabbitMQ、Kafka、ActiveMQ、Redis、RocketMQ 等,它们都提供了丰富的功能和灵活的配置选项,适用于各种不同的应用场景
这里不对消息队列过多讲解,之后可能会单独出文章。
2.5 方案流程

我们在最开始也说了,服务转发分为三步,分配seqId,异步存储消息,处理业务逻辑,每一步我们都已经讲解了(具体业务逻辑暂时不关系),那么它们之间的顺序如何编排?
- 方案一
服务端在分配好seqId之后直接返回ACK消息,同时进行落库。
- 优点:消息到达后分配,保证了分配seqId的可用性
- 缺点:
- ack回复慢,影响收发效率,seqId分配称为性能瓶颈
- 消息存储失败则消息丢失
- 方案二
- 消息存储成功之后回复ACK,ACK失败则客户端重发
- 一旦消息落库,此时服务端崩溃了,导致长连接断开,客户端重写建立连接时,可以进行pull操作,拉取历史消息进行消息补洞。
- 消息落库,但是业务处理失败,接入层的长连接是无法感知的,那么无法push消息给客户端。业务层需要做异常捕获,并追加pull信令给clientB,主动触发客户端拉取历史消息。
- 优点:
- 保证业务处理的全流程可用性
- 出现异常,可以毫秒级触发接收端,保证消息及时性
- 缺点:
- ack回复更慢了,上行消息p95将延迟
- 通信复杂度增加
- 弱网环境下需要协议升降级机制(下面会讲)
3. 下行消息
主要流程是服务端将消息发送给客户端B,消息序号依赖于之前的seqId发生器。
3.1 方案一
客户端定期轮询发起pull请求拿取新消息
- 优点: 实现简单
- 缺点:
- 客户端耗电高,用户体验不佳
- 消息时延高,及时性差
3.2 方案二
- 依赖seqId的严格递增
- 使用redis increasby 生成seqId,使用sessionId作为key
- 用消息到达服务端的顺序分配seqId,会话内保证全局有序
- 服务端保证seqId严格递增的前提下将消息发送给clientB,clientB按照preSeq +1 = seqId的规则进行接受
- 服务端等待clientB的ACK,超时后重发
- 优点
- 实现简单
- 最大程度保证严格递增
- 缺点
- Redis存在单点问题,难以保证严格递增
- 弱网重传问题
- 当clientB不在线,无法进行消息传递
- 需要维护超时重传队列以及定时器
3.3 方案三
- 解决redis单点问题,代价是seqId趋势递增
- 使用lua脚本,存储maxSeqId和当前节点的runId
- lua每次获取Id是会检查当前node的runid和存储的runId是否一致
- 不一致,这说明发生主从切换,对maxSeqId进行跳变增加,保证序号不倒退
- clientB发现消息不连续的时候,发送pull信令进行补洞,拉取不到新消息,则说明是序号跳变造成,不处理
- 如果发现clientB当前不在线,查询用户状态之后仅仅存储不推送。
- 优点
- 最大可能的保证连续性,任何时刻的单调递增性
- seqId会话级别,不需要全局ID,redis可以通过cluster模式进行水平拓展
- 对于用户是否在线,做出来业务区分,减少网络带宽消耗
- 缺点
- 协议复杂度高
- 群聊场景下,可能造成消息风暴
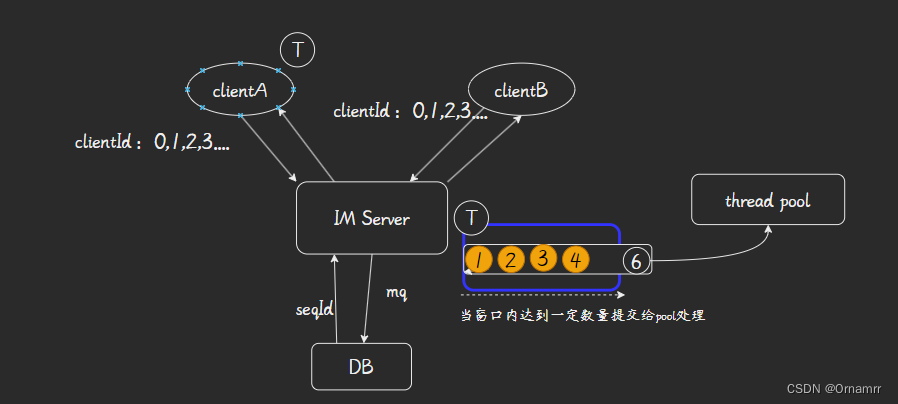
- 解决群聊消息风暴问题,我们可以采用协议降级的思想:当群聊不活跃,直接退化为点对点通信,次数对系统的负荷不大。当群聊活跃时,群聊会导致大量的ACK和PULL,消息风暴产生,此时我们可以设置服务端窗口,定时打包(eg:800ms)整体发送到一个client,client也对这些消息回复一个统一的ACK。
- 同时,由于服务端消息有序,故可以进行消息压缩,减少消息带宽。但是,如果消息打包后实在太大,那么会在TCP被分包(IP层pkg上限1500B),此时服务端需要发送PULL信令给clientB,要求clientB主动PULL消息,clientB这时候发起HTTP短连接,进行请求,不去占用长连接,避免群聊信息同步占用所有长连接带框导致用户其他会话产生卡顿的可能。
- 根据用户规模进行决策,是否支持此级别可用性




![[嵌入式系统-5]:龙芯1B 开发学习套件 -2- LoongIDE 集成开发环境集成开发环境的安装步骤](https://img-blog.csdnimg.cn/direct/e8d9f199f2c549c2a400b71b2cfdde4b.png)





