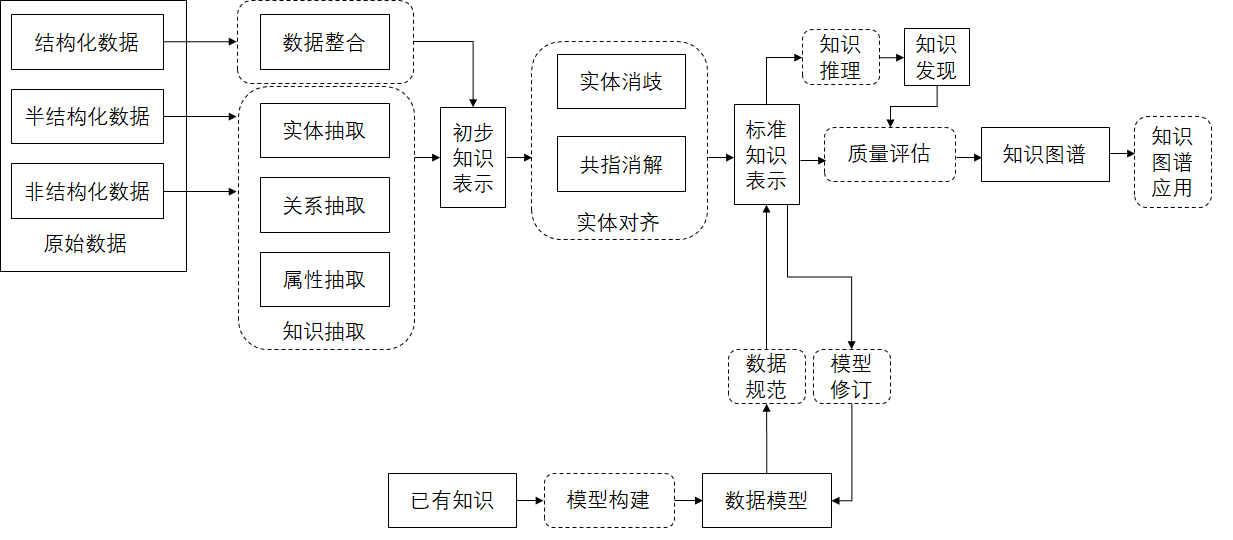
一、背景
在qemu调试linux kernel时 有时我们会遇到dump 情况,这时可以通过gdb 方式连接分析dump, 但实际中我们用得更多的是离线dump 分析,分析的文件通常是vmcore(linux kernel panic 生成的coredump文件)或者ramdump(类似高通平台提供的抓取手机的整个内存空间);这里我将介绍如何利用qemu 抓取vmcore, 以及后续利用crash 工具离线分析异常的方法。
二、qemu monitor建立连接
1、qemu 抓取vmcore 需要建立连接,server端连接建立
qemu-system-aarch64 \
-monitor telnet:127.0.0.1:5554,server,nowait \
-machine virt,virtualization=true,gic-version=3 \
-nographic \
-m size=2048M \
-cpu cortex-a72 \
-smp 2 \
-kernel Image \
-drive format=raw,file=rootfs.img \
-append "root=/dev/vda rw "对比前面的qemu 启动linux kernel, 这里需要增加指令:
-monitor telnet:127.0.0.1:5554,server,nowait
monitor通过telnet端口5554 建立server连接;
2、qemu monitor telnet client连接
geek@geek-virtual-machine:~/workspace/linux/qemu$ telnet 127.0.0.1 5554
qemu monitor中也有一些指令用来查看qemu运行的linux kernel 状态,这里不详细展开,有兴趣的可以自行搜索(比如热插拔增加一个device, 执行info roms查看 qemu运行的信息,抓取寄存器等)

对于抓取vmcore,我们唯一需要关心的是指令dump-guest-memory :
dump-guest-memory [-p] [-d] [-z|-l|-s|-w] filename [begin length] -- dump guest memory into file 'filename'.
-p: do paging to get guest's memory mapping.
-d: return immediately (do not wait for completion).
-z: dump in kdump-compressed format, with zlib compression.
-l: dump in kdump-compressed format, with lzo compression.
-s: dump in kdump-compressed format, with snappy compression.
-w: dump in Windows crashdump format (can be used instead of ELF-dump converting),
for Windows x64 guests with vmcoreinfo driver only.
begin: the starting physical address.
length: the memory size, in bytes.通常使用 dump-guest-memory filename 或 dump-guest-memory -z filename 指令会抓取qemu中linux kernel的vmcore,一个是不压缩,一个是zlib压缩格式, 后续就可以利用这个vmcore来进行kernel panic 离线分析;
三、qemu vmcore抓取
1、如何生成vmcore
先用最简单的命令行触发一个panic: echo c > /proc/sysrq-trigger
~ # echo c > /proc/sysrq-trigger
[ 142.419430] sysrq: Trigger a crash
[ 142.419886] Kernel panic - not syncing: sysrq triggered crash
[ 142.420293] CPU: 0 PID: 143 Comm: sh Tainted: G N 6.6.1-g3cba94c761ec-dirty #15
[ 142.420642] Hardware name: linux,dummy-virt (DT)
[ 142.420985] Call trace:
[ 142.421120] dump_backtrace+0x90/0xe8
[ 142.421412] show_stack+0x18/0x24
[ 142.421673] dump_stack_lvl+0x48/0x60
[ 142.422098] dump_stack+0x1c/0x28
[ 142.422434] panic+0x39c/0x3f0
[ 142.422744] sysrq_reset_seq_param_set+0x0/0x10c
[ 142.423099] __handle_sysrq+0x154/0x294
[ 142.423427] write_sysrq_trigger+0x80/0xcc
[ 142.423731] proc_reg_write+0x108/0x16c
[ 142.423990] vfs_write+0x158/0x45c
[ 142.424218] ksys_write+0xd0/0x180
[ 142.424425] __arm64_sys_write+0x44/0x58
[ 142.424651] invoke_syscall+0x60/0x184
[ 142.424887] el0_svc_common.constprop.0+0x78/0x13c
[ 142.425132] do_el0_svc+0x30/0x40
[ 142.425351] el0_svc+0x38/0x70
[ 142.425559] el0t_64_sync_handler+0x120/0x12c
[ 142.425816] el0t_64_sync+0x190/0x194
[ 142.426441] SMP: stopping secondary CPUs
[ 142.427057] Kernel Offset: disabled
[ 142.427264] CPU features: 0x1,00000200,3c020000,1000421b
[ 142.427700] Memory Limit: none
[ 142.428385] ---[ end Kernel panic - not syncing: sysrq triggered crash ]---然后在qemu monitor 端执行: dump-guest-memory ramdump1
或者:dump-guest-memory -z vmcore1

用 -z参数和不带参数抓取的vmcore只是一个压缩,一个不压缩,大小不同而已,对我们分析无影响

后面我们就用这个抓取到的ramdump1/vmcore1 文件进行分析,分析前我们还需要准备对应的kernel版本的vmlinux, 以及crash 工具(这个工具是redhat开发的分析kdump的免费开源工具);
2、crash工具交叉编译
1.下载crash tool
https://github.com/crash-utility/crash.git
2.编译crash, 我们分析的vmcore是arm64平台
make target=ARM64
3.根目录会生成crash工具,加到环境变量中使用即可
4. crash 还有一些externsion在目录extensions ---本次分析vmcore暂时不涉及,可以忽略
make extensions
编译生成后的so,在crash中通过extend XXX.so方式加载
a. trace.so 用来提取ramdump中的trace log, 分析一些疑难杂症是有用,
本质就是根据trace buffer结构体提取里面的trace log
https://github.com/fujitsu/crash-trace
b.gcore.so 可以在kernel panic后的ramdump中提取指定进程的coredump,对应用端逻辑调用栈进行分析
https://github.com/fujitsu/crash-gcorecrash 的指令学习可以参考下面两篇文章:
CRASH安装和调试_crash gcore-CSDN博客
四、crash加载vmcore
1、crash加载指令:
crash vmcore路径 vmlinux路径 -m vabits_actual=XX 指定虚拟地址长度(位长的设置后面会介绍)
crash ../qemu/vmcore1 vmlinux -m vabits_actual=48虚拟地址长度可以在.config中查看(64位平台通常的配置是48或者39):
//CONFIG_ARM64_VA_BITS_48=y CONFIG_ARM64_VA_BITS=48

2、加载遇到问题

看来这个问题已经在crash bug上有人报过了,但是问题还是没有解决(反馈者对比发现4.X 版本的内核是正常的---我自己用4.19也是正常的, 现在我用的linux6.6.1也是有问题,这个问题应该在crash arm64上存在了很久,但是没人去解决)。
[Crash-utility] [Question] crash-arm64 cannot determine VA_BITS_ACTUAL for qemu dump-guest-memory
花了些时间分析后, 发现是自动计算kimage_voffset时遇到了问题,导致后面无法进行; 由于这个在一个编译的版本上是固定值,于是我简单通过 gdb 连接,然后在内核查看变量kimage_voffset的值,最后通过crash的参数设定传入,
(gdb) p /x kimage_voffset
$3 = 0xffff80003fe00000上面可以看到我这个版本的kimage_voffset值是0xffff80003fe00000,不清楚怎么单步调试kernel的参考我前面的文章: 无人知晓:qemu单步调试arm64 linux kernel
3、crash增加参数 kimage_voffset=XXX
重新加载vmcore, 通过gdb获取kimage_voffset的值,在crash 加载vmcore/ramdump时,arm64平台有如下几个参数可以设置:
ARM64: //这些都是特定平台相关参数,通过 -m option=value 指定
phys_offset=<physical-address> //指定物理地址的起始
kimage_voffset=<kimage_voffset-value> //指定kimage_voofset的值
max_physmem_bits=<value>
vabits_actual=<value> //指定虚拟地址长度,手机通常使用39位,虚拟地址空间已经到512G,足够使用,
//39位相对48位,正好少一级页表,性能上有提升,同时当前的虚拟地址空间足够手机使用了
--kaslr offset //kaslr指定kaslr偏移的参数,qemu调试我们通常会关闭,否则对齐vmlinux需要花些功夫
//在高通平台中ocimem.bin特定offset存放,
//linux ramdump parse解析的结果也有这个offset
crash最终启动命令:
crash ../qemu/vmcore1 vmlinux -m vabits_actual=48 -m kimage_voffset=0xffff80003fe00000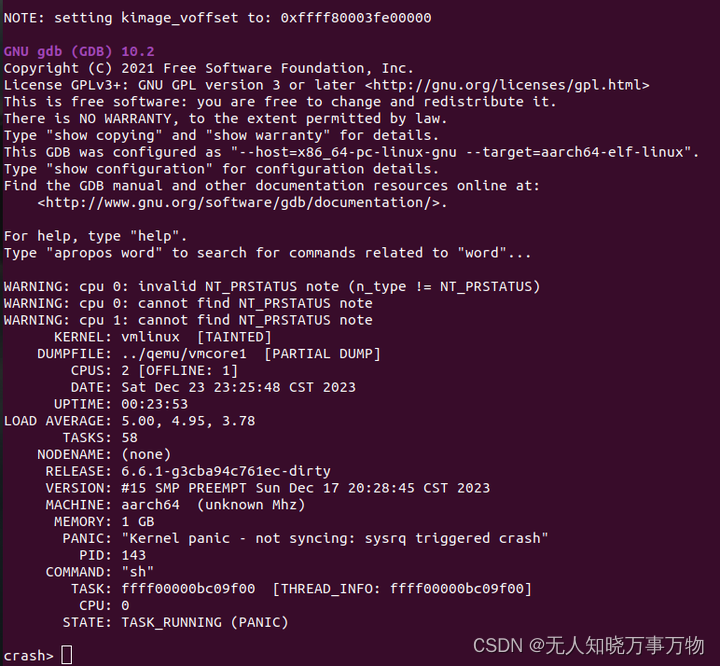
如上,加载vmcore成功。
五、crash中如何调试一个vmcore
echo c > /proc/sysrq-trigger 方式触发的dump, 入口在drivers/tty/sysrq.c中

实际我们在调试中,遇到panic都需要恢复调用栈及问题发生时的寄存器来进行分析;
1、如何恢复调用栈
crash> bt
PID: 143 TASK: ffff00000bc09f00 CPU: 0 COMMAND: "sh"
bt: WARNING: cannot determine starting stack frame for task ffff00000bc09f00执行bt为什么无法恢复调用栈?panic时sp指针等信息并没有填入导致的,正如我们在使用T32调试通常也需要也个cmm放置 x0~x29, sp/lr 等信息才能正常恢复异常现场
2、如何获取panic时的寄存器信息?
通常内核发生异常时会打印当前CPU的寄存器信息,利用这个打印信息就可以,在遇到wdt或者tz卡死类问题时,肯定是无法打印出来,这时平台通常是触发fiq到trustzone, 然后在TZ中抓取EL1 的cpu寄存信息,我们这里是因为调用的panic, 这个默认也是不打印寄存器信息的。如果是触发data abort或者instuction abort等异常还是能正常打印,如:

上面是我用4.19内核echo c 触发的,4.19的实现就是通过空指针访问制造的异常(个人觉得用空指针制造的panic更方便分析)
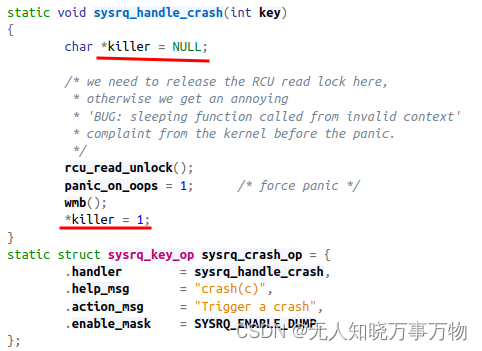
3、获取panic时的调用栈
执行bt时,提供了 pid和触发panic的进程name信息:
PID: 143 TASK: ffff00000bc09f00 CPU: 0 COMMAND: "sh"
crash> task -x -R thread.cpu_context 143
PID: 143 TASK: ffff00000bc09f00 CPU: 0 COMMAND: "sh"
thread.cpu_context = {
x19 = 0xffff80008475af40,
x20 = 0x0,
x21 = 0xffff00000bc09f00,
x22 = 0xffff7fffb13f4000,
x23 = 0xffff800082e0e748,
x24 = 0xffff00000bd1d500,
x25 = 0xffff800085fd7850,
x26 = 0xffff80008475b338,
x27 = 0xffff800082e0e750,
x28 = 0xffff000034202748,
fp = 0xffff800085fd7740,
sp = 0xffff800085fd7740, //利用sp恢复
pc = 0xffff8000817d4390
},
利用bt恢复时,需要lr指针,sp + 8就是lr, sp中存放的是上一级的sp;不清楚可以看后面参考的链接:https://student.cs.uwaterloo.ca/~cs452/docs/rpi4b/aapcs64.pdf
crash> bt -S 0xffff800085fd7748
PID: 143 TASK: ffff00000bc09f00 CPU: 0 COMMAND: "sh"
bt: WARNING: cannot determine starting stack frame for task ffff00000bc09f00
#0 [ffff800085fd7750] idle_cpu at ffff80008010a9a0
#1 [ffff800085fd7780] irq_exit_rcu at ffff8000800c4a68
#2 [ffff800085fd7790] arm64_preempt_schedule_irq at ffff8000817d424c
#3 [ffff800085fd77b0] el1_interrupt at ffff8000817caf10
#4 [ffff800085fd77d0] el1h_64_irq_handler at ffff8000817cb2c0
#5 [ffff800085fd7910] el1h_64_irq at ffff800080011ae4
#6 [ffff800082b361e0] (null) at f420
PC: 000000000044fd4c LR: 00000000004b7734 SP: 0000ffffd8894070
X29: 0000ffffd8894070 X28: 0000000000000000 X27: 0000000000000000
X26: 0000000001e57970 X25: 0000000000000002 X24: 0000000000000020
X23: 0000000001e5c6a0 X22: 0000000000602000 X21: 0000000000000002
X20: 0000000001e5c6a0 X19: 0000000000000001 X18: 0000000000000000
X17: 0000000000403140 X16: 0000000000600020 X15: 000000000360ed96
X14: 0000000000000001 X13: 0000ffffd88941b0 X12: 00000000ffffffc8
X11: 00000000ffffff80 X10: 0000000000000000 X9: 0000000000000020
X8: 0000000000000040 X7: 7f7f7f7f7f7f7f7f X6: 0000000000000063
X5: fffffffffffffffe X4: 0000000000000001 X3: 0000000000601ca5
X2: 0000000000000002 X1: 0000000001e5c6a0 X0: 0000000000000001
ORIG_X0: 0000000000000001 SYSCALLNO: 40 PSTATE: 80000000恢复到第五级,遇到一些问题,直接查看堆栈内容,在0xffff800085fd7910处出现了栈回溯问题,这是因为中断的原因,跳过这一级继续向下就可以恢复完整异常发生的调用栈,如下标红线的就是sp回溯,sp + 8就是每一级对应的lr函数,可以通过sym XXXXX查看
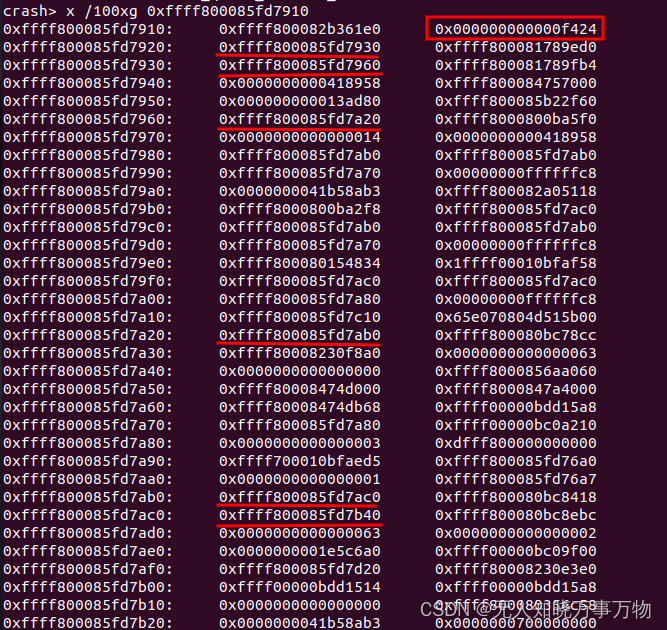
从0xffff800085fd7920 开始恢复调用栈,此时就是真实触发异常的调用栈
crash> bt -S 0xffff800085fd7928
PID: 143 TASK: ffff00000bc09f00 CPU: 0 COMMAND: "sh"
bt: WARNING: cannot determine starting stack frame for task ffff00000bc09f00
#0 [ffff800085fd7930] __delay at ffff800081789ecc
#1 [ffff800085fd7960] __const_udelay at ffff800081789fb0
#2 [ffff800085fd7a20] panic at ffff8000800ba5ec
#3 [ffff800085fd7ab0] sysrq_handle_crash at ffff800080bc78c8
#4 [ffff800085fd7ac0] __handle_sysrq at ffff800080bc8414
#5 [ffff800085fd7b40] write_sysrq_trigger at ffff800080bc8eb8
#6 [ffff800085fd7b70] proc_reg_write at ffff8000804b83e8
#7 [ffff800085fd7ca0] vfs_write at ffff8000803f5b84
#8 [ffff800085fd7d60] ksys_write at ffff8000803f6130
#9 [ffff800085fd7da0] __arm64_sys_write at ffff8000803f6224
#10 [ffff800085fd7dd0] invoke_syscall at ffff80008002ee48
#11 [ffff800085fd7e20] el0_svc_common.constprop.0 at ffff80008002efe4
#12 [ffff800085fd7e60] do_el0_svc at ffff80008002f0d8
#13 [ffff800085fd7e80] el0_svc at ffff8000817cb060
#14 [ffff800085fd7ea0] el0t_64_sync_handler at ffff8000817cb45c
#15 [ffff800085fd7fe0] el0t_64_sync at ffff800080011d48
PC: 000000000044fd4c LR: 00000000004b7734 SP: 0000ffffd8894070
X29: 0000ffffd8894070 X28: 0000000000000000 X27: 0000000000000000
X26: 0000000001e57970 X25: 0000000000000002 X24: 0000000000000020
X23: 0000000001e5c6a0 X22: 0000000000602000 X21: 0000000000000002
X20: 0000000001e5c6a0 X19: 0000000000000001 X18: 0000000000000000
X17: 0000000000403140 X16: 0000000000600020 X15: 000000000360ed96
X14: 0000000000000001 X13: 0000ffffd88941b0 X12: 00000000ffffffc8
X11: 00000000ffffff80 X10: 0000000000000000 X9: 0000000000000020
X8: 0000000000000040 X7: 7f7f7f7f7f7f7f7f X6: 0000000000000063
X5: fffffffffffffffe X4: 0000000000000001 X3: 0000000000601ca5
X2: 0000000000000002 X1: 0000000001e5c6a0 X0: 0000000000000001
ORIG_X0: 0000000000000001 SYSCALLNO: 40 PSTATE: 80000000crash的使用技巧可以参考文末部分(写得都很详细)
六、总结
1、利用qemu monitor 提取vmcore
2、利用crash 工具加载分析vmcore
参考:
CRASH安装和调试_crash gcore-CSDN博客
crash实战:手把手教你使用crash分析内核dump-CSDN博客
https://student.cs.uwaterloo.ca/~cs452/docs/rpi4b/aapcs64.pdf
https://linux.web.cern.ch/centos7/docs/rhel/Red_Hat_Enterprise_Linux-7-Kernel_Crash_Dump_Guide-en-US.pdf
![[嵌入式系统-5]:龙芯1B 开发学习套件 -2- LoongIDE 集成开发环境集成开发环境的安装步骤](https://img-blog.csdnimg.cn/direct/e8d9f199f2c549c2a400b71b2cfdde4b.png)